
Digitalisering zit in de lift en veel bedrijven zijn op zoek naar betere manieren om documenten te verwerken en op te slaan. Traditionele archieven worden verplaatst naar de cloud en meer documenten worden digitaal verwerkt.
Hoewel digitalisering fantastische voordelen heeft, zijn er ook uitdagingen om rekening mee te houden. De belangrijkste is het voldoen aan de strenge General Data Privacy Regulations (GDPR), het Nederlandse AVG, die in mei 2018 zijn opgelegd.
Hoewel deze verordeningen de bescherming van gegevens verbeteren en de verantwoordelijkheden van organisaties verduidelijken, voorkomen ze datalekken niet helemaal.
De kosten als gevolg van datalekken zijn gestegen van $3,86 miljoen naar $4,24 miljoen. Dit zijn gemiddeld gezien de hoogst geregistreerde totale kosten in de afgelopen 17 jaar.
Aangezien cybercriminelen steeds geraffineerder worden, moeten bedrijven oplossingen vinden om de opgeslagen gegevens beter te beschermen. Een uitstekende oplossing is het afschermen van gegevens om zo de risico’s op gegevensinbreuk te minimaliseren en AVG naleving te garanderen.
Deze blog gaat over wat data masking is, hoe het werkt, en over hoe Klippa data-afscherming voor jou kan automatiseren.
Wat is data masking?
Data masking, ook wel bekend als data-anonimisering, is een beveiligingstechniek om gevoelige gegevens te maskeren. Dergelijke gegevens zijn bijvoorbeeld burgerservicenummers of rekeningnummers.
Het maskeren van gegevens wordt toegepast om te voorkomen dat de gegevens worden blootgelegd en om de beveiligingsrisico’s te verminderen, terwijl tegelijkertijd aan de regelgeving omtrent gegevensbescherming wordt voldaan.
Veel organisaties moeten bijvoorbeeld Know Your Customer (KYC) controles uitvoeren bij de aanname van nieuwe klanten. Bij het uitvoeren van deze controles om de identiteit van klanten te valideren, moeten organisaties identiteitsdocumenten verwerken.
Sommige informatie, zoals burgerservicenummers, kan echter niet worden opgeslagen onder de AVG. Hoewel er uitzonderingen zijn, moet de meerderheid van de organisaties de gegevens anonimiseren of verduisteren om de naleving te waarborgen.
Momenteel wint het maskeren van data steeds meer terrein en de sector zal naar schatting groeien van $483,90 miljoen in 2020 tot $1044,93 miljoen in 2026.
Soorten gevoelige gegevens
Data masking kan worden gebruikt om vele soorten gegevens te beschermen. De meest voorkomende soorten zijn:
- Persoonlijk identificeerbare informatie (PII)
- Beschermde gezondheidsinformatie (PHI)
- Informatie over betaalkaarten (PCI-DSS)
- Health Insurance Portability and Accountability Act (HIPAA)
Het is van essentieel belang om te weten hoe gegevensafscherming werkt en welke soorten en technieken geschikt zijn voor jouw bedrijfsdoeleinden. Alleen dan wordt het gemakkelijker om gegevensafscherming te gebruiken om privacygevoelige gegevens te beschermen.
Laten we eens kijken hoe data-afscherming werkt.
Hoe werkt data masking?
Het begint bij het identificeren van alle gevoelige gegevens die je organisatie bezit of verwerkt. Het is essentieel om in gedachten te houden dat gegevens in vele vormen voorkomen; e-mails, fax, excel sheets, database informatie, en gescande documenten zoals paspoorten.
Zodra de identificatie van gegevens is voltooid, moeten algoritmen en anonimiseringstechnieken worden toegepast. Organisaties kunnen gevoelige gegevens verwijderen, zwart maken, vervangen, of versleutelen, afhankelijk van het gebruik en de wettelijke vereisten.
Laten we als voorbeeld een excel sheet met klantgegevens nemen, inclusief gevoelige informatie zoals bankrekeningnummers. Bij het bewaren van dit soort informatie kan gegevensafscherming de veiligheid van je gegevens vergroten.
In plaats van gevoelige gegevens zichtbaar te laten, kunnen de bankrekeningnummers bijvoorbeeld worden vervangen door een “x” en worden alleen de laatste vier cijfers getoond.
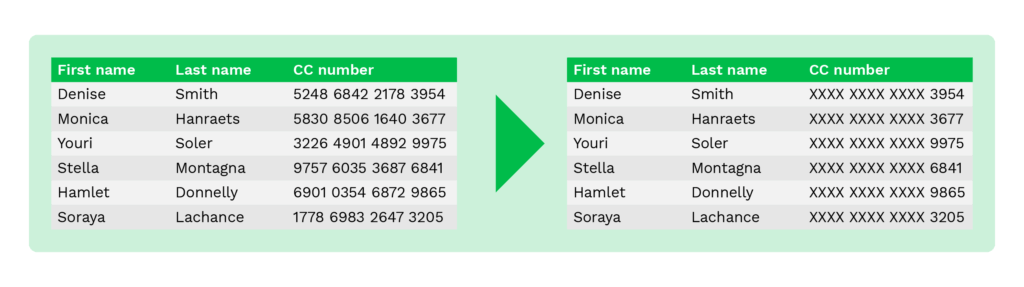
Zelfs als alleen de laatste vier cijfers worden getoond, kan personeel de bankrekening nog steeds verifiëren. Op die manier kunnen fraudeurs het bankrekeningnummer niet gebruiken, ook al zouden ze de informatie in handen krijgen.
Een ander voorbeeld is het maskeren van informatie op de scan van een identiteitsdocument uit een KYC-proces. Hieronder zie je een een voor en na afbeelding van een gemaskeerd paspoort om AVG-naleving te garanderen.
