
Nu data het nieuwe goud is voor de bedrijfswereld, is het voor bedrijven ongelooflijk lastig als waardevolle informatie vastzit in ongestructureerde documentformaten, zoals een PDF. De reden hiervoor is dat ongestructureerde documentformaten niet machinaal leesbaar zijn. Dit betekent dat, om met de gegevens van een PDF-document te werken, informatie handmatig moet worden geëxtraheerd en opgeslagen in je database.
Het handmatig extraheren van informatie is een aanvaardbaar proces zolang bedrijven slechts met een handvol PDF-documenten werken. Zodra een organisatie grotere hoeveelheden documenten moet verwerken, wordt het handmatige proces te traag, te duur én foutgevoelig.
Hier kan een PDF parser het traditionele handmatige proces van data entry en extractie vervangen. Met data parsing is het mogelijk om snel gegevens om te zetten van het ene formaat naar het andere, zoals een PDF-bestand naar een machinaal leesbaar JSON-bestand.
In deze blog bespreken we wat een PDF parser is en hoe PDF-gegevens worden geparsed. Daarnaast leggen we uit waarom bedrijven überhaupt een PDF parser zouden moeten gebruiken, om vervolgens af te sluiten met een automatiseringsoplossing voor PDF parsing.
Key Takeaways
- PDF parsing zet ongestructureerde PDF-data automatisch om naar gestructureerde, machineleesbare formaten zoals JSON.
- Handmatige data-extractie is traag, kostbaar en foutgevoelig; een parser elimineert deze problemen.
- Doxis AI.dp biedt hoge nauwkeurigheid, snelle verwerking en flexibele integratie via API en SDK.
- Automatisering met Doxis bespaart tijd, verlaagt kosten en optimaliseert bedrijfsprocessen.
Wat is een PDF parser?
Een PDF parser, ook bekend als PDF-schraper, is software die gegevens uit PDF-documenten kan identificeren en extraheren. Dit betekent dat de tekst in het document, oftewel ongestructureerde gegevens, wordt omgezet in gestructureerde gegevens die door machines kunnen worden gelezen. Op die manier wordt waardevolle informatie ontsloten die anders in het ongestructureerde formaat ontoegankelijk zou blijven.
In het algemeen kun je met een PDF parser:
- Tekst uit PDF’s halen
- Afbeeldingen uit PDF’s halen
- Tabellen en andere structuren uit PDF’s halen
- Het PDF-bestand omzetten in JSON-, XML- en HTML-bestanden
- Gestructureerde gegevens gebruiken voor bedrijfsprocessen
Nu we weten wat een PDF parser is, laten we eens kijken hoe parsing werkt, zodat je het ook voor je bedrijf kunt gebruiken.
Hoe parse je data uit een PDF?
PDF parsers maken gebruik van geavanceerde algoritmen om de gegevenselementen in een PDF-document te identificeren. Als de PDF parser goed getraind is, kan hij alle basistypes van document-elementen identificeren.
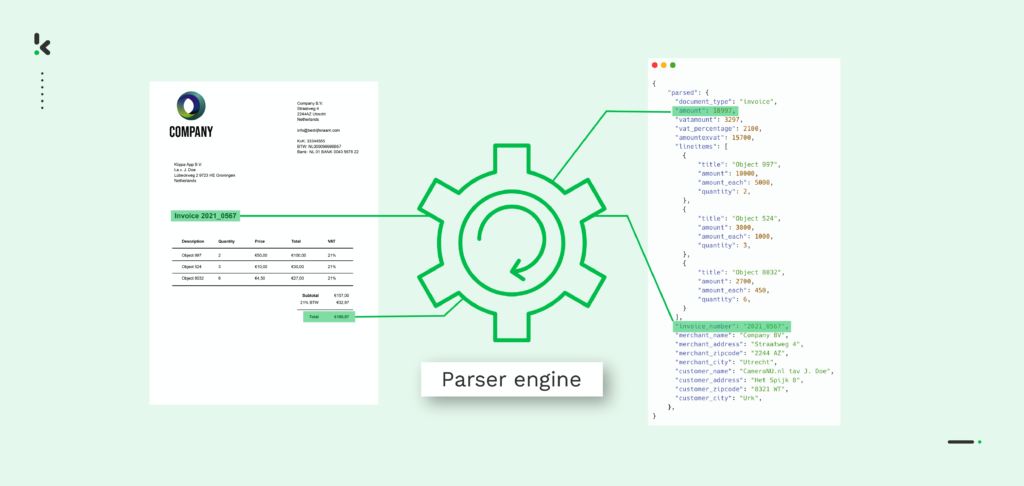
Dit proces omvat Optical Character Recognition (OCR) en andere AI-technologieën zoals Natural Language Processing (NLP) en Machine Learning (ML). Alleen met behulp van deze technologieën kan een PDF parser een PDF-bestand scannen en er gegevens uit parsen.
