
Laut dem Theft Resource Center wurden allein im Jahr 2021 1.862 Datenschutzverletzungen registriert – ein Anstieg von 68 % im Vergleich zum Vorjahr. Eine alarmierende Entwicklung, insbesondere da immer mehr Daten in cloudbasierten Systemen gespeichert und zugänglich sind.
Für Unternehmen ist es essenziell, dass sensible Informationen nicht in die falschen Hände geraten. Eine der wirksamsten Maßnahmen, um das Risiko bei der Speicherung und Weitergabe von Daten im Internet zu minimieren, ist das gezielte Entfernen sensibler Informationen. Denn je weniger vertrauliche Daten vorhanden sind, desto geringer ist das Sicherheitsrisiko.
Bedeutet das, dass jedes Dokument manuell überprüft und bereinigt werden muss? Zum Glück nicht! Moderne Softwarelösungen erkennen und entfernen sensible Informationen automatisch, ohne manuellen Aufwand.
Doch was genau zählt eigentlich als sensible Information? Wie funktioniert die automatische Zensur solcher Daten? Und kann Software diesen Prozess wirklich effizient und sicher gestalten?
In diesem Blog beantworten wir diese Fragen, geben konkrete Beispiele und zeigen Ihnen, welche Vorteile eine automatisierte Lösung für Ihr Unternehmen bietet.
Kurzübersicht
- Datenschutz gewährleisten: Vertrauliche Daten in Dokumenten müssen vor unbefugtem Zugriff geschützt werden.
- Automatische Anonymisierung: KI-gestützte Lösungen erkennen und maskieren sensible Informationen wie personenbezogene Daten.
- DSGVO- & Compliance-konform: Die Entfernung sensibler Daten minimiert Risiken und erfüllt gesetzliche Vorgaben.
- Effiziente Dokumentenverarbeitung: Automatisierung spart Zeit, reduziert Fehler und erhöht die Sicherheit.
- Intelligente Lösungen: Tools wie Klippa DocHorizon ermöglichen eine präzise und regelkonforme Datenanonymisierung.
Was sind sensible Informationen?
Beginnen wir mit der Definition von sensiblen Informationen. Sensible Informationen sind Informationen, die vor Einblicken geschützt werden sollten. Es handelt sich um vertrauliche, private oder anderweitig geheime Informationen, die nur bestimmten Personen zugänglich sein sollten. Ob eine Information sensibel ist, hängt von der Zielgruppe, der sie offenbart wird, und vom rechtlichen Kontext einer Organisation und eines Landes ab.
In Europa werden sensible Daten weitgehend durch die GDPR-Vorschriften definiert, während in Amerika die meisten Unternehmen den California Consumer Privacy Act (CCPA) einhalten müssen.
Sensible Informationen können in Dokumenten enthalten sein, die in Papierform oder digital gespeichert und organisiert sind, z. B. ein Foto und ein Name auf einem Lebenslauf. In diesem Blog konzentrieren wir uns auf Informationen, die digital gespeichert sind.

Welche Arten von Daten müssen entfernt werden?
Um den Prozess des Findens und Entfernens sensibler Daten zu beginnen, muss eine Organisation definieren, welche Arten von Informationen Kunden und Mitarbeiter üblicherweise teilen, welche davon tatsächlich benötigt werden und welche entfernt werden müssen.
Im Allgemeinen gibt es vier Arten von Daten, die vor unbefugten Personen geschützt werden müssen:
- Personenbezogene Informationen: Dazu gehören alle Daten, die zur Identifizierung einer bestimmten Person verwendet werden können. Informationen wie der vollständige Name, die Sozialversicherungsnummer, die Führerscheinnummer oder die Reisepassnummer.
