Inmiddels heb je vast wel eens van OCR gehoord, maar het is misschien nog niet geheel duidelijk wat het is of hoe het voor jouw bedrijf van toegevoegde waarde kan zijn.
Simpel gezegd is het een tekstherkenning-systeem waarmee je bijvoorbeeld papieren documenten kunt omzetten naar digitale versies. Bedrijven gebruiken OCR vaak om gegevens van ontvangstbewijzen vast te leggen of uit documenten te halen en om kentekens te lezen.
Dus wat is OCR precies? OCR is een technologie die voortdurend evolueert en hele industrieën transformeert door handmatige processen te automatiseren. Tegenwoordig zijn er verschillende leveranciers die OCR-software en zelfs meer geavanceerde oplossingen, zoals Intelligent Document Processing (IDP), aanbieden. Maar waarom wordt het steeds vaker aangenomen in sectoren zoals het bankwezen, de detailhandel, de reissector, de juridische sector, en de gezondheidszorg?
In deze blog vind je alles wat je moet weten over OCR. We behandelen wat het is, hoe het werkt, de gebruiksmogelijkheden, de voordelen, en hoe je ermee kunt starten. Laten we beginnen!
Wat is Optical Character Recognition (OCR)?
Optical Character Recognition (OCR), ofwel optische tekenherkenning, is een technologie waarmee tekst in een handomdraai uit afbeeldingen of gescande documenten gehaald kan worden. Die tekst wordt dan omgezet in een formaat dat de computer kan lezen. Dit is handig als er gegevens nodig zijn voor verdere verwerking, zoals in de boekhouding, onkostenbeheer, loyaliteitsprogramma’s of identiteitscontrole.
In principe kun je handmatige documentatie dus terugdringen door OCR-software te gebruiken om letters, woorden, regels, zinnen en patronen te herkennen.
Vaak wordt de OCR-technologie gekoppeld aan Artificial Intelligence (AI) en Machine Learning (ML) om bepaalde processen te automatiseren en de nauwkeurigheid van de data-extractie te verhogen. Optimale tekstherkenning bereiken kost tijd en de OCR-technologie moet worden getraind door het te voeden met gegevens. Na verloop van tijd wordt het systeem steeds nauwkeuriger en beter.
Nu we hebben uitgelegd wat OCR is, is de volgende stap om je te laten zien hoe het werkt.
Hoe werkt OCR?
OCR werkt eigenlijk hetzelfde als het menselijk vermogen om een tekst te lezen, en patronen en tekens te herkennen. Normaal leest een mens de tekst en haalt er dan de nodige informatie uit door de gegevens handmatig in te voeren in een systeem, databestand of database.
Bij OCR gaat dit net een beetje anders. De technologie verbetert de kwaliteit van een gescande tekst of afbeelding en volgt dan verschillende stappen om de vastgelegde gegevens te extraheren. Het verschil is voornamelijk dat handmatig werk meer tijd kost en vatbaarder is voor menselijke fouten.
Laten we de volgende stappen van het OCR-proces eens in detail bekijken:
- Stap 1: Beeldbewerking
- Stap 2: Segmentatie
- Stap 3: Karakterherkenning
- Stap 4: Nabewerking
Stap 1: Beeldbewerking
Voor nauwkeurige data-extractie moet de kwaliteit van het beeld vaak worden verbeterd. Het verbeteren van afbeeldingen wordt ook wel de beeldbewerking genoemd. Hoe duidelijker en beter de afbeelding of het gescande document, hoe nauwkeuriger de data-entry.
In de beeldbewerkingsfase zoekt de OCR-engine automatisch naar fouten en corrigeert deze. De technieken die worden gebruikt om de afbeeldingen of gescande documenten te verbeteren, zijn onder meer:
- Deskew: Dit is het proces waarbij een foto of een gescand document wordt rechtgetrokken en de hoek wordt gecorrigeerd.

- Binarisatie: Binarisatie is het proces waarbij een afbeelding of een gescand document wordt omgezet in zwart-wit, waardoor de tekst beter van de achtergrond kan worden gescheiden.

- Zone: Dit is ook wel bekend als layout analyse. Dit wordt gebruikt om kolommen, rijen, blokken, bijschriften, paragrafen, tabellen en andere elementen te identificeren.

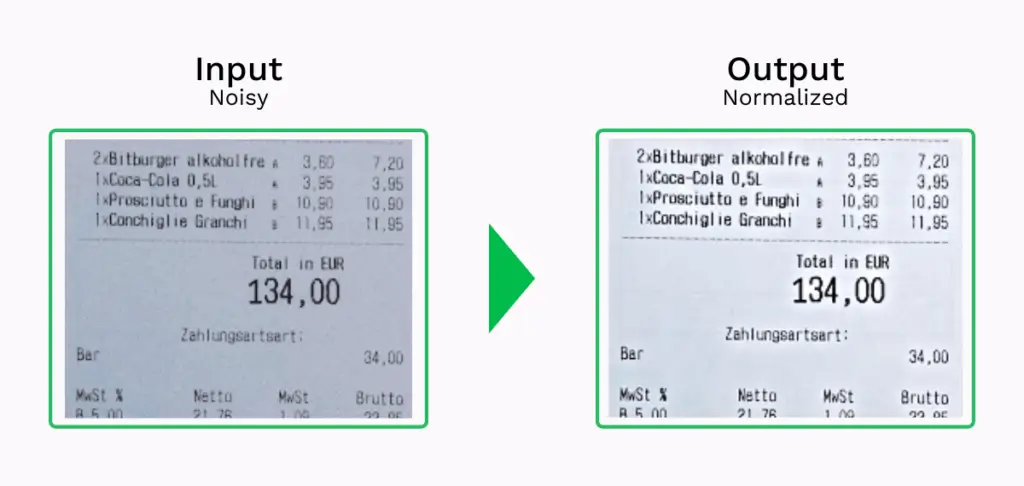
- Normalisatie: Het proces waarbij ruis wordt verminderd door de intensiteitswaarde van de pixels aan te passen aan de gemiddelde waarden van de omringende pixels.
