
Onderzoek je of je Tesseract moet gebruiken of niet? Tesseract is voor veel organisaties de standaard open-source OCR-oplossing: gratis te gebruiken, goed bekend en toepasbaar in talloze situaties.
Toch verandert de markt voor documentverwerking razendsnel. Volgens de IDP Survey 2025 vervangt 66% van de ondernemingen hun verouderde Intelligent Document Processing-tools door moderne, AI-gestuurde systemen, en gebruikt 78% al AI binnen hun documentworkflows.
In dat licht blijft Tesseract weliswaar populair, maar valt het steeds vaker onder de categorie legacy: krachtig voor basistaken, maar vaak ingehaald op het gebied van nauwkeurigheid, automatisering en schaalbaarheid.
Dus: heeft het nog zin om de Tesseract OCR-engine te gebruiken?
In deze blog leggen we uit wat Tesseract precies is, hoe het werkt en of Tesseract de juiste keuze is voor jouw situatie. Laten we beginnen.
Key Takeaways
- Tesseract OCR is een gratis en bekende open-source oplossing voor het extraheren van tekst uit afbeeldingen, compatibel met veel programmeertalen via wrappers zoals Pytesseract.
- Moderne, AI-gestuurde OCR-oplossingen overtreffen Tesseract in nauwkeurigheid, automatisering en gebruiksgemak, en werken vaak direct “out-of-the-box” dankzij vooraf getrainde modellen.
- Tesseract vereist veel handmatige configuratie, codering en trainingsdata voor complexere toepassingen.
- Klippa DocHorizon biedt een plug-and-play alternatief met hogere nauwkeurigheid, AI-verrijking, mobiele scanning en schaalbare automatisering.
Wat is Tesseract?
Tesseract is een open-source OCR-engine die gedrukte of geschreven tekst uit afbeeldingen haalt. Het werd oorspronkelijk ontwikkeld door Hewlett-Packard, en de ontwikkeling werd later overgenomen door Google. Daarom staat het nu bekend als ‘Google Tesseract OCR’.
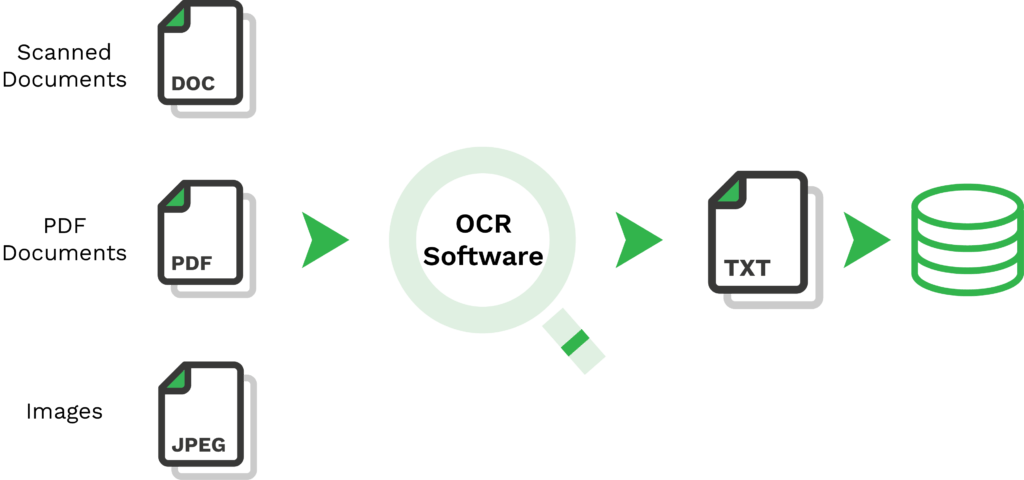
Maar wat is een open-source OCR? Simpelweg betekent het dat het voor iedereen beschikbaar is om vrij te gebruiken, rechtstreeks of via een Application Programming Interface (API). Met Tesseract OCR kunnen gebruikers tekst uit afbeeldingen halen met efficiënte in-line en karakterpatroonherkenning van de OCR-engine.
