Voor de meeste organisaties is het extraheren van informatie uit documenten een dagelijkse taak. Om deze taak efficiënter uit te voeren, zijn bedrijven overgestapt op automatisering. Data extractie wordt nu gedaan met behulp van moderne technologieën, zoals AI, Computer Vision of Natural Language Processor (NLP). Met behulp van automatisering kunnen bedrijven hun document-verwerkingstijd verkorten en de nauwkeurigheid van de geëxtraheerde gegevens vergroten.
Om de snelheid en efficiëntie van de workflow te verbeteren, gebruiken bedrijven vaak Named Entity Recognition (NER) om data-extractie processen te automatiseren. NER is een van de natuurlijke taalverwerking-technieken en kan zeer nuttig zijn voor organisaties die hun automatie mogelijkheden willen maximaliseren.
Als je niet bekend bent met de term Named Entity Recognition, of je weet niet zeker hoe je het moet implementeren, maak je dan geen zorgen. In deze blog behandelen we wat Named Entity Recognition is en hoe je een NER-model kunt bouwen of trainen. Daarnaast kijken we naar enkele mogelijkheden om NER te implementeren met behulp van code, namelijk nltk en spaCy.
Laten we beginnen.
Wat is Named Entity Recognition?
Named Entity Recognition is een, op NLP gebaseerde, techniek die wordt gebruikt om informatie in tekstdocumenten te extraheren, te identificeren en te categoriseren. Het detecteert entiteiten (d.w.z. delen van spraak) en classificeert ze in een vooraf bepaalde categorie, zoals naam of landcode.
NER-categorieën kunnen generiek zijn en bijvoorbeeld woorden aanduiden die een organisatie, persoon of tijd aanduiden. Ze kunnen echter ook worden aangepast aan een specifieke gebruikssituatie. Om je een voorbeeld te geven: het NER-model kan worden gebouwd om categorieën te herkennen zoals ‘naam van de patiënt’ en ‘geboortedatum’ op documenten in de gezondheidszorg of ‘naam van de verkoper’ en ‘aankoopdatum’ op facturen. De mogelijkheden zijn eindeloos.
Om de beste, meest nauwkeurige resultaten te krijgen, vereist Named Entity Recognition een grondige kennis van wiskunde, Machine Learning en beeldverwerking. De lijst houdt hier echter niet op. Named Entity Recognition kan gebaseerd zijn op meerdere methoden, dus laten we eens dieper ingaan op dit onderwerp en de verschillende benaderingen van NER ontdekken.
Verschillende NER-methodes
Zoals eerder vermeld, kan Named Entity Recognition gebaseerd zijn op meerdere methoden. Het verschil tussen deze methoden zit in de manier waarop het model is getraind om gegevensvelden nauwkeurig te identificeren en te extraheren.
- Woordenboek-gebaseerde methode – Bij deze methode wordt een woordenboek met een uitgebreide woordenschat gebruikt om het NER-model te trainen. Er wordt een basis algoritme voor string matching gebruikt om te controleren of een entiteit in de gegeven tekst overeenkomt met een item in het woordenboek.
- Regel-gebaseerde methode – Bij deze methode wordt een vooraf bepaalde set regels gebruikt voor informatie-extractie. Deze regels kunnen patroon-gebaseerd zijn, waarbij het morfologische patroon van de woorden wordt gebruikt, of context-gebaseerd, waarbij de context van het gegeven woord in het document wordt gebruikt.
- Machine Learning-gebaseerde methode – Deze aanpak is gebaseerd op statistieken en omvat twee stappen om NER uit te voeren. Eerst en vooral worden de bestanden die gebruikt worden voor het trainen van het model geannoteerd. Pas na deze procedure kan het NER-model beginnen met trainen op de geannoteerde gegevens. In de tweede stap kan het getrainde model zelf ruwe documenten annoteren.
- Deep Learning-gebaseerde methode – Tot slot is de op deep learning gebaseerde methode de meest nauwkeurige methode. Het is in staat om semantische en syntactische relaties tussen woorden in een gegeven tekst te begrijpen, maar is ook in staat om onderwerp-specifieke woorden te analyseren.
