In 2023 wordt elke dag een ongelooflijke hoeveelheid van 3,5 triljoen bytes aan gegevens gecreëerd. Behoorlijk verbazingwekkend, toch? Deze gegevens zijn essentieel voor de groei van organisaties, omdat ze het leven van mensen makkelijker maken, problemen in organisaties oplossen en innovatie stimuleren.
Er is echter een probleem: de meeste gegevens zitten vast in ongestructureerde formaten zoals gescande documenten of handgeschreven papieren. Dit maakt het voor bedrijven vrijwel onmogelijk om gegevens effectief te gebruiken.
Wat het een uitdaging maakt, is dat bedrijven deze gegevensbestanden nodig hebben en ze in andere formaten moeten omzetten om ze van de ene software naar de andere door te sturen. Daarvoor moeten ze een oplossing vinden die gegevens toegankelijk maakt voor allerlei entiteiten. Dit is waar data parsing in beeld komt.
Op dit punt voelt data parsing misschien als een abstract concept. Daarom zullen we in de volgende paragraaf uitleggen wat data parsing is, verder gaan met het uitlichten van de verschillende soorten data parsing en verduidelijken waarom data parsing zo essentieel is.
Laten we beginnen!
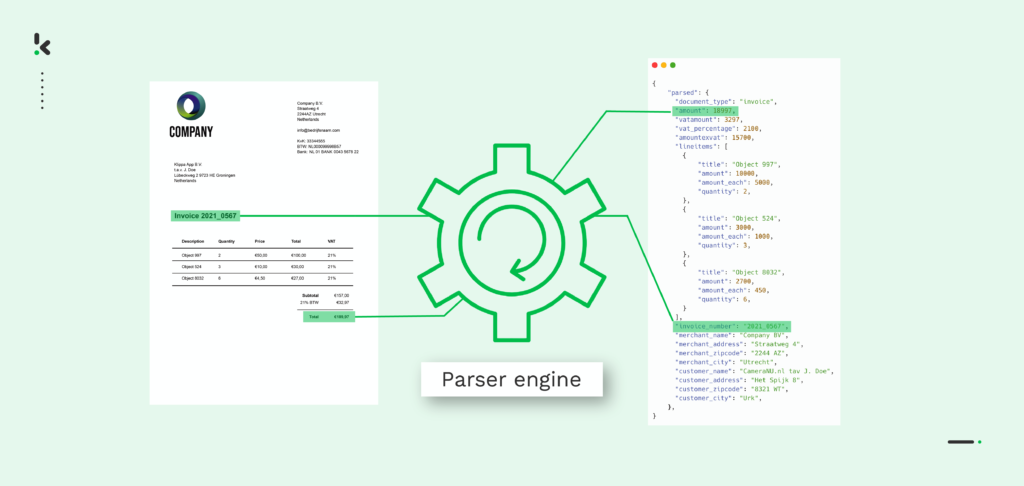
Wat is data parsing?
Simpel gezegd is data parsing het proces van het omzetten van gegevens van het ene formaat naar het andere. Laten we bijvoorbeeld zeggen dat je een PDF-bestand hebt, maar je hebt dit bestand eigenlijk nodig als een JSON-bestand. In dat geval heb je een data parser nodig die de ruwe PDF-gegevens kan parsen in een machinaal leesbaar formaat.

In het algemeen wordt het parsen van gegevens toegepast als de volgende stap nadat gegevens uit een document zijn gehaald. Meestal zijn de geëxtraheerde gegevens in één formaat en moeten ze worden geconverteerd naar een ander formaat, zodat ze kunnen worden opgeslagen in je database of kunnen worden doorgestuurd naar een andere software.
De omzetting van het ene bestandsformaat naar het andere is mogelijk met behulp van een onderdeel van AI, Natural Language Processing (NLP) genaamd, waarin een reeks symbolen, speciale tekens en gegevensstructuren wordt geanalyseerd. Op basis van door de gebruiker gedefinieerde regels wordt informatie eerst gestructureerd en vervolgens georganiseerd, waardoor de geëxtraheerde gegevens betekenis krijgen.
Belangrijk om in gedachten te houden is, dat afhankelijk van de contextuele structuren van de geëxtraheerde gegevens, verschillende data parsing soorten kunnen worden toegepast. Laten we eens kijken hoe deze verschillende soorten werken.
Verschillende soorten data parsing
In het algemeen zijn er twee verschillende soorten voor het parsen van gegevens: Grammatica-gestuurde data parsing en data-gestuurde data parsing.
Grammatica-gedreven data parsing
Zoals de naam al aangeeft, baseert grammatica-gestuurde data parsing het parseer-proces op een reeks formele grammaticaregels. Dit werkt door zinnen uit ongestructureerde gegevens te fragmenteren en ze vervolgens om te zetten in een gestructureerd en gemakkelijk te begrijpen formaat.