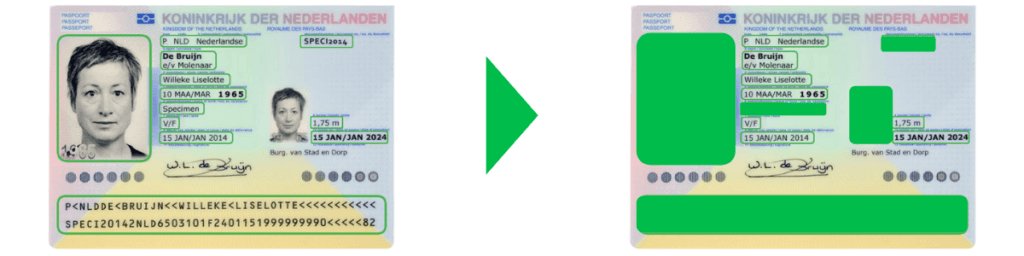
Een soortgelijke aanpak voor het maskeren van gegevens kan worden toegepast op verzekeringsnummers, rekeningnummers, burgerservicenummers, of dergelijken.
Nu we hebben uitgelegd hoe het maskeren van gegevens werkt, laten we eens kijken naar de twee verschillende soorten van data anonimisering.
Data masking soorten
Er zijn verschillende data masking soorten en het gebruik ervan hangt vooral af van de middelen, gebruikssituaties en aanbieders. De meest gebruikte soorten data masking zijn statische en dynamische data masking.
In het volgende gedeelte wordt het verschil tussen de twee verder besproken.
Statische data masking
Static Data Masking (SDM) wordt vaak gebruikt voor het testen van software om gevoelige gegevens te vervangen door gegevens te wijzigen die zijn opgeslagen op een laptop, harde schijf of in een database. Met statische data-afscherming kunnen organisaties voldoen aan gegevens- en privacyvoorschriften zoals AVG, PCI, PHI, PII, ITAR, en HIPAA.
Deze vorm van data masking begint met de originele kopie, waaruit de gevoelige gegevens worden gemaskeerd voordat ze verder worden gestuurd voor verwerking.
Met deze aanpak wordt gevoelige informatie permanent vervangen om de naleving van de regelgeving, met betrekking tot gegevensprivacy en bescherming tegen gegevensinbreuken, te waarborgen.
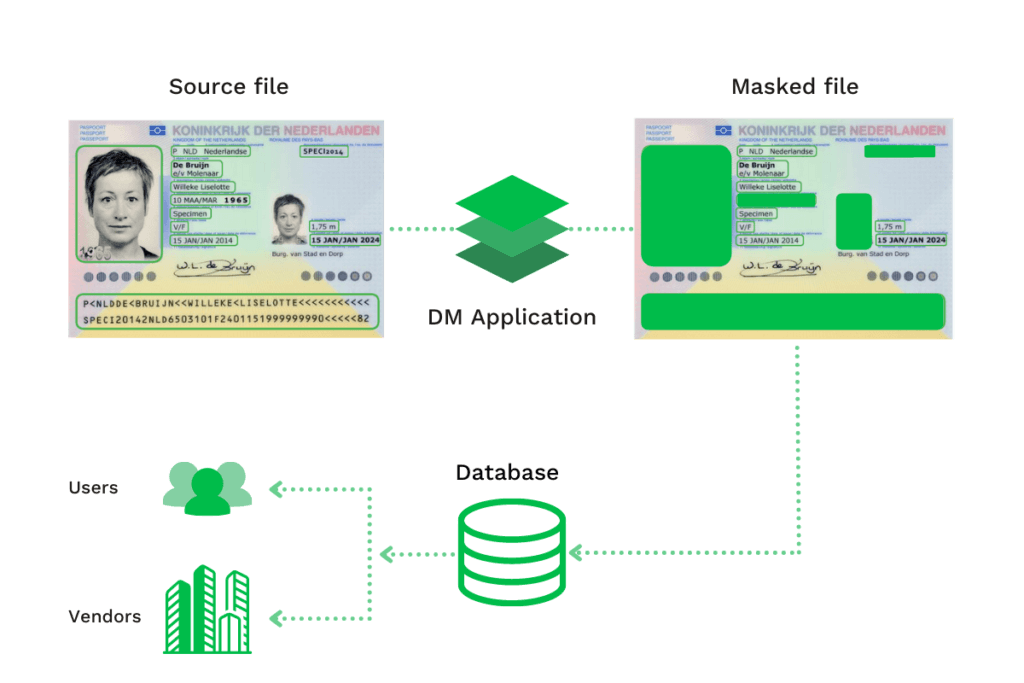
Dynamische data masking
Dynamic Data Masking (DDM) is anders dan de statische vorm. DDM wordt gebruikt om actief gebruikte gevoelige gegevens te maskeren, waarbij de oorspronkelijke kopie ongewijzigd blijft. Bij deze aanpak zijn de ongemaskeerde gegevens zichtbaar in de database.
DDM wordt voornamelijk gebruikt om vragen van klanten te verwerken en medische dossiers binnen beveiligingstoepassingen te behandelen. Het verbergen van gevoelige gegevens voor specifieke gebruikers is voor sommige bedrijfstakken noodzakelijk.
Met DDM kunnen organisaties gewijzigde vraagstellingen, zoals verzoeken om gegevens, die bij de oorspronkelijke database binnenkomen gebruiken om de gegevens dynamisch te maskeren en door te geven aan de partij die erom vraagt.
Dit type van data anonimiseren wordt vaak gebruikt wanneer organisaties gegevens naar een derde partij of naar interne belanghebbenden sturen, die geen toestemming hebben om gevoelige gegevens te zien. Dergelijke gegevens kunnen burgerservicenummers of rekeningnummers zijn.
