Unternehmen speichern mehr Daten in Online-Datenbanken und -Umgebungen als je zuvor. In der Tat befinden sich 60 % der weltweiten Unternehmensdaten in der Cloud. Aber haben diese Unternehmen die richtigen Werkzeuge, um sensible Daten zu schützen? Es gibt zwar viele Datenschutzbestimmungen, an die sich Unternehmen halten müssen, wie z. B. die DSGVO in Europa, aber diese schützen die Daten nicht immer vor Datenschutzverletzungen.
Nach Angaben von Verizon betreffen die meisten Datenschutzverletzungen personenbezogene Daten und Zahlungskartendaten. Jedes Mal, wenn ein Unternehmen von einer Datenschutzverletzung betroffen ist, kann es kostspielig werden, geeignete Maßnahmen zu ergreifen, um den Schaden zu minimieren und die verschiedenen Interessengruppen darüber zu informieren, dass die Daten betroffen sind.
Außerdem kann es sich negativ auf den Ruf des Unternehmens auswirken, was auf lange Sicht zu finanziellen Verlusten führen kann. Aus diesem Grund sollten Unternehmen Präventivmaßnahmen wie die Datenanonymisierung ergreifen, um die von ihnen gespeicherten und verarbeiteten sensiblen Daten zu schützen.
Wie diese Präventivmaßnahmen aussehen, welche Techniken eingesetzt werden können und wie die Datenanonymisierung mit modernen KI-Lösungen automatisiert werden kann, wird in diesem Blog besprochen. Legen wir los!
Was ist Datenanonymisierung
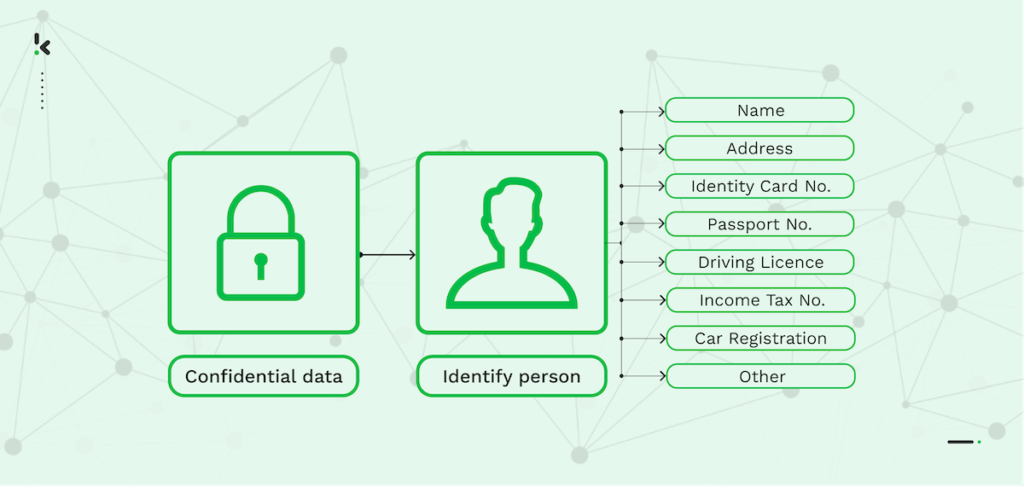
Das Anonymisieren von Daten ist eine Methode zum Schutz vertraulicher oder persönlicher Informationen, durch das Löschen oder Ändern von persönlich identifizierbaren Daten, die in einem Datensatz gespeichert sind. Ziel der Datenanonymisierung ist es, die Glaubwürdigkeit der gespeicherten oder ausgetauschten Daten zu wahren und die Einhaltung strenger Datenschutzbestimmungen zu gewährleisten.