Deze aanpak heeft echter één probleem, namelijk het gebrek aan robuustheid. Om dit probleem te vermijden, worden grammaticale beperkingen vaak versoepeld. Dat betekent dat zinnen die niet binnen het bereik van de gebruikelijke grammatica vallen, kunnen worden uitgesloten van de analyse van de data parsing.
Aangezien grammatica-gestuurde data parsing zijn beperkingen en inconsistenties heeft, is een aanvullende manier van data parsing gevonden. Hier komt data-driven data parsing om de hoek kijken.
Data-gedreven data parsing
In het algemeen maakt data-gedreven data parsing gebruik van slimme statistische parsers en moderne treebanks om zoveel mogelijk talen te dekken. Dit maakt het mogelijk om conversatietalen en zinnen te parsen die een hoge precisie vereisen, ook al zijn ze ongelabeld en domeinspecifiek.
Note: Een treebank verbetert NLP-modellen, zodat een AI-software geschreven tekst kan begrijpen. De statistische parser kan gebruik maken van het NLP-model, om de mogelijke verschillende betekenissen binnen een zin te begrijpen, en geeft de meest waarschijnlijke terug.
Bij data-gedreven data parsing kunnen twee verschillende manieren worden gebruikt:
- Regels-gebaseerde aanpak
- Learning-gebaseerde aanpak
Regel-gebaseerde aanpak
De op regels-gebaseerde aanpak is geschikt voor gestructureerde documenten zoals belastingfacturen of inkooporders. De gedefinieerde regels helpen de gebruiker om een template te bepalen dat wordt gebruikt als referentie voor de parser om gegevens uit een document te extraheren.
Het grote nadeel hier is de strikte afhankelijkheid van vooraf gedefinieerde templates, wat betekent dat zelfs een licht afwijkend documentformaat zal leiden tot een mislukte data parsing. Dus wat zou een manier kunnen zijn om gegevens flexibeler te parsen?
Learning-gebaseerde aanpak
Het antwoord is: Een op learning-gebaseerde benadering van data parsing. Deze aanpak is sterk afhankelijk van Machine Learning (ML) en Natural Language Processing (NLP) en wordt in het algemeen gebruikt om gegevens te extraheren uit elk soort document.
Omdat het model wordt getraind met een diverse reeks ongestructureerde documenten, wordt het vermogen om gemakkelijk belangrijke velden te herkennen en er gegevens uit te halen verbeterd.
In de praktijk wordt echter een combinatie van beide, regelgebaseerde en leergebaseerde benaderingen, gebruikt om gegevens te parsen. Deze combinatie maakt het mogelijk om elk document met elke soort lay-out te verwerken, en beperkt je niet tot slechts één lay-out.
Laten we met dit in gedachten eens kijken hoe data parsing wordt gebruikt in verschillende sectoren.
Gebruikssituaties voor data parsing
Data parsing wordt in verschillende sectoren gebruikt om gegevens in onbruikbare formaten om te zetten in bedrijfsklare gegevens. Omwille van de leesbaarheid zullen we ons beperken tot vier sectoren, maar houd er rekening mee dat deze lijst verre van volledig is:
- Financiële sector
- Gezondheidszorg
- Juridisch
- Transport & logistiek
Financiële industrie
Banken en andere financiële instellingen hebben te maken met miljoenen documenten van klanten, zoals identiteitskaarten, bankafschriften en instroom-aanvragen. Al deze documenten moeten worden geanalyseerd en de relevante informatie moet worden opgeslagen in de database van de bank.
Evenzo heeft elk bedrijf te maken met facturen en bonnen die vaak handmatig worden verwerkt en opgeslagen in verschillende formaten (PNG, PDF, enz.). Dit maakt het erg moeilijk om gegevens te doorzoeken en er dus efficiënt mee te werken.
Om financiële processen te verbeteren, kan een data parser worden gebruikt in de volgende gevallen:
- Geautomatiseerde gegevensinvoer
- Instroom van klanten
- Volledigheidscontrole van documenten
- KYC-automatisering
- Geautomatiseerde factuurverwerking
- PDF omzetten naar Excel
- Gegevens uit PDF halen

Maak je geen zorgen als jouw gebruikssituatie hier niet bij staat. Er zijn nog veel meer gebruikssituaties voor de financiële sector.
Gezondheidszorg
De gezondheidszorg wordt vaak geconfronteerd met een tekort aan middelen, lange werktijden en enorme administratieve taken. Dit kan snel leiden tot fouten in patiëntendossiers, vervolgbehandelingen en recepten, wat zich vertaalt in ernstige schade of zelfs overlijden van de patiënt.
