
Die Digitalisierung ist auf dem Vormarsch, da viele Unternehmen nach besseren Möglichkeiten zur Verarbeitung und Speicherung von Dokumenten suchen. Traditionelle Archive werden in die Cloud verlagert, und immer mehr Dokumente werden in digitalen Arbeitsabläufen verarbeitet.
Die Digitalisierung hat zwar fantastische Vorteile, aber es gibt auch einige Herausforderungen zu beachten. Die wichtigste ist die Einhaltung der strengen allgemeinen Datenschutzbestimmungen (GDPR), die im Mai 2018 eingeführt wurden.
Obwohl diese Verordnungen den Datenschutz verbessern und die Verantwortlichkeiten der Organisationen klären, können sie Datenschutzverletzungen nicht gänzlich verhindern.
Tatsächlich stiegen die durch Datenschutzverletzungen verursachten Kosten von 3,86 Millionen US-Dollar auf 4,24 Millionen US-Dollar, womit die höchsten durchschnittlichen Gesamtkosten seit 17 Jahren zu verzeichnen sind.
Da Cyberkriminelle immer raffinierter werden, müssen Unternehmen Lösungen finden, um die gespeicherten Daten besser zu schützen. Eine hervorragende Lösung, um die Risiken von Datenschutzverletzungen zu minimieren und die Einhaltung der DSGVO zu gewährleisten, ist Data Masking.
In diesem Blog erfahren Sie, was Data Masking ist, wie es funktioniert und wie Klippa das Maskieren von Daten für Sie automatisieren kann.
Kurzübersicht
- Was ist Data Masking? Eine Technik zur Verschleierung sensibler Daten, um Datenschutz und Sicherheit zu gewährleisten.
- Warum ist es wichtig? Schützt personenbezogene und vertrauliche Informationen vor unbefugtem Zugriff.
- Welche Methoden gibt es? Statische, dynamische und On-the-Fly-Maskierung für verschiedene Anwendungsfälle.
- Welche Vorteile bringt es? Erfüllt DSGVO-Anforderungen, reduziert Risiken und ermöglicht sicheres Datenmanagement.
- Mit Klippa DocHorizon: Automatische Erkennung und Maskierung sensibler Daten in Dokumenten und Datenbanken.
Was ist Data Masking?
Data Masking, auch bekannt als Data Anonymization, Data Redaction, oder Data Obfuscation, ist eine Sicherheitstechnik zur Maskierung sensibler Daten. Solche Daten sind zum Beispiel Sozialversicherungsnummern oder Zahlungskartennummern.
Data Masking wird angewandt, um eine Gefährdung der Daten zu vermeiden und die Sicherheitsrisiken zu verringern, während gleichzeitig die Datenschutzbestimmungen eingehalten werden.
Viele Unternehmen müssen beispielsweise im Rahmen der Kundenbetreuung Überprüfungen der Kundenidentität (Know Your Customer – KYC) durchführen. Um die Identität der Kunden zu überprüfen, müssen Unternehmen Ausweisdokumente verarbeiten.
Einige Informationen, wie z. B. Sozialversicherungsnummern, dürfen jedoch gemäß der Datenschutz-Grundverordnung nicht gespeichert werden. Obwohl es Ausnahmen gibt, müssen die meisten Organisationen die Daten anonymisieren oder verschleiern, um die Einhaltung der Vorschriften zu gewährleisten.
Derzeit gewinnt Data Masking immer mehr an Fahrt, und es wird geschätzt, dass die Branche von 483,90 Millionen US-Dollar im Jahr 2020 auf 1044,93 Millionen US-Dollar im Jahr 2026 wachsen wird.
Datenmaskierung zum Schutz von sensiblen Daten
Datenmaskierung kann zum Schutz vieler Arten von Daten verwendet werden. Zu den gängigsten Arten gehören:
- Personenbezogene Informationen (PII)
- Geschützte Gesundheitsinformationen (PHI)
- Informationen zur Bankkarte (PCI-DSS)
- Health Insurance Portability and Accountability Act (HIPAA)
Es ist wichtig zu wissen, wie Datenmaskierung funktioniert und welche Arten und Techniken für Ihre Geschäftszwecke geeignet sind. Nur dann wird es einfacher sein, Data Masking zum Schutz von datenschutzrechtlich sensiblen Daten einzusetzen.
Schauen wir uns einmal an, wie Data Masking funktioniert.
Wie funktioniert Data Masking?
Der Ausgangspunkt ist die Ermittlung aller sensiblen Daten, die Ihr Unternehmen besitzt oder verarbeitet. Dabei ist es wichtig zu bedenken, dass Daten in vielen Formen auftreten können: E-Mails, Faxe, Excel-Tabellen, Datenbankinformationen und gescannte Dokumente wie Pässe, um nur einige zu nennen.
Sobald die Identifizierung der Daten abgeschlossen ist, sollten Algorithmen und Techniken zur Maskierung der Daten angewendet werden. Unternehmen können sensible Daten je nach Anwendungsfall und rechtlichen Anforderungen entfernen, schwärzen, ersetzen oder verschlüsseln.
Nehmen wir als Beispiel eine Excel-Tabelle mit Kundendaten, einschließlich sensibler Informationen wie Kontonummern. Bei der Speicherung dieser Art von Informationen kann Data Masking dazu beitragen, die Sicherheit Ihrer Daten zu erhöhen.
Anstatt sensible Daten preiszugeben, können beispielsweise die Kontonummern durch ein “x” ersetzt werden, so dass nur die letzten vier Ziffern angezeigt werden.
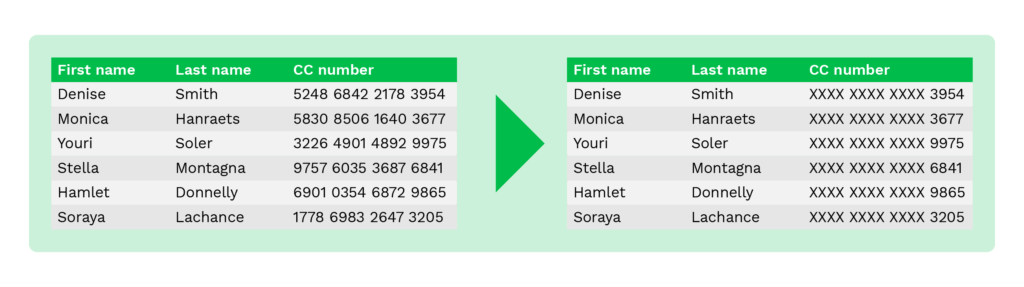
Selbst wenn nur die letzten vier Ziffern angezeigt werden, können Ihre Back-Office-Mitarbeiter die Besitzer des Bankkontos verifizieren. Auf diese Weise können Betrüger die Kontonummer nicht verwenden, selbst wenn sie die Informationen erhalten.
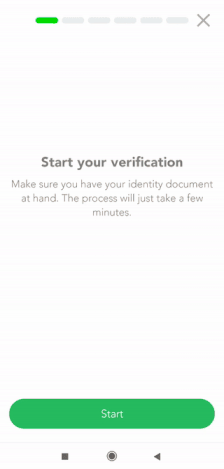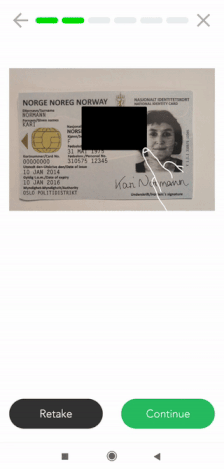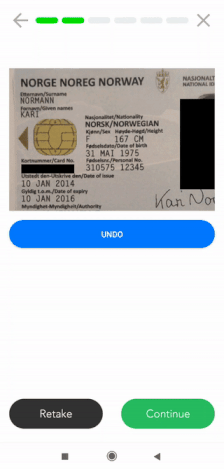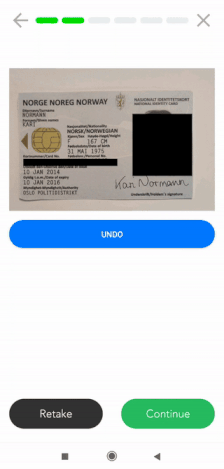
Ein weiteres Beispiel wäre das Maskieren von Informationen auf dem Scan eines Ausweisdokuments aus einem KYC-Prozess. Unten sehen Sie ein Vorher-Nachher-Bild eines maskierten Reisepasses, um die Einhaltung der DSGVO zu gewährleisten.

