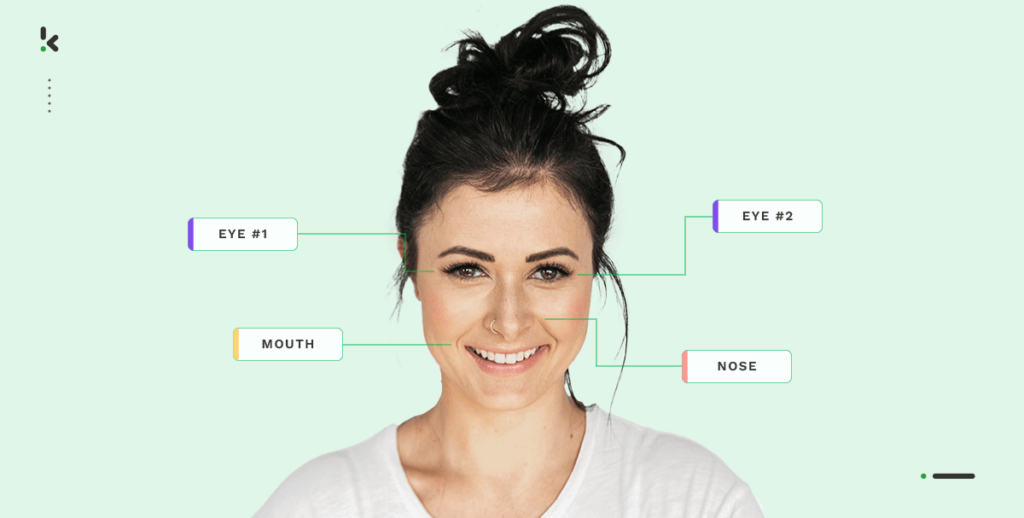
Kunstmatige intelligentie, ook wel Artificial Intelligence (AI) genoemd, en Machine Learning (ML) zijn snelgroeiende technologieën waarmee we ongelooflijke dingen kunnen maken. Denk aan een zelfrijdende auto of de face-ID ontgrendeling van je smartphone. Heb je er ooit over nagedacht hoe dat precies werkt?
Voordat een machine de beslissing kan nemen om niet tegen een boom te rijden, moet hij getraind worden om specifieke informatie te begrijpen. Om dergelijke geautomatiseerde machines en toepassingen te ontwikkelen, is een enorme hoeveelheid trainingsgegevens nodig. Bedrijven kunnen trainingsgegevens kopen of een deskundig team van zogenaamde data annoteurs inhuren die met onbewerkte datasets kunnen werken.
In het algemeen is data annotatie een complex en duur proces dat door deskundigen moet worden uitgevoerd om tot een bevredigend resultaat te komen.
Veel bedrijven die zich bezighouden met AI worstelen met data annotatie en weten niet waar ze moeten beginnen. Daarom zullen we in deze blog uitleggen wat data annotatie is, welke data annotatie methoden beschikbaar zijn en vervolgens zullen we bespreken waarom data annotatie tegenwoordig zo noodzakelijk is.
Laten we beginnen!
Wat is data annotatie?
Kort gezegd is data annotatie het proces waarbij gegevens in een video, afbeelding of tekst worden gelabeld. De gegevens worden gelabeld zodat modellen een bepaalde gegevensbron gemakkelijk kunnen begrijpen en in de toekomst bepaalde formaten, objecten, informatie of patronen kunnen herkennen.
Om het model de gepresenteerde afbeeldingen, video’s en andere formaten te laten begrijpen en begrijpen, maakt het gebruik van Computer Vision. Computer Vision is een deelgebied van de kunstmatige intelligentie (AI) dat software en computers in staat stelt digitale visuele invoer te observeren en te begrijpen. Maar wat heeft dat met data annotatie te maken?
Om Computer Vision objecten, patronen of andere informatie te leren herkennen, moeten gegevens nauwkeurig worden geannoteerd of, in meer technische termen, worden voorzien van een Machine Learning model. Dit wordt bereikt door gebruik te maken van een aantal methoden en hulpmiddelen.