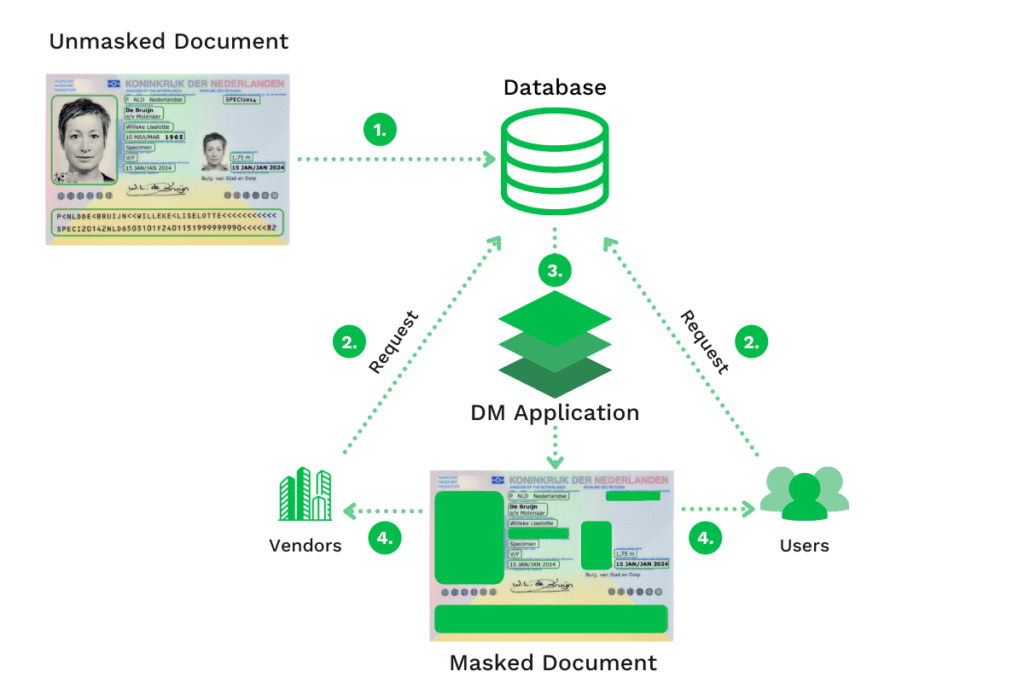
Nu we de meest gebruikte soorten van data anonimiseren hebben doorgenomen, laten we gaan kijken naar de technieken die erachter zitten.
Data-afschermingstechnieken
Data masking wordt gedaan met verschillende technieken, die hieronder uitgelegd worden.
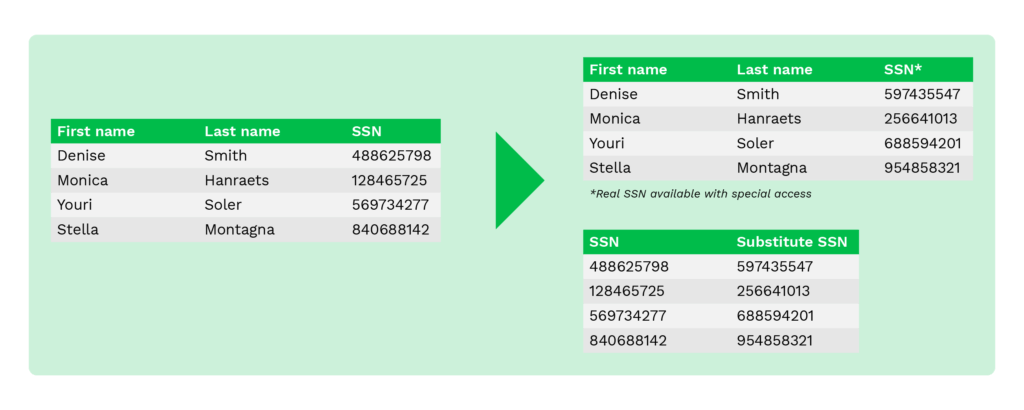
Substitutie
Substitutie, ook wel pseudonimisering genoemd, is een techniek die wordt gebruikt om de oorspronkelijke gegevens te vervangen door willekeurige gegevens uit meegeleverde of aangepaste lookup-bestanden. Dit is nuttig wanneer organisaties het authentieke uiterlijk van gegevens moeten behouden en tegelijkertijd gevoelige gegevens moeten verhullen.
Deze techniek kan gegevens doeltreffend beschermen tegen inbreuken en interne toegang helpen controleren.
Shuffling
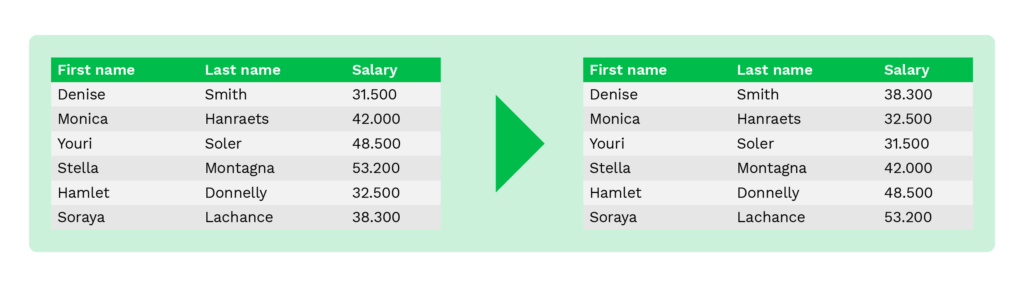
Shuffling is een techniek die lijkt op substitutie. Het wordt ook gebruikt om oorspronkelijke gegevens te vervangen door andere gegevens die er authentiek uitzien. Het verschil is dat alle gegevens in dezelfde kolom willekeurig worden gehusseld.
Organisaties kunnen deze techniek bijvoorbeeld gebruiken om de kolommen met werknemersnamen van meerdere werknemersrecords willekeurig te verschuiven. Deze techniek is kan vatbaar zijn voor reverse engineering als iemand het gebruikte algoritme in handen krijgt.