Das Hauptkriterium der Anonymisierung gemäß der ISO-Norm (ISO 29100:2011) ist, dass persönlich identifizierbare Informationen (PII) irreversibel verändert werden, sodass die Person nicht mehr direkt oder indirekt identifiziert werden kann. Daher sollten Finanzdaten, Kontaktdaten, Gesundheitsberichte und Zahlungsdaten, die PII enthalten, gut geschützt werden, um die strengen Datenschutzbestimmungen einzuhalten.
Nun, da Sie wissen, was Datenanonymisierung ist, lassen Sie uns damit fortfahren, wie man Daten anonymisiert.
Wie werden Daten anonymisiert?
Um Daten zu anonymisieren, müssen Sie zunächst die personenbezogenen Daten im Datensatz identifizieren und dann die richtige Anonymisierungstechnik je nach dem potenziellen Risiko von Verstößen bestimmen. Es gibt verschiedene Softwarelösungen, die Ihren Anwendungsfall und Ihre Anforderungen unterstützen können, zum Beispiel:
- Software zur Datenmaskierung
- Datenverschlüsselungs-Software
- Software zur Anonymisierung von Daten
- Software zur Datenverwaltung
- Intelligente Dokumentenverarbeitungssoftware
Jede dieser Software verwendet eine andere Art von Datenanonymisierungstechniken, die wir im folgenden Abschnitt näher erläutern werden.
Techniken zur Anonymisierung von Daten
Die folgende Liste enthält die am häufigsten verwendeten Techniken zur Anonymisierung sensibler Daten:
- Maskierung von Daten
- Pseudonymisierung
- Verallgemeinerung
- Data Swapping
- Daten-Störungen
- Synthetische Daten
Maskierung von Daten
Unter Datenmaskierung versteht man den Prozess, Daten mit geänderten Werten zugänglich zu machen. Die Datenmaskierung kann durch die Änderung von Daten in Echtzeit (dynamische Datenmaskierung) oder durch die Erstellung eines Spiegelbilds einer Datenbank auf der Grundlage geänderter Daten (statische Datenmaskierung) erfolgen.
Die Anonymisierung kann mit einer Reihe von Datenmaskierungstechniken durchgeführt werden, z. B. Verschlüsselung, Datenredigierung, Zeichenmischung, Zeichenumwandlung, Scrambling usw.
Pseudonymisierung
Pseudonymisierung ist eine Methode zur De-Identifizierung von Daten, bei der private Identifikatoren durch Pseudonyme (falsche Identifikatoren) ersetzt werden. Ein Beispiel wäre der Austausch des Namens „Jane Smith“ durch „Janet Doe“. Die Pseudonymisierung gewährleistet statistische Genauigkeit und stellt gleichzeitig sicher, dass die Daten vertraulich sind. Das bedeutet, dass die Daten weiterhin für Schulungs-, Test- und Analysezwecke verwendet werden können.
Verallgemeinerung
Die Verallgemeinerung ist eine Technik, bei der bestimmte Teile der Daten absichtlich ausgeschlossen werden, um sie weniger identifizierbar zu machen, während die Genauigkeit der Daten erhalten bleibt. Mit dieser Technik können Daten in eine Reihe von Werten mit logischen Grenzen umgewandelt werden. So kann beispielsweise eine bestimmte Adresse ohne Hausnummer angegeben werden, oder die Nummer wird innerhalb eines Bereichs von 140 Hausnummern der ursprünglichen Adresse ersetzt.
Data Swapping (Datenaustausch)
Data Swapping, auch bekannt als Shuffling oder Permutation, ist eine Technik, bei der die Attributwerte des Datensatzes vertauscht und neu angeordnet werden, sodass Daten nicht mehr mit den ursprünglichen Informationen übereinstimmen. Das Vertauschen von Attributen, die identifizierbare Werte wie die Sozialversicherungsnummer oder das Geburtsdatum enthalten, kann die Anonymisierung erheblich beeinflussen.
Data Swapping wird häufig verwendet, wenn es um identifizierbare Daten in Spalten von Excel-Dateien geht, z. B. bei Kunden- oder Mitarbeiterdaten.