In het algemeen bestaat de procedure uit twee stappen, ongeacht of de annotatie handmatig of automatisch gebeurt:
- Labelen van gegevens
- Kwaliteitscontroles en audits
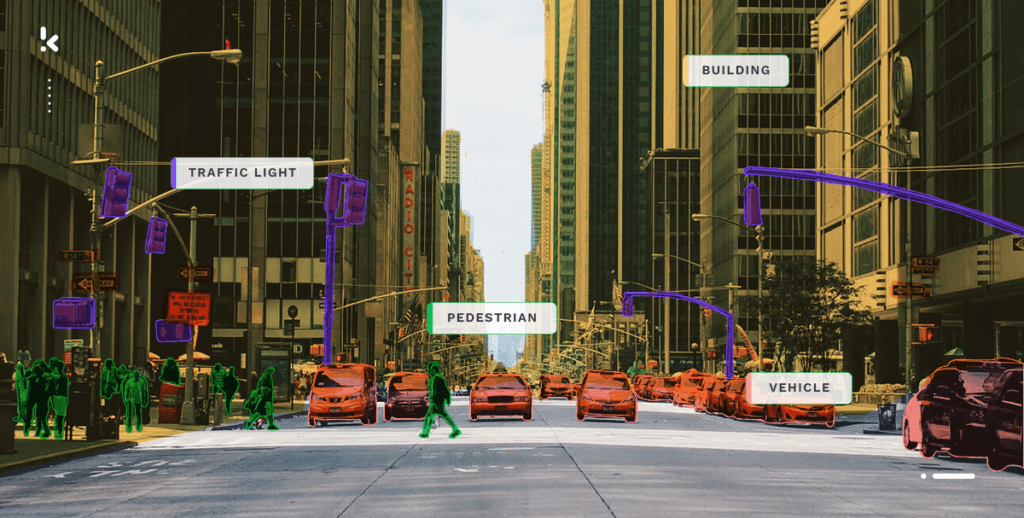
De eerste stap van data annotatie is het labelen van gegevens van afbeeldingen, video’s of tekst. In deze context betekent gegevenslabeling het toevoegen van één of meer informatieve labels aan ruwe gegevens om context te bieden, zodat een model voor Machine Learning ervan kan leren. In de onderstaande afbeelding worden bijvoorbeeld verkeerslichten, voetgangers, voertuigen en gebouwen gelabeld om het model te laten begrijpen wat het zijn.
De tweede stap begint nadat de gegevens zijn gelabeld. Hier wordt de geannoteerde dataset gecontroleerd op echtheid en precisie. Deze stap is ontzettend belangrijk, want als het opgestelde model getraind wordt met onjuiste gegevens, kan dat leiden tot kostbare hertraining.
Nu we een algemeen idee hebben over wat data annotatie is, willen we de verschillende soorten annotatie verder toelichten.
Verschillende vormen van data annotatie
Zoals eerder vermeld kan het proces van data annotatie worden toegepast op verschillende soorten lay-outs. Dit betekent dat verschillende data annotatie methoden worden gebruikt. Met het oog op de leesbaarheid van de blog zullen we ons concentreren op drie verschillende methoden voor data annotatie. Houd er rekening mee dat deze lijst dus niet volledig is:
- Beeldannotatie
- Video-annotatie
- Tekstannotatie
Beeldannotatie
Voor een groot aantal toepassingen zoals Computer Vision, gezichtsherkenning en oplossingen die gebruik maken van AI, maakt beeldannotatie het mogelijk om beelden te interpreteren. Voordat dit kan worden toegepast, moet het AI-model worden getraind met duizenden gelabelde beelden.
De training kan worden uitgevoerd door metadata, zoals identificaties, bijschriften en trefwoorden toe te voegen aan honderden beelden. Met effectieve training neemt de nauwkeurigheid van het AI-model toe en kan het voor tal van doeleinden worden gebruikt (zelfrijdende voertuigen, automatische identificatie van medische aandoeningen, etc.).
Binnen beeldannotatie zelf bestaan weer verschillende soorten annotatie-methoden, zoals:
- Bounding Boxes – Tekenen van een rechthoek rond het object dat je wilt annoteren in een bepaalde afbeelding. De randen van de bounding box moeten de buitenste pixels van het gelabelde beeld raken om de hoogst mogelijke nauwkeurigheid te garanderen.