Averaging
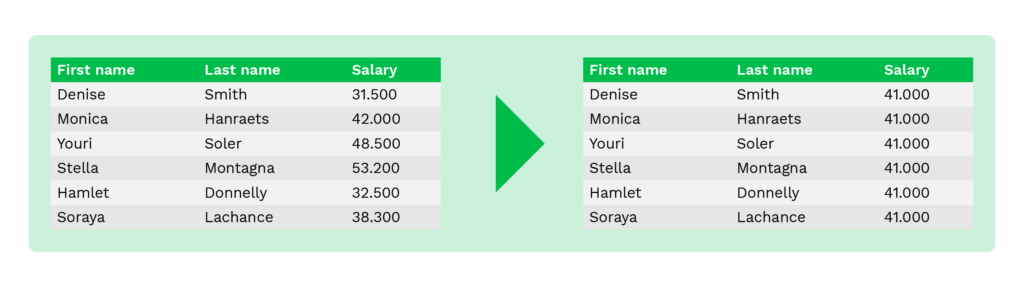
Averaging is een methode om de oorspronkelijke gegevens te vervangen door de gemiddelde waarde van de kolom. In plaats van salarissen of rekeningsaldo’s van personen te tonen, toont de initiatiefnemer bijvoorbeeld alleen de gemiddelde waarde van salarissen of rekeningsaldo’s.
Deze methode helpt de opgetelde waarde te behouden en wordt gewoonlijk gebruikt voor statistische analyses of gegevensverzameling door financiële instellingen.
Nulling out (verwijderen)
Nulling out is een techniek die wordt gebruikt om gevoelige gegevens te vervangen door een nulwaarde om zo te voorkomen dat onbevoegde gebruikers de oorspronkelijke gegevens zien. Het betekent simpelweg dat de informatie wordt verwijdert of wordt vervangen door een lege waarde.

In sommige situaties wordt informatie op bepaalde documenten geheel weggelaten, zoals de geboortedatum op cv’s. Vaak wordt dit gedaan om de risico’s van onethische wervingspraktijken uit te sluiten.

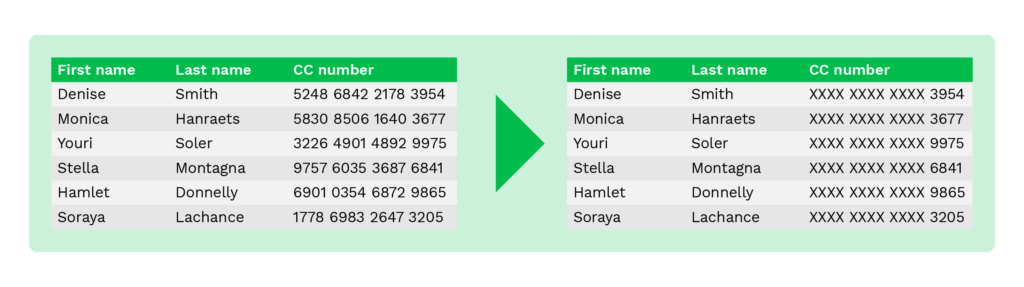
Data redactie (blacklining)
Data redactie, ook wel blacklining genoemd, is een methode die lijkt op nulling, omdat slechts een deel van de oorspronkelijke gegevens wordt afgeschermd.
Tijdens het online winkelen worden bijvoorbeeld alleen de laatste vier cijfers van het rekeningnummer aan klanten getoond om fraude te voorkomen.
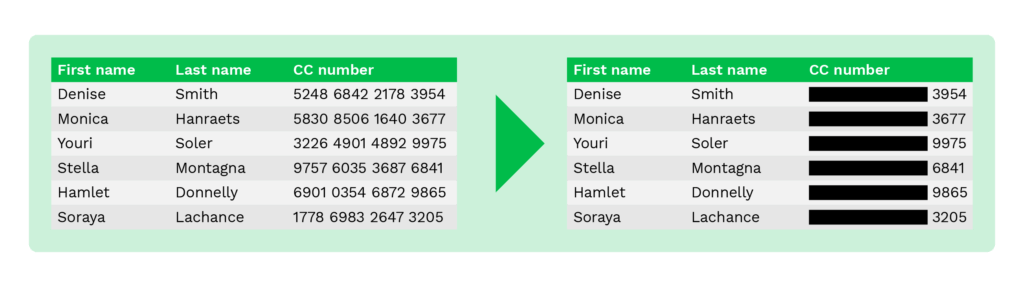

Dezelfde methode kan worden toegepast op elk document dat privacygevoelige informatie bevat. Hieronder zie je het voorbeeld met een paspoort, waarop verschillende velden zijn bewerkt.
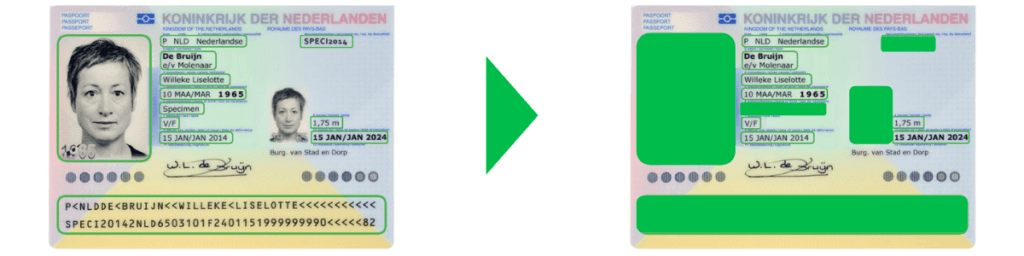
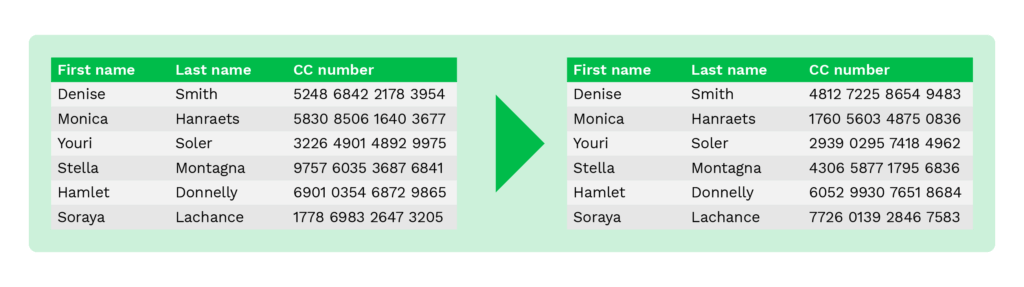
Data scrambling
Data scrambling, ofwel gegevens versleuteling, wordt gebruikt om gegevens te wijzigen door de volgorde van tekens of cijfers willekeurig te herschikken met een specifiek algoritme.
