
De best presterende organisaties zijn die organisaties die hun beslissingen baseren op actuele en nauwkeurige informatie. Veel bedrijven worstelen echter met hun informatieverzameling, vooral als de informatie zich in allerlei verschillende bronnen bevindt. Deze organisaties hebben vaak te maken met ongestructureerde informatieformaten zoals afbeeldingen of gescande documenten, waardoor gegevens moeilijk te verkrijgen zijn.
Dit is een enorm probleem wanneer organisaties honderden, duizenden of zelfs miljoenen documenten per maand moeten verwerken. Het verwerken van grote hoeveelheden ongestructureerde documenten en het omzetten daarvan in bedrijfsklare formaten is niet optimaal, omdat het foutgevoelig, duur en inefficiënt is.
Gelukkig zijn er verschillende methoden om handmatig werk waarbij informatie uit digitale of fysieke documenten wordt gehaald, te automatiseren. Technologieën zoals Optical Character Recognition (OCR) en Artificial Intelligence (AI) zijn vaak essentieel om bedrijven te helpen informatie efficiënt te extraheren.
In dit artikel duiken we in wat informatie-extractie is, hoe het werkt, de voordelen ervan, gebruikssituaties en introduceren we een oplossing die jouw organisatie kan helpen om je informatie-extractie te automatiseren.
Laten we beginnen!
Wat is informatie-extractie?

Informatie-extractie is het proces waarbij informatie uit ongestructureerde formaten – PNG, JPEG, PDF – wordt gehaald en omgezet in gestructureerde, bewerkbare, doorzoekbare en machine-leesbare formaten – JSON, CSV, XLSM. Vaak krijgen bedrijven bedrijfsklare gegevens door PDF naar Excel te converteren.
Informatie-extractie maakt de consolidatie van gegevens mogelijk. Meerdere informatiebronnen, meestal slecht georganiseerd en volledig ongestructureerd, kunnen worden omgezet in bruikbare informatie die nog verder kan worden opgeslagen of geanalyseerd.
Duidelijke informatie over de werking van je organisatie is de basis voor onder meer een kritische analyse van het besluitvormingsproces, serviceverbeteringen, verkoopprognoses en kostenoptimalisatie.
Dus hoe kan je bedrijf informatie extraheren? In het algemeen zijn er drie informatie-extractie technieken voor bedrijven:
- Handmatige informatie-extractie
- Geautomatiseerde informatie-extractie
- Geautomatiseerde informatie-extractie met human-in-the-loop
1. Handmatige informatie-extractie
Handmatige informatie-extractie is het handmatig verzamelen van informatie uit een gegevensbron. Dit gebeurt in veel bedrijfsprocessen. Binnen jouw bedrijf heb je bijvoorbeeld een werknemer die facturen verwerkt.
De werknemer leest het fysieke of digitale document en typt de informatie in je crediteurensoftware. Dit kan een praktische methode zijn wanneer je informatie uit slechts enkele documenten moet halen.
Het handmatig extraheren van informatie is echter repetitief, tijdrovend en foutgevoelig, wat onnodige overheadkosten met zich meebrengt. Daarom maken veel bedrijven gebruik van geautomatiseerde oplossingen om het informatie-extractieproces te beheren.
2. Geautomatiseerde informatie-extractie
Hoe kunnen bedrijven informatie-extractie automatiseren? Met software voor informatie-extractie die technologieën zoals OCR en AI gebruikt, kunnen bedrijven automatisch informatie uit elk type document halen.
OCR, in het kort, is een technologie die een afbeelding kan omzetten in tekst. AI-technologieën daarentegen helpen met informatieherkenning, documents classificatie en informatieverificatie. Eenvoudig gezegd maakt AI zinvol gebruik van de geëxtraheerde informatie en herkent gegevensvelden, zoals een factuurnummer of een totaalbedrag.
Door de combinatie van AI en OCR kan informatie-extractie software nauwkeurig en snel gegevens uit documenten halen. Met software voor informatie-extractie die met deze technologieën is uitgerust, kan het proces van informatie-extractie binnen enkele seconden worden uitgevoerd.