Ein ähnlicher Ansatz der Maskierung von Daten kann auf Versicherungsnummern, Kreditkartennummern oder Sozialversicherungsnummern angewandt werden, um nur einige zu nennen.
Nachdem wir nun erklärt haben, wie Data Masking funktioniert, wollen wir uns nun zwei verschiedene Arten ansehen.
Data Masking Arten
Es gibt mehrere Data Masking Arten, und die Verwendung hängt in erster Linie von den Ressourcen, Anwendungsfällen und Anbietern ab. Die beiden häufigsten Arten der Maskierung von Daten sind die statische und dynamische Datenmaskierung.
Wir werden den Unterschied in den folgenden Abschnitten näher erläutern.
Static data masking
Static Data Masking (SDM) wird häufig für Softwaretests benötigt, um sensible Daten zu ersetzen, indem Daten verändert werden, die auf einem Laptop, einer Festplatte oder in einer Datenbank gespeichert sind. Mit Static Data Masking können Unternehmen Daten- und Datenschutzbestimmungen wie GDPR, PCI, PHI, PII, ITAR und HIPAA einhalten.
Diese Data Masking Architektur beginnt mit der Originalkopie, aus der sensible Daten maskiert werden, bevor sie zur weiteren Verarbeitung (in einer Datenbank, Software usw.) weitergeleitet werden.
Bei diesem Ansatz werden sensible Informationen dauerhaft ersetzt, um die Einhaltung von Datenschutzbestimmungen und den Schutz vor Datenschutzverletzungen zu gewährleisten.

Dynamic data masking
Die Dynamic Data Masking (DDM) Architektur unterscheidet sich von der statischen. Sie wird verwendet, um sensible Daten während der Übertragung (d.h. bei aktiver Nutzung) zu maskieren, wobei die Originalkopie unverändert bleibt. Bei diesem Ansatz sind die unmaskierten Daten in der eigentlichen Datenbank sichtbar.
DDM wird hauptsächlich für die Bearbeitung von Kundenanfragen und die Bearbeitung von Krankenakten in rollenbasierten Sicherheitsanwendungen eingesetzt. In einigen Branchen ist es notwendig, sensible Daten vor bestimmten Benutzern zu verbergen.
Mit DDM können Unternehmen geänderte Anfragen (d. h. Datenanfragen) an die ursprüngliche Datenbank verwenden, um die Daten dynamisch zu maskieren und an den Anfragenden weiterzuleiten.
Diese Art der Datenmaskierung wird häufig verwendet, wenn Unternehmen Daten an Drittanbieter oder interne Beteiligte senden, die nicht berechtigt sind, sensible Daten zu sehen. Bei solchen Daten kann es sich um Sozialversicherungsnummern (SSN) oder Kreditkartennummern handeln.