De oorspronkelijke gegevens kunnen, nadat het proces is voltooid, niet meer worden verkregen omdat de gegevens zijn versleuteld.

Data encryptie
Data encryptie is een techniek die toegang tot gegevens alleen mogelijk maakt met een decryptiesleutel.
Het is het meest complexe algoritme voor gegevensversleuteling en daarmee ook het veiligste. Naast de complexiteit vereist het een goed beheer van de encryptiesleutel om de veiligheid te waarborgen.
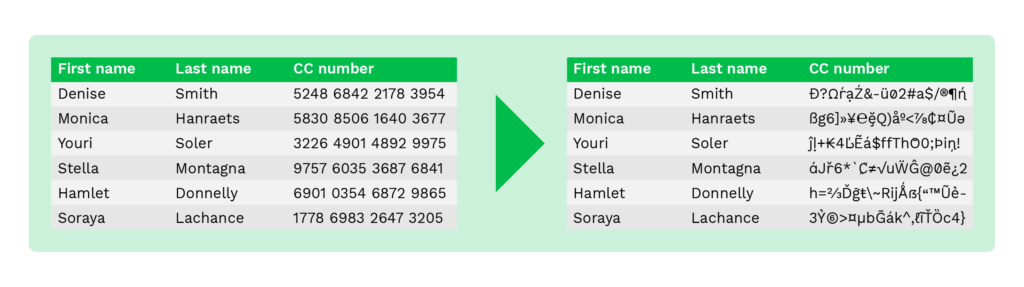

Waarom is data masking zo belangrijk?
Sinds de AVG is opgelegd, is gegevensbescherming voor veel bedrijven een topprioriteit geworden. Als gevolg daarvan is het voor organisaties essentieel om het maskeren van data te implementeren als één van de hulpmiddelen om gevoelige gegevens te beschermen.
Waarom is data masking dan nodig? In principe biedt data masking organisaties een veilige manier om alternatieve versies van bruikbare en goed beveiligde gegevens te creëren.
Met het gebruik van data anonimiseren kunnen organisaties de volgende voordelen behalen.
Data masking voor naleving van de AVG
Het maskeren van data helpt organisaties te voldoen aan wet- en regelgeving op het gebied van gegevensprivacy. Met verschillende technieken voor gegevens maskeren kunnen tal van organisaties de blootstelling van gevoelige gegevens voorkomen.
Toch gebruiken niet alle organisaties data masking om te voldoen aan de AVG. Zo kreeg kledingretailer H&M in 2020 een boete van €35 miljoen voor het overtreden van de AVG. Het incident betrof de toegang van het management tot gevoelige gegevens, zoals religieuze overtuigingen en familiekwesties, via opnames van vergaderingen. Deze opnames werden gebruikt als basis om de prestaties van werknemers te evalueren.
Dit incident had voorkomen kunnen worden door alle gevoelige gegevens uit de gedocumenteerde opnames van deze vergaderingen te verwijderen.
Bescherming tegen data breuken
Eén van de belangrijkste voordelen van data masking is dat gegevens onbruikbaar worden gemaakt voor cyberaanvallen, terwijl de bruikbaarheid voor de organisatie behouden blijft. Zelfs als de gegevens worden geschonden als gevolg van cyberaanvallen, kunnen veel van de technieken voor anonimiseren voorkomen dat indringers gevoelige informatie bemachtigen.
In 2018 werd gemeld dat Panera Bread ten minste 37 miljoen klantengegevens lekte door een gebrek aan toegangscontrole en beveiligingsmaatregelen. Gegevens zoals persoonlijke e-mails, adressen en creditcardgegevens waren toegankelijk via zoekmachines.
Toch had ook dit scenario voorkomen kunnen worden met verschillende technieken voor het maskeren van gegevens.
Verminderde data veiligheidsrisico’s
Veel bedrijven werken samen met partijen aan wie bepaalde gegevens worden overgedragen. Daarnaast kunnen ook werknemers en andere interne belanghebbenden toegang hebben tot gegevens.
Simpel gezegd bestaat er altijd het gevaar dat gegevens verloren gaan. Data masking kan de middelen bieden om de gegevens te beveiligen tegen mensen of partijen die niet bevoegd zijn om ze te zien.
Alleen valse gegevens kunnen worden gezien, tenzij toestemming is verleend om de gegevens te ontmaskeren. Anonimisering van gegevens kan dus de interne risico’s voor gegevensbeveiliging en datalekken verminderen.
In het algemeen biedt het maskeren van gegevens indrukwekkende voordelen, die bedrijven kunnen helpen een concurrentievoordeel te behalen. Maar wat zijn de gangbare gebruikssituaties? We gaan er een paar bekijken!
Gebruiken van data masking
Er zijn veel situaties waarin gebruik van data masking gemaakt kan worden, waaronder de volgende:
- Blacklining van rekeningnummers
- Anonimiseren van burgerservicenummers
- Redactie van cv’s
- Maskeren van gegevens voor digitale archivering
- Redactie of coderen van persoonlijke gezondheidsinformatie
- Redactie of coderen van overheidsdocumenten
- Redactie van juridische documenten en openbare rechtszaken
- Anonimiseren van opnames van vergaderingen
- Interne toegangscontrole
- Encryptie van documenten inzake intellectuele eigendom
- Delen van gegevens met derden
Hieronder zullen we de eerste vier benoemde situaties extra uitdiepen.