Data Perturbation (Datenstörung)
Data Perturbation ist eine Technik, bei der der ursprüngliche Datensatz durch Hinzufügen von Zufallsrauschen und die Verwendung von Rundungsmethoden für Werte leicht verändert wird. Die Werte müssen in einem angemessenen Verhältnis zur Störung stehen, um die Verwendbarkeit der Daten zu gewährleisten.
Wenn beispielsweise die Basis, die zur Veränderung der ursprünglichen Werte verwendet wird, zu klein ist, können die Daten nicht ausreichend anonymisiert werden. Ist die Basis zu groß, sind die Daten möglicherweise nicht mehr erkennbar oder verwendbar.
So wird zum Beispiel häufig ein Basiswert von 5 für die Rundung von Werten wie dem Alter verwendet.
Synthetische Daten
Synthetische Daten sind algorithmisch erzeugte künstliche Datensätze, die keinen Bezug zu einem Originalfall haben. Diese Methode wird durch die Verwendung mathematischer Modelle ermöglicht, die auf den Mustern des Originaldatensatzes basieren. Solche Modelle umfassen lineare Regressionen, Standardabweichungen, Mediane oder andere statistische Modelle, die für die Erstellung synthetischer Ergebnisse nützlich sind.
Bei der Verwendung künstlicher Datensätze besteht kein Risiko, Datenschutz und Privatsphäre zu gefährden, da sie keine echten personenbezogenen Daten enthalten.
Einige dieser Techniken sind Ihnen vielleicht schon einmal begegnet, wenn Ihr Unternehmen mit sensiblen Daten arbeitet. Falls nicht, hoffen wir, Sie im nächsten Abschnitt darüber aufzuklären, ob sie für Sie relevant sind, indem wir verschiedene Anwendungsfälle der Datenanonymisierung vorstellen.
Anwendungsfälle der Datenanonymisierung
Um diesen Blog übersichtlich zu halten, behandeln wir nur die Anwendungsfälle der Datenanonymisierung, die am häufigsten aufkommen. Die folgende Liste erhebt keinen Anspruch auf Vollständigkeit:
- Remote Kunden Onboarding
- Verarbeitung von Finanzinformationen
- Software- und Produktentwicklung
Remote Kunden Onboarding
Unternehmen, die ihre Kundendaten während des Remote-Onboarding-Prozesses überprüfen und speichern müssen, unterliegen verschiedenen Vorschriften wie KYC, DSGVO und AML, um nur einige zu nennen. Oft müssen Kunden ihre Identitätsdokumente einscannen, damit das Unternehmen ihre Identität überprüfen oder eine Customer-Due-Diligence Prüfung des Kunden durchführen kann.
Um personenbezogene Daten wie die Sozialversicherungsnummer (SSN) oder das Geburtsdatum vor Missbrauch zu schützen, können Unternehmen Daten durch verschiedene Maskierungstechniken anonymisieren.
Finanzielle Informationsverarbeitung
Finanzinstitute müssen die Privatsphäre ihrer Kunden bei der Verarbeitung von Finanzdaten schützen. Dies kann oft durch das Entfernen oder Unkenntlich machen von personenbezogenen Daten aus Datensätzen mithilfe von Datenanonymisierungstechniken wie Datenmaskierung oder Generalisierung erreicht werden.
Diese Techniken können auf verschiedene Arten von Finanzdaten angewendet werden, z. B. auf Transaktionsberichte, Kreditberichte, Zahlungsinformationen, Rechnungen, Kontoauszüge und Kreditanträge.

Software und Produktentwicklung
Entwickler müssen bei der Entwicklung von Software und Tools echte Daten verwenden, um reale Probleme zu lösen, Tests durchzuführen und bestehende Lösungen zu verbessern. Der Grund, warum die Daten oft anonymisiert werden, ist, dass die Entwicklungsumgebung anfällig für Sicherheitslücken sein kann, wenn Daten an mehrere Teams weitergegeben werden. Dies kann letztlich dazu führen, dass sensible Daten in Gefahr geraten.