Momenteel ondersteunt Tesseract al taalherkenning voor meer dan 100 talen ‘out of the box’. De meest recente versie van Tesseract (4.0) heeft een AI-integratie via LSTM Neural Network om invoer van verschillende grootte beter te detecteren en te herkennen.
Een van de sterke punten van Tesseract is dat het compatibel is met vele programmeertalen en frameworks met behulp van wrappers zoals Pytesseract, ook bekend als Python-Tesseract. Laten we dit verband tussen Tesseract OCR en Python eens nader bekijken.
Open Source Python OCR-software
Pytesseract is niet alleen OCR in Python, open source software, of een Python-bibliotheek, maar dient ook als een wrapper voor Google’s Tesseract OCR-engine. Wat het doet is Python-code om Tesseract OCR wikkelen, waardoor compatibiliteit en de mogelijkheid om met verschillende softwarestructuren te werken verzekerd zijn.

Merk op dat er andere Python OCR-bibliotheken en wrappers zijn die aan Tesseract gekoppeld kunnen worden, waaronder:
- PYOCR – maakt meer opties mogelijk voor detectie van zinnen, cijfers en woorden.
- Textract – maakt extractie van PDF-gegevens mogelijk voor grote bestanden en pakketten.
- OpenCV – open source bibliotheek van programmeer-functies gericht op live-Computer Vision.
- Leptonica – maakt beeldverwerkingsfuncties en beeld-analysetoepassingen mogelijk met zijn imaging library.
- Pillow – een andere beeldvorming-bibliotheek van Python, die het openen, manipuleren en opslaan van een uitgebreide lijst beeldbestand-formaten ondersteunt.
Nu we hebben uitgelegd wat Tesseract is en wat het verband is met Python, laten we eens gaan kijken naar de stappen in het Tesseract OCR-proces.
Stappen in het Tesseract OCR-proces
Om je te helpen begrijpen hoe het Tesseract OCR proces er normaal gesproken uitziet, hebben we het opgedeeld in de volgende stappen:
- API-verzoek – Tesseract OCR is alleen toegankelijk via API-integratie. Zodra die verbinding tussen je oplossing en Tesseract tot stand is gebracht, kun je vanuit jouw oplossing API requests sturen naar de Tesseract OCR engine.
- Beeld-invoer – Met een API request kun je jouw beeld-invoer insturen voor tekst-extractie.
- Beeld-voorverwerking – Voor de data-extractie worden de beeld-voorverwerkingsfuncties van de Tesseract OCR-engine ingeschakeld. Deze stap zorgt ervoor dat de beeldkwaliteit zo hoog mogelijk is om accurate data extractie resultaten te bereiken. Vaak wordt OpenCV gekoppeld aan Tesseract om de beeldkwaliteit voor data extractie te verhogen.
- Data-extractie – Samen met getrainde data sets en Leptonica of OpenCV verwerkt de Tesseract OCR-engine de invoer-afbeelding en extraheert de data.
- Tekstconversie – Als de gegevens uit de invoer zijn gehaald, kunnen deze nu worden geconverteerd naar een gewenst formaat dat Tesseract ondersteunt, waaronder PDF, platte tekst, HTML, TSV en XML.
- API-respons – Zodra de uitvoer klaar is, krijgt je oplossing een API-respons terug met de gefinaliseerde uitvoer.