Laten we eens kijken naar een derde manier om informatie uit documenten te halen.
3. Geautomatiseerde informatie-extractie met human-in-the-loop
Human-in-the-loop (HITL) automatisering combineert de vorige twee manieren. Zelfs met de meest geavanceerde technologie is het bijna onmogelijk om altijd 100% nauwkeurig gegevens uit documenten te halen.
In sommige gevallen kan 1% aan fouten bij het extraheren van informatie bedrijven al miljoenen euro’s kosten. Daarom kan in veel gevallen de combinatie van het beste van mensen en het beste van kunstmatige intelligentie de beste resultaten opleveren.
Laten we een eenvoudige berekening uitvoeren. Stel dat je organisatie 1.000.000 documenten per maand verwerkt. Laten we aannemen dat elke fout je gemiddeld €100 kost. Slechts 1% van de fouten staat dan al gelijk aan €1.000.000.
Daarom geven sommige bedrijfstakken er de voorkeur aan automatisering te combineren met menselijke intelligentie om deze dure fouten tot een minimum te beperken.
Nu je de definitie van informatie-extractie en de methoden kent, laten we het geautomatiseerde proces met software eens nader bekijken.
Hoe extraheer je informatie automatisch?
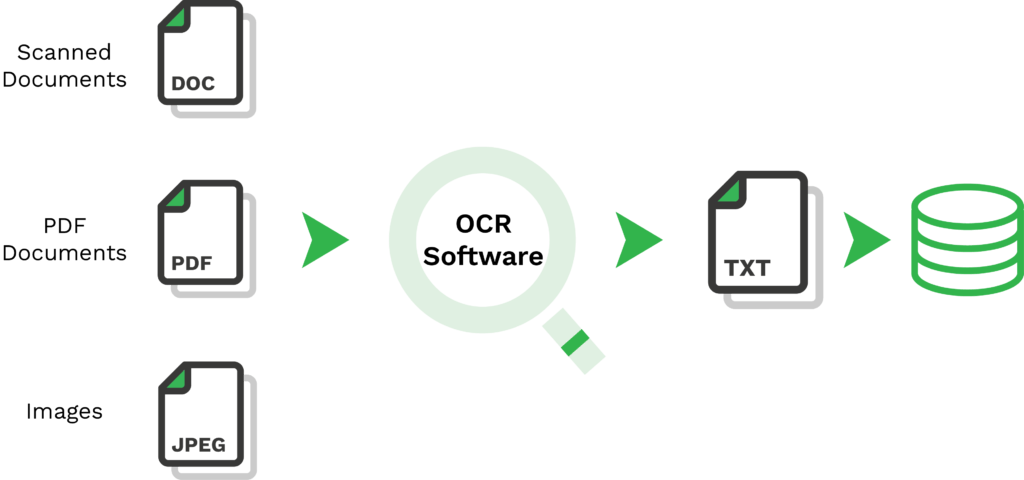
Met OCR-software kan je organisatie elk type document of afbeelding binnen enkele seconden automatisch verwerken. Maar hoe ziet het informatie-extractieproces eruit?
Het proces van informatie-extractie uit een document verloopt over het algemeen als volgt:
- Uploaden van het document – Eerst moet het ongestructureerde document worden geüpload naar de software. Dit kan gebeuren via het web, e-mail, computer of mobiele telefoon. Vaak is de eenvoudigste manier om dit te doen het maken van een foto met een mobiel apparaat met behulp van een SDK voor het scannen van documenten. Het invoerbestand kan naar de software worden gestuurd in verschillende ongestructureerde formaten, zoals JPG, PDF, PNG, TXT en vele andere.
- Afbeelding naar TXT – Nadat het document naar de software is geüpload, begint de feitelijke informatie-extractie. Het enige probleem is dat de computer nog niet kan lezen wat er op het document of de afbeelding staat. Daarom moet de afbeelding met behulp van OCR worden omgezet in een TXT-bestand.