- 3D Cuboids – Deze methode lijkt sterk op bounding boxes annotatie. Het enige verschil is dat de gebruiker rekening moet houden met de dieptefactor. Ze kan worden gebruikt om vlakken of auto’s op een afbeelding te annoteren.

- Polygonen – Bij het gebruik van bounding boxes of 3D-kubussen kunnen onbedoeld verschillende objecten in het geannoteerde gebied worden opgenomen. Met het polygoongereedschap kan een lijn worden getrokken rond het specifieke object in de afbeelding dat moet worden geannoteerd.

- Keypoint tool – Een object kan worden geannoteerd door een reeks punten. Dit wordt vaak gebruikt voor het detecteren van gebaren of het volgen van bewegingen.
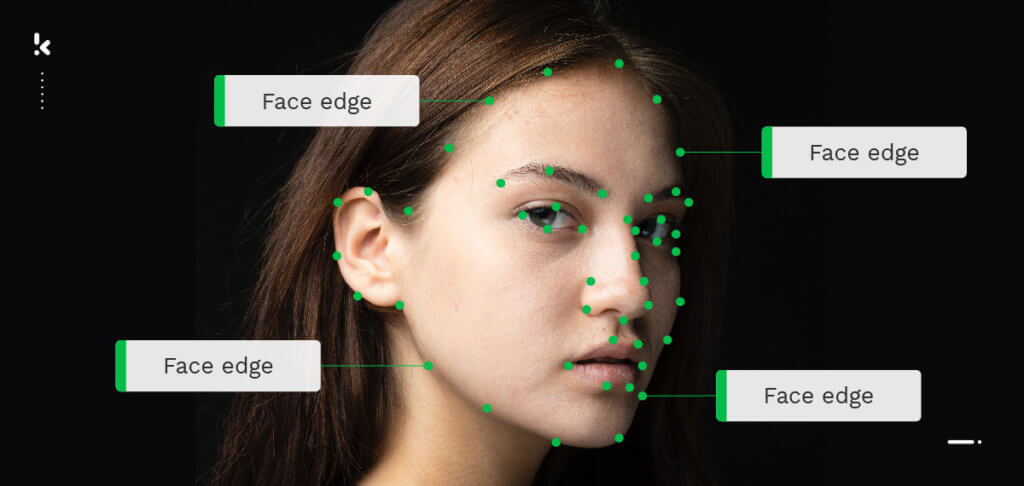
Laten we nu eens kijken naar video-annotatie.
Video-annotatie
Video-annotatie wordt frame per frame uitgevoerd om geannoteerde objecten herkenbaar te maken voor modellen voor Machine Learning. In het algemeen worden dezelfde technieken gebruikt als bij beeldannotatie om de gewenste objecten te detecteren of te identificeren.
Deze annotatie methode is een essentiële techniek voor Computer Vision taken zoals lokalisatie en object tracking, waarbij een algoritme de beweging van een object kan volgen. Daarom is video-annotatie nuttig voor verschillende industrieën, zoals de medische sector, productie en verkeersmanagement.
Als laatste type data annotatie willen we het hebben over tekstannotatie. Tekst is de meest gebruikte gegevenscategorie, omdat de meeste bedrijven in diverse bedrijfsprocessen sterk afhankelijk zijn van tekst.
Tekstannotatie
Tekstannotatie verwijst naar het toevoegen van metadata of labels aan stukken tekst. Laten we eens bekijken wat dat betekent.
Metadata toevoegen
Metadata toevoegen betekent relevante informatie verstrekken aan het algoritme. Zo kan het prioriteiten stellen en zich richten op bepaalde woorden.
Voorbeeld: “Hier is de factuur (document_type) voor de nieuwe computer (bestelling) die je gisteren (tijdstip) hebt besteld.”
De tussen haakjes toegevoegde metadata levert de relevante informatie aan het algoritme, zodat het in de toekomst de informatie kan detecteren waarvoor het is getraind.
Labels toevoegen
Door labels toe te voegen, kunnen woorden aan een zin worden toegekend die het type ervan beschrijven. Een zin kan bijvoorbeeld worden beschreven met sentimenten.