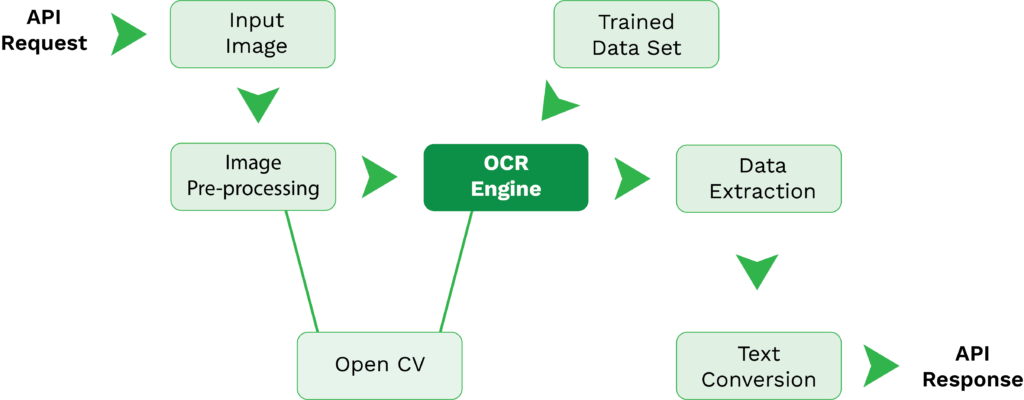
Om deze OCR-stroom tot stand te brengen, is kennis en tijd nodig om alle relevante API-verbindingen te bouwen. Verder zou je de relevante componenten moeten vinden, zoals bibliotheken en wrappers, en uitgebreid moeten coderen. Dit hangt vooral af van je gebruikssituatie en de toepassing van OCR.
Zoals eerder gezegd, wordt Tesseract vaak gekoppeld aan OpenCV om de kwaliteit van de ingevoerde beelden te verbeteren naar de huidige normen. Laten we eens in detail bekijken hoe dit werkt.
Betere beeldverwerking door het combineren van OpenCV & Tesseract
Om te begrijpen waarom OpenCV vaak wordt gecombineerd met Tesseract OCR, moeten we computer vision uitleggen. Computer vision is een deelgebied van kunstmatige intelligentie (AI) dat computers en software in staat stelt om digitale beelden, video’s of andere visuele input te zien, te observeren en te begrijpen. Maar wat heeft het te maken met OpenCV?
OpenCV is een open-source bibliotheek van computer vision functies die de gegevens-extractie van OCR engines zoals Tesseract kan verbeteren. Je kunt de OpenCV-bibliotheek gebruiken om de volgende functies in de OCR-oplossing te integreren:
- Objectdetectie – stelt de oplossing in staat om een verscheidenheid aan objecten te detecteren.
- Diepe neurale netwerken (DNN) – stelt de oplossing in staat om afbeeldingen te classificeren.
- Beeldverwerking – stelt de oplossing in staat om ingevoerde beelden beter te verwerken met verschillende technieken zoals randdetectie, pixel-manipulatie, scheefstand-correctie, etc.
Zonder OpenCV is Tesseract niet zo geavanceerd als we zouden verwachten van de huidige OCR-oplossingen, omdat veel van hen verschillende AI-technologieën toepassen.
Nu je weet dat Tesseract OCR kan worden verbeterd met andere bibliotheken van programmeer-functies zoals OpenCV, laten we eens kijken naar een van de meest gebruikte Tesseract wrappers in Python: PyTesseract.
Hoe werkt (Py)tesseract?
Tot nu toe weten we dat Pytesseract een wrapper is voor Google’s Tesseract OCR in Python met extra functionaliteiten die Tesseract alleen niet heeft. Dus wat zijn deze functionaliteiten, en hoe werkt het?
Pytesseract kan worden gebruikt als een alleenstand script voor Tesseract waardoor het herkende tekst kan afdrukken in plaats van het te converteren naar een bestand. Pytesseract kan alle beeldbestanden lezen die worden ondersteund door imaging libraries zoals Leptonica en Pillow, inclusief JPEG, PNG, GIF, BMP, TIFF en vele andere. Daarom wordt het vaak gebruikt in image-to-text Python OCR toepassingen.
Pytesseract zet de tekst en grafische elementen van een gescande afbeelding om in een bitmap. Deze bitmap is gewoon een constructie van witte en zwarte punten. Zoals bij elke OCR, doorloopt de afbeelding de pre-processing fase voor helderheid en contrast aanpassingen voor data extractie en conversie.