Nachdem nun die gängigsten Arten der Datenmaskierung behandelt wurden, wollen wir uns nun die Data Masking Techniken ansehen.
Data Masking Techniken
Für die Datenmaskierung gibt es verschiedene Techniken, die im Folgenden erläutert werden.
Substitution
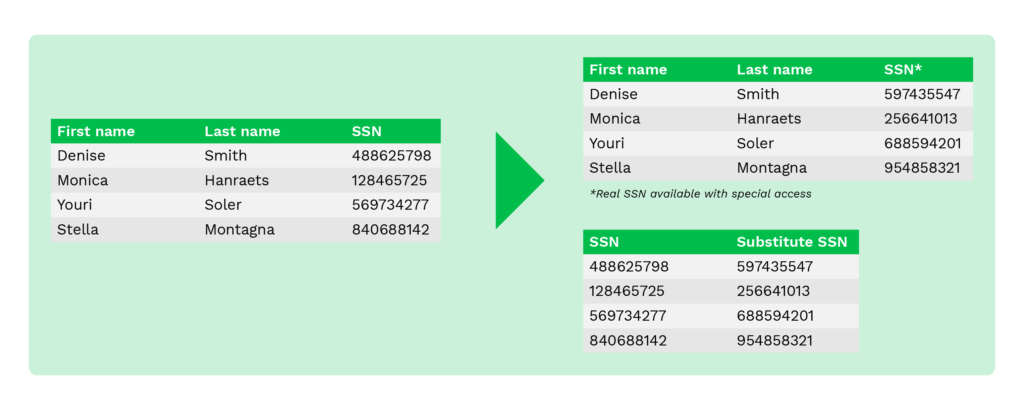
Die Substitution, auch Pseudonymisierung genannt, ist eine Technik, bei der die Originaldaten durch Zufallsdaten aus mitgelieferten oder angepassten Lookup-Dateien ersetzt werden. Sie ist nützlich, wenn Organisationen das authentische Aussehen von Daten bewahren und gleichzeitig sensible Daten verschleiern müssen.
Mit dieser Technik lassen sich Daten wirksam vor Verstößen schützen und der interne Zugriff kontrollieren.

Shuffling
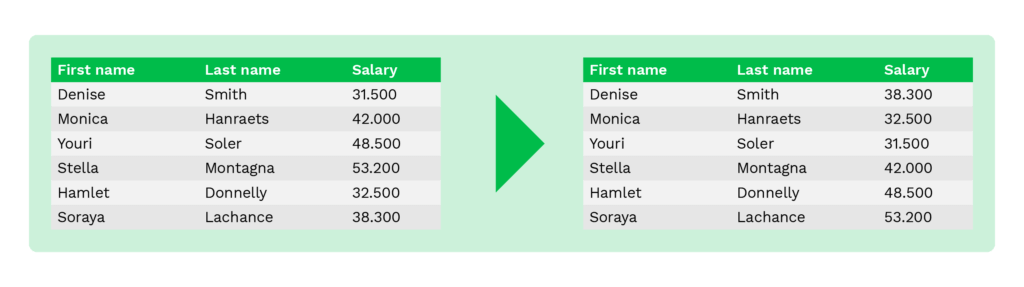
Shuffling ist eine ähnliche Technik wie die Substitution. Sie wird ebenfalls verwendet, um Originaldaten durch andere Daten zu ersetzen, die authentisch aussehen. Der Unterschied besteht darin, dass die Einheiten in derselben Spalte zufällig gemischt werden.
Unternehmen können diese Technik beispielsweise verwenden, um die Spalten mit den Mitarbeiternamen in mehreren Mitarbeiterdatensätzen nach dem Zufallsprinzip zu mischen. Diese Technik kann anfällig für Reverse Engineering sein, wenn jemand den Umordnungsalgorithmus in die Hände bekommt.
Averaging
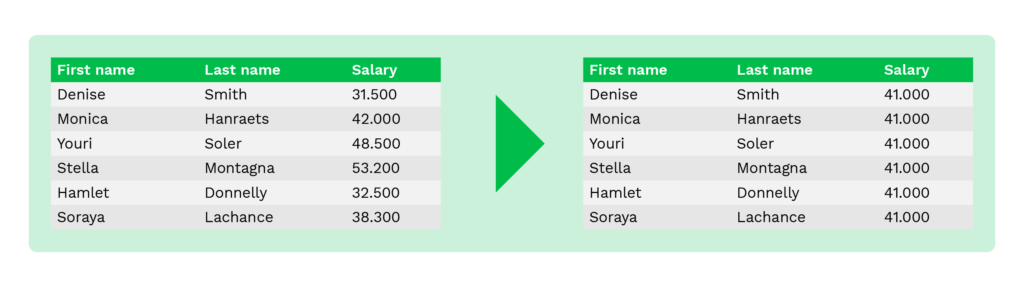
Averaging ist eine Methode, um die ursprünglichen Werte durch einen Durchschnittswert der Tabellenspalten zu ersetzen. So zeigt der Initiator beispielsweise statt der Gehälter oder Kontostände von Einzelpersonen nur den Durchschnittswert der Löhne oder Kontostände an.
Diese Methode trägt dazu bei, den Gesamtwert zu erhalten und wird üblicherweise für statistische Analysen oder Datenerhebungen von Finanzinstituten verwendet.
Nulling out (Deletion)
Nulling out ist eine Technik, bei der sensible Daten durch einen Nullwert ersetzt werden, um zu verhindern, dass unbefugte Benutzer die Originaldaten sehen können. Es bedeutet einfach, dass die Informationen in Dokumenten entfernt oder durch einen leeren Wert ersetzt werden.