Named Entity Recognition lijkt een geweldig hulpmiddel om informatie nauwkeurig te extraheren.
Maar hoe werkt het eigenlijk? Inzicht in het proces achter dit model helpt bedrijven een beter idee te krijgen van wat Named Entity Recognition inhoudt. Laten we eens kijken wat de procedure is voor het bouwen en trainen van het NER-model.
Hoe bouw en train je een NER-model?
Het is tijd om te leren hoe je een NER-model vanaf nul opbouwt en traint. Eén van de meest gebruikte benaderingen voor het bouwen van een NER-model is het gebruik van een taalmodel, genaamd Bidirectional Encoder Representations from Transformers, ook bekend als BERT.
Een BERT-model is een vooraf getraind taalmodel dat kan worden verfijnd en bijgewerkt. Hierdoor kan het voorgetrainde model tekstpatronen beter begrijpen en context en betekenis analyseren. Het gebruikt in de kern de NER-techniek, maar biedt de mogelijkheid tot training en perfectionering, waardoor de nauwkeurigheid verbetert.
Laten we eens kijken naar de vijf stappen die nodig zijn om het Named Entity Recognition-model te bouwen en te trainen met behulp van het BERT-taalmodel:
- Data verzameling
- Input voorbereiding voor het NER-model
- Hyperparameters voor het NER-model initialiseren
- Training en voorspelling van het BERT-model
- Prestatie-inschatting voor het NER-model
Data verzameling
De eerste stap in elke procedure met op deep learning gebaseerde modellen, zoals BERT, is het invoeren van gegevens in het model. Op deze manier kan het algoritme de gegeven informatie verwerken en assimileren. Om vertrouwd te raken met entiteiten (namen, locaties, organisaties, landcodes) moet het model voorkennis hebben. Alleen dan kan het entiteiten in een context herkennen en onderscheiden.
Hoewel een BERT-model vooral wordt getraind op zinnen die de entiteit van interesse bevatten, bijvoorbeeld “persoon”, kan het ook worden getraind om woorden te herkennen met behulp van subwoorden. Laten we zeggen dat we de entiteit “persoon” hebben. Een subwoord voor deze entiteit zou de naam van een persoon zijn. Met voldoende training kan het model herkennen dat elk woord dat de naam van een persoon is, overeenkomt met de entiteit “persoon”. Daarom is er veel data nodig.
Input voorbereiding voor het NER-model
Voordat we naar de tweede stap gaan, is het belangrijk om te onthouden dat het NER-model een specifiek tagging-schema gebruikt, in tegenstelling tot andere modellen voor natuurlijke taalverwerking. De voorkeur gaat uit naar het IOB-formaat vanwege het gebruiksgemak. Het wordt vaak gebruikt voor het taggen van tokens (d.w.z. entiteiten, woorden) in een chunking-taak voor het NER-model.
Voor het geval je het je afvroeg, chunking is een NLP-proces dat wordt gebruikt om spraakdelen in een zin te identificeren. Spraakdelen verwijzen naar wat we kennen als zelfstandige naamwoorden, werkwoorden, bijvoeglijke naamwoorden enzovoort. Een chunking taak is daarom verantwoordelijk voor het identificeren van deze entiteiten en ze dienovereenkomstig te labelen.
IOB-indeling staat voor “Inside, Outside, Beginning” en gaat als volgt:
- Het voorvoegsel “I” voor een tag geeft aan dat het token zich binnen een chunk bevindt.
- “O” geeft aan dat een token niet bij een chunk hoort.
- Het “B” voorvoegsel voor een tag geeft aan dat de betreffende tag het begin van een chunk is en direct volgt op een andere chunk zonder het “O” voorvoegsel ertussen. Als een chunk echter volgt na een “O” prefix, krijgt het eerste token van de chunk een “I” prefix, in plaats van de “B”.