Het Pytesseract framewerk is geoptimaliseerd voor betere taaldetectie, wat ook Google’s Tesseract OCR ten goede komt. Daarnaast is dit raamwerk uitstekend in het detecteren van gebruikte lettertypen en de oriëntatie van de tekst op de invoerafbeelding. Het kan bijvoorbeeld een betrouwbaarheidscijfer voor de oriëntatie geven om de detectie van de oriëntatie te garanderen. Een van de belangrijkste kenmerken is echter dat het je kan voorzien van de bounding box informatie van de OCR.
Kennismaken met de functies en hoe Pytesseract Python OCR werkt is leuk, maar het geeft je geen details over hoe je Google’s Tesseract OCR kunt gebruiken. Laten we daar nu op ingaan!
Python OCR toepassingen met Tesseract
Als je in een bedrijf zit dat documenten verwerkt van klanten, leveranciers, partners of werknemers, dan is de kans groot dat je je werkstroom voor document-verwerking kunt verbeteren met Tesseract OCR. Hieronder hebben we een aantal situaties opgesomd waarin Python OCR kan worden toegepast.
- Geautomatiseerde gegevensinvoer – Knelpunten worden vaak veroorzaakt door vervelende taken zoals gegevensinvoer. Met OCR kun je handmatige gegevensinvoer elimineren en de kosten tot 70% verlagen.
- Digitale klanten-instroom – OCR kan zeer nuttig zijn bij het extraheren van persoonlijke informatie uit identiteitsdocumenten. Met OCR kun je jouw klanten instroom op afstand aanbieden zonder dat er een instroomproces aan de balie nodig is.
- Automated Receipt Clearing voor loyaliteitscampagnes – Wat als je een grote loyaliteitscampagne hebt met een aanzienlijke hoeveelheid te verifiëren bonnen? Eerst moet je de gegevens in je database opnemen voor validatie. Dit is waar Tesseract jou mee kan helpen.
- Geautomatiseerde factuurverwerking voor crediteuren – crediteuren-processen doorlopen vele stadia en beginnen altijd met handmatige gegevensinvoer. Met OCR kun je de doorlooptijd en kosten verminderen door geautomatiseerde gegevens-extractie van facturen.
- Digitale archivering – Het kan veel tijd kosten om een stuk informatie uit een papieren archief terug te vinden. Digitale archivering met OCR heeft veel voordelen voor organisaties, waaronder kostenbesparingen, GDPR-compliance en betere toegang tot gegevens.
- VIN data-extractie – Het handmatig schrijven van Vehicle Identification Numbers (VIN’s) op papier of formulieren is niet altijd de meest efficiënte manier om ze te verwerken. Het extraheren van het VIN met Tesseract OCR is eenvoudig en kan je activiteiten aanzienlijk verbeteren.
Maak je geen zorgen als jouw gebruikssituatie hier niet is beschreven. Tesseract kan over het algemeen veel document-gerelateerde werkstromen verbeteren zoals elke andere Python OCR oplossing. Één ding om wel in gedachten te houden is echter dat het geen out-of-the-box oplossing is.
Dit betekent dat je voor elk van de bovengenoemde toepassingen meerdere API’s aan elkaar moet koppelen, en verschillende Python-wrappers en bibliotheken met programmeer-functies moet gebruiken. Bovendien zou je de OCR-engine moeten trainen met een aanzienlijke hoeveelheid gegevens om jouw situatie te ondersteunen, wat tonnen middelen vereist, zowel tijd als geld.
Tesseract trainen om je documenten te verwerken
In gevallen waar Tesseract jouw data-extractie behoeften niet out-of-the-box ondersteunt, moet je de OCR-engine zelf trainen. Wat dit praktisch gezien betekent, is dat je duizenden voorbeeld-afbeeldingen of -documenten geannoteerd moet hebben om Tesseract OCR te trainen. Dit wordt ook wel ’trainingsdata’ genoemd.
