Het gebruik van geautomatiseerde data-extractie kan je bedrijf transformeren. Het is vrij eenvoudig om ermee te beginnen, maar het kan even duren voordat je precies beseft wat en hoeveel het voor jouw bedrijf kan betekenen.
Moeten jij of je medewerkers honderden, duizenden of zelfs miljoenen documenten per maand handmatig verwerken? Is dit een proces waar je liever vanaf wilt? Je bent niet de enige! Gelukkig is er een antwoord: het automatisch extraheren van gegevens uit documenten. Dit versnelt en versimpelt het hele proces.
Ben je nou benieuwd hoe dit werkt? Of wil je jezelf vertrouwd maken met een algemeen beter begrip van het extraheren van gegevens? Lees dan verder.
Key Takeaways
- Data-extractie maakt documenten direct bruikbaar – Zet PDF’s, scans en afbeeldingen automatisch om naar gestructureerde data.
- Minder fouten en lagere kosten – Automatisering vervangt handmatige invoer en verlaagt het foutpercentage.
- Flexibel inzetbaar met of zonder ETL – Werkt binnen ETL-processen én als standalone extractie.
- Schaalbaar zonder extra personeel – Verwerkt groeiende documentvolumes moeiteloos.
- Onmisbaar voor compliance-processen – Ondersteunt KYC, factuurverwerking en fraudedetectie.
Typen gegevens in het data-extractieproces
Om data-extractie beter te begrijpen, is het belangrijk om de meest voorkomende gegevensbronnen en hun unieke eigenschappen te kennen. Hieronder bespreken we de vier belangrijkste soorten gegevens en wat ze bijzonder maak
- Gestructureerde gegevens zijn sterk georganiseerde en geformatteerde gegevens met een duidelijk vooraf gedefinieerd datamodel. Dit maakt ze eenvoudig doorzoekbaar en gemakkelijk te analyseren. Voorbeelden: SQL-databases, Excel-spreadsheets, CSV-bestanden.
- Ongestructureerde gegevens hebben geen vooraf bepaald datamodel en volgen geen vaste structuur. Dit type gegevens is moeilijker te analyseren, maar vaak rijk aan waardevolle informatie. Voorbeelden: E-mails, PDF-documenten, multimedia-inhoud zoals afbeeldingen en video’s.
- Fysieke bronnen omvatten allerlei soorten papieren documenten die handmatig zijn gemaakt. Deze documenten moeten meestal gedigitaliseerd worden voordat de gegevens eruit kunnen worden geëxtraheerd. Voorbeelden: Papieren facturen, bonnetjes, geprinte rapporten, inkooporders.
- Digitale bronnen bestaan uit gegevens die elektronisch zijn gegenereerd, opgeslagen of verwerkt. Dit type gegevens is meestal direct toegankelijk en eenvoudig te verwerken met geautomatiseerde tools. Voorbeelden: Digitale documenten, databases, multimedia-bestanden, systeemrapporten.

De verschillende typen gegevens en bronnen bepalen welke methoden voor databeheer en data-extractie het meest effectief zijn. De aard van de gegevens en hun herkomst beïnvloeden de technieken die worden gebruikt voor extractie, analyse en toepassing in diverse processen.
Nu we inzicht hebben in de verschillende soorten gegevens, kunnen we verder ingaan op de rol van data-extractie binnen én buiten het ETL-proces.
Wat betekent data-extractie?
Wat betekent het om gegevens uit documenten te halen? Het komt erop neer dat verschillende soorten gegevens uit één of meerdere bronnen worden gehaald. Deze bronnen zijn meestal slecht georganiseerd en ongestructureerd.
Door de gegevens te extraheren kun je ze elders nog verder verwerken, opslaan en analyseren. Dit soort gegevens wordt meestal gebruikt om de bedrijfsvoering te verbeteren. Het is de basis voor het doen van een kritische analyse in het besluitvormingsproces.
Er zijn drie vormen van data-extractie. Handmatig, geautomatiseerd en human in the loop, een combinatie van de eerste twee.
Nu de definitie van data-extractie duidelijk is, gaan we verder met het belang van het proces.