Stap 2: Segmentatie
Segmenteren is een proces waarbij er één regel tekst tegelijk wordt herkend. Segmentatie omvat de volgende stappen:
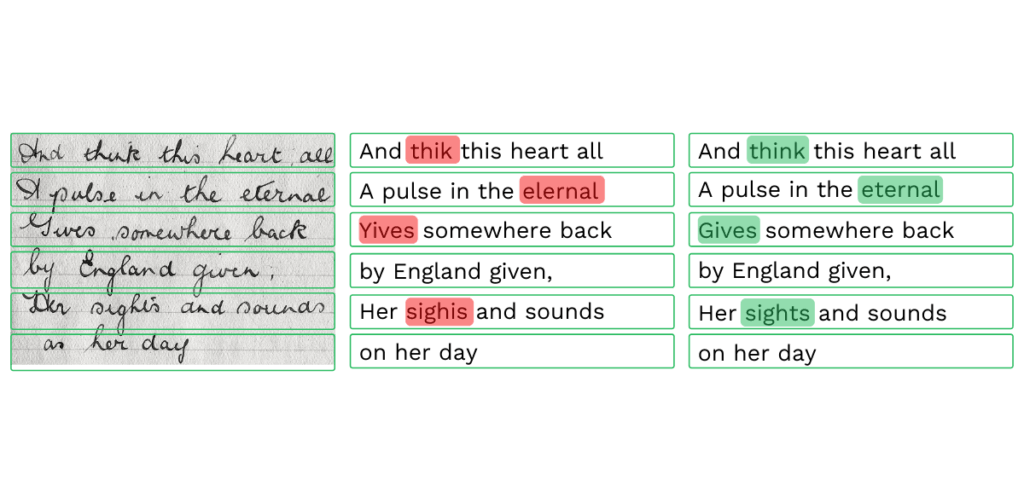
- Woord- en regelherkenning: Dit betreft de identificatie van de tekstregels en de woorden die daarbij horen.

- Script-herkenning: Dit is het proces van het identificeren van een script op basis van documenten, pagina’s, tekstregels, alinea’s, woorden, en tekens.

Stap 3: Karakterherkenning
In deze stap wordt een foto of document opgedeeld in delen, secties of zones. Nadat de scheiding is gemaakt, worden de tekens in hun eigen deel herkend.
In de tekenherkenning worden twee benaderingen gebruikt:
- Matrix-matching: Hierbij wordt elk teken vergeleken met een bibliotheek van teken-matrices. De OCR-engine voert een vergelijking per pixel uit om een afbeelding van een teken te labelen met het overeenkomstige teken.

- Kenmerkherkenning: Dit is het proces van het herkennen van tekstpatronen en kenmerken van tekens uit afbeeldingen. De grootte, hoogte, vorm, lijnen en structuur van een teken worden bijvoorbeeld vergeleken met die in de bestaande bibliotheek.
Stap 4: Nabewerking
Deze stap gaat om de technieken en de algoritmen die de nauwkeurigheid van de data-extractie verbeteren voor het optimale resultaat. Eerst worden de gegevens gedetecteerd en zo nodig gefixeerd.
De geëxtraheerde gegevens worden vergeleken met een vocabulaire of een bibliotheek van tekens voor grammaticacontrole en contextuele overwegingen om de fase van nabewerking af te ronden.
Hoewel traditionele OCR buitengewoon nuttig is bij het omzetten van afbeeldingen in machine readable tekst en waardevolle gegevens, heeft het ook enkele beperkingen. We zullen de belangrijkste hierna behandelen.
Beperkingen van OCR op basis van templates
De traditionele OCR was eigenlijk nooit bedoeld als een oplossing voor dynamische data-extractie. Het werd aanvankelijk uitgevonden voor blinden om tekens om te zetten in spraak. Later werd de technologie gebruikt om zwarte tekst tegen een witte achtergrond te lezen en te herkennen. OCR komt dus niet zonder uitdagingen.
Hier zijn de vijf belangrijkste beperkingen van traditionele OCR:
Afhankelijk van de invoer kwaliteit
De kwaliteit van de tekstherkenning en -extractie hangt af van de kwaliteit van de beeldinvoer voor de engine. De nauwkeurigheid daalt bijvoorbeeld drastisch wanneer de tekenhoogte lager is dan 20 pixels.
Afhankelijk van regels en templates
Voor traditionele OCR zijn regels en templates nodig. Er moeten strikte regels worden opgesteld door de engine te programmeren om gegevens uit de juiste velden en regels te halen. Daarom kan het diversiteit van documenten niet aan en heeft het moeite met ongestructureerde documenten.
Gebrek aan automatisering
Omdat traditionele OCR afhankelijk is van sjablonen en regels, mist het veel automatiseringsmogelijkheden. Als je bijvoorbeeld gestructureerde gegevens uit facturen wilt halen, is voor elk specifiek gegevensveld een nieuwe regel nodig. En, zoals je weet, zijn er facturen in verschillende stijlen en formaten, wat kan leiden tot enorm veel regels.
Meer regels toevoegen zou betekenen dat er meer gegevens en middelen nodig zijn om de OCR-engine te trainen. Er zullen altijd meer regels moeten worden ingesteld met de conventionele aanpak, dus dit kan een ernstig knelpunt worden.
Prijzig
Aangezien meer regels en algoritmen moeten worden ontwikkeld om de nauwkeurigheid te verhogen, kan traditionele OCR zeer duur worden. Bovendien garandeert het opstellen van deze regels en algoritmen niet altijd een uitvoer van hoge kwaliteit, aangezien dit ook afhangt van de kwaliteit van de beeldinvoer.
Moeite met grote verscheidenheid aan documenten
Met traditionele OCR is de uitvoer vaak zeer nauwkeurig wanneer de documenten eenvoudig zijn en weinig variaties bevatten. Veel bedrijven moeten echter verschillende documenten verwerken binnen hun workflows.
Hoe groter de verscheidenheid aan documenten, hoe moeilijker het wordt. Omdat de traditionele OCR-engine wordt getraind met templates, kan hij een grote verscheidenheid niet bijhouden.