Een alternatief voor het IOB tagging schema is het gebruik van bestaande frameworks, zoals TensorFlow. In dit geval is het gebruik van pre-processor klassen nodig om de tagging uit te voeren.
Hyperparameters initialiseren voor het NER-model
De derde stap in het proces is het laden van het BERT-taalmodel in het programma en het initialiseren van hyperparameters. Deze hyperparameters vormen een benchmark voor het BERT-model, zodat de training nauwkeurig geëvalueerd kan worden.
Om de juiste parameters te vinden, moet het model worden verfijnd op basis van zijn prestaties op de gegevens die het heeft gekregen. De geannoteerde gegevens worden in het programma geladen om als tensors te dienen voor het trainen van het model op een diep neuraal netwerk. Een diep neuraal netwerk, of kortweg DNN, is een subset van Machine Learning en deep learning, dat gegevens op complexe manieren verwerkt door gebruik te maken van wiskundige modellering.
Om de nauwkeurigheid van de voorspelling van entiteiten te verbeteren, spelen deze hyperparameters een cruciale rol in het model.
Training en voorspelling van het BERT-model
Na het instellen van de hyperparameters is het tijd om het BERT-model te trainen. De training van het BERT-model bestaat uit twee fasen. Ten eerste het instellen van de trainingsrichtlijnen, gevolgd door de daadwerkelijke modeltraining.
- Bij het instellen van de trainingsrichtlijnen wordt een lus geschreven op basis van het aantal epochs. Een epoch is het aantal keren dat het leer-algoritme de volledige set met trainingsgegevens doorwerkt. In deze fase is het ook belangrijk om de grafische verwerkingseenheden (GPU’s) te controleren. Deze grafische verwerkingseenheden versnellen de rekenprocessen voor deep learning, waardoor het model wordt geoptimaliseerd voor snellere training.
- De volgende fase is de eigenlijke modeltraining. We moeten nu de eerder ingestelde parameters activeren en de verliesfunctie en optimalisatiefunctie initialiseren. Deze functies helpen de prestaties van het model te verbeteren, waardoor de nauwkeurigheid van de uitvoer toeneemt.
De verliesfunctie meet het verschil tussen de voorspelde uitvoer en de werkelijke uitvoer, terwijl de optimizer de parameters van het model aanpast om de verliesfunctie te minimaliseren.
In wezen is het belangrijkste doel om het model zo te trainen dat fouten worden geminimaliseerd en de nauwkeurigheid van de voorspellingen wordt verhoogd.
Prestatie-inschatting voor het NER-model
Tot slot moeten we een schatting maken van de prestaties van het model. Deze schatting kan op verschillende manieren worden gedaan, maar de meest gebruikelijke zijn het gebruik van een F1-score en een ontspannen match-score.
- F1 score – De F1 score is een evaluatiemetriek in ML die precisie en recall scores combineert. Het laat zien hoe vaak een model een correcte voorspelling heeft gedaan over de gehele dataset. Deze metriek is alleen nauwkeurig als elke klasse van de dataset hetzelfde aantal monsters heeft.
- Ontspannen match-score – Bij deze metriek wordt de prestatie berekend op basis van hoeveel entiteiten het model als het juiste entiteitstype heeft geïdentificeerd. Laten we eens kijken naar het volgende voorbeeld:
Laten we zeggen dat er 3 “persoon”-entiteiten en 2 “locatie-entiteiten in een gegeven tekst staan. Als het model in plaats daarvan 4 “persoonsentiteiten” en 1 “locatie-entiteit” identificeert, is de prestatie 75% van de 100%. De ontspannen match-score metriek herkent het model nog steeds als succesvol. Waarom is dat zo? Hoewel de exacte identificatie niet mogelijk was, herkende het model toch de 3 “persoonsentiteiten”, wat als een positief resultaat wordt gezien.
We hebben zojuist geleerd hoe we een Named Entity Recognition model vanuit het niets kunnen bouwen en trainen, met behulp van het BERT taalmodel. De echte truc zit hem in het implementeren van het NER-model. Laten we ontdekken hoe we dit op NLP gebaseerde model met behulp van code kunnen implementeren.