Data-extractie en ETL
Het ETL-proces (Extract, Transform, Load) is een veelgebruikte methode om gegevens uit verschillende bronnen te integreren, transformeren en op te slaan voor analytische doeleinden. Dit proces zorgt ervoor dat je data consistent, nauwkeurig en klaar is om waardevolle inzichten te onthullen. Hieronder volgt een overzicht van hoe het werkt:
- Extractie (Extract): Tijdens deze fase worden gegevens opgehaald uit bronsystemen zoals databases, applicaties, bestanden of andere opslagplaatsen. Dit omvat het identificeren en verzamelen van relevante gegevens die nodig zijn voor analyse of rapportage.
- Transformatie (Transform): Na de extractie worden de gegevens getransformeerd om te voldoen aan de gewenste structuur, opmaak of kwaliteitsnormen. Transformaties kunnen bestaan uit het opschonen van gegevens, het samenvoegen van datasets, verrijking of andere bewerkingen om de data gereed te maken voor analyse.
- Laden (Load): Wanneer de gegevens zijn geëxtraheerd en getransformeerd, worden ze geladen in een doelsysteem, vaak een datawarehouse of een database die geoptimaliseerd is voor analytische queries. Tijdens deze stap worden de voorbereide gegevens efficiënt opgeslagen en toegankelijk gemaakt.
Dit proces is essentieel voor organisaties die inzichten willen halen uit data afkomstig van meerdere, vaak uiteenlopende bronnen.
Data-extractie zonder ETL
Niet elke organisatie heeft een ETL-framework nodig voor data-extractie. In situaties waarin directe toegang tot ruwe gegevens voldoende is en uitgebreide transformaties niet noodzakelijk zijn, is data-extractie zonder ETL een geschikte aanpak. Hieronder volgt een overzicht van hoe dit werkt:
- Directe Extractie: In sommige gevallen worden gegevens rechtstreeks uit bronsystemen gehaald, zonder de tussenstappen van transformatie en laden die typisch zijn voor ETL. Deze methode is ideaal voor onmiddellijke analyse of rapportage. Met technologieën zoals OCR (Optical Character Recognition) kunnen bijvoorbeeld gegevens uit PDF’s, afbeeldingen en gescande documenten worden geëxtraheerd en direct gebruikt.
- Gebruik van API’s (Application Programming Interfaces): Data-extractie zonder ETL kan ook plaatsvinden via directe API-koppelingen met bronsystemen. API’s maken gestructureerde communicatie mogelijk tussen verschillende softwaretoepassingen, waardoor specifieke datasets direct toegankelijk zijn. OCR-technologie kan bovendien worden geïntegreerd om tekst of gegevens uit documenten te halen die via API’s worden bereikt.
- Bestandsgebaseerde Extractie: Een andere methode omvat het direct extraheren van gegevens uit bestanden zoals Excel-spreadsheets, CSV-bestanden of andere gestructureerde formaten. Deze aanpak is bijzonder handig wanneer de gegevens al in een geschikt formaat voor analyse beschikbaar zijn.
Directe data-extractie biedt eenvoud en snelheid voor bepaalde toepassingen. Het mist echter de uitgebreide integratie- en transformatiemogelijkheden die ETL-processen bieden. De keuze tussen ETL en directe extractie hangt af van je specifieke bedrijfsdoelen en het beoogde gebruik van de gegevens.
Waarom is data-extractie belangrijk?
Stel je voor dat je een bank bent die hypotheken verstrekt aan kopers van huizen. Volgens de wet ben je dan verplicht KYC-controles uit te voeren, het inkomen van de koper te registreren en waarschijnlijk nog veel meer.
Om deze controles uit te voeren sturen klanten documenten op met deze informatie. Deze informatie moet in jouw database, of beslissingssysteem, terechtkomen.
Helaas zijn de gegevens ongestructureerd, waardoor je een team nodig hebt om de aanwezigheid van informatie op documenten, zoals het salaris op de loonstrook, te identificeren. Daarnaast moet de informatie worden ingevoerd in je digitale systemen.
