
Volgens het Identity Theft Resource Center waren er in 2023 maar liefst 3.205 openbaar gerapporteerde datalekken, die naar schatting 353.027.892 personen hebben getroffen. Dit is een toename van 78% ten opzichte van 2022. Dit is een zorgwekkende trend, aangezien steeds meer gegevens worden opgeslagen in de cloud.
Als organisatie wil je natuurlijk niet dat gevoelige gegevens in verkeerde handen terechtkomen. Een van de beste strategieën om je risico’s bij het delen of opslaan van gegevens online te beperken, is door zoveel mogelijk gevoelige informatie te onleesbaar maken. Hoe meer je onleesbaar maakt, hoe kleiner het risico wordt.
Betekent dit dat je alle documenten handmatig moet controleren en gevoelige informatie moet verwijderen? Gelukkig niet! Er bestaan intelligente oplossingen die automatisch gevoelige informatie in documenten vinden en het onleesbaar maken.
Maar wat wordt precies gedefinieerd als gevoelige informatie? Hoe werkt het onleesbaar maken van deze informatie? En kan software dit proces echt vereenvoudigen?
In deze blog beantwoorden we deze vragen, presenteren we relevante voorbeelden en laten we zien welke voordelen een geautomatiseerd systeem jouw organisatie kan bieden.
Wat is gevoelige informatie?
Laten we beginnen met het definiëren van gevoelige informatie. Gevoelige informatie is informatie die beschermd moet worden tegen onbevoegden. Het gaat om vertrouwelijke, privé of geheime gegevens die alleen toegankelijk mogen zijn voor bepaalde personen.
In Europa wordt vertrouwelijke data grotendeels bepaald door de AVG-regelgeving, terwijl in Amerika veel organisaties moeten voldoen aan de California Consumer Privacy Act (CCPA).
Vertrouwelijke gegevens kunnen voorkomen in papieren of digitale documenten, zoals een foto en naam op een cv. In deze blog richten we ons op digitaal opgeslagen gegevens.

Welke gegevens moeten onleesbaar worden gemaakt?
Om vertrouwelijke gegevens te kunnen vinden en blurren, moet een organisatie eerst bepalen welke informatie klanten en medewerkers delen, welke nodig is en welke geblurd moet worden.
Over het algemeen zijn er vier soorten gegevens die beschermd moeten worden:
- Persoonlijk identificeerbare informatie (PII): Bijvoorbeeld volledige naam, BSN, rijbewijsnummer of paspoortnummer.

- Beschermde medische informatie: Zoals medische geschiedenis, testresultaten en verzekeringsgegevens.

- Betalingsgegevens: Bijvoorbeeld creditcardnummers en vervaldatums (voor PCI/DSS-compliance).

- Intellectueel eigendom: Creaties zoals ontwerpen of handelsmerken. Vaak wordt hier een watermerk toegevoegd in plaats van redactie.

De volgende velden worden vaak als gevoelig beschouwd en kunnen worden geïdentificeerd en geblurd:
- Naam
- Adres
- Geboortedatum
- Leeftijd
- Bankrekeningnummer
- Creditcardnummer
- Burgerservicenummer (BSN)
- Werk- en opleidingsgeschiedenis
- Foto
- Handtekening
Natuurlijk is niet alle bovengenoemde informatie van toepassing op jouw organisatie, omdat dit per sector verschilt. Maar nu je een overzicht hebt van de informatie waar je op moet letten, heb je een goede basis voor de volgende stappen.
Waarom zou je gevoelige informatie uit een database onleesbaar maken?
Er zijn verschillende redenen waarom een organisatie vertrouwelijke informatie uit haar database zou moeten blurren. Het beschermen van gevoelige gegevens is niet alleen een wettelijke verplichting in jouw branche, maar ook een teken van respect voor je klanten en andere betrokkenen.
Hier zijn de 4 belangrijkste redenen waarom een organisatie vertrouwelijke informatie onleesbaar zou moeten maken:
- Voldoen aan regelgeving
- Minimaliseren van beveiligingsrisico’s
- Juridische verplichtingen
- Verzekeringseisen
De risico’s van datalekken zijn reëel en mogen niet worden onderschat. Om ernstige schade voor jouw organisatie en alle betrokkenen te voorkomen, is het cruciaal om goede beveiliging te implementeren. Dit omvat het blurren van gevoelige data uit documenten.