Blacklining van rekeningnummers
Soms kan een lid van je organisatie toegang nodig hebben tot creditcard- of rekeninggegevens. Daarom kan het maskeren van data worden gebruikt om de laatste vier cijfers van het rekeningnummer zwart te maken voorkomen dat gevoelige onderdelen worden blootgesteld.
Het is een veel gebruikte methode voor banken en andere financiële instellingen om de betalingsinformatie van hun klanten te verwerken. Door het kaartnummer zwart te maken, kunnen organisaties zorgen voor naleving van de PCI-DSS.

Anonimiseren van burgerservicenummers
Informatie zoals het social security number (SSN) op identiteitsdocumenten zoals paspoorten en identiteitskaarten is zeer gevoelig. Vaak mogen organisaties buiten overheidsinstellingen het SSN niet opslaan in hun database.
In Nederland is het burgerservicenummer (BSN) gelijkwaardig aan het SSN. Het BSN is een uniek, persoonlijk nummer dat wordt gebruikt om elke geregistreerde burger te identificeren. Het BSN wordt bijvoorbeeld gebruikt door overheidsinstellingen om gegevens van elke burger te vinden, vaak voor belastingdoeleinden.
SSN’s en BSN’s zijn strikt verboden onder de AVG omdat ze behoren tot “speciale categorieën van persoonsgegevens”. Natuurlijk zijn er gevallen waarin het opslaan van dergelijke gegevens is toegestaan. Maar alleen met een speciale wettelijke uitzondering of toestemming van de persoon.
Daarom is het gebruikelijk om SSN- of BSN-nummers te anonimiseren met behulp van verschillende technieken voor het maskeren van gegevens.

Aanpassen van CV’s
Ondanks alle training om vooroordelen in het wervingsproces te verminderen, baseren veel recruiters hun beslissingen toch op verschillende vooroordelen. Helaas is het nog steeds gebruikelijk dat als twee kandidaten vergelijkbare vaardigheden en ervaring hebben, de aantrekkelijkste wordt aangenomen.
Hoewel het illegaal is om te discrimineren in het wervingsproces, doen veel bedrijven het nog steeds. In totaal zijn 20% van de bedrijven in de VS verantwoordelijk voor de helft van de gevallen van discriminatie.
Organisaties zijn begonnen met het aanpassen van cv’s om vooroordelen en discriminatie in de vroege fase van het wervingsproces te voorkomen. Volgens een rapport van HRO Today zijn de meest voorkomende velden die uit cv’s worden weggelaten:
- Huisadres
- Naam
- Foto
Door het afschermen van deze gegevens zijn recruiters beter in staat om kandidaten uitsluitend op basis van hun vaardigheden en ervaring te evalueren. Het is hier belangrijk om op te beseffen dat recruiters ook maar mensen zijn!

Data masking voor digitaal archiveren
Het opslaan van gegevens op papier is voor een heleboel organisaties simpelweg geen optie meer. De redenen voor organisaties om met de voortschrijdende technologie over te stappen op digitalisering zijn onder andere:
- Een enorme achterstand van ongeorganiseerde gegevens
- Interne toegangscontrole
- Tijd- en kostenbesparing
- Milieuvriendelijkheid
- Naleving van de AVG
- Eenvoudige toegang tot gegevens
Hoewel gegevensarchivering zeer voordelig kan zijn, is de uitdaging om te voldoen aan de wettelijke verplichtingen wat betreft de wetgeving over gegevensprivacy. In dit opzicht is data-afscherming een veilige en betrouwbare oplossing om de naleving van de AVG te waarborgen.
Vóór de archivering kunnen bedrijven data masking gebruiken om alle gevoelige onderdelen zoals namen, patiëntnummers, en burgerservicenummers uit documenten te verwijderen of te vervangen door structureel identieke gegeven, zoals hetzelfde aantal cijfers of tekens.
Organisaties hebben deze methode toegepast in sectoren zoals bijvoorbeeld justitie en de gezondheidszorg.
Nu we enkele gebruiken hebben behandeld, kunnen we gaan kijken naar de transformatie van document-redactie.
Transformatie van documenten redigeren
Zolang we ons kunnen herinneren, wordt het handmatig redigeren van documenten in verschillende sectoren toegepast. Het is een vervelende taak om uit te voeren en het heeft veel onderliggende problemen. Een van de grootste problemen is de schaalbaarheid.
Het menselijk personeel heeft moeite om de nauwkeurigheid, efficiëntie, en consistentie in de tijd te handhaven. Dit resulteert in trage doorlooptijden, ontevreden klanten, en hoge kosten.
Neem de juridische sector als voorbeeld. Een typische werkstroom houdt in dat teams van advocaten en paralegals honderden uren lang grote stapels met documenten doornemen. In plaats van dat ze hun kennis en ervaring te gebruiken voor zinvolle taken, worden ze belast met het toevoegen, wijzigen en verwijderen van redacties in documenten. En dan hebben we het nog niet eens over de kosten van het inhuren van dit personeel.
Het toevoegen van meer personeel naarmate het volume van de documenten toeneemt, verhoogt al snel de kosten. Dus laten we eerlijk zijn, het handmatig redigeren van documenten is geen schaalbare optie. Tenminste, niet als je kostenefficiënt wilt werken.