Dit is een kostbare, tijdrovende en vervelende taak, maar dat hoeft niet zo te zijn. Veel bedrijven maken namelijk gebruik van geautomatiseerde extractie oplossingen en technieken, die door AI worden aangedreven, om het data-extractie proces van het begin tot het einde te beheren.
De belangrijkste voordelen van het gebruik van een geautomatiseerde extractie oplossing zijn:
- Verbeterde nauwkeurigheid
- Verhoogde productiviteit van werknemers
- Lagere kosten
- Tijdsbesparing
- Schaalbaarheid
- Snellere doorlooptijd
Verbeterde nauwkeurigheid
Vervanging van handmatig invoeren van data door geautomatiseerde data-extractie vermindert de kans op menselijke fouten aanzienlijk. Daarom leidt het tot een hogere nauwkeurigheid.
Als het invoeren van grote hoeveelheden gegevens een dagelijkse taak is voor je meeste werknemers, is de kans groot dat er enkele onnauwkeurigheden en fouten zijn als gevolg van menselijke fouten. Zonder enige verificatiestappen heeft data-invoer een foutenpercentage van 4%.
Door het extraheren van de gegevens uit documenten te automatiseren, worden de gegevens over het algemeen nauwkeuriger. Een grotere nauwkeurigheid leidt niet alleen tot betere zakelijke beslissingen, maar is ook zeer gunstig voor werknemers. Dit brengt ons bij het volgende voordeel.
Verbeterde werknemer productiviteit
Wanneer het handmatig extraheren van gegevens wordt vervangen door een geautomatiseerde tool, kunnen werknemers meer tijd besteden aan belangrijke taken. Sommige taken kunnen alleen door mensen worden gedaan. Laat je medewerkers die uitvoeren en de taken die geautomatiseerd kunnen worden door een geautomatiseerde extractie oplossing.
Niet alleen zal de tevredenheid toenemen omdat werknemers geen vervelende energie slurpende taken te hoeven verrichten, werknemers kunnen zich ook richten op zinvollere taken. Dit zal weer leiden tot een grotere tevredenheid, wat (op termijn) zal leiden tot een hogere productiviteit.
Verminderde kosten
Door te kiezen voor een extractie hulpmiddel kan je bedrijf zowel op korte als op lange termijn geld besparen.
Op korte termijn kan je bedrijf al veel geld besparen door het verminderen van fouten bij handmatige gegevensinvoer. Op lange termijn hoeft jouw bedrijf zich geen zorgen te maken over het schalen en financieren van een groot team om de gegevensbehoeften van je bedrijf af te handelen. Daarom zijn geautomatiseerde systemen voor gegevensinvoer en -extractie in opkomst.
Tijdsbesparend
Studies tonen aan dat automatisering gewoonlijk een kostenbesparing van 40 tot 75% oplevert. Tijd is geld, en daarom is het misschien wel één van de grootste verkoopargumenten van een extractie software.
Schaalbaarheid
Wanneer een bedrijf groeit, groeit ook de hoeveelheid inkomende en uitgaande documenten. Als het extraheren van gegevens uit documenten nog steeds handmatig gebeurt, stapelt de hoeveelheid documenten zich op.
Dit kan worden voorkomen door over te stappen op een geautomatiseerd systeem. Daardoor kan het bedrijf opschalen zonder dat het zich zorgen hoeft te maken over grote hoeveelheden rondslingerende gegevens, of dat het een groot personeelsbestand moet aannemen.
Snellere doorlooptijd
Door de geautomatiseerde data-extractie kunnen de doorlooptijden van dagen of weken naar seconden gaan. Als een mens een document handmatig moet controleren, kan slechts één document per keer worden gedaan. Bovendien kunnen mensen maar 8 uur per dag werken.
Uitdagingen
Als er voordelen zijn, moeten er ook uitdagingen zijn met betrekking tot de data-extractie. Twee uitdagingen zijn:
- Beveiliging van gevoelige gegevens – Een voorbeeld van gevoelige gegevens zijn financiële gegevens. Daarom moet de beveiliging van data-extractie worden gewaarborgd. Het is belangrijk om alleen te werken met softwareoplossingen die kunnen aantonen dat hun beveiliging regelmatig wordt getest en dat ze kunnen voldoen aan de AVG en andere wetgevingen.