Al met al kunnen we dus concluderen dat traditionele OCR niet perfect is. Maar laat dit je zeker niet ontmoedigen! Aangezien de markt elk jaar veeleisender wordt wat betreft eisen en functies, heeft OCR meerdere sprongen voorwaarts gemaakt om aan die vraag te voldoen.
Laten we kijken naar de meer geavanceerde OCR-technologie.
De volgende generatie van OCR technologie
De volgende generatie OCR-technologie is er al. Deze wordt vaak aangedreven door zowel Machine Learning als Artificial Intelligence, waardoor organisaties kunnen bereiken wat ze met traditionele OCR niet konden: automatisering. Deze revolutionaire technologie staat ook bekend als Intelligent Document Processing (IDP).
IDP kan resultaten leveren die de menselijke vermogens te boven gaan, zolang er rekening wordt gehouden met efficiëntie en tijd. Het maakt gegevens begrijpelijk, categoriseert, organiseert, en converteert de gegevens automatisch voor de gebruiker, en dat alles binnen seconden.
Eén van de belangrijkste verbeteringen is dat het niet beperkt is tot templates of regels zoals zijn conventionele voorgangers. Dit maakt de AI-gestuurde OCR-software schaalbaarder en betaalbaarder voor bedrijven.
Laten we de rol van Machine Learning en AI in moderne OCR-oplossingen eens van wat dichterbij bekijken.
De benadering van Machine Learning
Een OCR-software met Machine Learning (ML) kan worden getraind om patronen en de betekenis van gegevens te herkennen aan de hand van een reeks regels. Dit kan gebeuren via supervised learning, unsupervised learning, of een combinatie van deze twee trainingsmethoden.
Hier zullen we deze methoden uitleggen aan de hand van een voorbeeld. We beloven dat we zullen proberen het zo eenvoudig mogelijk te houden!
Supervised learning
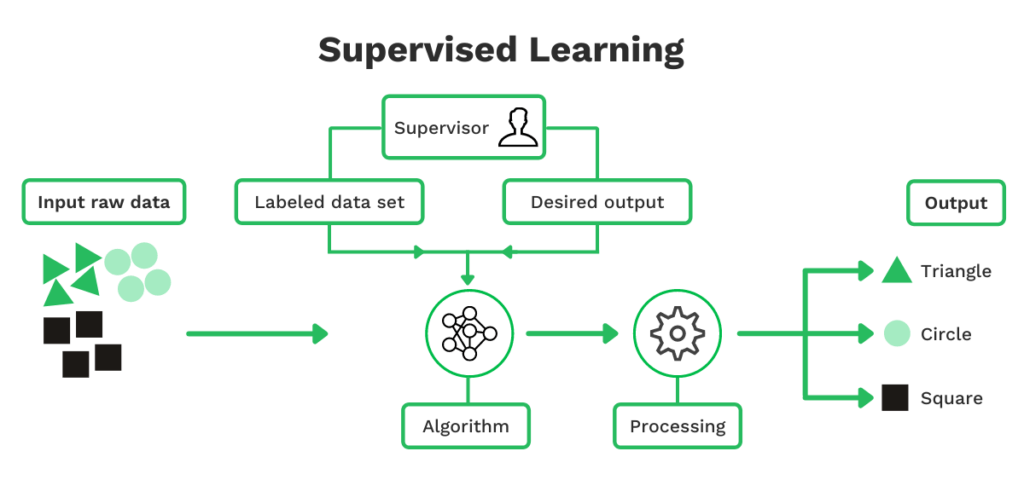
Supervised learning in ML verwijst naar het gebruik van gelabelde gegevenssets om algoritmen te trainen die gegevens classificeren en uitkomsten met hoge nauwkeurigheid voorspellen. Het model moet worden gevoed met een grote hoeveelheid invoer data om dit te bereiken.
Als je bijvoorbeeld wilt voorspellen of een e-mail spam is en deze in een categorie wilt onderbrengen, moet je de machine voeden met voldoende spammails. Met voldoende gegevens kan het model de categorie herkennen en voorspellen en zo een e-mail correct classificeren.
Een soortgelijke aanpak geldt voor het voorspellen van de plaats van de prijs van artikelen of de naam van de handelaar op kassabonnen.
Unsupervised learning
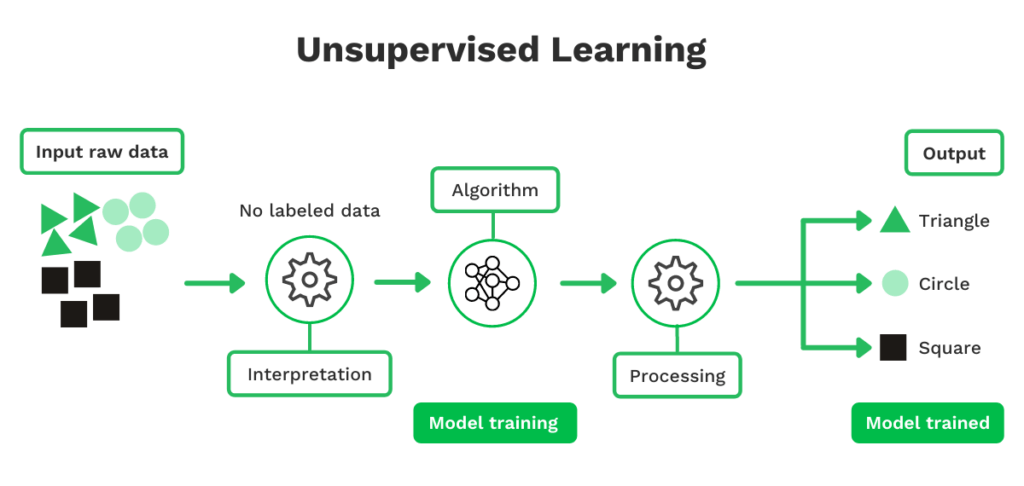
Unsupervised learning is in wezen vergelijkbaar met supervised learning. Het verschil is dat unsupervised learning ongelabelde, in plaats van gelabelde, gegevens gebruikt. Deze aanpak is nuttiger wanneer gemeenschappelijke eigenschappen binnen een gegevensreeks moeilijk te identificeren zijn, wat het model meer vrijheid geeft.