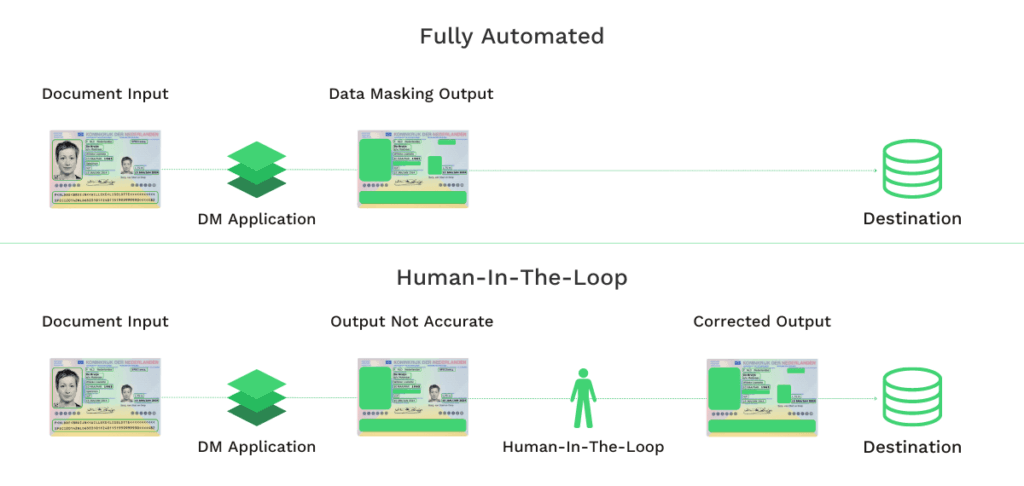
Gelukkig is het met de huidige technologie mogelijk om documenten automatisch te redacteren. Er zijn twee manieren waarop organisaties hiermee hun voordeel kunnen doen: volledig geautomatiseerde data anonimisering en automatisering van data masking met menselijke hulp.
Volledig geautomatiseerde data masking
Bij een volledig geautomatiseerde oplossing voor het maskeren van gegevens is menselijke tussenkomst niet nodig. Met technologieën zoals AI-aangedreven Optical Character Recognition (OCR) is het mogelijk om automatisch het vereiste informatieveld uit documenten te herkennen, te lokaliseren en te redigeren.
Je hoeft de OCR machine alleen nog maar te voorzien van de documenten die moeten worden afgeschermd, en de technologie doet de rest. Deze optie maakt personeel vrij, dat je vervolgens kunt inzetten voor meer gecompliceerde taken. Zo kun je de efficiëntie van je organisatie maximaliseren.
Mens-ondersteunde data masking
De andere oplossing is het gebruik van door mensen ondersteunde automatisering, met andere woorden: human-in-the-loop (HITL) automatisering. Deze oplossing maakt gebruik van AI voor automatisering en stelt menselijk personeel in staat de eindcontroles uit te voeren om de voltooiing van de gegevensafscherming te controleren.
Het voordeel van human-in-the-loop automatisering is dat het een hogere nauwkeurigheid van document-redactie mogelijk maakt. Dit is geen verrassing, de HITL-oplossing combineert namelijk het beste van kunstmatige intelligentie met het beste van menselijke intelligentie.
Soms kunnen er problemen zijn met de technologie, zoals beeldkwaliteit of document kwaliteit, waardoor het niet mogelijk is om gegevens af te schermen. Dan kan een beoordeling door mensen van de gegevensinvoer of -uitvoer helpen fouten te beperken.
Het is moeilijk, duur, en tijdrovend om een van deze oplossingen vanuit het niets te creëren. Daarom hebben we bij Klippa besloten om onze OCR-technologie te combineren met data-afscherming om verschillende organisaties te helpen. Wij kunnen onze klanten helpen met het automatiseren van document masking op schaal.
Dus waarom zou jouw organisatie het maskeren van data automatiseren? Laten we ons eens verdiepen in de voordelen.
Voordelen van automatische data masking
Hoewel we al weten dat organisaties gegevens kunnen beschermen tegen lekken en de naleving van de AVG kunnen waarborgen met gegevensafscherming, voegt de automatisering ervan nog veel meer voordelen toe. Deze voordelen zijn onder andere:
- Nauwkeurigheid – Met een geautomatiseerde oplossing voor data masking, die gebruik maakt van AI, kunnen bedrijven een hogere nauwkeurigheid bereiken. Machines en computers worden tenslotte niet moe.
- Snellere doorlooptijden – Door document- of gegevensredactie te automatiseren, kan je personeel zich richten op belangrijkere taken. Er zijn minder mensen nodig om deze vervelende taken uit te voeren en dus wordt de doorlooptijd versneld.
- Snelheid – Met een geautomatiseerde oplossing kan het redigeren van gegevens tot 90 keer sneller gaan. Een vereenvoudigde berekening vind je in de volgende paragraaf.
- Kostenbesparing – Met de hogere efficiëntie en nauwkeurigheid die met AI wordt bereikt, kunnen organisaties aanzienlijk geld besparen wat betreft arbeidsuren, minder fouten, etc.
- Schaalbaarheid – Er is een grens aan hoeveel documenten een gemiddelde werknemer kan redacteren. Automatisering van gegevensafscherming biedt bedrijven een manier om documenten op schaal te redacteren zonder de operationele kosten te verhogen.
Het lijkt erop dat er veel voordelen van geautomatiseerde data masking zijn voor organisaties. Maar wat betekent het voor jou als bedrijf?
Om het tastbaar te maken voor je, hebben we in de volgende paragraaf een voorbeeldberekening gegeven van een potentiële return on investment (ROI).
De ROI van automatische data masking
Stel dat je 100.000 identiteitsdocumenten hebt, waarvan je de sofinummers moet redigeren. Laten we ook aannemen dat een ervaren kantoorbediende gemiddeld twee identiteitsdocumenten per minuut handmatig kan redigeren. Dat zijn 120 identiteitsdocumenten in een uur. Laten we de kosten voor het inhuren van een ervaren medewerker, inclusief verzekering, uurloon en andere kosten, schatten op €25,00 per uur.
Om ervoor te zorgen dat de redactie correct gebeurt, zou je een andere kantoorbediende moeten inhuren om de gecorrigeerde documenten dubbel te controleren. Laten we aannemen dat een identieke medewerker elke redactie kan dubbelchecken op juistheid in een tempo van 360 identiteitsdocumenten per uur.
De totale kosten van het handmatig redigeren van 100.000 identiteitsdocumenten zouden dan meer dan 27.700 euro bedragen en het project zou meer dan 1.110 werknemersuren in beslag nemen.