- Samenhang van geëxtraheerde gegevens uit verschillende bronnen – De uitdaging is nog groter als deze bronnen zowel ongestructureerd als gestructureerd zijn, omdat je er dan nog steeds voor moet zorgen dat ze goed samenwerken. AI-aangedreven systemen kunnen worden getraind om gegevens te combineren en ze na verwerking geschikt te maken voor bewerkingen.
Soorten data
Gegevens kunnen worden ingedeeld volgens de structuur van de bron:
- Gestructureerde gegevens – De gegevensbron heeft al een logische structuur. Daarom zijn ze zeer geschikt voor extractie. Je hoeft deze niet te bewerken voor het proces van data-extractie. Voorbeelden hiervan zijn CSV- en XML-bestanden.
- Ongestructureerde gegevens – De meeste gegevens bestaan in ongestructureerde elementen. Bronnen van ongestructureerde gegevens zijn bijvoorbeeld PDF’s, gescande teksten, webpagina’s, e-mails of afbeeldingen. Ongestructureerde gegevens moeten worden gefilterd voor een zinvolle extractie van gegevens. Voorbeelden hiervan zijn het verwijderen van witregels, dubbele resultaten en andere ‘ruis’ die uit het document moet worden verwijderd.
Soorten technieken van data-extractie
Er zijn twee verschillende technieken voor het extraheren van gegevens: logische en fysieke extractie.
Logische extractie
Logische extractie is de meest gebruikte techniek. Zij kan worden onderverdeeld in twee subtypes:
- Volledige extractie – Alle gegevens worden tegelijkertijd volledig geëxtraheerd, zonder dat er extra (techno)logische informatie nodig is. Volledige extractie is een methode die wordt gebruikt wanneer de gegevens voor het eerst moeten worden geëxtraheerd en geladen. Het weerspiegelt de gegevens die op dat moment in het bronsysteem beschikbaar zijn.
- Incrementele extractie – Sinds de laatste succesvolle data-extractie worden de optredende wijzigingen in de brongegevens bijgehouden. Deze wijzigingen worden vervolgens incrementeel geëxtraheerd en geladen.
Fysieke extractie
Als het extraheren van gegevens uit verlopen of beperkte gegevensopslagsystemen met behulp van logische extractie moeilijk is, is het toepassen van fysieke extractietechnieken de enige manier om deze gegevens te verkrijgen. Fysieke extractie kan worden opgesplitst in twee types:
- Online extractie – Er is een directe verbinding tussen het bronsysteem en het uiteindelijke archief. Bij online extractie zijn de geëxtraheerde gegevens meer gestructureerd dan de brongegevens.
- Offline extractie – De werkelijke data-extractie vindt plaats buiten het bronsysteem. Bij offline extractie zijn de gegevens zelf gestructureerd of worden ze via extractie-routines gestructureerd.