Implementatie van Named Entity Recognition
Het gebruik van code heeft de voorkeur als het gaat om het implementeren van NER. Hoewel er meerdere programmeertalen worden gebruikt voor deze actie, zullen we ons concentreren op twee specifieke talen, namelijk spaCy en nltk. Beide zijn gebaseerd op Python en maken het mogelijk om geavanceerde NLP-taken uit te voeren.
Named Entity Recognition Using spaCy
SpaCy is een open-source NLP bibliotheek voor geavanceerde natuurlijke taalverwerkingstaken in Python. Het wordt gebruikt voor verschillende taken en maakt gebruik van ingebouwde methoden voor Named Entity Recognition.
Een SpaCy model presteert goed op alle soorten tekstgegevens, maar het kan worden verfijnd voor specifieke categorieën. Als alternatief zijn er verschillende voorgetrainde modellen in spaCy die gebruikt kunnen worden om taken uit te voeren, zoals Named Entity Recognition of data extractie op specifieke gegevens.
Het is goed om in gedachten te houden dat om NER te implementeren met spaCy, het noodzakelijk is om de laatste versies van Python 3, Pip en natuurlijk spaCy te hebben. Bovendien is het ook aan te raden om spaCy core voorgetrainde modellen te downloaden om ze direct in de programma’s te gebruiken. Laten we beginnen!
Ten eerste gebruiken we een terminal of opdracht-prompt en typen we de volgende opdracht in:

Daarna voegen we de onderstaande code toe:
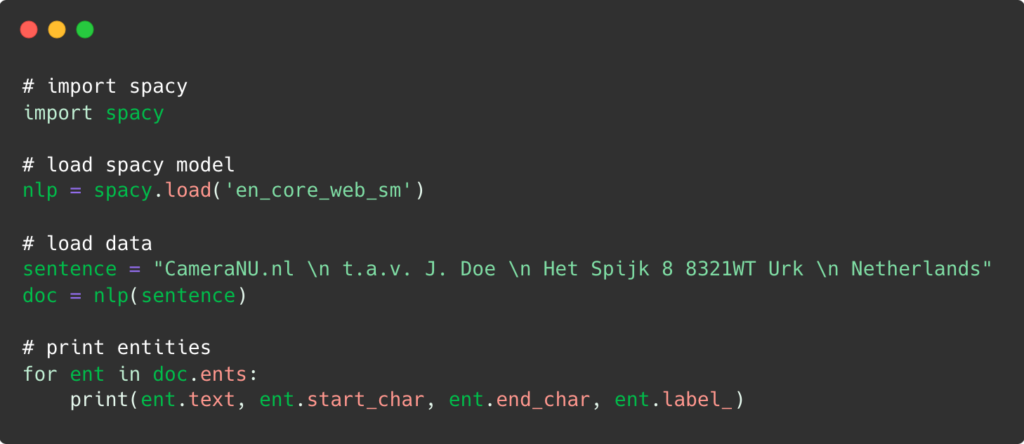
Nadat Named Entity Recognition de gegeven informatie heeft verwerkt, wat betekent dat het de tekst leest, de entiteiten identificeert en categoriseert, krijgen we de uiteindelijke uitvoer:

Dit is zo eenvoudig als het maar kan. Natuurlijk hangt de nauwkeurigheid van de geëxtraheerde en gecategoriseerde gegevens ook grotendeels af van hoe groot de tekst is. In dat geval kunnen we verschillende modellen gebruiken, afhankelijk van de grootte van de tekst:
En_core_web_sm – voor teksten van klein formaat
En_core_web_md – voor middelgrote teksten
En_core_web_lg – voor grote teksten
We hebben nu gezien hoe Named Entity Recognition kan worden geïmplementeerd met spaCy. Maar hoe zit het met het implementeren van NER met behulp van een ander Python-gebaseerd platform? Laten we eens kijken hoe de implementatie van NER eruit ziet met nltk.