Het proces kan er als volgt uitzien:
- Een PDF-bestand uploaden naar de parser → De PDF moet worden geüpload naar een API om het parseerproces te starten. Het is belangrijk dat de PDF geen ruis op de achtergrond bevat.
- Voorverwerking van de PDF → De helderheid van de PDF-scan kan worden geoptimaliseerd of de grijswaarden kunnen worden verbeterd om de herkenningsnauwkeurigheid van de gegevens te verhogen.
- PDF omzetten in tekst → In deze stap kan het PDF-document worden omgezet in een tekstbestand (TXT). Elk deel van het document wordt herkend (totaalbedrag, adres) en vervolgens worden de gegevens geëxtraheerd.
- Conversie naar gestructureerde gegevens → In deze laatste stap wordt het tekstbestand geconverteerd naar een gestructureerd machineleesbaar formaat zoals JSON. Nu kun je de gegevens uit de PDF gemakkelijk verwerken in je database.
Op dit moment vraag je je misschien af wat voor soort gegevens een PDF parser eigenlijk kan extraheren om je te helpen beslissen of een PDF parser aan je behoeften voldoet.
Wat voor data kan je uit PDF’s parsen?
De meeste organisaties gebruiken PDF-bestanden als de go-to optie voor veel verschillende soorten documenten. Denk aan boeken, presentaties, facturen, inkooporders en rapporten die vaak in de vorm van een PDF-bestand worden gedeeld tussen organisaties.
Hoewel PDF’s een geweldig bestandsformaat zijn om rijke media in op te nemen, kun je er met PDF parsers de volgende informatie uit halen:
- Tekstparagrafen → Hoewel dit de meest elementaire vorm van gegevens is, zou het handmatig kopiëren en plakken ervan leiden tot opmaakproblemen. Een PDF parser kan tekst met de juiste opmaak extraheren, zodat je die gemakkelijk voor verdere processen kunt gebruiken.
- Tabellen en lijsten → Hier is het de moeite waard extra onderzoek te doen, omdat alleen de modernste PDF parsers de aanwezigheid van tabellen kunnen herkennen. De meeste oude PDF parsers beschouwen tabellen als een paragraaf en maken er een puinhoop van, waardoor handmatige data extractie nodig is.
- Afbeeldingen → Een PDF parser kan afbeeldingen uit het PDF-document halen. Dit is vooral nuttig wanneer je afbeeldingen uit het document elders wilt hergebruiken en bespaart je de last van het maken van schermafbeeldingen van lage kwaliteit.
- Velden met enkelvoudige gegevens (tracking-nummers, QR-codes, barcodes) → Als een PDF velden bevat met enkelvoudige gegevens, kan een PDF parser deze nauwkeurig extraheren en de gegevens netjes rangschikken in een bepaald veld.
Met dit in gedachten, gaan we nu bekijken waarom een PDF parser waardevol is voor bedrijven.
Waarom zouden bedrijven PDF parsing gebruiken?