- Conversie van informatieformaat – In de laatste stap leest de informatie-extractiesoftware het TXT-bestand en zet het bestand om in een gestructureerd formaat zoals JSON, XML en CSV. Zodra dit is gebeurd, wordt de informatie opgeslagen in een database of doorgegeven aan andere software.
Nu we weten hoe we informatie uit ongestructureerde tekstdocumenten kunnen halen, laten we eens kijken hoe dit jouw organisatie ten goede kan komen.
De voordelen van geautomatiseerde informatie-extractie
Veel bedrijven maken voor verschillende voordelen gebruik van geautomatiseerde informatie-extractie-oplossingen die worden aangedreven door AI.
De belangrijkste voordelen van het gebruik van een geautomatiseerde oplossing voor informatie-extractie zijn:
- Verbeter de nauwkeurigheid tot over 95%
- Verhoog de productiviteit van je werknemers met 6 uur per week
- Operationele kosten tot 70% verlagen
- Schaalbaarheid voor bedrijfsuitbreiding
- Snellere doorlooptijd
Verbeter de nauwkeurigheid tot over 95%

Door handmatige gegevensinvoer te vervangen door geautomatiseerde informatie-extractie worden kostbare fouten drastisch verminderd. Machines maken minder fouten dan mensen, omdat ze niet vermoeid of afgeleid raken.
Bij het handmatig verwerken van grote hoeveelheden informatie bestaat vaak de kans op fouten bij de gegevensinvoer. Een factuurnummer kan bijvoorbeeld gemakkelijk verkeerd worden getypt of over het hoofd worden gezien.
Automatisering van het proces om informatie uit documenten te halen, leidt tot nauwkeuriger gegevens. Met nauwkeurigere informatie kun je betere en preciezere zakelijke beslissingen nemen.
Verbeter je werknemer’s productiviteit met zes uur per week

Met geautomatiseerde informatie-extractie kunnen werknemers handmatige vervelende taken achter zich laten. Automatisering is niet alleen sneller, maar medewerkers kunnen in dezelfde hoeveelheid tijd meer ander werk gedaan krijgen.
Uit een onderzoek van Smartsheet blijkt zelfs dat het automatiseren van repetitieve taken zes of meer uur per week tijd vrijmaakt voor werknemers. Dat maakt een enorm verschil in productiviteit met bijna een volledige werkdag.
Verminder de operationele kosten met tot wel 70%
Een van de meest voorkomende redenen voor bedrijven om het extraheren van informatie te automatiseren is geld. Handmatige informatie-extractie betekent meer werknemersuren of zelfs het inhuren van meer mensen om handmatige taken uit te voeren.
Studies tonen aan dat handmatige informatie-extractie meestal leidt tot hogere verwerkingskosten, van 60% tot 70% meer dan een geautomatiseerd alternatief.
Schaalbaarheid voor de expansie van je bedrijf
Wanneer een bedrijf groeit, groeit ook de hoeveelheid inkomende en uitgaande documenten die verwerkt en opgeslagen moeten worden. Bedrijven willen hun personeelsbestand niet uitbreiden alleen maar omdat ze informatie uit meer documenten moeten halen. Dat zou het bedrijf afleiden van zijn kernactiviteiten.
Dit kan worden voorkomen door over te schakelen op een geautomatiseerde oplossing voor het extraheren van informatie. Daardoor kan het bedrijf zijn activiteiten uitbreiden zonder zich zorgen te hoeven maken over grote hoeveelheden documenten.
Snellere doorlooptijden
Het handmatig extraheren van informatie uit een document is beperkt tot één persoon tegelijk, wat kan leiden tot een lange doorlooptijd. Dat kan leiden tot papieren die zich opstapelen, werknemers of klanten die wachten op een antwoord, etc. Met software voor informatie-extractie kan de doorlooptijd van dagen of weken naar enkele seconden gaan.
Nu we de belangrijkste voordelen van geautomatiseerde informatie-extractie kennen, laten we eens kijken naar de gebruikssituaties ervan.