Voorbeeld: “Het product voldoet niet aan mijn wensen, ik wil het terugsturen.” Hier zou het label “ongelukkig” kunnen worden toegekend.

Dit helpt het algoritme het sentiment en de bedoeling van een tekst te begrijpen en is nauw verwant met named entity recognition. Laten we eens kijken waarom dat zo is.
Named Entity Recognition
Named Entity Recognition (NER) wordt gebruikt om woorden te zoeken op basis van hun betekenis. Het is bedoeld om vooraf gedefinieerde benoemde entiteiten en uitdrukkingen in een zin op te sporen. In het algemeen is NER nuttig bij het extraheren, classificeren en categoriseren van informatie.
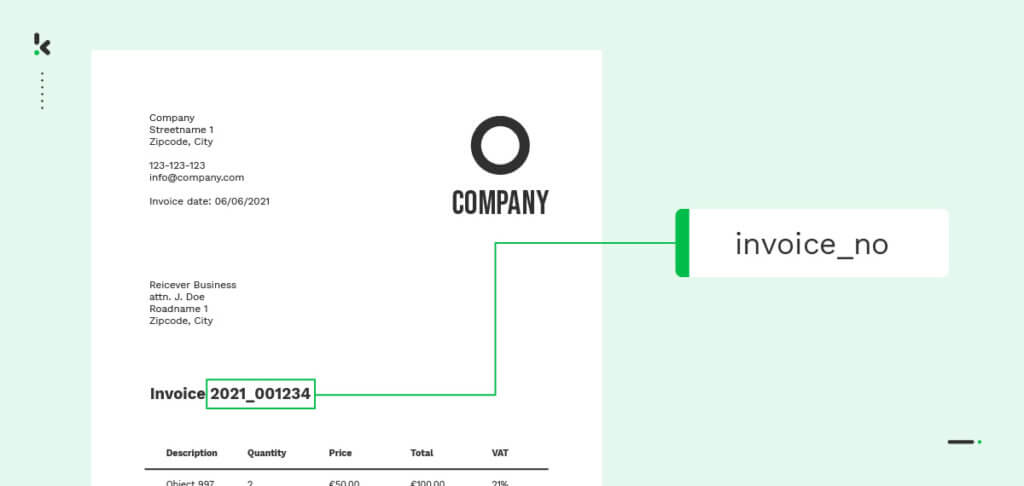
Kijk eens naar het voorbeeld van een factuur. Door het model te trainen op het woord “factuurnummer” plus de kenmerken van een factuurnummer (bv. het aantal cijfers) kan het het document classificeren als een factuur. Hetzelfde werkt voor verschillende woorden op verschillende documenten, wat betekent dat je de Named Entity Recognition-methode kunt gebruiken om verschillende documenten te classificeren op basis van gegevensvelden.
Bovendien kan een AI-algoritme specifiek worden getraind om het sentiment en de intentie van een zin te begrijpen, omdat dit zeer belangrijk is om menselijk gedrag te begrijpen. Laten we eens kijken wat dat betekent.
Sentiment annotatie
Zoals eerder vermeld wordt sentiment annotatie uitgevoerd door labels toe te kennen aan tekst die menselijke emoties weergeven. Daarbij worden labels gebruikt als verdrietig, blij, gefrustreerd of boos. Vervolgens kan het worden gebruikt voor sentimentanalyses in bijvoorbeeld de detailhandel om inzicht te krijgen in de klanttevredenheid.
Intentie-annotatie
Intentie-annotatie betekent in feite dat labels worden toegekend aan zinnen die een bepaalde intentie of behoefte uitdrukken. Dit kan zeer nuttig zijn voor bijvoorbeeld klantenservice.
Laten we een chatbot als voorbeeld nemen. Wanneer een klant de zin “Ik heb problemen met betalen met mijn creditcard” indient, kan de persoon onmiddellijk worden doorverwezen naar het financiële team.
Dit is mogelijk omdat het algoritme is getraind met honderden zinnen met een soortgelijke behoefte.
Woorden als “problemen” drukken een ‘emotie’ of ‘sentiment’ van de klant uit. Bovendien werden woorden als “creditcard” eerder gelabeld als ‘betaalmethode’ of soortgelijke labels, waardoor het algoritme de klant naar de financiële afdeling kan leiden.