In einigen Anwendungsfällen werden Informationen in bestimmten Dokumenten ganz weggelassen, z. B. das Geburtsdatum in Lebensläufen. Dies geschieht häufig, um das Risiko unethischer Einstellungsverfahren zu vermeiden.

Datenredaktion (Blacklining)
Die Datenredaktion, auch Blacklining genannt, ist eine Methode, die dem Löschen ähnelt, da nur ein Teil der Originaldaten maskiert wird.
So werden den Kunden beim Online-Shopping nur die letzten vier Ziffern der Kartennummer angezeigt, um Betrug zu verhindern.
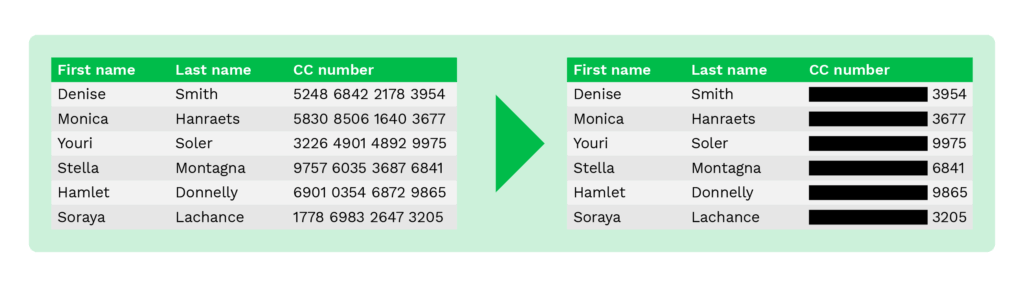

Die gleiche Methode kann auf jedes Dokument angewandt werden, das datenschutzrelevante Informationen enthält. Unten sehen Sie das Beispiel eines Reisepasses, bei dem mehrere Felder geschwärzt sind.

Data Scrambling
Die Data Scrambling Technik wird verwendet, um Daten zu verändern, indem die Reihenfolge der Zeichen oder Zahlen mit einem bestimmten Algorithmus zufällig neu angeordnet wird.
Die Originaldaten sind nach Abschluss des Vorgangs nicht mehr zu erhalten, da die Daten verschlüsselt sind.
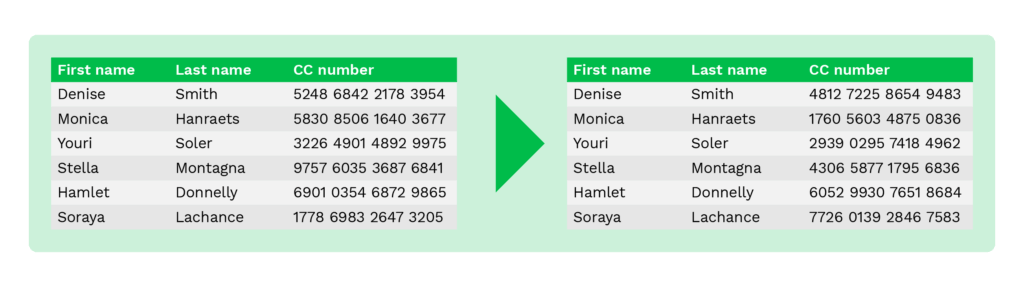

Datenverschlüsselung
Datenverschlüsselung ist eine Technik, die den Zugriff auf Daten nur mit dem Entschlüsselungsschlüssel erlaubt.
Es ist der komplexeste und sicherste Algorithmus zur Datenmaskierung. Zusätzlich zu seiner Komplexität erfordert er eine angemessene Verwaltung der Verschlüsselungsschlüssel, um die Sicherheit zu gewährleisten.