Named Entity Recognition gebruikt nltk
Nltk is ook een, op Python gebaseerde, bibliotheek die natuurlijke taalverwerking-taken uitvoert. Deze taken variëren van het verwerken van tekstgegevens, het modelleren van gegevens of het taggen van delen van spraak. Qua extra configuraties is het eenvoudig en kan het breed gebruikt worden op verschillende besturingssystemen.
Om nltk te kunnen gebruiken voor het implementeren van NER, is het noodzakelijk om stabiele Python 3, Pip en nltk pakketten te installeren. Het implementeren van named entity recognition met nltk gebeurt in drie stappen.
Ten eerste moet nltk worden geïmporteerd en moeten de benodigde pakketten worden gedownload:

Nadat we alle benodigde pakketten hebben aangelegd, is het tijd om de gegevens te laden. In dit geval hebben we gekozen voor een zin die op een factuur staat.

Tot slot tokeniseert het platform de entiteiten binnen de gegeven tekst, vindt relevante spraakdelen en bakent woorden af binnen het document. Terwijl het de informatie verwerkt, wordt de volgende uitvoer gegenereerd:

We kunnen zien dat het gebruik van nltk om Named Entity Recognition te implementeren ook een eenvoudig proces is, hetzelfde als spaCy. Weten hoe NER werkt voegt echter geen waarde toe aan organisaties als ze de voordelen ervan niet erkennen. In de volgende sectie hebben we enkele van de belangrijkste gebruikssituaties uitgelicht waarbij Named Entity Recognition een grote hulp kan zijn voor organisaties.
Gebruikssituaties met NER
Voor bedrijven die hun bedrijfsprocessen willen verbeteren, kan Named Entity Recognition een grote aanwinst zijn. Het kan organisaties helpen bij het uitvoeren van taken zoals het parsen van gegevens, waardoor nauwkeurige automatisering van data invoer mogelijk wordt. Dit zijn slechts enkele voorbeelden van de voordelen van NER voor organisaties:
- Klantenservice – Bedrijven kunnen de klanttevredenheid verbeteren en de responstijd verkorten door gebruik te maken van NER. Het model onderscheidt klachten, vragen of verzoeken van gebruikers die via chatbots binnenkomen, door de trefwoorden die klanten gebruiken te identificeren en te categoriseren.
- Inhoud categoriseren – Content wordt eenvoudig ingedeeld in verschillende categorieën met Named Entity Recognition. Het algoritme leest het document en kan direct een blog onderscheiden van een e-mail of een dagboeknotitie. Dit model wordt gebruikt voor het archiveren van digitale bibliotheken, het aanbieden van aanbevelingen op streamingdiensten of online retailers.
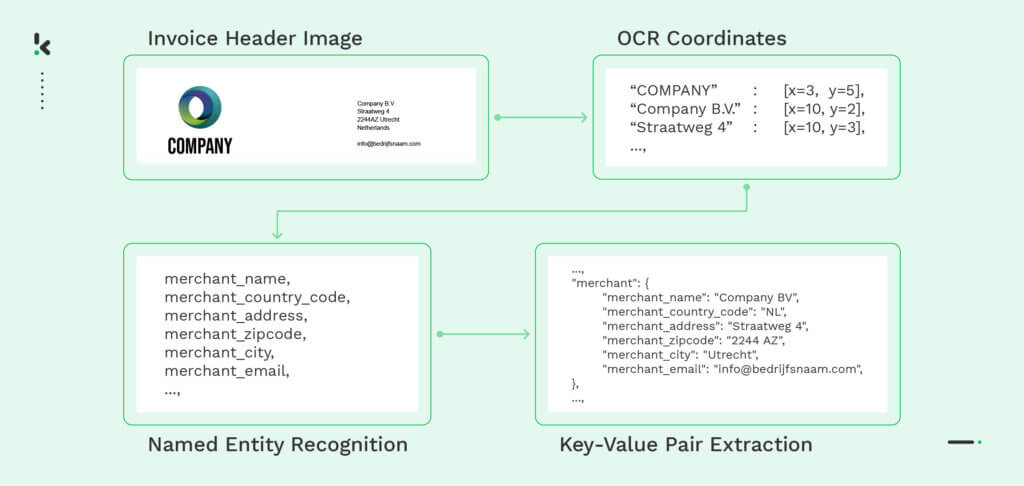
- Documentsclassificatie – Named Entity Recognition wordt getraind om verschillende soorten documenten te onderscheiden, zoals facturen, bonnetjes of paspoorten. Door simpelweg specifieke nummers of afzonderlijke gegevensvelden te identificeren, categoriseert NER de documenten in verschillende klassen.