Voordat we uitleggen waarom jij data annotatie nodig hebt, willen we dieper ingaan op het verschil tussen geautomatiseerde data annotatie en handmatige data annotatie.
Geautomatiseerde data annotatie vs handmatige data annotatie
Bij handmatige data annotatie, zoals de naam al suggereert, zijn er mensen betrokken en werkt het als volgt:
- De data annoteur wordt voorzien van ruwe datasets voor annotatie;
- Op basis van de specificaties en het gewenste resultaat weet de annoteur welke methode hij moet gebruiken om de relevante elementen te annoteren;
- De annotatie-expert labelt alle vereiste elementen handmatig;
- Daarna is de dataset klaar voor gebruik om een model te trainen.
Het annoteren van één afbeelding kan tot 15 minuten duren, afhankelijk van de kwaliteit van het verstrekte document, de annotatietool en de vereisten. Stel dat je een project hebt met tot 50.000 afbeeldingen. Dit betekent dat een deskundige annoteur 12.500 uur besteedt aan het annoteren van deze beelden. Dat moet beter kunnen!
Geautomatiseerde data annotatie
Om de weg vrij te maken voor snellere data annotatie worden modellen voor automatische data labeling steeds prominenter. Bij automatische data labeling nemen AI-systemen het proces van data annotatie voor hun rekening.
Dit werkt op basis van vooraf gedefinieerde regels en voorwaarden die door mensen zijn ingesteld. Een dataset wordt door deze vooraf gedefinieerde regels gehaald om een specifiek label te valideren. Hoewel dit efficiënter is, is er nog steeds een probleem. Zodra gegevensstructuren vaak veranderen, wordt het moeilijk om voorwaarden en regels op te stellen, waardoor het voor een model bijna onmogelijk wordt om een geïnformeerde beslissing te nemen.
Daarom zal een gecombineerde inspanning van menselijke en kunstmatige intelligentie waarschijnlijk het best mogelijke resultaat opleveren. Met de hulp van human-in-the-loop worden de resultaten van het AI-model consequent gevalideerd, geverifieerd en geoptimaliseerd, terwijl het model zorgt voor het labelen van de gegevens.
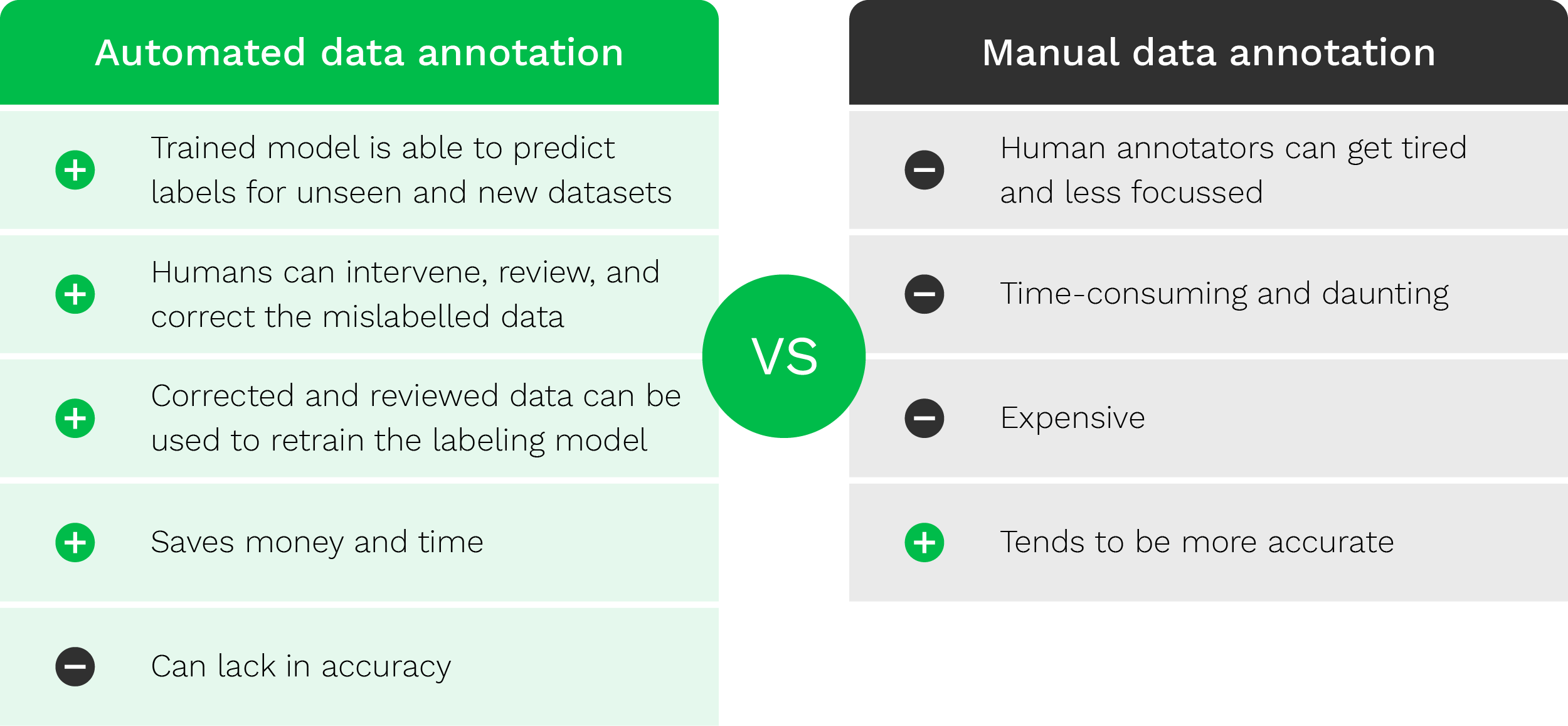
Om een snel overzicht te geven van het verschil tussen geautomatiseerde en handmatige data annotatie, geven we de onderstaande tabel.