Daarnaast zorgt het anonimiseren van informatie ervoor dat je voldoet aan de AVG-vereisten van jouw land of bedrijf.
In de EU gelden strenge regels voor de bescherming van gegevens. Deze regels schrijven voor dat informatie op een rechtmatige, eerlijke en transparante manier moet worden verwerkt, en dat de opslag en overdracht van gegevens tot een minimum beperkt moeten blijven. Het is belangrijk om aan deze eisen te voldoen als je jouw gegevens op een Europese server wilt hosten.
Voordat we doorgaan naar het volgende deel, willen we een aantal technische termen introduceren en de volgende vraag beantwoorden:
Hoe noem je het onleesbaar maken van gevoelige informatie uit documenten?
Kort gezegd: dit wordt data masking genoemd, ook bekend als data redaction, data-anonimisering en data-obfuscatie.
Data masking kan op verschillende manieren worden uitgevoerd, zoals:
- Substitutie
- Herschikking
- Gemiddelde berekening
- Nullen van gegevens
- Data redaction
- Data scrambling
- Data encryptie
We gaan hier niet uitgebreid in op elke techniek, maar als je meer wilt weten, raden we je aan onze ultieme gids over data masking te lezen.
Als je nog niet bekend bent met de onderliggende technologie van data masking, lees dan eerst verder in deze blog. In het volgende deel leggen we uit welke technologie het mogelijk maakt om automatisch gevoelige data uit documenten onleesbaar te maken.
Hoe kun je gevoelige gegevens uit documenten automatisch verwijderen?
Als je slechts een paar bestanden hebt waarbij gevoelige gegevens moeten worden geblurd, is het prima om dit handmatig te doen. Bij grotere organisaties is het volume aan documenten en gegevens echter vaak enorm.
Dit maakt handmatig anonimiseren een tijdrovende klus. De kosten en tijd lopen hoog op, doorlooptijden worden lang en fouten komen vaak voor.
Gelukkig is er een alternatief voor handmatige redactie. Bij het proces van het vinden en blurren van vertrouwelijke informatie kunnen vrijwel alle stappen worden geautomatiseerd met behulp van Intelligent Document Processing (IDP)-software.
Een IDP-oplossing zoals Klippa DocHorizon kan bijvoorbeeld binnen enkele seconden documenten controleren en redacties uitvoeren. Bij Klippa bieden we meerdere opties om gevoelige data automatisch te vinden en te maskeren, zoals:
- Volledig geautomatiseerde data masking met AI
- Human-assisted automation
- Data masking op mobiele apparaten
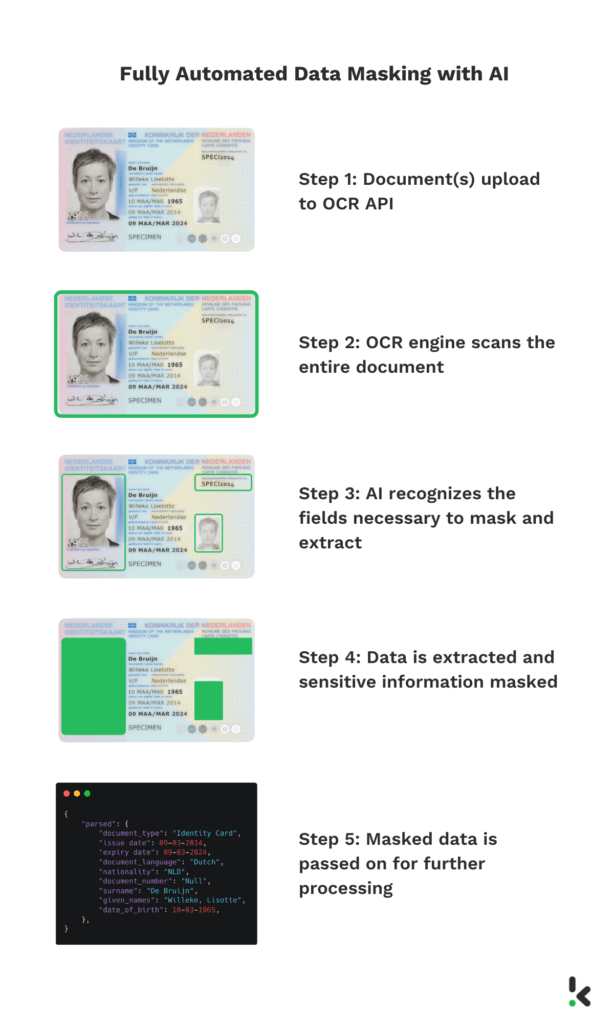
Volledig geautomatiseerde data masking met AI
Met een volledig geautomatiseerde oplossing is menselijke tussenkomst niet meer nodig. Klippa heeft het DocHorizon platform ontwikkeld, waarmee je gevoelige informatie automatisch kunt herkennen, lokaliseren en maskeren binnen enkele seconden.