Ook al zijn labels voor datapunten niet gedefinieerd, de feitelijke datapunten blijven bestaan. Daarom kan het model patronen herkennen door de data-entry te observeren. Simpel gezegd kan unsupervised learning het menselijk vermogen tot aanpassen en leren nabootsen.
Als je bedrijf bijvoorbeeld ontvangstbewijzen moet verwerken, moet je het model voor unsupervised learning voeden met vele ontvangstbewijzen. Het model voor machine learning interpreteert dan de ingevoerde gegevens en maakt interpretaties van overeenkomsten.
Laten we zeggen dat het in staat is de handelsnaam en het totaalbedrag (ofwel de datapunten) te bepalen rond de exacte locatie op de kassabonnen. Het model gebruikt deze informatie dan om te voorspellen of het volgende document een kassabon is of niet, gebaseerd op de overeenkomsten.
Semi-supervised learning
Zoals de naam misschien al doet vermoeden, zijn de ingevoerde gegevens bij semi-supervised learning zowel gelabeld als ongelabeld. Het wordt vaak gebruikt om problemen met data-extractie aan te pakken bij grote hoeveelheden gegevens.
Omdat semi-supervised learning het beste van beide combineert, helpt het de uitdagingen van beide benaderingen aan te gaan: classificatie, tijd, kosten, en grote hoeveelheden gegevens.
Het wordt ideaal gebruikt voor gevallen waarin een klein aantal trainingsgegevens opmerkelijke resultaten kan opleveren wat betreft nauwkeurigheid.
Hoe weet je welke benadering van machine learning je moet kiezen? Het antwoord is eenvoudig: dat hoeft niet. Vooral omdat veel leveranciers out-of-the-box OCR-oplossingen bieden.
Nu we de rol van machine learning hebben uitgelegd, behandelen we hierna de rol van AI.
AI voor automatie
Met AI in de OCR-software kan het systeem zich voortdurend aanpassen en leren om gegevens nauwkeuriger te herkennen. Het kan een gevorderd begrip van semantiek ontwikkelen en het aanbod aan ondersteunde talen, formaten, lay-outs, en documenttypes uitbreiden.
AI stelt de OCR-software of het systeem in staat alle beschikbare gegevens te analyseren, verbanden te vinden, en een uitgebreide kennisbank aan te leggen. De kennisbank die AI creëert kan zich in de loop der tijd aanpassen, wat kan helpen bij de vooruitgang van de nauwkeurigheid van de data-extractie.
Het beste deel van AI is dat het de menselijke capaciteiten nabootst om de belangrijkste inzichten met hoge snelheid en nauwkeurigheid te scannen en te begrijpen.
Wat je zakenmodel ook is, een OCR-systeem aangedreven door AI kan je helpen de gegevens voor je te laten werken.
Nu we ML en AI hebben behandeld, laten we eens kijken naar wat de voordelen zijn wanneer beide zijn ingebouwd in de OCR-oplossing.
Voordelen naast conventionele OCR
Naast conventionele OCR technologie kunnen geavanceerde OCR-systemen nog veel meer. Om je een idee te geven van hoe voordelig het is om deze technologie te gebruiken in je documentverwerking, hebben we hieronder een lijst met voordelen opgesteld:
Digitaliseer documenten binnen seconden: Met de OCR-software kan je organisatie gegevens uit documenten halen en in een gedigitaliseerd formaat transformeren, en op die manier papierloos worden. Dit proces kan binnen enkele seconden worden uitgevoerd.
Snellere implementatietijd: Meer geavanceerde OCR-oplossingen zijn niet alleen afhankelijk van regels en templates. Het kost dus minder tijd om het programma te trainen en de technologie goed te implementeren.
Schaalbaarheid: De volgende generatie OCR-systemen biedt schaalbaarheid, waar zijn conventionele voorganger aanzienlijk achterblijft. Hoewel het mogelijk is om te schalen met OCR op basis van templates, kan dit snel te prijzig worden voor veel bedrijven.
Hogere nauwkeurigheid: Terwijl conventionele OCR een data-extractie nauwkeurigheid heeft van 60% tot 85%, kunnen veel meer geavanceerde oplossingen met AI en Machine Learning tot 99% halen. Hoewel handmatige data-extractie ook een nauwkeurigheid van 90%-95% oplevert, is dit voor veel bedrijven veel langzamer en inefficiënt.
Vermindering van handmatige invoerfouten: Fouten komen vaak voor wanneer mensen werken aan vervelende en repetitieve taken, zoals het handmatig invoeren van gegevens. OCR kan deze taken automatiseren, waardoor menselijke fouten worden verminderd. Met AI en Machine Learning kan het foutenpercentage nog verder worden teruggebracht.
Snellere doorlooptijd: Traditionele document-verwerking werkstromen hebben vaak veel trage en omslachtige taken die problemen opleveren. Het handmatig verifiëren en extraheren van gegevens kan zo 10 tot 20 minuten per document in beslag nemen, terwijl traditionele OCR dat in minder dan de helft van de tijd kan. IDP kan dat zelfs binnen 15 seconden, wat uiteindelijk neerkomt op 98% van de bespaarde tijd.
Kostenbesparing: Aangezien AI-gestuurde OCR snellere doorlooptijden mogelijk maakt, vervelende taken automatiseert, en fouten in de data-entry minimaliseert, worden de algemene kosten aanzienlijk verlaagd. Dit brengt ons bij een van de belangrijkste voordelen voor organisaties, namelijk kostenreductie. Bij handmatige document-verwerking kunnen de kosten per document variëren van 4 tot 6 euro. Traditionele OCR kan de kosten per document terugbrengen tot 1 tot 2 euro en IDP zelfs tot minder dan 0,50 euro.
Fraudedetectie: Bedrijven verliezen jaarlijks enorme bedragen aan document-fraude. Meer geavanceerde OCR kan dit probleem helpen aanpakken met fraudedetectie via beeld- en EXIF-analyse. Zo kun je voorkomen dat je kapitaal verliest aan zowel interne als externe fraude.