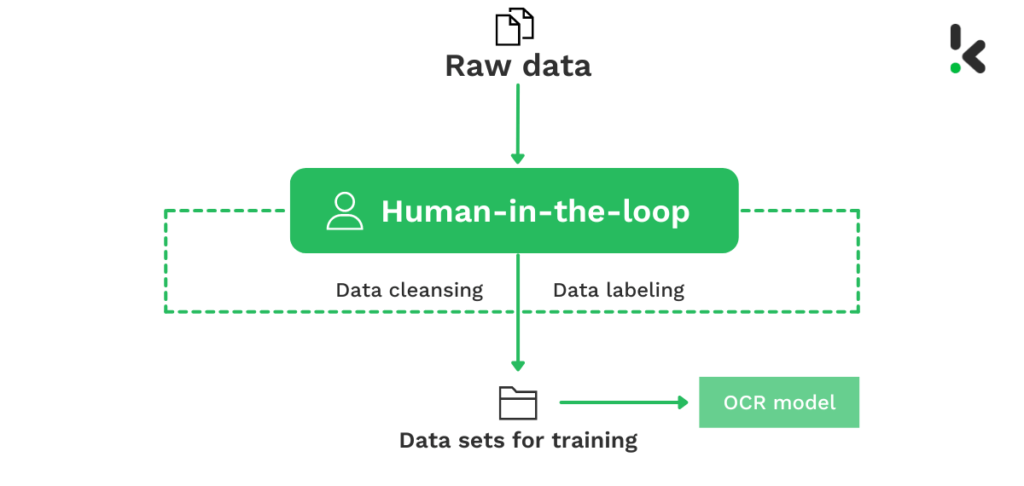
Niet alle organisaties beschikken over opleidingsgegevens. Het verwerven van trainingsgegevens kan je organisatie veel geld kosten. En als je zelf gegevens zou annoteren, kost dat zowel tijd als geld.
Dit zijn vaak de belangrijkste redenen waarom veel organisaties liever kiezen voor een oplossing die al out-of-the-box opties biedt. Maar er zijn nog andere redenen om te overwegen voordat je je overhaast stort in het gebruik van open-source OCR zoals Tesseract van Google.
Beperkingen van Tesseract
Tesseract OCR kan zeer nuttig zijn in vele gevallen en gebruikssituaties. Maar net als bij elke andere open-source oplossing zijn er altijd enkele nadelen om rekening mee te houden. In deze sectie zullen we deze beperkingen één voor één belichten:
- Tesseract is niet zo nauwkeurig als een meer geavanceerde oplossingen met AI;
- Tesseract is gevoelig voor fouten als de scheiding van voor- en achtergrond van de afbeelding niet significant is;
- Je hebt veel middelen en tijd nodig om je eigen oplossing met Tesseract OCR te ontwikkelen;
- Tesseract ondersteunt zelf niet alle bestandsformaten;
- Tesseract herkent geen handschrift;
- De beeldkwaliteit moet een bepaalde drempel van Dots per Inch (DPI) punten bereiken om te kunnen werken;
- Tesseract moet verder ontwikkeld worden en heeft de integratie van AI nodig om bepaalde documentsprocessen – zoals verificatie, kruiscontrole validatie – te kunnen automatiseren;
- Tesseract heeft geen Graphic User Interface (GUI), wat betekent dat je het aan je bestaande GUI moet koppelen of er een moet laten ontwikkelen;
- De extra ontwikkeling kost tijd en geld.
Al met al, als jouw OCR-gebruiksgeval eenvoudig is en je zelf kennis hebt van het ontwikkelen van OCR-oplossingen met Python, dan kan Google’s Tesseract voor jou een toereikende oplossing zijn.