Bovendien zit de instroom van patiënten vol met allerlei documenten, waardoor medewerkers in de gezondheidszorg veel tijd moeten besteden aan het invoeren van gegevens uit formulieren in computers.
In de gezondheidszorg kan een data parser nuttig zijn in de volgende gevallen:
- Geautomatiseerde instroom van patiënten
- Data extractie uit patiëntendossiers
- Scannen van medische gegevens

Juridisch
Advocaten zijn duur, wat betekent dat advocatenkantoren zeker willen dat zij hun tijd gebruiken om zaken op te lossen in plaats van eindeloze hoeveelheden documenten te sorteren. Maar omdat advocaten allerlei soorten documenten van cliënten in verschillende formaten ontvangen, zijn ze veel tijd kwijt aan het sorteren ervan. Dit maakt hen zeer inefficiënt en traag.
Bovendien bedienen advocaten meerdere cliënten tegelijk. Daarom is het essentieel dat alle documenten goed georganiseerd en gecategoriseerd zijn. Anders is het bijna onmogelijk om overzicht en overzicht te houden over de verschillende zaken.
Bovendien bevatten de meeste klant-documenten gevoelige informatie die moet worden beschermd tegen datalekken en fraude.
In het geval van de juridische sector kan data parsing op de volgende manieren van pas komen:
- Verzamelen en organiseren van data
- Documentclassificatie
- Geautomatiseerde data extractie
- Anonimisering van informatie

Transportatie & logistiek
Elk bedrijf dat online producten of diensten verkoopt, heeft te maken met een grote hoeveelheid verzend- en factureringsinformatie. Daarom moeten gegevens zoals verzend-etiketten, pakbonnen en leveringsbewijzen worden beheerd.

Hier kan een data parser worden gebruikt in gevallen als:
- Geautomatiseerde gegevensinvoer
- Nalevingscontroles
- Geautomatiseerde factuurverwerking
- Detectie van documentfraude
- Beheer van pakketten
Als we naar deze verschillende use cases kijken, wordt het duidelijk dat data parsing gunstig is voor verschillende industrieën. Door data parsing te automatiseren kan het proces worden verbeterd en nog efficiënter worden gemaakt. Laten we eens kijken hoe data parsing kan worden geautomatiseerd.
Hoe automatiseer je data parsing?
Tegenwoordig ben je waarschijnlijk gedwongen om tijd, menselijke inspanningen en uitgaven voor je bedrijf waar mogelijk te verminderen. Om dit te bereiken lijkt automatisering de enige oplossing. Zoals blijkt uit de gepresenteerde use cases, levert data parsing zelf al grote voordelen op, zoals optimalisatie van de werkwijzes voor bedrijven. Maar om het parsen van gegevens te verbeteren, kunnen we het proces automatiseren.
Laten we eens kijken naar de verschillende manieren om data parsing te automatiseren:
- Klassieke OCR-software
- Web-applicaties
- Robots & RPA
Klassieke OCR-software
Klassieke OCR-software is een vrij eenvoudige oplossing om processen te automatiseren. Het heeft alle basisfuncties en instructies om de klus te klaren. Maar de mogelijkheden zijn beperkt.
Daarom is een klassieke OCR-software bruikbaar voor kleinere bestanden en om bijvoorbeeld een eenvoudige PDF naar JSON te converteren. Maar taken als het parseren van tabellen of het lezen van afbeeldingen kunnen niet worden uitgevoerd, omdat daarvoor krachtigere bibliotheken nodig zijn, die meer rekenkracht en gegevens verbruiken.
Web-applicaties
Web-applicaties worden vaak gebruikt voor een User Interface (UI) om het data parsing proces te automatiseren. Om op bepaalde soorten bestanden te kunnen werken, wordt een specifieke backend-taal gekozen, zoals Python of Java. Alle communicatie tussen de UI, de backend en andere databases gebeurt hoofdzakelijk via de database.
Als de website wordt beheerd via een krachtige cloud-oplossing, kan OCR worden geïntegreerd om gegevens te parseren. Desondanks kan deze oplossing tijdrovend zijn, omdat zij vele stappen en verzoeken over het hele web uitvoert.
Robots & RPA
Robotic Process Automation (RPA) is één van de nieuwste ontwikkelingen die automatisering mogelijk maken. In plaats van dat mensen handmatige taken uitvoeren, zorgen robots voor de automatisering van die taken. Ze zijn uitgerust met intelligente algoritmen die hen in staat stellen te leren en fouten bij elke iteratie te minimaliseren.
Eén van de belangrijkste voordelen is dat deze robots kunnen worden verbonden met verschillende gegevensbronnen, API’s en andere integraties van derden, waardoor je gegevens anders kunt parseren.
Nu we hebben besproken hoe data parsing kan worden geautomatiseerd, laten we eens kijken naar de voordelen van data parsing.