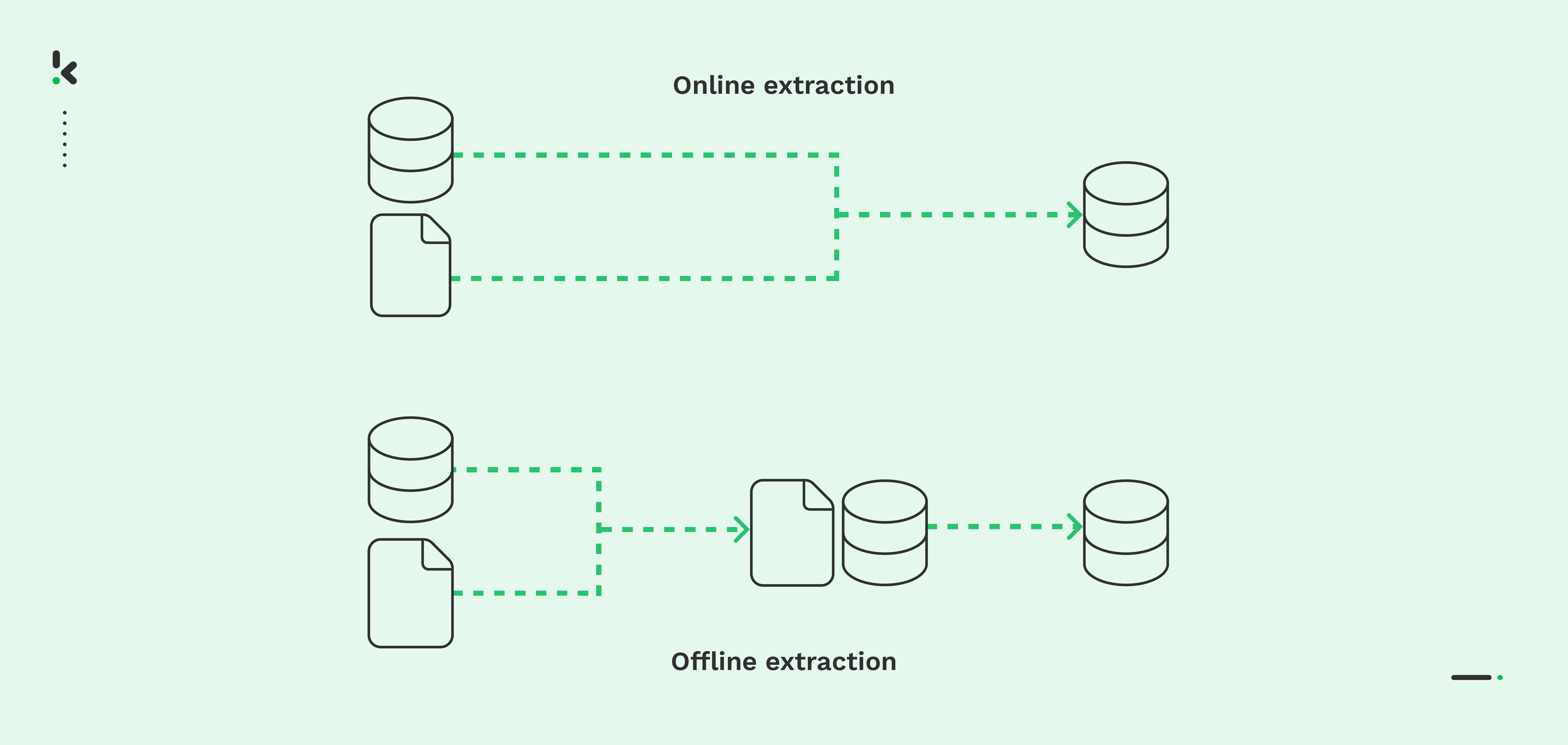
Categorieën van tools voor extractie
Tools voor gegevens-extractie halen automatisch gegevens uit de bron. Het type en het doel zijn zeer belangrijke parameters. Om te begrijpen welke categorie hulpmiddelen het beste zou werken voor jouw bedrijf, moet je het verschil tussen de drie begrijpen:
- Tools voor batchverwerking – Kunnen interessant zijn voor bedrijven die gegevens van de ene naar de andere locatie moeten overbrengen, maar er komen uitdagingen bij kijken. Uitdagingen kunnen gegevens zijn die zijn opgeslagen in verouderde vormen, of legacy gegevens. Batchverwerking kan ook nuttig zijn voor bedrijven die gegevens on-premise of in een gesloten omgeving willen verplaatsen.
- Open source hulpmiddelen – Hebben de voorkeur voor bedrijven met een budget. Zij kunnen Open Source software aanschaffen om verstrekte gegevens te extraheren. Open source tools zijn meestal voldoende voor kleinere bedrijven.
- Cloud-gebaseerde hulpmiddelen – de meerderheid van de beschikbare extractie tools zijn tegenwoordig cloud-gebaseerd. Cloud-gebaseerde hulpmiddelen blinken uit in snelle, betrouwbare data-extractie. Door cloud-gebaseerde hulpmiddelen te gebruiken, hoeven bedrijven zich niet langer zorgen te maken over compliance- en beveiligingskwesties binnen hun bedrijf. Bovendien zijn vertragingen door batchverwerking verleden tijd.
