
In het snelle bedrijfsleven van vandaag worstelen bedrijven van elke omvang met een enorme toestroom van gegevens. Dit omvat een breed scala aan ongestructureerde gegevens, wat verwijst naar gegevens die niet netjes georganiseerd zijn in een traditioneel gestructureerd database-formaat. Voorbeelden van ongestructureerde gegevens zijn e-mails, teksten, afbeeldingen, video’s en meer.
Recente studies suggereren dat tot 80% van deze nieuwe gegevens ongestructureerd is, wat bedrijven voor aanzienlijke uitdagingen stelt bij het effectief vastleggen, kwantificeren, verwerken en archiveren ervan. Het vermogen om essentiële informatie uit deze gegevens te halen en om te zetten in bedrijfsklare gegevens bepaalt of bedrijven een concurrentievoordeel kunnen behalen. Dit is waar file parsing om de hoek komt kijken. Maar wat is het eigenlijk?
In deze blog leggen we uit wat file parsing is, welke technologieën erachter zitten, hoe bedrijven er gebruik van kunnen maken en hoe Doxis je kan helpen file parsing te automatiseren.
Klaar? Laten we beginnen!
Wat is file parsing?
File parsing is een techniek die bedrijven gebruiken om essentiële informatie uit ongestructureerde gegevens te halen. Hierbij wordt de inhoud van bestanden, zoals tekstdocumenten of afbeeldingen, geanalyseerd om er relevante gegevenspunten uit te halen en die om te zetten in een bruikbaar formaat.

Vaak wordt file parsing door bedrijven gebruikt bij gegevensverwerking om ongestructureerde gegevens zoals PDF-bestanden om te zetten in voor bedrijven geschikte formaten zoals CSV, XML, JSON, XLMS en meer. Efficiënte en nauwkeurige file parsing speelt een belangrijke rol in veel industrieën en domeinen waar de toestroom van gegevens groot is en gegevensverwerking een kritieke taak is.
Dus hoe kunnen bedrijven informatie uit bestanden parsen? Die vraag zullen we hierna behandelen.
Hoe parse je bestanden?
Laten we aannemen dat je bedrijf PDF-bestanden ontvangt en dat je de nodige informatie daaruit in je database moet opslaan of in je computersysteem moet invoeren. Normaal gesproken wordt dit gedaan door back-office medewerkers die het PDF-bestand lezen en de informatie handmatig in het computersysteem kopiëren.
Met een file parser kun je het PDF-bestand parsen (lezen), de nodige informatie eruit halen en het binnen enkele seconden exporteren als bijvoorbeeld een JSON-bestand. Dit bestand kan dan verder worden verzonden en verwerkt in je computersysteem, zonder menselijke tussenkomst.
Dit zijn enkele veel voorkomende voorbeelden van bedrijven die file parsing gebruiken om gegevens te extraheren of de gegevens om te zetten van ongestructureerd naar gestructureerd formaat:
- Afbeeldingen converteren naar tekst om handmatige gegevensinvoer te verminderen.
- Gegevens exporteren uit PDF-bestanden naar JSON, CSV, XML en vele andere formaten.
- E-mails doorzoeken om zinvolle informatie te extraheren.
- Extractie van sleutel-waardeparen uit documenten zoals facturen en bonnetjes.
- Extractie van relevante gegevens uit identiteitsdocumenten voor onboarding van klanten.
Natuurlijk zijn er nog veel meer voorbeelden waarbij file parsing kan worden gebruikt om informatie uit ongestructureerde documenten te halen. Nu je weet waar file parsing kan worden gebruikt, laten we eens kijken naar de meest essentiële onderdelen ervan:
- Optical Character Recognition (OCR)
- Machine Learning
- Programmeertalen
OCR
Optical Character Recognition (OCR) is de meest essentiële technologie bij het parsen van bestanden, omdat het de extractie van informatie uit gescande afbeeldingen of documenten mogelijk maakt. File parsers gebruiken OCR-technologie om afbeeldingen om te zetten in tekst die door machines kan worden gelezen. Deze geconverteerde tekst wordt vervolgens verwerkt, geanalyseerd en omgezet in gestructureerde gegevens voor verder gebruik.