Verbeterde klantervaring: Er zijn veel zakelijke gevallen waarin in AI ingebouwde OCR helpt de klantervaring te verbeteren. Wanneer banken bijvoorbeeld nieuwe klanten aannemen, maakt de technologie het aanneem-proces soepeler en flexibeler door middel van mobiele integratie.
Vergelijking document verwerkingsmethoden
We hebben al verschillende voordelen van de volgende generatie OCR-technologieën behandeld. Maar er is nog steeds een scala aan methoden en oplossingen om documenten te verwerken, en het vinden van de juiste kan overweldigend zijn. Om jou het leven gemakkelijker te maken, hebben we een vergelijkingstabel van de verschillende methoden gemaakt.
Kortom, OCR-technologie kan bedrijven veel voordelen opleveren. Meer geavanceerde technologieën zoals IDP presteren echter veel beter dan de traditionele oplossingen. Natuurlijk is geen enkele oplossing perfect, daarom wordt de OCR-technologie voortdurend verbeterd om bepaalde beperkingen te overwinnen.
Nu we de belangrijkste voordelen hebben behandeld, is het tijd om enkele van de meest voorkomende gebruikssituaties door te nemen.
Waarvoor wordt OCR gebruikt?
Elke repetitieve taak met een hoog volume waarbij documenten worden verwerkt kan standaard worden geautomatiseerd met OCR-software met Artificial Intelligence. We lichten hieronder enkele gebruikssituaties uit om je te inspireren om een OCR-systeem te gaan gebruiken voor soortgelijke procedures binnen jouw organisatie:
- OCR voor loyaliteitsprogramma’s
- Data-extractie van ID’s voor klantverificatie
- Geautomatiseerde factuurverwerking voor de crediteur
- Automatisering van compleetheid-checks
OCR en loyaliteitsprogramma’s
Loyaliteitsprogramma’s bestaan in vele soorten en maten. In de meeste gevallen gaat het om een op punten gebaseerde campagne of een cashback-actie. Klanten moeten hun kassabon naar de winkelier sturen en krijgen in ruil daarvoor een beloning voor de aankoop van het product.
Je kunt je voorstellen dat dergelijke programma’s meestal veel werk achter de schermen met zich meebrengen. Het aankoopbewijs moet worden gecontroleerd, de klantendatabase moet worden bijgewerkt, de cashback of punten moeten worden bepaald en toegekend, etc. In dat geval is OCR van kassabonnen via een scan-hulp optimaal om de vervelende en foutgevoelige back-office-taken over te nemen.
Organisaties die moeten controleren of de consumenten de producten in het loyaliteitsprogramma daadwerkelijk hebben gekocht, hoeven de kassabonnen niet langer handmatig te controleren. OCR kan de regels en items van kassabonnen scannen en zo nagaan of de producten binnen de periode van de campagne zijn gekocht.
Gegevensvelden die kunnen worden geëxtraheerd zijn onder andere:
- Taal bij ontvangst
- Land van herkomst
- Handelsnaam
- Wijze van betaling
- BTW-bedragen en -percentages
- Valuta
- Totaalbedrag
- Aankoopdatum
- Artikelen
Sommige OCR-leveranciers, zoals Doxis, kunnen organisaties ook helpen fraude te voorkomen door detectie van duplicaten op basis van hashing van afbeeldingen. Met de vroegtijdige detectie van fraudepogingen wordt het verlies van tijd en geld geminimaliseerd.
Data-extractie van ID’s voor klantenverificatie
Organisaties in de financiële sector, zoals banken, moeten bij het aannemen van nieuwe klanten hun identiteit verifiëren om er zeker van te zijn dat deze klanten zijn wie zij beweren te zijn.
Dit proces staat ook bekend als het Know Your Customer (KYC) proces. Het verifiëren van de identiteit van klanten en het handmatig invoeren van gegevens in meerdere systemen voor kruisvalidatie kan inefficiënt en tijdrovend zijn.
Daarom wordt OCR in het proces gebruikt: om de doorlooptijd te versnellen en de instroom van nieuwe klanten te vergroten. Met OCR-software kunnen financiële instellingen eenvoudig en binnen enkele seconden gegevens van ID’s scannen en automatisch extraheren.
Gegevensvelden die kunnen worden geëxtraheerd zijn onder andere:
- Volledige naam
- Nationaliteit
- Geboortedatum
- Datum van afgifte
- Plaats van afgifte
- Geldig tot
- Documentnummer
- Sofinummer (SSN)
- Machine-leesbare zone (MRZ)
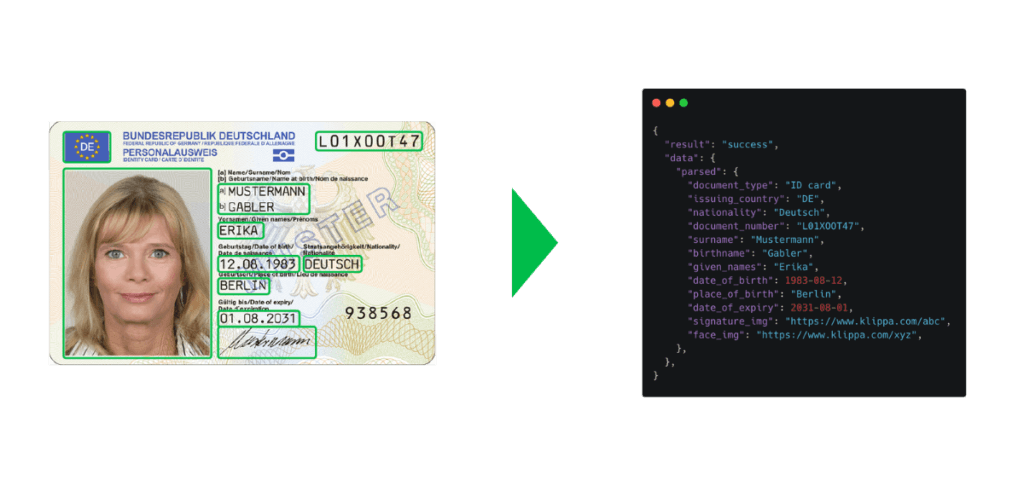
Nadat de gegevens zijn geëxtraheerd, kunnen ze ook worden getoetst aan fraudedatabases of zwarte lijsten om pogingen tot fraude aan het licht te brengen en te voorkomen.