Warum ist Data Masking wichtig?
Seit der Einführung der Datenschutz-Grundverordnung hat der Datenschutz für viele Unternehmen oberste Priorität. Infolgedessen haben Organisationen es für unerlässlich gehalten, Data Masking als eines der Werkzeuge zum Schutz ihrer sensiblen Daten zu implementieren.
Warum also ist Data Masking notwendig? Im Prinzip bietet Data Masking Unternehmen einen sicheren Weg, um alternative Versionen von nutzbaren und gut gesicherten Daten zu erstellen.
Mit dem Einsatz von Data Masking können Unternehmen von folgenden Vorteilen profitieren.
Einhaltung der Datenschutzgesetze
Data Masking hilft Unternehmen bei der Einhaltung von Datenschutzgesetzen und -vorschriften. Mit den verschiedenen verfügbaren Datenmaskierungstechniken können zahlreiche Organisationen die Preisgabe sensibler Daten verhindern.
Doch nicht alle Unternehmen nutzen Data Masking, um die GDPR einzuhalten.
So wurde beispielsweise der große Modeeinzelhändler H&M im Jahr 2020 wegen Verstößen gegen die DSGVO zu einer Geldstrafe von 35 Millionen Euro verurteilt. Der Vorfall betraf den Zugriff der Geschäftsleitung auf sensible Daten wie religiöse Überzeugungen und Familienangelegenheiten durch Aufzeichnungen von Besprechungen. Diese Aufzeichnungen wurden als Grundlage für die Bewertung der Leistungen der Mitarbeiter verwendet.
Dieser Vorfall hätte vermieden werden können, wenn alle sensiblen Daten aus den Aufzeichnungen dieser Besprechungen entfernt worden wären.
Schutz vor Datenschutzverletzungen
Einer der Hauptvorteile von Data Masking besteht darin, die Daten für Cyberangreifer unbrauchbar zu machen und gleichzeitig ihre Nutzbarkeit für das Unternehmen zu bewahren. Selbst wenn die Daten durch Cyberangriffe verletzt werden, können viele Data Masking Techniken verhindern, dass Unbefugte an sensible Informationen gelangen.
Im Jahr 2018 wurde bekannt, dass Panera Bread aufgrund mangelnder Zugangskontrollen und Sicherheitsmaßnahmen mindestens 37 Millionen Kundendaten preisgegeben hat. Daten wie persönliche E-Mails, Adressen und Kreditkarteninformationen waren durch Crawling zugänglich.
Auch dieses Szenario hätte durch verschiedene Data Masking Techniken vermieden werden können.
Geringere Datensicherheitsrisiken
Viele Unternehmen arbeiten in ihrem Umfeld mit Dritten und Anbietern zusammen, denen einige Daten übergeben werden. Darüber hinaus können auch Mitarbeiter und andere interne Beteiligte Zugang zu Daten haben.
Einfach ausgedrückt: Es besteht immer die Gefahr, dass Daten verloren gehen. Data Masking bietet jedoch die Möglichkeit, Daten vor Personen oder Parteien zu schützen, die nicht befugt sind, sie einzusehen.
Es sind nur falsche Daten zu sehen, es sei denn, die Berechtigung zur Demaskierung der Daten wurde erteilt. Somit kann die Anonymisierung von Daten interne Datensicherheitsrisiken und Datenlecks verringern.
Insgesamt bietet Data Masking beeindruckende Vorteile, die Unternehmen einen Wettbewerbsvorteil verschaffen können. Was sind aber die häufigsten Anwendungsfälle? Werfen wir einen Blick auf einige dieser Fälle.
Data Masking Anwendungsfälle
Es gibt viele Anwendungsfälle für die Datenmaskierung, darunter die folgenden:
- Blacklining Kreditkartennummern
- Anonymisierung von Sozialversicherungsnummern
- Zensur des Lebenslaufs
- Maskierung von Daten für die digitale Archivierung
- Schwärzung oder Verschlüsselung von persönlichen Gesundheitsinformationen
- Schwärzung oder Verschlüsselung von Regierungsdokumenten
- Schwärzung von Rechtsdokumenten und öffentlichen Gerichtsverfahren
- Anonymisierung von Sitzungsaufzeichnungen
- Interne Zugangskontrolle
- Verschlüsselung von Dokumenten über geistiges Eigentum
- Datenaustausch mit Drittanbietern
Im Folgenden gehen wir auf die ersten vier näher ein.
Blacklining von Kreditkarten
Es kann vorkommen, dass ein Mitglied Ihrer Organisation Zugang zu Kreditkarten- oder Zahlungskarteninformationen benötigt. Daher kann die Verwendung von Datenmaskierung zum Schwärzen der letzten vier Ziffern der Kartennummer verhindern, dass sensible Komponenten wie Kreditkartennummern offengelegt werden.
Dies ist ein weit verbreitetes Verfahren, mit dem Banken und andere Finanzinstitute die Zahlungsdaten ihrer Kunden verarbeiten. Durch das Schwärzen der Kreditkartennummer können Organisationen die Einhaltung des PCI-DSS sicherstellen.

Anonymisierung von Sozialversicherungsnummern
Informationen wie die Sozialversicherungsnummer auf Ausweisdokumenten wie Pässen und Personalausweisen sind höchst sensibel. Oft dürfen Organisationen außerhalb staatlicher Einrichtungen die Sozialversicherungsnummer nicht in ihrer Datenbank speichern.
In den Niederlanden ist die Bürgerservicenummer (BSN) gleichbedeutend mit der Sozialversicherungsnummer. Die BSN ist eine eindeutige persönliche Bürgerservicenummer, die zur Identifizierung jedes registrierten Bürgers verwendet wird. Die BSN wird zum Beispiel von staatlichen Einrichtungen verwendet, um Daten von jedem Bürger zu finden, oft für Steuerzwecke.
Sozialversicherungsnummern und Bürgerservicenummern sind nach der Datenschutz-Grundverordnung grundsätzlich geschützt, da sie zu den “besonderen Kategorien personenbezogener Daten” gehören. Natürlich gibt es Fälle, in denen die Speicherung solcher Daten erlaubt ist. Aber nur mit einer besonderen gesetzlichen Ausnahme oder der Zustimmung der Person.
Daher ist es üblich, Sozialversicherungsnummern oder Bügerservicenummern (BSN) mit verschiedenen Datenmaskierungstechniken zu anonymisieren.

Zensur des Lebenslaufs
Trotz aller Schulungen zum Abbau von Voreingenommenheit im Einstellungsprozess machen sich viele Personalverantwortliche schuldig, ihre Entscheidungen auf verschiedene Vorurteile zu stützen. Leider ist es immer noch üblich, dass bei zwei Bewerbern mit ähnlichen Fähigkeiten und Erfahrungen der attraktivere von beiden eingestellt wird.
Obwohl es illegal ist, bei der Einstellung von Mitarbeitern in irgendeiner Weise zu diskriminieren, tun dies viele Unternehmen immer noch. In der Tat sind 20 % der Unternehmen in den USA für die Hälfte der Diskriminierungsfälle verantwortlich.
Unternehmen haben damit begonnen, Lebensläufe zu schwärzen, um Vorurteile und Diskriminierung in der Anfangsphase des Einstellungsverfahrens zu beseitigen. Laut dem Bericht von HRO Today sind die häufigsten Felder, die in Lebensläufen geschwärzt werden, folgende:
- Wohnanschrift
- Name
- Bild (Attraktivität, Geschlecht, Herkunft)
Mit Data Masking werden die Personalverantwortlichen besser darin unterstützt, die Bewerber ausschließlich auf der Grundlage ihrer Fähigkeiten und Erfahrungen zu bewerten. Es ist jedoch wichtig zu beachten, dass Personalverantwortliche auch nur Menschen sind.