Dit wordt mogelijk gemaakt door AI-gestuurde OCR-technologie, die is getraind met honderden documenten om specifieke velden te herkennen en bijvoorbeeld vertrouwelijke informatie zwart te maken.
Volledig geautomatiseerde data masking bespaart tijd van je medewerkers, zodat ze hun vaardigheden kunnen inzetten voor complexere taken. Zo verhoog je de efficiëntie van je organisatie.
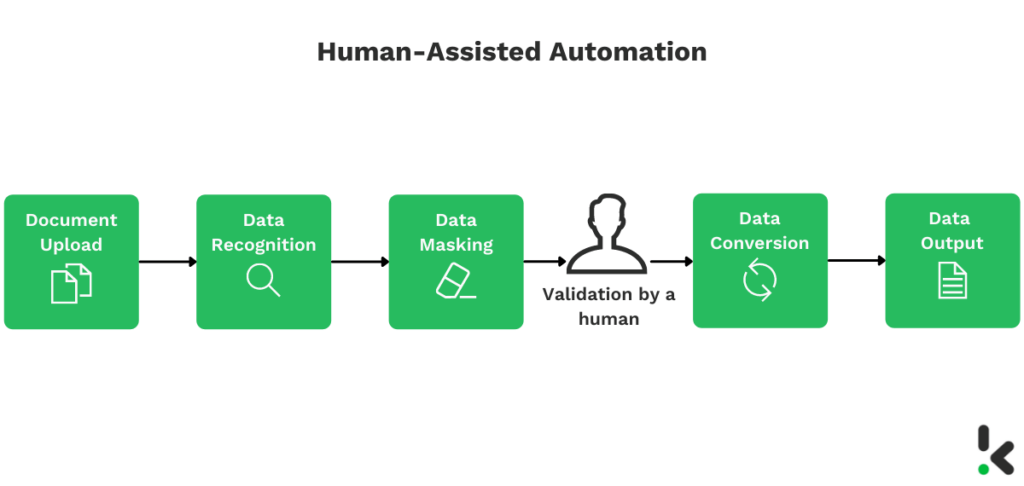
Human-assisted automation
Als jouw organisatie 100% nauwkeurigheid vereist, kan het verstandig zijn om human-assisted automation te implementeren. Voordat de gegevens in de database worden opgeslagen, controleert een medewerker het gemaskeerde document in plaats van dat de gegevens automatisch worden opgeslagen.
Op deze manier kunnen fouten door bijvoorbeeld een slechte beeld- of documentkwaliteit worden voorkomen en wordt de nauwkeurigheid vergroot.
Deze oplossing combineert het beste van kunstmatige intelligentie met het beste van menselijke intelligentie, waardoor jouw organisatie zowel efficiënt als effectief kan werken.
Data masking op mobiel (Semi-geautomatiseerde oplossing)
Als je zelf een applicatie hebt of er een wilt ontwikkelen, is de eenvoudigste manier om deze uit te breiden met data masking-functionaliteiten het integreren van onze mobiele scanner SDK in de applicatie.