Stel je je eens voor dat je talloze gescande facturen moet verwerken en alle relevante informatie handmatig moet invoeren in een ERP- of boekhoudsysteem. Dat kan tijdrovend en foutgevoelig zijn. Met OCR kan deze handmatige inspanning achterwege blijven omdat het tekst uit gescande documenten kan halen.
OCR kan echter meer informatie verzamelen dan vanuit zakelijk oogpunt nodig is. Dit is waar file parsers een verschil maken, aangezien zij de gegevens kunnen lezen en interpreteren, en een gestructureerd bestandsformaat produceren dat alleen de zinvolle uitvoer bevat voor verder gebruik.
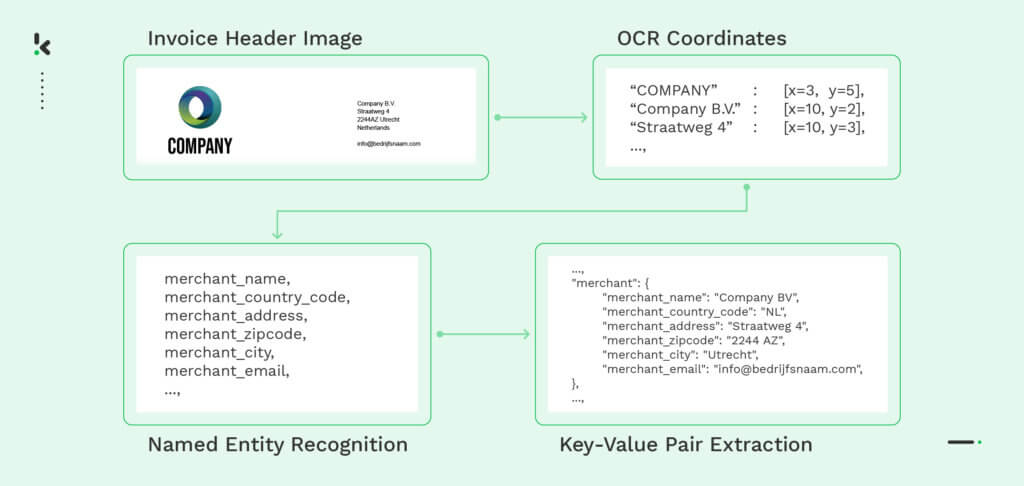
Het volgende voorbeeld laat zien hoe een OCR-gebaseerde file parser informatie uit een afbeelding van een factuur haalt. Eerst wordt de factuur gedigitaliseerd met behulp van OCR, en vervolgens worden de nodige gegevensvelden, zoals de naam en het adres van de handelaar, geïdentificeerd met behulp van Named-Entity-Recognition (NER). Ten slotte extraheert de parser de informatie in key-value pairs die kunnen worden omgezet in een machinaal leesbaar formaat, zoals JSON. Dit proces maakt een efficiënte en nauwkeurige data extractie uit verschillende bestandsformaten mogelijk.
Machine Learning
Algoritmen op basis van Machine Learning, een onderdeel van kunstmatige intelligentie (AI), worden gebruikt om de mogelijkheden van file parsers op verschillende manieren te verbeteren. Machine Learning-algoritmen kunnen bijvoorbeeld worden getraind om specifieke informatie of patronen uit documenten te herkennen voor data extractie.
File parsers zonder Machine Learning kunnen moeite hebben met nauwkeurige data extractie in complexe gevallen. In dergelijke gevallen kunnen algoritmen voor spellingcontrole, data validatie of gegevensopschoning worden gebruikt om fouten in de parsing gegevens, zoals spelfouten, ontbrekende waarden of inconsistente gegevensformaten, op te sporen en te corrigeren. De integratie van Machine Learning in parsers verhoogt de nauwkeurigheid en de prestaties bij data extractie en file parsing.