Maar waarom zou je je hier eigenlijk druk om maken? Nou, er zijn een paar redenen waarom data annotatie nodig is. Laten we eens kijken!
Waarom heb je data annotatie nodig?
Onze steeds groeiende behoefte aan innovatie maakt annotatie van data noodzakelijk. Hoe kan een auto anders ooit zelf rijden? Zonder data annotatie zou elk beeld hetzelfde zijn voor een machine, omdat het geen kennis heeft over iets in de wereld.
Dat betekent dat zonder training van het model van wat een voertuig, de straat, het trottoir of een voetganger is, de zelfrijdende auto gewoon gedachteloos in zou rijden op alles wat zijn weg kruist.
Evenzo trainen veel bedrijven AI-modellen om documenttypes te identificeren om categorisatie- en data extractie processen te automatiseren. Aangezien veel bedrijven te maken hebben met leveranciers, nemen we facturen als voorbeeld. Om het model het documenttype correct te laten categoriseren, worden de kenmerken van een factuur eerst gelabeld en vervolgens aan het algoritme voorgeschoteld.
Dit is niet beperkt tot facturen en kan worden toegepast op elk type document. Voor jou betekent dit dat al jouw document gerelateerde workflows kunnen worden geoptimaliseerd en dat je team niet langer zelf documenten hoeft te identificeren en categoriseren.
Laten we, met dat in gedachten, eens snel kijken naar de belangrijkste voordelen van data annotatie.
De voordelen van data annotatie
Naast tijd- en geldbesparing heeft data annotatie nog een aantal andere voordelen. Deze voordelen zijn
- Hogere efficiëntie – Door gegevens te labelen kunnen Machine Learning systemen beter worden getraind, waardoor ze efficiënter worden in het herkennen van objecten, woorden, sentiment, intentie, enz.
- Een hogere mate van precisie – Correcte data labeling leidt tot nauwkeurigere gegevens om een algoritme te trainen. En dit zal in de toekomst leiden tot een hogere nauwkeurigheid van data extractie.
- Minder tussenkomst van mensen – Hoe beter de data annotatie, hoe beter de output van het AI-model. Nauwkeurige output van het algoritme betekent dat er minder menselijke interventie nodig is, wat de kosten drukt en tijd bespaart.
- Schaalbaarheid – Dit geldt voor geautomatiseerde data annotatie, waardoor je data annotatie projecten kunt schalen om AI- en ML-modellen te verbeteren.