Als je echter een nauwkeurigere OCR-oplossing nodig hebt die schaalbaar is of out of the box werkt, dan is Tesseract niet de beste oplossing voor jou. Hoewel het gratis te gebruiken is, zijn betaalde opties vaak gemakkelijker en mogelijk nog steeds goedkoper dan het gebruik van Tesseract. Andere redenen waarom het misschien niet de juiste keuze voor jou is:
- Lange installatietijd;
- De noodzaak om verbindingen te maken met ERP- of boekhoudsystemen;
- Gebrek aan ondersteuning voor jouw gebruikssituatie;
- Gebrek aan trainingsgegevens;
- Gebrek aan interne kennis over OCR in Python.
Het perfecte alternatief voor Tesseract OCR: Klippa DocHorizon
Klippa DocHorizon wordt beschouwd als de volgende evolutie van OCR-technologie. Met meer dan tienduizenden ontwikkelingsuren is de oplossing gepolijst om klanten in meerdere industrieën te bedienen.
DocHorizon kan niet alleen afbeeldingen beter naar tekst omzetten met OCR dan Tesseract OCR, maar ook gegevens automatisch classificeren, valideren en maskeren met behulp van AI-technologieën.
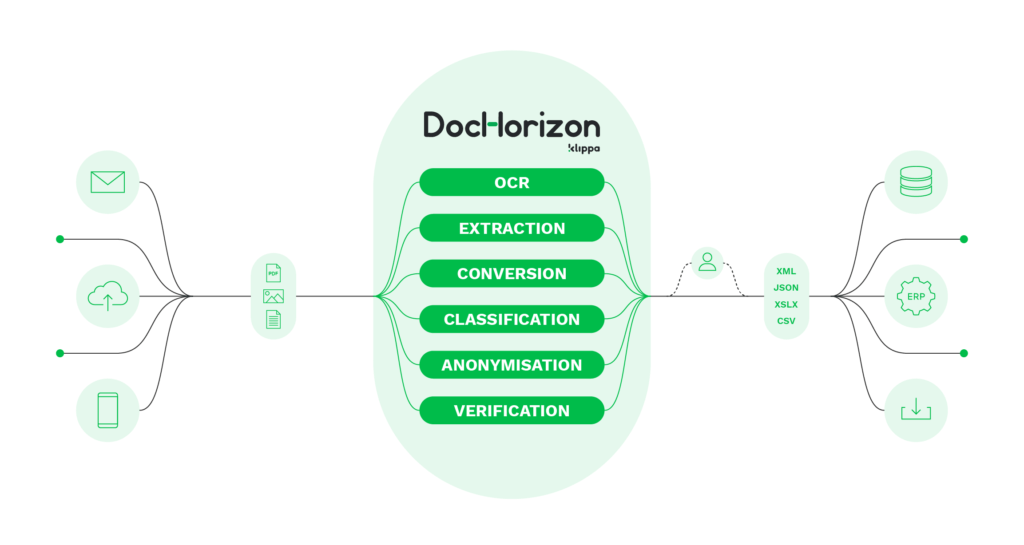
Waarom zou je DocHorizon overwegen boven Tesseract OCR? De voordelen van het gebruik van Klippa DocHorizon ten opzichte van Tesseract zijn onder andere:
- Schaalbaarheid – DocHorizon is niet beperkt door sjablonen of bepaalde invoerbestanden, waardoor jouw organisatie OCR operaties kan schalen.
- Breed scala aan ondersteunde documenttypes – Momenteel zijn er out-of-the-box opties om gegevens vast te leggen van documenten zoals paspoorten, kassabonnen, facturen, identiteitskaarten, rijbewijzen en vele andere in meerdere talen.
- Gespecialiseerd instroomteam – Maakt een snelle en betrouwbare onboarding mogelijk, zodat je zo snel mogelijk aan de slag kunt.
- Hogere OCR-nauwkeurigheid – Met AI-technologieën is de OCR-nauwkeurigheid hoger omdat de oplossing voortdurend leert en niet beperkt is tot sjablonen of strikte regels.