Maskierung von Daten für die digitale Archivierung
Die Speicherung von Daten auf Papier ist für viele Unternehmen keine Option mehr. Die Gründe für Unternehmen, mit dem Fortschritt der Technologie zur Digitalisierung überzugehen, sind unter anderem:
- Ein enormer Rückstau an unorganisierten Daten
- Interne Zugangskontrolle
- Zeit- und Kosteneinsparungen
- Umweltfreundlichkeit
- Einhaltung der GDPR
- Leichter Datenzugriff
Die Archivierung von Daten kann sehr vorteilhaft sein, doch die Herausforderung besteht darin, die rechtlichen Verpflichtungen in Bezug auf den Datenschutz zu erfüllen. In dieser Hinsicht ist die Datenmaskierung eine sichere und solide Lösung, um die Einhaltung der GDPR zu gewährleisten.
Vor der Archivierung können Unternehmen durch Data Masking einfach alle sensiblen Daten wie Namen, Patientennummern und Sozialversicherungsnummern aus den Dokumenten entfernen oder sie durch strukturell identische Daten (gleiche Anzahl von Zahlen oder Zeichen) ersetzen.
Organisationen haben diese Methode in Branchen wie dem Rechtswesen und dem Gesundheitswesen übernommen, um nur einige zu nennen.
Nachdem wir nun einige Anwendungsfälle behandelt haben, wollen wir uns den Wandel der Schwärzung von Dokumenten ansehen.
Die Wandlung der Dokumentenredaktion
Seit wir denken können, wird die manuelle Schwärzung von Dokumenten in verschiedenen Branchen eingesetzt. Dies ist eine mühsame Aufgabe, die viele Probleme mit sich bringt. Eines der Hauptprobleme ist die Skalierbarkeit.
Mitarbeiter haben Mühe, Genauigkeit, Effizienz und Konsistenz über einen längeren Zeitraum aufrechtzuerhalten. Dies führt zu langsamen Bearbeitungszeiten, unzufriedenen Kunden und hohen Kosten.
Nehmen wir als Beispiel die Rechtsbranche. Ein typischer Arbeitsablauf umfasst Teams von Anwälten und Rechtsanwaltsgehilfen, die Hunderte von Stunden lang große Stapel an Dokumenten durchgehen.
Anstatt ihr Wissen und ihre Erfahrung für sinnvolle Aufgaben zu nutzen, werden sie mit dem Hinzufügen, Ändern und Entfernen von Schwärzungen in Dokumenten beauftragt. Ganz zu schweigen von den Kosten für die Anstellung dieser Mitarbeiter.
Die Aufstockung des Personalbestands bei steigendem Dokumentenaufkommen lässt die Kosten schnell in die Höhe schnellen. Machen wir uns also nichts vor. Die manuelle Schwärzung von Dokumenten ist keine skalierbare Option (zumindest nicht, wenn Sie kosteneffizient sein wollen).
Glücklicherweise ist es mit der heutigen Technologie möglich, die Schwärzung von Dokumenten zu automatisieren. Es gibt zwei Möglichkeiten, die Unternehmen nutzen können: vollautomatisches Data Masking und automatisches Data Masking mit menschlicher Unterstützung.
Vollautomatisches Data Masking
Bei einer vollautomatischen Lösung zur Datenmaskierung ist kein menschliches Eingreifen erforderlich. Mit Technologien wie der KI-gestützten optischen Zeichenerkennung (OCR) ist es möglich, die erforderlichen Informationsfelder in Dokumenten automatisch zu erkennen, zu lokalisieren und zu entfernen.
Sie müssen die OCR-Engine lediglich mit den Dokumenten füttern, die maskiert werden sollen, und sie erledigt den Rest. Diese Option setzt Ihre personellen Ressourcen frei, die Sie für kompliziertere Aufgaben einsetzen können. Auf diese Weise können Sie außerdem die Effizienz Ihrer Organisation maximieren.
Menschengestütztes Data Masking
Die andere Lösung ist die menschengestützte Automatisierung, mit anderen Worten die HITL-Automatisierung (Human-in-the-Loop). Diese Lösung nutzt KI für die Automatisierung und ermöglicht es dem Mitarbeiter, die abschließenden Kontrollen durchzuführen, um die Vollständigkeit des Data Masking zu überprüfen.
Der Vorteil der Human-in-the-Loop-Automatisierung besteht darin, dass sie eine höhere Genauigkeit bei der Dokumentenredaktion ermöglicht. Dies ist keine Überraschung, da die HITL-Lösung das Beste der künstlichen Intelligenz mit dem Besten der menschlichen Intelligenz kombiniert.
Manchmal gibt es Probleme mit der Technologie (Bildqualität, Dokumentenqualität usw.), die die Durchführung von Datenmaskierungsaufträgen einschränken. Daher kann eine Überprüfung der Dateneingabe oder -ausgabe helfen, Fehler zu vermeiden.
Eine dieser Lösungen von Grund auf neu zu entwickeln ist schwierig, kostspielig und zeitaufwändig. Aus diesem Grund haben wir bei Klippa beschlossen, unsere OCR-Technologie mit Datenmaskierungsfunktionen zu kombinieren, um verschiedenen Unternehmen zu helfen. Wir können unseren Kunden helfen, Data Masking in großem Umfang zu automatisieren.