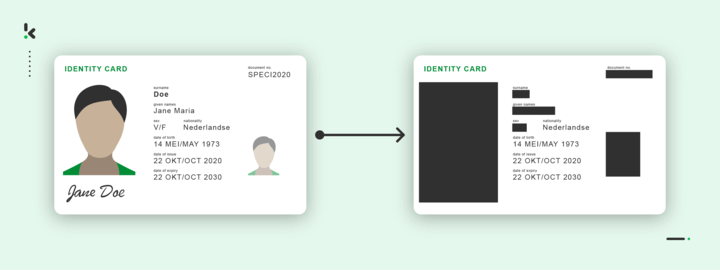
- Geschützte Gesundheitsinformationen: Diese Informationen umfassen die Krankengeschichte, demografische Informationen, Test- und Laborergebnisse, psychische Erkrankungen, Versicherungsinformationen und andere persönliche Gesundheitsdaten.

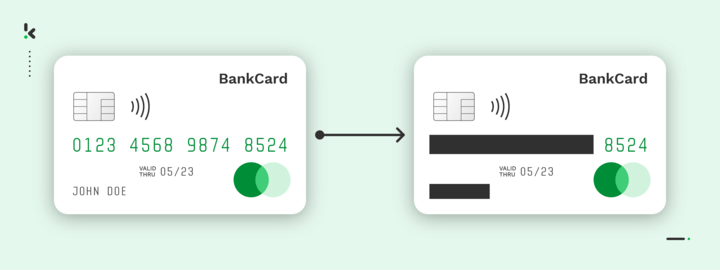
- Informationen zur Bankkarte: Jedes Unternehmen muss die Informationssicherheitsstandards einhalten, die für den Umgang mit Kreditkarten gelten. Als sensible Informationen werden hier die Kreditkartennummer, der Name des Karteninhabers oder die Ablaufdaten bezeichnet. Dies kann insbesondere für PCI/DSS-Compliance-Verpflichtungen relevant sein.
- Geistiges Eigentum: Informationen über geistiges Eigentum beziehen sich auf Werke wie Erfindungen, Entwürfe, literarische und künstlerische Werke oder im Geschäftsleben verwendete Namen und Bilder. In diesem Fall werden die Informationen in der Regel nicht geschwärzt, sondern das Werk wird mit einem Wasserzeichen versehen, um den Eigentümer des Eigentums anzugeben.
In diesen Datentypen sind die folgenden Felder normalerweise als sensible Informationen gekennzeichnet. Folgende können identifiziert und entfernt werden:
- Name
- Adresse
- Geburtsdatum
- Alter
- Kontonummer
- Kreditkartennummer
- Sozialversicherungsnummer
- Arbeits- und Bildungsverlauf
- Bilder
- Unterschrift
Natürlich treffen nicht alle der oben genannten Informationen auf Ihr Unternehmen zu, da dies von Branche zu Branche unterschiedlich ist. Aber da Sie nun einen Überblick über die Informationen haben, nach denen Sie suchen sollten, haben Sie eine gute Grundlage für die folgenden Schritte.
Warum sollten sensible Informationen aus einer Datenbank entfernt werden?
Es gibt mehrere Gründe, warum Unternehmen sensible Daten aus ihren Datenbanken entfernen sollten. Der Schutz sensibler Informationen ist nicht nur eine gesetzliche Verpflichtung in vielen Branchen, sondern auch eine Frage des Respekts gegenüber Kunden und anderen betroffenen Personen.
Hier sind die vier wichtigsten Gründe für die Entfernung sensibler Daten:
- Einhaltung gesetzlicher Vorschriften (z. B. DSGVO)
- Minimierung von Sicherheitsrisiken (Schutz vor Datenlecks und Cyberangriffen)
- Vermeidung rechtlicher Konsequenzen (Bußgelder und Sanktionen)
- Erfüllung von Versicherungsanforderungen (Risikominimierung für Unternehmen)
Datenverstöße sind ein ernstzunehmendes Risiko und können erhebliche Schäden für Unternehmen und betroffene Personen verursachen. Um sich davor zu schützen, sollten sensible Informationen in Dokumenten zuverlässig geschwärzt oder entfernt werden.