Er zijn tegenwoordig veel cloud-gebaseerde oplossingen op de markt. Eén daarvan is Doxis AI.dp.
Doxis is gespecialiseerd in data-extractie vanuit ongestructureerde documenten en kan jou helpen ongestructureerde documenten om te zetten in gestructureerde gegevens.
Voorbeeld van data-extractie
Laten we eens kijken wat een extractie-oplossing voor jou kan doen. We nemen een paspoort als voorbeeld:
Stel dat je klant dit paspoort links in een KYC-proces heeft geüpload en je gebruikt data-extractie software om de benodigde informatie te verkrijgen. De volledige naam, het documentnummer en de MRZ, bijvoorbeeld.
Binnen 3 seconden kan het systeem de ongestructureerde afbeelding omzetten in de gestructureerde gegevens zoals weergegeven op de rechter afbeelding hieronder.
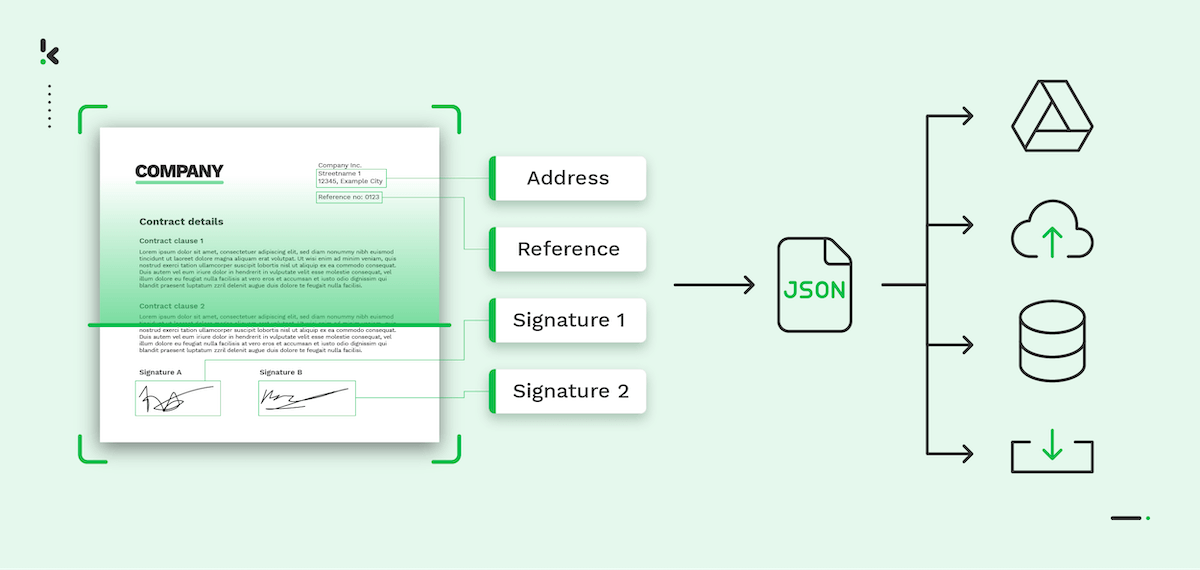
Doxis’ cloud-gebaseerde extractie-oplossing
Doxis AI.dp is een Intelligent Document Processing bedrijf. De software die wij bouwen is gemaakt om bedrijfsprocessen waarbij documenten betrokken zijn te automatiseren. Onze oplossingen helpen de productiviteit en efficiëntie te verhogen en de kosten en menselijke fouten te verminderen.
Doxis biedt een uitgebreide cloud-gebaseerde data-extractie oplossing, die bedrijven helpt automatisch elk type document binnen enkele seconden te verwerken.
Hoe werkt het extractie-proces van ongestructureerde documenten?
Maar hoe worden gegevens geëxtraheerd? Het proces van data-extractie uit een document kan in een paar stappen kort worden uitgelegd. Het beschreven proces is hoe het extractie-proces bij Doxis werkt.