Programmeertalen
Er zijn verschillende programmeertalen die ingebouwde of externe bibliotheken en functies bieden waarmee ontwikkelaars parsers kunnen bouwen om informatie die is opgeslagen in bestanden met specifieke formaten of gegevensstructuren te extraheren en te transformeren.
Enkele populaire programmeertalen voor file parsers zijn:
- Python
- Java
- JavaScript
- Golang
- Ruby
Python is een veelzijdige programmeertaal die bekend staat om zijn eenvoud en leesbaarheid. Het heeft een rijk ecosysteem van bibliotheken, zoals CSV, JSON, XML en binaire file parsers, die het gemakkelijk maken om bestanden in verschillende formaten te parsen en te manipuleren.
Java, een populaire programmeertaal, staat bekend om zijn platform-onafhankelijkheid en robuuste ondersteuning voor objectgeoriënteerd programmeren. Het biedt een groot aantal bibliotheken die uitgebreide mogelijkheden bieden voor het parsen van bestanden; Apache POI voor Microsoft Office-bestanden, Jackson voor JSON-bestanden, en JAXB voor XML-bestanden. Dankzij deze bibliotheken is Java een veelzijdige keuze voor het parsen van bestanden.
JavaScript is een populaire scripttaal die vooral wordt gebruikt voor web ontwikkeling. Het heeft ingebouwde JSON parsing mogelijkheden, en ook uitgebreide bibliotheken die file parsing functionaliteit mogelijk maken; PapaParse voor CSV-parsing en xml2js voor XML-parsing.
Go, ook wel bekend als Golang, is een statisch getypeerde en gecompileerde programmeertaal ontwikkeld door Google. Go heeft standaardbibliotheken die robuuste mogelijkheden voor file parsing bieden; encoding/csv voor CSV-parsing, encoding/json voor JSON-parsing, en encoding/xml voor XML-parsing.
Ruby is een dynamische, objectgeoriënteerde programmeertaal die bekend staat om zijn elegante syntaxis en gebruiksgemak. Het heeft ingebouwde ondersteuning voor het parsen van tekstbestanden, en heeft ook bibliotheken; CSV voor CSV-parsing, Nokogiri voor XML- en HTML-parsing, en JSON voor JSON-parsing.
Dit zijn enkele voorbeelden van de vele programmeertalen die gebruikt kunnen worden voor het maken van file parsers. Zoals je misschien al begrepen hebt, hangt de keuze van een programmeertaal af van de specifieke behoeften van het te parsen bestandsformaat, prestatieoverwegingen en vertrouwdheid met de taal.
Niettemin maakt de wijdverbreide veelzijdigheid van Python het een zeer populaire programmeertaal op het gebied van file parsing. In de volgende paragrafen gaan we dieper in op hoe Python wordt gebruikt om gegevens uit bestanden te parsen.
Parsen in Python
Zoals gezegd is Python een van de populairste keuzes als file parsing programmeertaal. Dit komt niet alleen door zijn veelzijdigheid, maar ook door het gebruiksgemak en de ruime beschikbaarheid van bibliotheken en modules. Dankzij de robuuste mogelijkheden van Python om tekenreeksen te manipuleren, is Python de aangewezen taal geworden voor het parsen van verschillende soorten bestanden, waaronder tekst, CSV, XML, JSON en meer.
Een van de belangrijkste voordelen van Python voor parsing-taken is het uitgebreide ecosysteem van bibliotheken. Python biedt een rijke verzameling ingebouwde modules voor bestandsbewerkingen, reguliere expressies en tekenreeks-manipulatie, wat parsing-taken eenvoudig en efficiënt maakt. Daarnaast zijn er tal van bibliotheken van derden die gespecialiseerde functies bieden om specifieke bestandsformaten te parsen.