Naast voordelen komt elke oplossing met zijn beperkingen. Daarom is het, om het grotere plaatje te begrijpen, belangrijk om die hierna te bespreken.
De beperkingen van data annotatie
Hoewel data annotatie essentieel is voor het trainen van AI- en ML-modellen, heeft het ook zijn beperkingen. Laten we kijken welke dat zijn:
- AI- en ML-modellen hebben een enorme hoeveelheid gelabelde gegevens nodig om te leren. Daarom moeten bedrijven veel arbeidskrachten inhuren die deze gelabelde gegevens kunnen genereren. Dat is niet alleen duur, maar beperkt ook de efficiëntie en productiviteit van die bedrijven.
- Vaak hebben bedrijven beperkte toegang tot goede hulpmiddelen en technologie die het precieze proces van data annotatie kunnen leveren. Dat betekent dat die bedrijven blijven zitten met onnauwkeurige gegevens en een traag trainingsproces van modellen.
- ML-modellen zijn zeer gevoelig. Zelfs de kleinste fouten kunnen bedrijven veel geld kosten. Als het model wordt getraind met onnauwkeurige gegevens, zal het verkeerd leren en dus in de toekomst gegevens verkeerd voorspellen.
- Een gebrek aan proceskennis kan leiden tot het niet naleven van de richtlijnen voor gegevensbeveiliging. Bedrijven hebben vaak te maken met gevoelige gegevens, zoals de identificatie van gezichten, die met de grootst mogelijke veiligheid moeten worden behandeld. Als het labelen van gegevens verkeerd gebeurt, kunnen verkeerde informatie of kleine fouten leiden tot verschrikkelijke resultaten.
Je ziet dat data annotatie een gevoelige procedure is die kan leiden tot verkeerd getrainde AI-modellen. Als dat gebeurt, zal je zelfrijdende auto tegen een boom botsen of zelfs een onschuldige voetganger overrijden. Omdat we zeker niet willen dat dat gebeurt, is het verstandig om gebruik te maken van andere bedrijven die ervaring hebben met het annoteren van gegevens.
Klippa is één van de bedrijven die duizenden uren hebben besteed aan het annoteren van gegevens om onze op AI-gebaseerde software te verbeteren.
Wat kan Klippa voor jou doen?
Bij Klippa hebben we onze modellen getraind om bedrijven te helpen met geautomatiseerde documentverwerking. Dankzij jarenlange training van onze AI-gestuurde OCR-engine kun je er zeker van zijn dat onze software, DocHorizon, betrouwbaar en nauwkeurig werkt. Door gebruik te maken van onze oplossing kun je je de ontmoedigende taak van data annotatie besparen en toch van alle voordelen profiteren.
Klippa DocHorizon
In het algemeen kan Klippa DocHorizon elke afbeelding omzetten in tekst. Daarnaast kan deze intelligente software gegevens extraheren, classificeren en verifiëren uit allerlei soorten documenten zoals bonnen, facturen, paspoorten en ID-kaarten. Dit betekent dat je elk gegevensveld automatisch kunt extraheren en opslaan in je database.
Voordat de gegevens in je database worden opgeslagen, kan onze software voor Intelligent Document Processing (IDP) document-fraude detecteren en gevoelige gegevens maskeren om te voldoen aan wettelijke vereisten.
Als je je bestaande software wilt aanvullen of gegevens uit andere objecten dan documenten wilt halen, kunnen we jou zeker helpen!
Object Detection SDK
Onze SDK voor object-detectie kan worden getraind om alles te herkennen wat je nodig hebt. Van een elektriciteitsmeter tot een factuur, met voldoende gelabelde datasets kan ons data annotatie team klanten helpen ons object-detectie model te trainen om elk gewenst object te herkennen.
Dit betekent dat jij jouw team een oplossing kunt bieden die betrouwbaar is en waarmee je gegevens kunt vastleggen met behulp van mobiele telefoons.

Ben je nieuwsgierig naar onze oplossing en wil je meer zien? Laat ons demonstreren hoe onze software werkt! Plan een gratis demo hieronder of neem contact op met een van onze experts voor meer informatie.