Toepassingen van informatie-extractie
Er zijn verschillende toepassingen waarin informatie-extractie een verschil maakt. Dit geldt niet alleen voor grote organisaties, maar in principe voor elk bedrijf dat met een aanzienlijke hoeveelheid documenten werkt. De kans is groot dat je werkt met informatiebronnen zoals facturen, bonnetjes, identiteitskaarten, meters van nutsbedrijven, prijskaartjes en identiteitsdocumenten.
Zie de volgende lijst voor enkele van de meest voorkomende toepassingen van informatie-extractie:
- Automatisering van de crediteurenadministratie
- Geautomatiseerde klantenregistratie
- Extractie van PDF naar Excel
- Conversie van beeld naar tekst
- Ontvangstverwerking voor loyaliteitscampagnes
- Automatisering van gegevensinvoer
- Informatie-extractie uit PDF
- Gegevensverzameling voor kartelschadeclaims
- Extractie van handtekeningen uit documenten
Het is heel interessant om te zien hoe verschillende toepassingen van geautomatiseerde informatie-extractie de winst van vele industrieën kunnen maximaliseren. Als je jouw gebruikssituatie hier niet ziet, geen zorgen, er is een grote kans dat we kunnen helpen met jouw specifieke situatie.
Laten we eens kijken naar onze oplossing, Klippa DocHorizon!
Geautomatiseerde informatie-extractie met Klippa
Klippa is gespecialiseerd in het automatiseren van informatie-extractie voor alle documentgerelateerde werkstromen. Met jarenlange toewijding is Klippa DocHorizon gecreëerd om organisaties over de hele wereld te helpen het proces van informatie-extractie uit verschillende objecten en documentstypen te versnellen.
Met Klippa DocHorizon kun je niet alleen informatie-extractie automatiseren, maar ook elk document classificeren, converteren, anonimiseren en verifiëren dankzij de in AI ingebouwde OCR-technologie. Het maakt niet uit voor welke uitdaging betreft documentsautomatisering je staat, Klippa kan het voor je automatiseren.
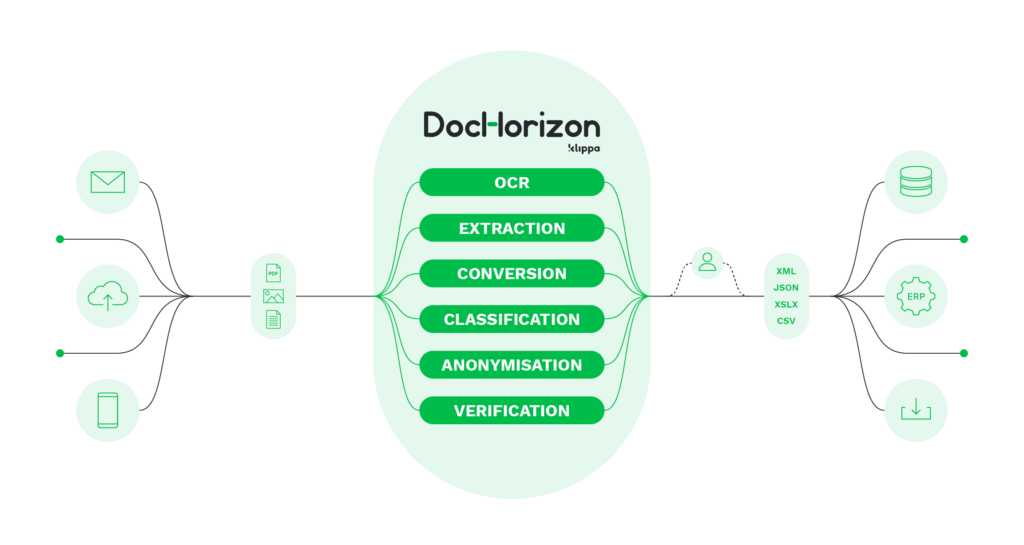
Als je organisatie op zoek is naar een oplossing om informatie uit documenten te halen, dan is DocHorizon de perfecte oplossing voor jou.
Plan een demo via onderstaand formulier om te zien hoe onze oplossing werkt. Als je vragen hebt, neem dan gerust contact met ons op!