Warum Sie Daten anonymisieren sollten
Es gibt verschiedene Gründe, warum Sie Daten anonymisieren sollten. Die wichtigsten Gründe können die folgenden sein:
- Absicherung gegen Datenmissbrauch: Die Anonymisierung von Daten stellt sicher, dass interne Beteiligte die Daten nicht missbrauchen können, und minimiert das Risiko, dass Daten missbraucht werden, wenn das Unternehmen von externen Tätern angegriffen wird.
- Einhaltung der Datenschutzbestimmungen: Die allgemeine Datenschutzverordnung (DSGVO) in der Europäischen Union und der California Consumer Privacy Act (CCPA) in den Vereinigten Staaten verpflichten Unternehmen, die personenbezogenen Daten von Einzelpersonen zu schützen und den Betroffenen bestimmte Rechte zu gewähren. Die Anonymisierung von Daten hilft Unternehmen, diese Anforderungen zu erfüllen und Geldstrafen für die Nichteinhaltung der Vorschriften zu vermeiden.
- Möglichkeiten der gemeinsamen Nutzung von Daten: Daten mit persönlich identifizierbaren Informationen können nicht an Drittunternehmen weitergegeben werden, was die Suche nach neuen Geschäftsmöglichkeiten einschränkt. Mit der Anonymisierung von Daten können Unternehmen jedoch Daten mit Partnern oder Forschern teilen, um neue Erkenntnisse zu gewinnen und neue Produkte zu entwickeln. Anonymisierte Daten können zum Beispiel zum Trainieren von Machine Learning Modellen verwendet werden, um Produkte und Dienstleistungen zu verbessern.
Obwohl es wichtig ist und für Ihr Unternehmen von Vorteil sein kann, Daten zu anonymisieren, gibt es auch einige Nachteile, die Sie berücksichtigen sollten.
Nachteile der Datenanonymisierung
Einige der Nachteile der Anonymisierung von Daten sind:
- Verlust des Nutzens der Daten: Gemäß den gesetzlichen Bestimmungen müssen Websites die Erlaubnis der Besucher einholen, um persönliche Daten wie Cookies und IP-Adressen zu sammeln. Das Entfernen von Identifikatoren und die Anonymisierung von Daten kann jedoch die Möglichkeit einschränken, die Daten in den Ergebnissen zu nutzen. Anonymisierte Nutzerdaten können zum Beispiel nicht für personalisiertes Marketing oder Targeting verwendet werden.
- Ist auf technische Ressourcen angewiesen: Die Anonymisierung von Daten kann ein technisch aufwendiger und ressourcenintensiver Prozess sein. Unternehmen müssen über spezielles Wissen und Fachkenntnisse verfügen, um ihn durchzuführen. Außerdem kann die Wartung zeitaufwändig und kostspielig sein. Aufgrund der ausgefeilten Methoden von Hackern und Datenverletzungen müssen Unternehmen ihre Anonymisierungstechniken ständig aktualisieren, um sicherzustellen, dass Daten wirklich anonym bleiben.
Nun, da Sie eine Vorstellung von den Vor- und Nachteilen der Datenanonymisierung haben, werden wir Ihnen erklären, wie Sie Daten anonymisieren können.