- Automatisering van de documentenstroom – DocHorizon kan elke documentgerelateerde werkstroom automatiseren, waardoor je terugkerende taken zoals handmatige archivering, handmatige gegevensinvoer en gegevensvalidatie kunt elimineren.
- Mobiel scannen – Til jouw bedrijf naar een hoger niveau door je organisatie of klanten in staat te stellen beelden te OCR-en met mobiele apparaten met behulp van DocHorizon’s mobiele scan-oplossingen.
- Aangepaste oplossing – Als je een aangepaste oplossing nodig heeft die is afgestemd op jouw situatie, kan Klippa’s ervaren ontwikkelingsteam je helpen deze te bouwen.
In het algemeen ondersteunt DocHorizon out-of-the-box veel meer gebruikssituaties dan Google’s Tesseract OCR. Als jouw organisatie een complexere situatie is of een plug-and-play oplossing wil laten implementeren, dan is DocHorizon het beste Tesseract alternatief voor jou.
Plan een demo via onderstaand formulier om te zien hoe onze oplossing werkt. Mocht je brandende vragen hebben die nog niet beantwoord zijn, neem dan gerust contact op met onze experts!
FAQ
Tesseract werkt het best als je technische kennis hebt voor installatie en aanpassing. Zonder die expertise bespaar je met een beheerde OCR-oplossing veel tijd en middelen.
2. Hoe nauwkeurig is Tesseract OCR vergeleken met AI-gestuurde tools?
De gemiddelde nauwkeurigheid ligt rond de 80–85% bij schone, gestructureerde tekst. AI-oplossingen zoals DocHorizon halen 95–98%, zelfs bij complexe lay-outs — zonder uitgebreide handmatige training.
3. Leest Tesseract OCR handgeschreven tekst?
Nee, Tesseract is gericht op gedrukte tekst. Voor handgeschreven formulieren, handtekeningen of notities heb je een OCR-engine nodig met handschriftherkenning.
4. Hoe lang duurt het om Tesseract in te stellen voor een aangepaste workflow?
Complexe workflows kunnen weken of zelfs maanden duren om te configureren. Klippa DocHorizon biedt vooraf getrainde modellen en kant-en-klare integraties, waarmee je binnen enkele dagen live kunt gaan.
5. Is Tesseract OCR echt gratis te gebruiken?
Ja, het is open-source en vrij van licentiekosten. Maar “gratis” betekent niet zonder kosten: ontwikkeltijd, training en onderhoud tellen niet mee. Veel bedrijven ervaren uiteindelijk lagere totale kosten met plug-and-play AI-oplossingen.
6. Kan Tesseract koppelen met ERP- of CRM-systemen?
Niet zonder maatwerk-API-ontwikkeling. DocHorizon biedt directe connectors en een open API voor naadloze integratie met ERP-, CRM- en andere bedrijfsapplicaties.
7. Kan Tesseract OCR documenten in meerdere talen verwerken?
Ja, het ondersteunt meer dan 100 talen, maar de nauwkeurigheid varieert afhankelijk van opmaak, lettertype en beeldkwaliteit.
8. Kan Tesseract fraude detecteren of gegevens anonimiseren?
Niet standaard. Hiervoor is extra codering en tooling nodig, terwijl sommige AI-OCR-platformen deze functies al direct aanbieden.
9. Waarom vervangen bedrijven verouderde OCR-oplossingen zoals Tesseract?
AI-gestuurde OCR biedt een snellere implementatie, hogere nauwkeurigheid, automatisering voor meer toepassingen en soepelere integratie met moderne technologieën.
10. Hoe kan ik DocHorizon uitproberen vóór aanschaf?
De beste manier om DocHorizon te ervaren is via een live demo met ons team. We verwerken je eigen documenten in realtime en tonen hoe de automatisering voor jouw organisatie werkt. Bovendien ontvang je €25 gratis credits om het platform zelf te testen.