OCR-technologie is tegenwoordig sterk geïntegreerd in KYC-automatisering wanneer het merendeel van de onboarding van klanten digitaal gebeurt.
Geautomatiseerde factuurverwerking voor de crediteur
De crediteur van een organisatie keurt facturen goed voordat ze worden betaald. Dit proces kan ingewikkeld en tergend langzaam zijn. Facturen die binnenkomen moeten georganiseerd, gecontroleerd, gecorrigeerd, goedgekeurd door de juiste persoon, betaald, en uiteindelijk toegevoegd worden aan de boekhouding van het bedrijf.
Met OCR-technologie kunnen bedrijven hun AP-workflow stroomlijnen en automatiseren en handmatige taken elimineren door automatisch gegevens van facturen vast te leggen. Je kunt de software gewoon voorzien van de facturen, en de software doet de rest: van digitalisering tot het verzenden van de uiteindelijke output naar je Enterprise Resource Planning (ERP) of boekhoudsysteem.
Een rapport van MineralTree geeft aan dat 64% van de organisaties met AP-automatisering meer facturen verwerkt dan die zonder, en 23% verwerkt dezelfde hoeveelheid facturen met minder personeel.
Wij hebben soortgelijke cijfers gevonden via ons interne onderzoek. Door je factuurverwerking voor de crediteurenadministratie te automatiseren, verminder je de tijdsbesteding tot 70%, verkort je de doorlooptijd van dagen tot minuten, minimaliseer je fouten en realiseer je een kostenbesparing van meer dan 70%.
Automatisering van volledigheidscheck
In sectoren zoals de juridische en de banksector wordt veel tijd besteed aan het controleren van de volledigheid van documenten om na te gaan of deze alle vereiste informatie bevatten. Zo moet een juridisch contract de handtekeningen bevatten van alle partijen die de overeenkomst aangaan.

Het niet slagen voor volledigheidscontroles kan ernstige gevolgen hebben. Zonder de handtekeningen van beide partijen, bijvoorbeeld, wordt een contract een nutteloze stapel papieren, en is het wettelijk niet aanvaardbaar.
Hier komt OCR om de hoek kijken. Het neemt de taak van het controleren en het valideren van de originaliteit en compleetheid van een document over. Het kan binnen een paar seconden detecteren of er handtekeningen op een document staan en of er cruciale informatie, zoals een belangrijke clausule, ontbreekt.
Om je een volledig beeld te geven, OCR-aanbieders kunnen de volgende taken voor de controle op volledigheid automatiseren:
- Controleren van het aantal documenten
- Classificeren van het type document
- Identificeren van het aantal pagina’s per document
- Valideren van de aanwezigheid van specifieke velden, waarden, regels of onderdelen (handtekeningen of afbeeldingen)
- Gegevens tussen documenten kruisen met een externe of interne database
We kunnen hieruit dus concluderen dat OCR voor vele doeleinden en gebruikssituaties kan worden benut. Heeft dit je nou geïnspireerd om op zoek te gaan naar automatiseringsmogelijkheden binnen jouw organisatie? Dan is de laatste vraag hoe je aan de slag gaat. Om daarbij te helpen, behandelen we in de volgende paragraaf verschillende manieren om OCR-technologie te integreren.
De cruciale rol van nauwkeurigheid in OCR
Hoewel OCR-technologie indrukwekkende mogelijkheden biedt, staat en valt het succes ervan met de nauwkeurigheid van de herkenning. Een fout in de interpretatie van tekens kan grote gevolgen hebben, vooral in datagedreven processen waar precisie essentieel is. Of het nu gaat om het digitaliseren van facturen, juridische documenten of medische dossiers, de kwaliteit van de output bepaalt de betrouwbaarheid van de gehele workflow. Daarom is het verbeteren van OCR-nauwkeurigheid geen luxe, maar een noodzaak.
De nauwkeurigheid van OCR bepaalt dus rechtstreeks de kwaliteit en betrouwbaarheid van de outputdata. Slechte OCR-herkenning kan leiden tot:
- Verhoogde foutmarges: Handmatige correcties zijn vaak nodig, wat inefficiëntie en extra kosten veroorzaakt.
- Vertragingen in processen: Onjuiste data-invoer leidt tot extra verificatielagen en vertragingen in workflows.
- Impact op besluitvorming: Inaccurate data kan resulteren in slechte zakelijke beslissingen, wat uiteindelijk het succes van projecten beïnvloedt.
Het verbeteren van OCR-nauwkeurigheid helpt organisaties niet alleen om operationele efficiëntie te verhogen, maar ook om betrouwbaarheid in gegevensbeheer te waarborgen.
Effectieve manieren om OCR-nauwkeurigheid te verbeteren
Hieronder vindt u een overzicht van de belangrijkste strategieën om OCR-resultaten te optimaliseren.
1. Kwaliteit van de bronafbeelding verhogen
De kwaliteit van de invoerafbeelding is de meest kritische factor voor OCR-nauwkeurigheid. Hoe beter de afbeelding, hoe hoger de kans dat OCR-software tekens correct herkent.
- Gebruik een camera met een hoge resolutie om wazige of vervormde tekst te vermijden.
- Zorg ervoor dat tekst goed contrasteert met de achtergrond.
- Vermijd schaduwvorming en overbelichting, aangezien deze OCR-prestaties kunnen verminderen.
- Streef naar een minimale tekenhoogte van 20 pixels voor optimale herkenning.
2. Afbeeldingen vastleggen in een gecontroleerde omgeving
Een gecontroleerde opnameomgeving helpt om ruis te minimaliseren en zorgt voor heldere, leesbare afbeeldingen.
- Maak foto’s op een vlak oppervlak om vervorming te voorkomen.
- Gebruik een neutrale en egale achtergrond om afleiding te minimaliseren.
- Vermijd schokkende of trillende bewegingen bij het vastleggen van afbeeldingen.