Verschillende lay-outs en structuren van PDF-bestanden maken ze complex en moeilijk om er gegevens uit te halen. Daarom is handmatige data extractie tijdrovend en kan het veel geld kosten. Het leidt ook tot allerlei fouten en onnauwkeurige data extractie.
Met een PDF parser kunnen fouten en onnauwkeurige extractie worden vermeden. Zoals we hierboven hebben geleerd, kan een PDF parser met behulp van moderne technologieën informatie op PDF’s nauwkeurig en zonder opmaakproblemen identificeren en extraheren.

Zoals je je kunt voorstellen, leidt dit tot een aanzienlijke vermindering van de tijd die wordt besteed aan de verwerking van PDF’s, wat uiteindelijk leidt tot lagere kosten en het gebruik van andere middelen die dan kunnen worden besteed aan taken die meer waarde opleveren. Een kortere verwerkingsduur van documenten resulteert in geoptimaliseerde workflows, wat de activiteiten van je bedrijf zal vergemakkelijken.
Zoals je kunt lezen, brengt een PDF parser software verschillende voordelen met zich mee. Daarom zijn er verschillende softwarebedrijven die een oplossing hebben ontwikkeld waar je van kunt profiteren. Een van deze software oplossingen is Doxis AI.dp.
PDF parsing automatiseren met Doxis AI.dp
Doxis AI.dp is een AI-gebaseerde OCR-software die kan worden gebruikt om informatie uit PDF’s en andere documenten waarmee je bedrijf kan werken te ontleden. Met onze OCR-technologie kun je nauwkeurig relevante gegevens extraheren uit ongestructureerde gegevensformaten (zoals PDF’s) en deze converteren naar het door jou gewenste formaat.
Daarnaast kan Doxis AI.dp documenttypes classificeren, gegevens verifiëren en anonimiseren, en dat alles zonder handmatige gegevensinvoer. Out-of-the-box herkent AI.dp een breed scala aan documenten in meer dan 100 talen.
Onze oplossing is beschikbaar via API en SDK, zodat je medewerkers snel alle relevante informatie uit de database van je organisatie kunnen halen en opslaan.
Wil je je gegevens die vastzitten in onbruikbare formaten ook transformeren naar bedrijfsklare gegevens? Wij laten je graag zien hoe je dat doet met onze oplossing. Boek een gratis demo hieronder of neem contact op met een van onze experts.
FAQ
Een PDF parser is software die ongestructureerde gegevens uit PDF-bestanden automatisch omzet naar gestructureerde en machinaal leesbare formaten zoals JSON, XML of CSV. Het herkent tekst, tabellen, afbeeldingen en velden (zoals trackingnummers of QR-codes) zodat de data direct gebruikt kan worden in bedrijfsprocessen.
2. Werkt een PDF parser ook met gescande documenten?
Ja. Moderne PDF parsers zoals Doxis AI.dp gebruiken Optical Character Recognition (OCR) om tekst en andere elementen uit gescande PDF’s te herkennen. Zelfs bij complexe opmaak of lage resolutie kan de parser nauwkeurig werken, mits het document goed leesbaar is.
3. Kan een PDF parser tabellen en complexe opmaak behouden?
Ja, afhankelijk van de kwaliteit van de parser. Doxis AI.dp herkent tabellen en behoudt hun structuur, inclusief kolommen en rijen, in het geëxporteerde bestand. Dit voorkomt dat data verloren gaat of opnieuw moet worden bewerkt.
4. Hoe veilig is het verwerken van vertrouwelijke PDF’s met Doxis?
Doxis verwerkt documenten in beveiligde, AVG‑ en ISO‑gecertificeerde omgevingen. Gegevens kunnen direct worden geanonimiseerd en het platform voldoet aan alle relevante compliance-eisen zoals AVG en SOC2.
5. Hoe kan ik Doxis AI.dp in mijn systemen integreren?
Doxis biedt zowel een API als SDK die eenvoudig te koppelen zijn aan bestaande workflows of ERP‑systemen. Implementatie kan vaak dezelfde dag nog worden gestart.