De voordelen van data parsing
Naast het belangrijkste voordeel van data parsing, het kunnen navigeren door een enorme hoeveelheid gegevens, zijn er nog meer voordelen:
- Tijdbesparing – Data parsers helpen bedrijven om gegevens in een ander formaat om te zetten en het proces te automatiseren dat anders handmatig zou worden gedaan. Het resultaat is dat de bedrijfsvoering sneller verloopt en dat menselijke middelen kunnen worden ingezet voor waardevollere taken.
- Meer toegankelijke gegevens – Data parsing maakt gegevens toegankelijker en vergroot de doorzoekbaarheid. Zakelijke professionals hebben toegang tot alle benodigde informatie uit de enorme hoeveelheid gegevens.
- Modernisering van gegevens – Het kan voorkomen dat opgeslagen gegevens van bedrijven jaren oud zijn en daarom niet beschikbaar zijn in moderne formaten. Maar deze gegevens kunnen nog steeds waardevolle informatie bevatten die nodig is voor het bedrijf. Data parsing kan het formaat van deze gegevens snel veranderen en bedrijven in staat stellen de informatie effectief te gebruiken.
Na te hebben doorgenomen wat data parsing is, in welke gevallen het wordt gebruikt en welke voordelen het kan opleveren, vraag je je misschien af hoe je toegang krijgt tot een data parser. Een optie zou kunnen zijn om je eigen parser te bouwen. Maar is dat wel een slim idee?
Je eigen parser bouwen of niet?
Om die vraag te beantwoorden, zullen we de voor- en nadelen van het bouwen van je eigen parser met je doornemen. Hierna zou je een weloverwogen beslissing moeten kunnen nemen.
Voordelen van je eigen parser bouwen
- Geeft je meer controle – Je hebt meer controle en kunt beslissen hoe je jouw data parser bijwerkt of onderhoudt. Als je bovendien te maken hebt met zeer gevoelige gegevens, geef je er misschien de voorkeur aan je informatie niet te delen met data parsers van derden.
- Aanpasbaar naar jouw behoeften – Wanneer je je eigen parser bouwt, wordt hij specifiek aangepast aan jouw bedrijf. Op die manier helpt het interne teams te voldoen aan de specifieke parsing-vereisten van je organisatie.
Nadelen van je eigen parser bouwen
Om je eigen parser te bouwen, heb je in het algemeen een team van ontwikkelaars nodig dat in staat is de parsing-toepassing te begrijpen en te schrijven. Het vinden van ontwikkelaars met deze noodzakelijke vaardigheden kan een hele uitdaging zijn. Maar dit is niet de enige nadeel. Laten we eens kijken welke andere nadelen er kleven aan het bouwen van je eigen parser:
- Duur – Je eigen parser bouwen is duur, omdat er veel tijd en middelen voor nodig zijn. Bovendien moet je een heel intern team inhuren en opleiden om je eigen parser te bouwen.
- Opleiding van personeel – Je moet je hele personeel trainen in het gebruik van de data parsing technologie.
- Onderhoud – Een data parser vereist regelmatig onderhoud, wat betekent dat je meer tijd en geld moet besteden.
- Infrastructuur – Het bouwen van een data parser vergt veel planning en eigen dedicated servers. Dit betekent dat je een krachtige server moet bouwen of kopen die snel genoeg is om informatie te parsen.
Voor de meeste organisaties wegen de nadelen zwaarder dan de voordelen, simpelweg omdat het duur is en uiterst moeilijk om ervaren mensen te vinden om een parser te bouwen. Als dat het geval is, vrees niet! Wij hebben een andere optie voor je. Je kunt je organisatie voorzien van een data parser die door duizenden ontwikkelingsuren is gebouwd.
Data parsing met Doxis
Doxis is een van de bedrijven die kan worden gebruikt om gegevens te parseren van elk soort document. Om gegevens te kunnen ontleden is een OCR-software (Optical Character Recognition) nodig.
Doxis AI.dp, onze op AI gebaseerde OCR-software, kan worden gebruikt om gegevens te ontleden uit elk soort document dat je organisatie moet verwerken. Met OCR-technologie kun je nauwkeurig relevante informatie uit ongestructureerde gegevensformaten halen en die gegevens omzetten in het door jou gewenste formaat.
Daarnaast kan AI.dp documenttypes classificeren, gegevens verifiëren en anonimiseren, en dat alles zonder handmatige gegevensinvoer. Out-of-the-box herkent AI.dp al een breed scala aan documenten in meer dan 100 talen.
Wil je je gegevens die die niet gebruikt worden vanwege onbruikbare formaten omzetten in bedrijfsklare gegevens? Wij laten je graag zien hoe dat kan met onze oplossing. Boek een gratis demo hieronder of neem contact op met een van onze experts.