- Bestanden parsen – In plaats van handmatig gegevens te extraheren uit ongestructureerde documenten, kan een bestand-parser met NER het bestand lezen en de belangrijkste informatie eruit halen. Bovendien kunnen ze de gegevens omzetten in een bruikbaar formaat voor verdere verwerking.
Limitaties met het bouwen van een NER-model
Een Named Entity Recognition-model vanaf nul opbouwen of trainen is niet onmogelijk, zoals we zojuist hebben geleerd. Het kan echter een uitgebreid proces zijn dat meerdere beperkingen met zich meebrengt:
- Het is duur – Een code vanaf nul opbouwen kan een kostbaar proces zijn, of het nu gaat om het intern creëren van de code of het uitbesteden ervan. Desalniettemin moeten financiële middelen worden besteed aan IT-experts of uitbestede code.
- Het is tijdrovend – Het kost veel tijd om een NER-model te trainen, laat staan vanaf het begin op te bouwen. Dit proces kan een potentieel nadeel zijn voor de meeste bedrijven, met name KMO’s.
- Kan kwetsbaar zijn voor datalekken – De keuze om een NER-model vanaf nul op te bouwen en te trainen kan leiden tot mogelijke datalekken. Als het model niet dienovereenkomstig wordt opgebouwd, kan het algoritme kwetsbaar worden voor oplichters en datalekken.
- Gebrek aan trainingsgegevens – Het verzamelen van voldoende trainingsgegevens om het NER-model te voeden is geen eenvoudige taak. Bedrijven moeten uiteindelijk op zoek naar een alternatief, waarbij ze meestal grote sommen geld investeren in het creëren van synthetische gegevens.
In plaats van een uitgebreide en nogal ingewikkelde procedure te doorlopen om een NER-model vanaf nul op te bouwen, kunnen bedrijven kiezen voor een kant-en-klare oplossing, namelijk OCR-software.
Hoewel er veel voorbeelden zijn van goed presterende OCR-software, zijn er maar een paar in staat om de noodzakelijke taken uit te voeren die Named Entity Recognition-technologie kunnen vervangen. Klippa DocHorizon is bijvoorbeeld in staat om gegevens te herkennen, te extraheren en te verifiëren, waardoor het niet meer nodig is om een gloednieuwe code te bouwen.
Klippa alternatief voor het NER-model
Klippa DocHorizon is een Intelligent Document Processing oplossing die AI gebruikt om document-gerelateerde workflows te automatiseren. Met behulp van OCR-technologie kunnen bedrijven mobiele documenten scannen, bestanden parsen, documenten verifiëren, gegevens maskeren en nog veel meer.
Met Klippa DocHorizon kunnen organisaties:
- Financiële, juridische, identiteitsdocumenten en vele andere documenten verwerken.
- Data extractie uitvoeren tot 99% nauwkeurig.
- Fouten bij het invoeren van gegevens minimaliseren.
- Documentsfraude voorkomen door de authenticiteit van documenten te verifiëren.
- Voldoen aan de privacyregels, omdat de verwerkte gegevens niet worden opgeslagen op de servers van Klippa.
In plaats van je te wagen aan een kostbaar en tijdrovend proces, kun je ook kiezen voor een alles-in-één oplossing voor Intelligent Document Processing. Boek hieronder een gratis demo of neem contact met ons op als je hulp nodig hebt bij je NER-gebruikssituatie!