Warum also sollte Ihr Unternehmen Data Masking automatisieren? Lassen Sie uns auf die Vorteile eingehen, die sich daraus ergeben.
Vorteile des vollautomatischen Data Masking
Zwar können Unternehmen mit Data Masking Daten vor Lecks schützen und die Einhaltung der GDPR sicherstellen, doch bietet automatisiertes Data Masking noch viele weitere Vorteile. Diese Vorteile umfassen:
- Schnellere Bearbeitungszeiten – Die Automatisierung der Schwärzung von Dokumenten oder Daten ermöglicht es Ihren Mitarbeitern, sich auf wichtigere Aufgaben zu konzentrieren. Es werden weniger Mitarbeiter benötigt, um diese mühsamen Aufgaben zu erledigen, und die Bearbeitungszeit wird verkürzt.
- Genauigkeit – Mit einer automatisierten Data Masking Lösung, die KI nutzt, können Unternehmen höhere Genauigkeit erzielen, da Maschinen und Computer nie müde werden.
- Geschwindigkeit – Mit einer automatisierten Lösung kann der Prozess der Datenschwärzung bis zu 90 Mal schneller ablaufen. Eine vereinfachte Berechnung finden Sie im folgenden Abschnitt.
- Kosteneinsparungen – Durch die höhere Effizienz und Genauigkeit, die mit KI erreicht wird, können Unternehmen erheblich Geld sparen (Arbeitsstunden, weniger Fehler usw.).
- Skalierbarkeit – Ein durchschnittlicher Mitarbeiter kann nur eine bestimmte Anzahl von Dokumenten bearbeiten. Die Automatisierung der Datenmaskierung bietet Unternehmen die Möglichkeit, Dokumente in großem Umfang zu schwärzen, ohne Betriebskosten zu erhöhen.
Es scheint, als könnten Unternehmen in vielerlei Hinsicht von einer automatisierten Data Masking Lösung profitieren. Aber was bedeutet dies für Sie in Bezug auf Ihr Geschäft?
Um dies für Sie greifbar zu machen, haben wir im folgenden Abschnitt eine Beispielrechnung für eine mögliche Kapitalrendite (ROI) erstellt.
Der ROI der automatisierten Data Masking Lösung
Nehmen wir an, Sie haben 100.000 Ausweisdokumente, aus denen Sie die Sozialversicherungsnummern herausfiltern müssen. Nehmen wir des Weiteren an, dass ein erfahrener Büroangestellter im Durchschnitt zwei Ausweisdokumente pro Minute manuell bearbeiten kann. Das macht 120 Ausweisdokumente in einer Stunde. Die Kosten für die Einstellung eines erfahrenen Sachbearbeiters (einschließlich Versicherung, Stundenlohn und anderer Kosten) belaufen sich auf 25,00 € pro Stunde.
Um sicherzustellen, dass die Schwärzung korrekt durchgeführt wird, müssten Sie einen weiteren Sachbearbeiter einstellen, der die geschwärzten Dokumente doppelt überprüft. Nehmen wir an, dass ein identischer Sachbearbeiter jede Schwärzung mit einer Geschwindigkeit von 360 Identitätsdokumenten pro Stunde auf ihre Richtigkeit überprüfen kann.
Die Gesamtkosten für die manuelle Schwärzung von 100.000 Identitätsdokumenten würden sich auf über 27.700 € belaufen. Die für die Durchführung des Projekts erforderlichen Mitarbeiterstunden belaufen sich auf über 1 110.
Vergleicht man dies mit der Lösung von Klippa, die 10.000 Dokumente pro Stunde bearbeiten kann, so könnte man das Projekt in 10 Stunden abschließen. Das sind etwa 1.100 eingesparte Arbeitsstunden.
Schätzungsweise würde es Ihr Unternehmen 4.000 € kosten, dieses Projekt mit unserer Lösung abzuschließen (je nach Dokumentenvolumen und -typ). Sie könnten also das Projekt über 90 Mal schneller und mit einem ROI von 6,9 abschließen.