In vergelijking met de Klippa oplossing, die 10.000 documenten per uur kan redigeren, zou je het project binnen 10 uur kunnen voltooien. Dat zijn dus ongeveer 1100 arbeidsuren die je bespaart.
Bij wijze van schatting kost het je organisatie, afhankelijk van het documenttype en -volume, €4.000 om dit project met onze oplossing te voltooien. Je zou het project meer dan 90 keer sneller kunnen voltooien en het levert een ROI van 6,9 op.

Probeer onze data masking ROI calculator zelf!
Maskeer je data met Klippa
Klippa is opgericht met het doel om bedrijven te helpen met het digitaliseren en automatiseren van document-verwerking door gebruik te maken van geavanceerde technologieën. Met technologieën zoals machine learning, AI, en OCR zijn we in staat om klanten uit verschillende branches en over de hele wereld te helpen.
Onze Intelligent Document Processing (IDP) oplossing, Klippa DocHorizon, is ontworpen om organisaties te helpen bij het intelligent automatiseren van document-verwerking; digitaliseren, extraheren, classificeren, verifiëren, en anonimiseren van gegevens uit verschillende documenten.
Met Klippa DocHorizon kan je organisatie doorlooptijden, kosten en menselijke fouten verminderen, en tegelijkertijd gevoelige gegevens beschermen.
Hoewel onze AI-gebaseerde OCR-software functies voor het maskeren van data bevat, hebben we een API voor gegevensafscherming ontwikkeld om integratie met bestaande systemen voor documentbeheer, Enterprise Resource Planning (ERP) of Elektronische Patiënten Dossiers (EPD) van onze klanten mogelijk te maken.
Naast de API hebben we ook een Software Development Kit (SDK) voor data masking ontwikkeld, zodat bedrijven onze technologie in hun systeem kunnen toepassen.
Data masking API
Om onze klanten zich te helpen ontdoen van repetitief werk in administratieve processen, hebben we een data masking OCR API ontwikkeld. Hiermee kunnen onze klanten bepaalde velden en afbeeldingen in documenten geheel zwart maken.
Onze parser-engine kan worden getraind om specifieke velden te herkennen die zwart gemarkeerd moeten worden. We verwerken vele out-of-the-box velden, maar aangepaste velden kunnen op verzoek worden toegevoegd of verwijderd.
De parser kan verschillende inputs krijgen, zoals JPG, PNG, en PDF. De standaard uitvoer die onze klanten ontvangen is een JSON bestand, dat kan worden doorgestuurd naar de gewenste bestemmingen zoals Enterprise Resource Planning (ERP) systemen. De uitvoer kan echter worden aangepast naar bijvoorbeeld CSV, XLSX of XML indien nodig. Naast de gestructureerde JSON is het ook mogelijk om de gemaskeerde documenten in JPG, PDF of soortgelijke bestandstypen te verkrijgen.
Onze data masking OCR API is momenteel beschikbaar via een RESTful API, zodat onze klanten het kunnen integreren in webgebaseerde applicaties. Om onze klanten te helpen, bieden wij duidelijke documentatie.
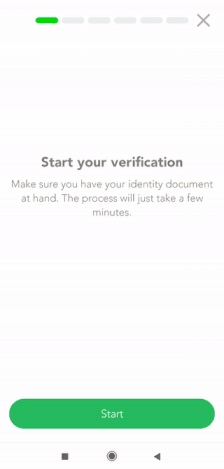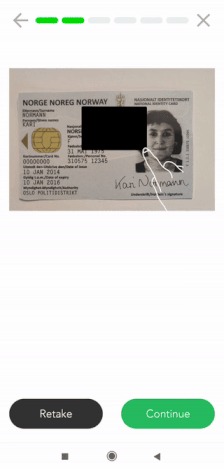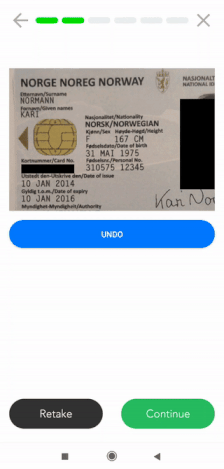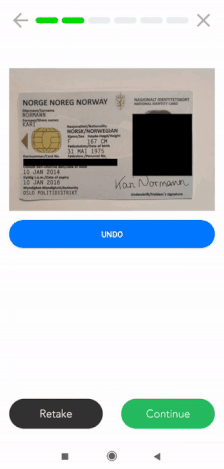
Mobiele data masking
Als je op zoek bent naar een mobiele data masking-oplossing, kan Klippa je daar ook mee helpen. Wij bieden een mobiele scanner-SDK die data-afscherming functionaliteiten bevat. Klanten gebruiken deze scanner-SDK om bepaalde informatie te maskeren in identiteitsdocumenten, ontvangstbewijzen, facturen, en vele andere soorten documenten.
Momenteel is onze scanner SDK beschikbaar voor zowel Android als IOS. Daarnaast bieden we wrappers voor cross-platform talen zoals ReactNative, Flutter, Cordova en Nativescript. Over het algemeen kan dit worden geïntegreerd in elke mobiele oplossing.
Documenten watermarkeren
In het geval dat één van deze manieren om gegevens te maskeren voor jou niet mogelijk is, biedt Klippa als alternatief ook digitale watermerken op documenten aan. Op deze manier kun je het auteursrecht van je documenten beschermen, je klanten in staat stellen gegevens veiliger te delen, en veiligheidsrisico’s verminderen bij het opslaan van gevoelige gegevens.
Als je Klippa DocHorizon een document geeft, stuurt het hetzelfde document terug met een watermerk. Dat watermerk kan aangepast worden naar jouw wens, bijvoorbeeld met je bedrijfsnaam en de scan-datum.

Of je nou op zoek bent naar een alles-in-één oplossing of een API/SDK-integratie om je document-verwerking te automatiseren, Klippa is er om jou te helpen! Vul het onderstaande formulier in voor een gratis demo of neem contact op met onze experts om te zien hoe Klippa jou kan ondersteunen.