Onze mobiele scanner SDK bevat data masking-technieken waarmee je een foto kunt maken van een document (bijvoorbeeld een ID-kaart, factuur of paspoort) en vervolgens handmatig een zwart blok kunt tekenen om gevoelige informatie te maskeren. Dit zorgt ervoor dat alleen de noodzakelijke informatie wordt gedeeld en opgeslagen.
We willen dat je een weloverwogen beslissing kunt nemen. Daarom presenteren we hieronder enkele voordelen van het automatisch en handmatig verwijderen van gevoelige informatie.
Wat zijn de voordelen van het automatisch verwijderen van gevoelige gegevens?
Hoeveel documenten verwerk je elke week? Elke maand? Misschien bevatten niet al deze documenten gevoelige informatie die moet worden geanonimiseerd, maar stel je eens voor hoeveel tijd je zou besparen als je niet elk document handmatig hoefde te controleren. Andere voordelen zijn:
- Gegevens scannen en extraheren binnen enkele seconden.
- Minimaliseren van fouten.
- Verlaging van arbeidskosten, doorlooptijden en fouten.
- Schaalbaarheid.
We hebben een tabel gemaakt om handmatige en geautomatiseerde documentverwerking te vergelijken. Zo kun je gemakkelijker de voor- en nadelen van elk proces zien.
Vergelijking: Documentverwerking
| Factoren | Handmatige Documentverwerking | Geautomatiseerde Documentverwerking |
|---|---|---|
| Verwerkingstijd | Zeer tijdrovend. Afhankelijk van het document kan een formulier 8 tot 10 minuten duren om te verwerken. | Het document kan binnen een paar seconden gescand en geëxtraheerd worden. Werknemers hoeven alleen de geëxtraheerde gegevens te bevestigen. |
| Foutpercentage | Mensen kunnen fouten maken zoals dubbele invoer, typefouten, grammaticale fouten en het invoeren van verkeerde gegevens. | Fouten zijn zeer beperkt, omdat de OCR-engine de exacte informatie uit het document extraheert. |
| Kostenbesparing | Meer mensen moeten worden ingehuurd om betere resultaten te behalen. Fouten kunnen kostbaar zijn en leiden tot dure gevolgen (bijv. boetes). | Verbeterde efficiëntie en nauwkeurigheid met AI. Bespaar geld door lagere arbeidskosten, kortere verwerkingstijd en minder fouten. |
| Schaalbaarheid | Een werknemer is beperkt tot een bepaald aantal documenten dat hij/zij kan verwerken. | Een geautomatiseerde oplossing biedt organisaties de mogelijkheid om documenten op schaal te verwerken zonder extra operationele kosten. |
Wat zijn veelvoorkomende toepassingen voor het maskeren van gevoelige gegevens?
In de volgende paragrafen bespreken we drie veelvoorkomende toepassingen:
- Identiteitsdocumenten
- Medische dossiers van patiënten
- Financiële documenten
Blacklining van identiteitsdocumenten
Een van de meest voorkomende toepassingen is het anonimiseren van kopieën van identiteitsdocumenten. Gegevens zoals het burgerservicenummer (BSN) op een paspoort of ID zijn zeer gevoelig en mogen vaak niet in een database worden opgeslagen.
Een BSN valt onder de “speciale categorieën van persoonsgegevens” en valt onder strikte regels volgens de AVG. Gewoonlijk hebben alleen overheidsinstanties toestemming om BSN’s op te slaan, wat betekent dat andere organisaties manieren moeten vinden om deze gegevens te blurren.
Een manier om BSN’s te redigeren is door met intelligente software automatisch de noodzakelijke informatie op de kopie van het document zwart te maken.