- Zorg voor voldoende verlichting, bij voorkeur natuurlijk licht of een goed geplaatste kunstmatige lichtbron.
3. Realtime feedback voor gebruikers bieden
Veel OCR-oplossingen kunnen real-time feedback geven aan gebruikers om de kwaliteit van de afbeelding te optimaliseren voordat deze wordt verwerkt. Dit helpt bij het minimaliseren van fouten en vermindert de behoefte aan handmatige correcties.
- Meldingen zoals “Houd de camera stil” of “Te donker, schakel flitser in” helpen gebruikers betere beelden vast te leggen.
- Automatische detectie van slechte beeldkwaliteit kan heropnames stimuleren.
- Slimme OCR-apps kunnen gebruikers begeleiden met visuele aanwijzingen om de perfecte opnamehoek en afstand te behouden.
Aanvullende strategieën voor een hogere OCR-precisie
4. Configuratie van taal- en karaktermodellen
OCR-software die specifiek is geoptimaliseerd voor bepaalde talen, karaktersets en zelfs vak-specifieke termen presteert beter.
- Taaloptimalisatie: Zorg ervoor dat het OCR-model is getraind op de relevante taal of tekenset.
- Herkenning van speciale tekens: Sectoren zoals financiën en recht vereisen herkenning van complexe tekens, zoals valuta- en wiskundige symbolen.
5. Inzet van AI en machine learning
Machine Learning (ML) en Artificial Intelligence (AI) maken OCR-systemen slimmer en adaptiever.
- Natural Language Processing (NLP): Dit helpt bij het begrijpen van context in tekst, waardoor fouten worden gereduceerd.
- Zelflerende algoritmes: OCR-oplossingen kunnen fouten analyseren en deze inzichten toepassen om nauwkeurigheid te verbeteren.
- Adaptieve herkenningstechnologie: Vergelijkt onbekende woorden met een database om de meest waarschijnlijke interpretatie te bieden.
6. Pre-processing en nabewerking
Naast een goede opnameomgeving zijn softwarematige bewerkingen van afbeeldingen essentieel.
- Ruisonderdrukking: Verwijdert storende pixels en verbetert de tekstweergave.
- Contrastoptimalisatie: Verhoogt het contrast tussen tekst en achtergrond.
- Automatische correcties: Zoals rotatie, bijsnijden en belichtingsbalans voor betere herkenning.
7. Validatie en menselijke controle
Zelfs met geavanceerde technologie zijn menselijke input en validatie belangrijke hulpmiddelen bij complexe OCR-processen.
- Menselijke validatie: Laat kritieke gegevens handmatig controleren om fouten op te vangen.
- Hybride workflow: Combineer automatisering met menselijke verificatie, ook wel Human-In-The-Loop, voor optimale resultaten.
Hoe start je met het integreren van OCR?
Wanneer je overweegt OCR in je bedrijf te integreren, moet je met verschillende zaken rekening houden. Dergelijke factoren zijn bijvoorbeeld het type document, het volume van de documentverwerking per maand, de middelen van je organisatie, je gebruikssituatie, enzovoort.
Om je te helpen hebben we de volgende opties opgesomd:
- Integratie van OCR API
- Mobiele-scan-mogelijkheden
- Alles-in-één oplossing
Integratie van OCR API
Met OCR API integratie kun je documenten verwerken door ze te versturen via een mobiele app, e-mail, en webapplicatie. Vaak is dit de beste keuze als je een al bestaande software of applicatie hebt waarin je de OCR-technologie wilt integreren.
Wat een Application Programming Interface (API) doet, is dat het je software of applicatie in staat stelt te communiceren met de OCR-leverancier en hun technologie gebruikt voor je documentverwerking.
Hoewel het ingewikkeld klinkt, kun je de gegevens van documenten binnen enkele seconden in een gestructureerd formaat terugontvangen.
Mobiele-scan-mogelijkheden
Mobiele-scan-mogelijkheden ondersteunen gebruikssituaties waarin organisaties een flexibele manier nodig hebben om gegevens vast te leggen. Je medewerkers hoeven bijvoorbeeld kassabonnen niet meer fysiek op te slaan, omdat ze in plaats daarvan simpelweg een foto van de kassabon kunnen maken.
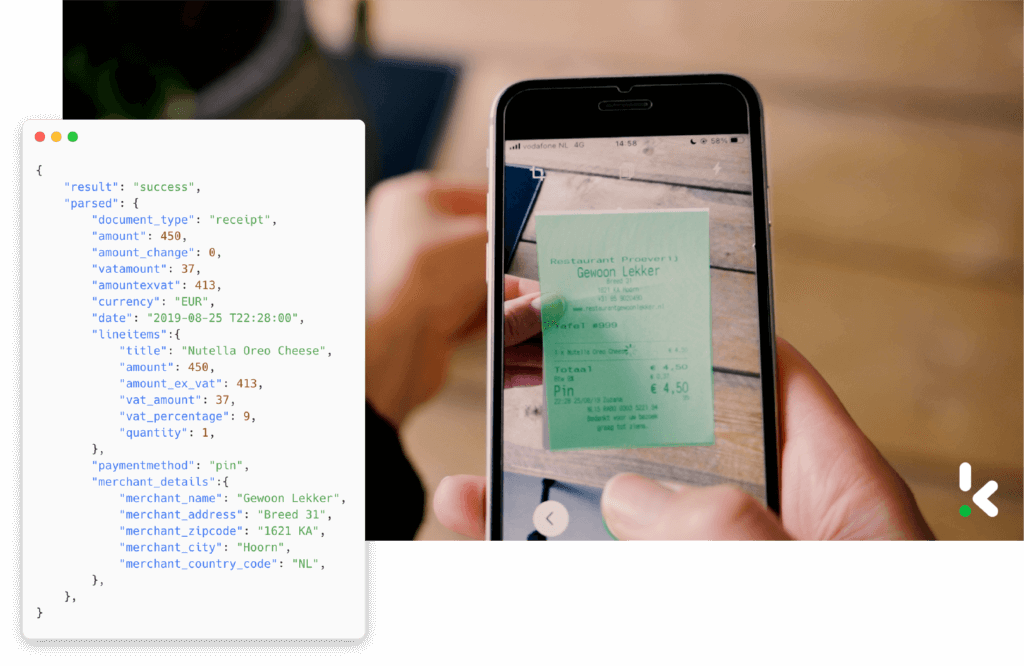
Het proces van teruggaan naar het kantoor met bonnetjes om een vergoeding aan te vragen kan hierdoor worden geëlimineerd. Dit bespaart natuurlijk tijd en verlaagt de algemene kosten.