Bovendien is Python door zijn begrijpelijke syntaxis een gebruiksvriendelijke taal voor het parsen van bestanden. Met de juiste infrastructuur kun je met Python parsing snel gegevens uit bestanden met complexe structuren halen, manipuleren en valideren. De multiprocessing-mogelijkheden van Python stellen ontwikkelaars ook in staat om parallelle parsing-taken uit te voeren, wat de prestaties en schaalbaarheid ten goede komt.
Dus als je je eigen parser wilt bouwen, is Python onze aanbevolen programmeertaal. Zelf een Python-parser bouwen kan echter veel middelen (tijd en geld) vergen en uitgebreide programmeerkennis, waarover je organisatie misschien niet beschikt. Daarom hebben we in de volgende sectie enkele oplossingen opgesomd waarvoor je geen eigen parsers hoeft te bouwen!
Geautomatiseerde informatie parsing uit bestanden
Bedrijven die menselijke inspanningen, tijd en kosten willen verminderen, kunnen het zich niet langer veroorloven om handmatig informatie uit bestanden te halen en in een computersysteem in te voeren. Dit gezegd hebbende, zijn er manieren voor bedrijven om het parsen van bestanden te automatiseren met behulp van verschillende technologieën. Hier volgen enkele opties:
- AI-ingebedde OCR-software
- Webtoepassingen
- Robots en Bots
AI-gebaseerde OCR-software
Optical Character Recognition (OCR) software maakt het mogelijk documenten te scannen en tekst te extraheren naar een machinaal leesbaar formaat. Om het parsen van bestanden te automatiseren, is het echter vaak nodig om gebruik te maken van OCR-software met AI. Met een dergelijke oplossing kunnen bedrijven een gestroomlijnde workflow opbouwen om automatisch informatie te ontleden uit bestanden zoals facturen, ontvangstbewijzen, identiteitskaarten, paspoorten, rijbewijzen, formulieren en vele andere.
AI kan op vele manieren helpen, niet alleen bij het parsen, maar ook bij het verifiëren van de authenticiteit van een document, het opsporen van fraude of het maskeren van gevoelige gegevens. Daarom is het voor bedrijven voordeliger om OCR-software in de cloud te integreren dan zelf een eenvoudige parser met veel beperkingen te ontwikkelen met behulp van Python of andere programmeertalen.
Webapplicaties
Er zijn verschillende webapplicaties en online tools beschikbaar voor bedrijven om gratis bestanden te parsen. Sommige tools kunnen automatisch gegevens ontleden uit bestanden zoals PDF’s, CSV’s, Excel-spreadsheets en andere gangbare bestandsformaten. Vaak kunnen gebruikers hun bestanden uploaden naar deze web-toepassingen, die vervolgens algoritmen gebruiken om de relevante gegevens te extraheren en om te zetten in een bruikbaar formaat. Bekijk bijvoorbeeld onze gratis image-to-text converter!
Het is belangrijk dat je je bewust bent van de beperkingen van deze hulpmiddelen. Ze kunnen nuttig zijn voor kleine hoeveelheden bestanden, maar er zijn beperkingen aan het aantal bestanden dat met een gratis account kan worden verwerkt, en de kosten kunnen snel oplopen. De privacy van gegevens is ook een belangrijk punt van zorg. Geven deze gratis online tools echt prioriteit aan de veiligheid van gebruikersgegevens, of zijn ze er vooral op uit om snel geld te verdienen? Hoewel het verstandig kan zijn om niet alleen op deze tools te vertrouwen, kan het toch de moeite waard zijn om het als optie te onderzoeken.
Robots en bots
Robots en Bots, in de context van Robotic Process Automation (RPA), zijn softwareprogramma’s die kunnen worden gebruikt voor het automatisch parsen van gegevens uit bestanden. Bij RPA zorgen robots of bots voor de automatisering van handmatige taken, waardoor menselijke tussenkomst overbodig wordt.