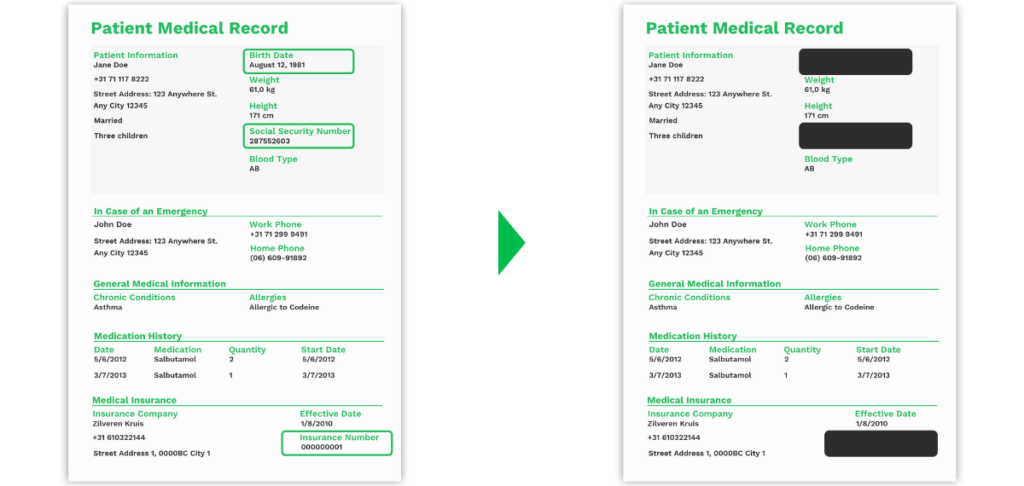
Blacklining van medische dossiers van patiënten
Persoonlijke gezondheidsinformatie is gevoelig en moet worden beschermd. Als zorgverleners en andere organisaties die patiëntinformatie gebruiken, verwerken of doorgeven, niet voldoen aan de eerder genoemde AVG-regels, kunnen ze te maken krijgen met boetes en sancties.
Een zorgverlener verwerkt duizenden documenten, waardoor het onmogelijk is om deze allemaal handmatig te controleren. Daarom is het cruciaal om software te gebruiken die automatisch gevoelige informatie kan vinden en onleesbaar maken, zoals adressen, BSN’s en verzekeringsnummers van patiënten.
Door medische dossiers te blacklinen met software kunnen patiënten worden beschermd tegen fraude en datalekken.
Blacklining van financiële documenten
Facturen, kopieën van creditcards en contracten zijn allemaal financiële documenten die dagelijks worden verwerkt. Deze documenten bevatten vertrouwelijke informatie die beschermd moet worden tegen onbevoegden.
De financiële sector heeft de verantwoordelijkheid om fraude te voorkomen en te voldoen aan regelgeving. Als een financiële instelling hier niet aan voldoet, kan dit leiden tot reputatieschade, rechtszaken of boetes.
Neem bijvoorbeeld een factuur. Gegevens zoals de naam en het adres van een klant moeten worden gemaskeerd. Door deze techniek te gebruiken, kan fraude door dubbele of valse facturen worden voorkomen.
Het handmatig controleren van alle documenten zou een onmogelijke taak zijn. Daarom zijn slimme documentoplossingen zoals Klippa ontwikkeld om dit proces te automatiseren.

We hebben zojuist drie verschillende gebruiksscenario’s beschreven, maar hetzelfde geldt eigenlijk voor vrijwel elk type document of afbeelding. Hebben we jouw specifieke geval hier niet behandeld en vraag je je af of we je ook kunnen helpen? Neem dan gerust contact met ons op voor vragen of meer informatie.
Haal automatisch vertrouwelijke gegevens uit documenten met Klippa
Klippa is gespecialiseerd in veel vormen van documentautomatisering. Alle genoemde voorbeelden zijn situaties die we dagelijks voor klanten wereldwijd oplossen.
Met Klippa kun je niet alleen gevoelige informatie vinden en blurren in documenten, maar ook:
- De kwaliteit van administratief werk verbeteren.
- Operationele kosten verlagen.
- Kostbare fouten voorkomen.
Het maskeren van gegevens met onze IDP-oplossing, Klippa DocHorizon, maakt AVG-compliance eenvoudiger dan ooit. Daarnaast biedt Klippa jouw organisatie de volgende voordelen:
- Ervaring in diverse industrieën
- Internationale klanten in meer dan 30 landen
- ISO gecertificeerde service
- Hostingopties in meerdere landen
- Documenten anonimiseren binnen seconden
Klinkt dit als een oplossing voor jouw organisatie? Laat ons je helpen om je bedrijf naar een hoger niveau te tillen. Boek hieronder een gratis demo om onze oplossing te leren kennen, of neem contact op met een van onze experts. We werken graag met je samen!