Voor de integratie van de mobiele-scan-mogelijkheid heb je een goed gedocumenteerde Software Development Kit (SDK) nodig. Deze is goed aan te passen, en met de hoogwaardige functies voor beeldvoorbewerking kun je documenten of zelfs objecten, zoals elektriciteitsmeters, scannen.
Een SDK is de beste keuze als je een AI-ondersteund OCR-systeem wilt gebruiken in je mobiele toepassing. Aan de andere kant is een API geschikter als je alleen documenten wilt uploaden via een webportaal of applicatie in plaats van documenten te scannen met een mobiel apparaat.
Alles-in-één oplossing
Met een alles-in-één oplossing kun je relatief moeiteloos en snel aan de slag. Het enige wat je hoeft te doen is een OCR software vendor vinden die je kan helpen met je business case.
Een complete oplossing zoals Doxis AI.dp kan bedrijven bijvoorbeeld helpen bij het stroomlijnen van hun document-verwerking. De geavanceerde technologieën kunnen data-extractie, classificatie, conversie, anonimisering, en verificatie automatiseren.
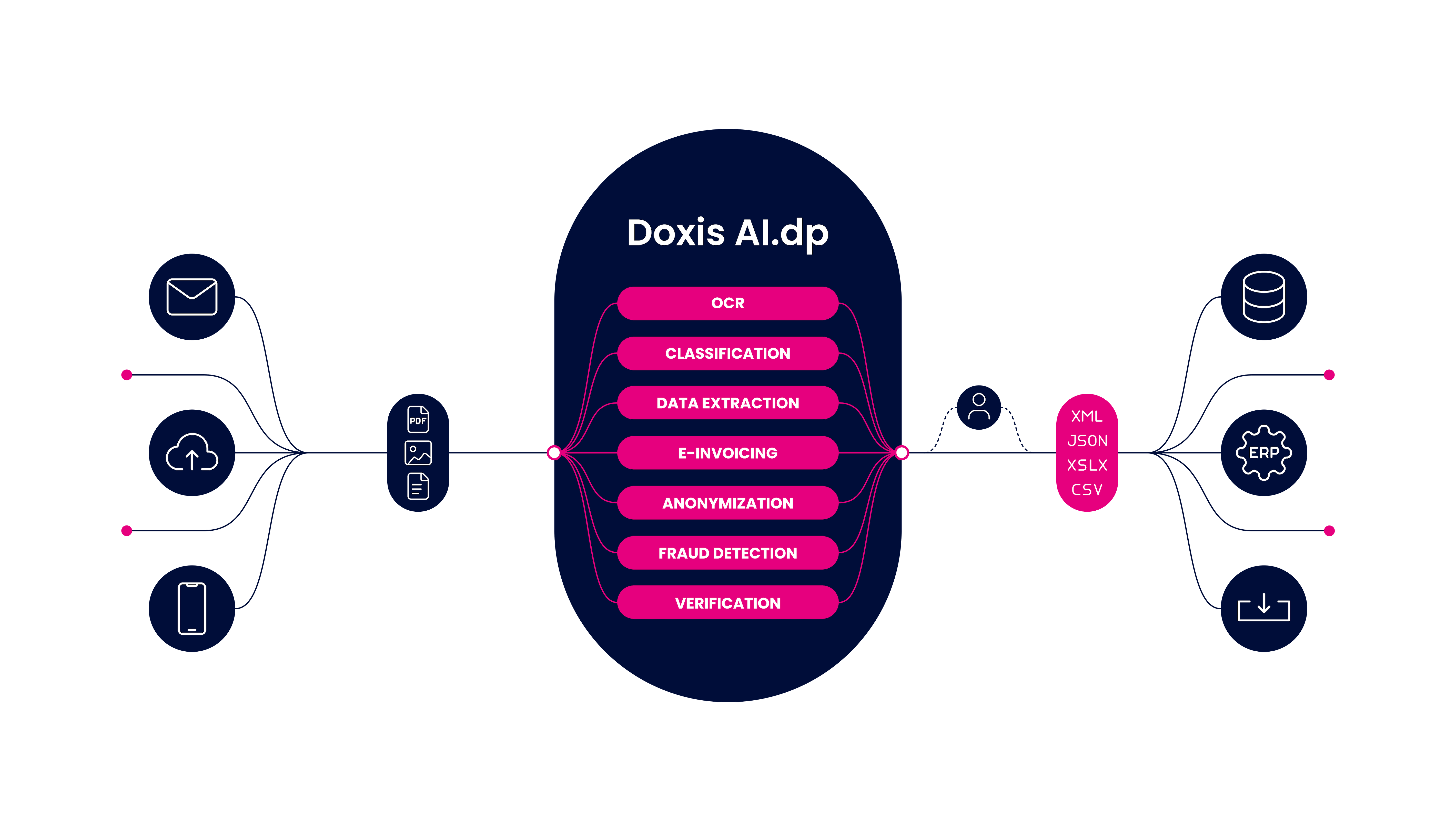
Traditionele OCR voorbij met Doxis
Traditionele OCR is gedateerder dan ooit tevoren. Bedrijven moeten een manier vinden om het resultaat en de klantervaring te verbeteren en om tegelijkertijd tools in te bouwen die de efficiëntie in de organisatie verhogen.
Dit is waar Doxis kan helpen. Of je nu de OCR-technologie wilt integreren via een API, SDK, of gewoon meteen aan de slag wilt met een end-to-end oplossing, bij Doxis kan het allemaal.
Werk samen met Doxis om van jouw medewerkers de kampioenen in documentverwerking te maken. Ga aan de slag door het onderstaande demoformulier in te vullen!