Anonymisierung Ihrer Daten mit Klippa DocHorizon
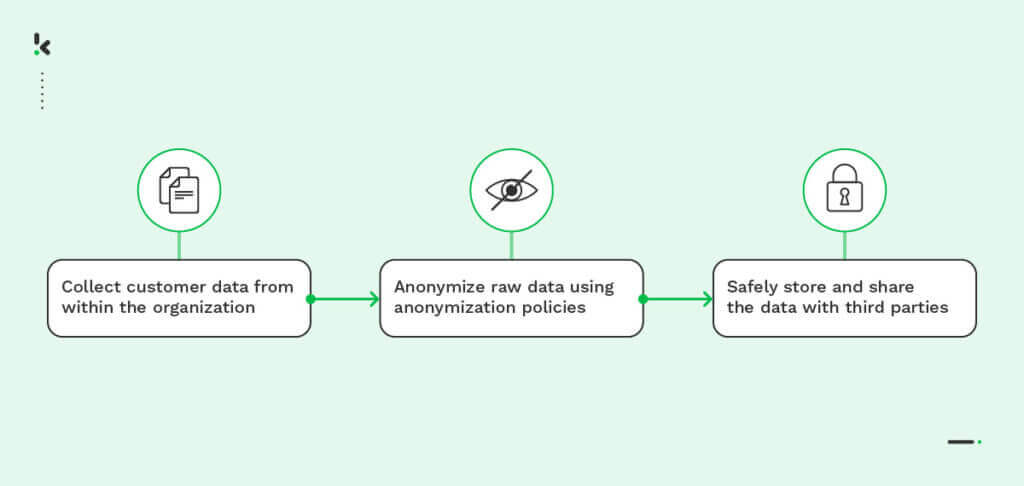
Wenn Sie Daten aus Dokumenten, die Sie sammeln, digitalisieren und extrahieren, anonymisieren möchten, kann Klippa Ihnen helfen. Unsere intelligente Dokumentenverarbeitungssoftware DocHorizon verwendet Optical Character Recognition (OCR), um Text aus Bildern zu extrahieren, und KI-Modelle, um Daten entsprechend Ihren Anforderungen zu erkennen, zu klassifizieren und zu anonymisieren. Wie?
DocHorizon kann so trainiert werden, dass bestimmte Felder und Texte in Dokumenten, die an die Parsing-Engine gesendet werden, geschwärzt und maskiert werden. Diese Dokumente können per E-Mail, über das Internet oder über eine mobile Anwendung in Form von JPG-, PNG- und PDF-Dateien gesendet werden. Nach der Datenanonymisierung können Sie die anonymisierten Daten in der Form Ihrer Wahl erhalten, einschließlich JSON, XLSX, XML oder CSV.
Die Implementierung unserer Datenanonymisierungslösung ist dank der verfügbaren Dokumentation sehr einfach und kann über API oder SDK erfolgen. Unsere API ist nützlich für Sie, wenn Sie Ihre eigene Pipeline zur Informationsextraktion und Anonymisierung aufbauen und mit Ihren bestehenden Softwaresystemen verbinden möchten.
Unser SDK hingegen ermöglicht es Ihnen, Ihre mobilen Geräte in Datenerfassungsgeräte zu verwandeln, mit der Möglichkeit, Daten selektiv zu maskieren. Dies ist nützlich, wenn Sie Ihrer bestehenden oder in Kürze erscheinenden mobilen Anwendung Datenanonymisierungsfunktionen hinzufügen möchten.
Mit DocHorizon profitieren Sie von den folgenden Vorteilen:
- Beibehaltung der Datennutzbarkeit bei automatischer Extraktion und Anonymisierung von Daten
- Bessere Einhaltung von Datenschutzbestimmungen und -anforderungen
- Geringere Kosten, da Sie nicht mehrere Lösungen kaufen müssen, um Ihre Datenanonymisierungspipeline zu erstellen
- Schnellere Durchlaufzeiten bei der Anonymisierung und Verarbeitung von Daten durch Automatisierung
- Erhöhte Skalierbarkeit mit geringer Abhängigkeit von menschlichen Ressourcen
Sind Sie bereit, Ihre Datenextraktion und Anonymisierung zu automatisieren? Füllen Sie einfach das unten stehende Formular aus, um eine kostenlose Demo unserer Software zu erhalten. Wenn Sie weitere Fragen haben, kontaktieren Sie gerne unsere Experten für weitere Informationen.