Een van de belangrijkste voordelen van het gebruik van RPA-robots voor het parsen van gegevens uit bestanden is hun hoge mate van nauwkeurigheid en efficiëntie. RPA-robots kunnen 24/7 werken zonder menselijke tussenkomst, waardoor het risico op fouten als gevolg van handmatige gegevensinvoer afneemt en de productiviteit toeneemt. Bovendien kunnen ze moeiteloos verbinding maken met diverse gegevensbronnen, API’s en integraties van derden, wat een aanzienlijk voordeel oplevert bij het verzamelen en verwerken van gegevens voor parsing op verschillende manieren.
File parsing met Doxis AI.dp
De toekomstbestendige AI-aangedreven OCR-software Doxis AI.dp dient verschillende bedrijven bij het automatiseren van documentverwerkingsworkflows, waaronder bestandsparsing. Het is een krachtige en veelzijdige file parsing oplossing die bedrijven in staat stelt om efficiënt waardevolle gegevens uit verschillende bestandsformaten te halen.
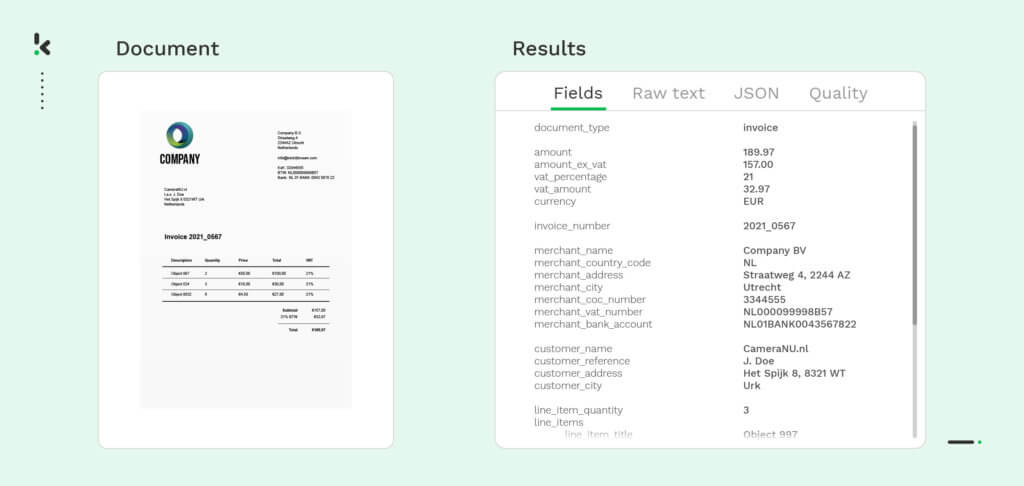
Naast bestandsontleding kan AI.dp de authenticiteit van een document verifiëren, frauduleuze documenten detecteren, documenten classificeren en gevoelige gegevens automatisch maskeren, waardoor je document-workflow toekomstbestendig wordt. Je kunt AI.dp integreren in je bestaande workflow of softwaresystemen met behulp van onze API.
Als je je huidige mobiele toepassingen wilt uitbreiden met OCR- of file parsing functies, kun je ook onze SDK’s voor mobiel scannen bekijken. Onze oplossingen bieden tal van voordelen, waaronder:
- Tot 99% data extractie met in-house AI-aangedreven OCR.
- Schaalbaarheid die je verbeelding te boven gaat.
- Lagere overheadkosten dankzij automatisering.
- Minimale fouten bij data invoer.
- Naleving van regels met betrekking tot data privacy, omdat de verwerkte gegevens niet worden opgeslagen op de servers van Doxis.
Klaar om je ongestructureerde gegevens om te zetten in bruikbare informatie? Plan een gratis demo via onderstaand formulier of neem contact op met een van onze experts voor informatie!