Testen Sie unseren Data Masking ROI-Rechner!
Data Masking mit Klippa – Sichere und effiziente Datenanonymisierung
Klippa unterstützt Unternehmen bei der Digitalisierung und Automatisierung der Dokumentenverarbeitung durch den Einsatz modernster Technologien. Mithilfe von künstlicher Intelligenz (KI), maschinellem Lernen und OCR ermöglichen wir eine effiziente und sichere Datenverarbeitung für Kunden weltweit.
- Unsere Intelligent Document Processing (IDP)-Lösung, Klippa DocHorizon, wurde speziell für die automatisierte Dokumentenverarbeitung entwickelt. Sie ermöglicht:
- Digitalisierung von Dokumenten
- Extraktion relevanter Informationen
- Klassifizierung und Verifizierung von Daten
- Data Masking (Anonymisierung) sensibler Informationen
Mit Klippa DocHorizon reduziert Ihr Unternehmen Bearbeitungszeiten, Kosten und menschliche Fehler, während gleichzeitig sensible Daten gemäß Datenschutzvorschriften geschützt bleiben.
Flexible Data Masking-Lösungen für jede Systemlandschaft
Unsere KI-gestützte OCR-Software beinhaltet integrierte Data Masking-Funktionen, um personenbezogene und geschäftskritische Daten automatisch zu anonymisieren. Für maximale Flexibilität bieten wir:
- Data Masking API – Ermöglicht eine nahtlose Integration in bestehende Dokumentenmanagement-, ERP- oder EHR-Systeme.
- Data Masking SDK – Entwickelt für Unternehmen, die unsere Technologie direkt in ihre eigenen Systeme einbinden möchten.
Durch diese modularen Lösungen unterstützt Klippa Unternehmen dabei, Datenschutzrichtlinien effizient einzuhalten und sensible Informationen sicher zu verarbeiten.
Klippa Data Masking API – Automatisierte Anonymisierung für maximale Datensicherheit
Unsere OCR-gestützte Data Masking API wurde entwickelt, um Unternehmen dabei zu unterstützen, wiederholende Verwaltungsaufgaben zu automatisieren und sensible Informationen zuverlässig zu schützen. Sie ermöglicht das automatische Schwärzen bestimmter Felder und Bilder in Dokumenten – schnell, präzise und DSGVO-konform.
Intelligente Erkennung & flexible Anpassung
Unsere Parsing-Engine kann trainiert werden, spezifische Datenfelder automatisch zu erkennen und zu maskieren. Neben zahlreichen vorkonfigurierten Feldern bieten wir auch die Möglichkeit, benutzerdefinierte Maskierungsregeln nach Bedarf zu definieren.
Breite Kompatibilität & flexible Ausgabeformate
- Eingabeformate: JPG, PNG, PDF
- Standardausgabe: JSON, kompatibel mit ERP-, DMS- oder EHR-Systemen
- Weitere Exportoptionen: CSV, XLSX, XML sowie maskierte Dokumente als JPG oder PDF
Nahtlose Integration & einfache Nutzung
Unsere RESTful-API ermöglicht eine einfache Einbindung in bestehende webbasierte Anwendungen. Um die Integration zu erleichtern, stellen wir eine detaillierte API-Dokumentation bereit, die unseren Kunden eine reibungslose Implementierung ermöglicht.
Data Masking auf dem Smartphone
Wenn Sie eine mobile Data Masking Lösung benötigen, kann Klippa Sie ebenfalls unterstützen. Wir bieten eine mobile Scanner-SDK an, die Funktionen zur Datenmaskierung enthält. Kunden nutzen diese Scanner-SDK, um bestimmte Informationen in Ausweisdokumenten, Quittungen, Rechnungen und vielen anderen Arten von Dokumenten zu maskieren.
Derzeit ist unsere Scanner-SDK sowohl für Android als auch für IOS verfügbar. Außerdem bieten wir Wrapper für plattformübergreifende Sprachen wie ReactNative, Flutter, Cordova und Nativescript. Generell kann sie jedoch in jede mobile Lösung integriert werden.
Dokumente mit Wasserzeichen versehen
Für den Fall, dass eine der Methoden des Data Masking für Sie nicht in Frage kommt, bietet Klippa als Alternative auch digitale Wasserzeichen für Dokumente an. Auf diese Weise können Sie das Urheberrecht Ihrer Dokumente schützen, Ihren Kunden einen sichereren Datenaustausch ermöglichen und Sicherheitsrisiken bei der Speicherung sensibler Daten verringern.
Legen Sie Klippa DocHorizon einfach ein Dokument vor, und es gibt dasselbe Dokument mit einem Wasserzeichen zurück. Dieses Wasserzeichen enthält etwas, das Ihren Bedürfnissen entspricht – zum Beispiel Ihren Firmennamen und das Scandatum.

Egal, ob Sie eine komplette End-to-End-Lösung oder eine flexible API-/SDK-Integration zur automatisierten Dokumentenverarbeitung benötigen – Klippa bietet die passende Lösung für Ihre Anforderungen.
FAQ
Data Masking ist eine Methode zur Anonymisierung oder Verschleierung sensibler Daten, um deren Vertraulichkeit zu gewährleisten. Es schützt personenbezogene und geschäftskritische Informationen vor unbefugtem Zugriff und hilft Unternehmen, Datenschutzvorschriften wie die DSGVO einzuhalten.
Es gibt zwei Hauptarten von Data Masking: Das Statische Data Masking. Dabei werden Daten dauerhaft maskiert und in Test- oder Entwicklungsumgebungen verwendet. Sowie das Dynamische Data Masking. Hier werden Daten in Echtzeit maskiert, wenn sie von bestimmten Nutzern oder Anwendungen abgerufen werden.
Zu den gängigsten Techniken des Data Masking zählen: Substitution, bei der Originaldaten durch fiktive Werte ersetzt werden, Shuffling (Durchmischung), bei dem Datensätze zufällig vertauscht werden, um ihre Anonymität zu gewährleisten, sowie Datenverschlüsselung, die Daten in ein unlesbares Format umwandelt, das nur mit einem spezifischen Schlüssel entschlüsselt werden kann.
Data Masking findet in verschiedenen Bereichen Anwendung, darunter: Softwareentwicklung, um anonymisierte Daten für Testzwecke bereitzustellen, Schulungen, bei denen realistische, aber anonymisierte Datensätze verwendet werden, sowie Datenanalyse, um sensible Informationen während der Analyse zu schützen.
Automatisiertes Data Masking bietet zahlreiche Vorteile: Effizienz, durch die schnelle und skalierbare Verarbeitung großer Datenmengen, Konsistenz, indem Maskierungsregeln einheitlich angewendet werden, und Sicherheit, da menschliche Fehler minimiert und Datenschutzverletzungen verhindert werden.
Klippa bietet automatisierte Lösungen zur Datenmaskierung an, die Unternehmen helfen, sensible Daten sicher und DSGVO-konform zu verarbeiten. Die Technologie erkennt und maskiert personenbezogene Daten in Dokumenten und Datenbanken effizient.