1. Uploaden van het document
Eerst moet het papieren document worden omgezet in een digitaal document. Meestal gebeurt dat door het document te scannen met een mobiele telefoon. Het kan ook worden gedaan door een bestand te uploaden naar het systeem. De input kan in verschillende formaten zijn, zoals JPG, PDF, PNG en TXT.
2. Afbeelding naar TXT
Nu de upload klaar is, kan de daadwerkelijke data-extractie beginnen. Het enige probleem is dat de computer nog niet kan lezen wat er op het document of de foto staat. Daarom moet het worden omgezet in een TXT-bestand. Daartoe komt de OCR-technologie (Optical Character Recognition) om de hoek kijken. Deze technologie haalt alle gegevens uit het document, maar deze zijn nog niet gestructureerd.
3. Omzetten naar JSON
In de laatste stap is een parser nodig om de tekst van het bestand te lezen en te begrijpen. De parser zet het TXT-bestand om in een gestructureerd JSON-bestand. Nadat de conversie is voltooid, kunnen de gegevens gemakkelijk worden verwerkt in de database. Naast JSON zijn ook andere outputs mogelijk, zoals XML, XLSX en CSV. Onze OCR API is zeer flexibel.
4. De geëxtraheerde data met derde partijen verifiëren
Optioneel kunnen wij de geëxtraheerde gegevens verifiëren met bronnen van derden. Dit kan je eigen database zijn, maar ook databases van de Kamer van Koophandel en anti-witwaslijsten. Zo ben je er zeker van dat de kwaliteit van de gegevens goed is en in overeenstemming met de regelgeving.
Data-extractie API
De bovenstaande oplossing voor data-extractie wordt gebruikt door bedrijven over de hele wereld en in verschillende bedrijfstakken. Voorbeelden van bedrijfstakken zijn financiële diensten, detailhandel, boekhouding, douane en gezondheidszorg.
Natuurlijk kun je proberen zelf een volledige extractie-pijplijn te bouwen, maar dat is ingewikkeld en tijdrovend. Het is ook duur om te onderhouden, en vaak zal de ROI van het bouwen ervan zeer slecht zijn in vergelijking met het gebruik van een bestaande oplossing.
Daarom is het implementeren van een API van derden voor data-extractie een goede keuze. Via onze API kan de oplossing worden geïntegreerd in elke bestaande software. Daarom kunnen de gegevens rechtstreeks in de software worden geëxtraheerd.
FAQ
Vrijwel alle documenten: facturen, bonnetjes, contracten, paspoorten, loonstroken, vrachtbrieven en formulieren, zowel digitaal als gescand.
2. Is data-extractie veilig voor gevoelige informatie?
Ja. Doxis voldoet aan strenge beveiligingsstandaarden en wetgeving zoals de AVG. Gegevens worden versleuteld verwerkt en opgeslagen, met gecontroleerde toegang en regelmatige beveiligingstests. Hierdoor is data-extractie ook geschikt voor gevoelige informatie zoals financiële en identiteitsgegevens.
3. Wanneer is human-in-the-loop nodig?
Bij uitzonderingen, twijfelgevallen of compliance-gevoelige processen. Hierbij controleert een mens steekproefsgewijs of corrigeert hij de automatisch geëxtraheerde data.
4. Hoe nauwkeurig is geautomatiseerde data-extractie?
Moderne AI-gedreven oplossingen behalen een zeer hoge nauwkeurigheid, vooral wanneer ze worden gecombineerd met validatieregels of human-in-the-loop controles.
5. Kan data-extractie omgaan met verschillende talen en documentlayouts?
Ja. Doxis ondersteunt meerdere talen en herkent uiteenlopende documentlayouts automatisch, zonder dat vaste templates nodig zijn. Hierdoor kunnen ook internationale en sterk variërende documenten betrouwbaar worden verwerkt.
6. Kan data-extractie helpen bij het opsporen van documentfraude?
Ja. Doxis combineert data-extractie met fraudedetectie, zoals het herkennen van afwijkingen, dubbele documenten en gemanipuleerde bestanden.