Zudem hilft die Anonymisierung oder Maskierung von Daten dabei, die strengen Datenschutzvorgaben der DSGVO zu erfüllen. In der EU gelten hohe Standards für den Umgang mit personenbezogenen Daten, einschließlich Transparenz, Zweckbindung und Speicherbegrenzung. Wer seine Daten auf einem europäischen Server hostet, muss diese Anforderungen zwingend einhalten.
Wie nennt man die Entfernung sensibler Informationen aus einem Dokument?
Kurz gesagt: Data Masking. Dieser Prozess ist auch unter Begriffen wie Datenanonymisierung, Datenverschleierung und Schwärzung bekannt.
Es gibt verschiedene Methoden des Data Masking, darunter Ersetzung, Umordnung, Mittelwertbildung, Nullsetzung, Schwärzung, Zufallsanordnung und Verschlüsselung.
Wir gehen hier nicht auf jede Technik im Detail ein – wenn Sie jedoch mehr darüber erfahren möchten, empfehlen wir Ihnen unseren ultimativen Leitfaden zum Data Masking.
Falls Sie mit den Grundlagen dieser Technologie noch nicht vertraut sind, lesen Sie einfach weiter. Im nächsten Abschnitt erklären wir, wie sensible Daten automatisch aus Dokumenten entfernt werden können.
Wie lassen sich sensible Daten automatisch aus Dokumenten entfernen?
Wenn Sie nur einige wenige Dateien haben, aus denen sensible Daten entfernt werden müssen, ist es durchaus in Ordnung, dies manuell zu tun. In größeren Unternehmen ist die schiere Menge an Dokumenten und Daten jedoch meist sehr groß.
Dies führt zu einer zeitraubenden Aufgabe, die von Hand erledigt werden muss. Der Kosten- und Zeitaufwand wäre sehr hoch, die Durchlaufzeiten lang und Fehler häufig.
Glücklicherweise gibt es eine Alternative zur manuellen Anonymisierung von Informationen. Beim Finden und Entfernen sensibler Informationen aus Dokumenten kann fast jeder Schritt automatisiert und von Software für die intelligente Dokumentenverarbeitung (IDP) durchgeführt werden.
Eine IDP-Lösung wie Klippa DocHorizon ist beispielsweise in der Lage, Dokumente innerhalb von Sekunden zu prüfen, zu zensieren bzw. Text im PDF zu schwärzen. Bei Klippa bieten wir mehrere Optionen zum automatischen Auffinden und Maskieren sensibler Daten an, wie z. B.:
- Vollständig automatisiertes Data Masking mit KI
- Menschlich unterstützte Automatisierung
- Data Masking auf dem Smartphone
Vollständig automatisiertes Data Masking mit KI
Mit einer vollautomatischen Data Masking Lösung sind menschliche Eingriffe nicht mehr notwendig, um Daten zu anonymisieren wie z. B in PDFs. Klippa hat die DocHorizon API entwickelt, die es Ihnen ermöglicht, sensible Informationen in Dokumenten innerhalb weniger Sekunden automatisch zu erkennen, zu lokalisieren und zu schwärzen.
Dies ist dank der KI-gestützten OCR-Technologie möglich, die mit Hunderten von Dokumenten trainiert wurde, um bestimmte Felder zu erkennen und sensible Informationen zu schwärzen.
Durch das vollautomatische Data Masking gewinnen Ihre Mitarbeiter Zeit und können ihre Fähigkeiten für komplizierte Aufgaben einsetzen. Auf diese Weise wird die Effizienz Ihrer Organisation gesteigert.
Menschlich unterstützte Automatisierung
Wenn Ihr Unternehmen höchste Genauigkeit benötigt, kann es sinnvoll sein, eine menschlich unterstützte Automatisierung einzusetzen. Dabei überprüft eine Person das maskierte Dokument, bevor die Daten endgültig in der Datenbank gespeichert werden.
Dadurch lassen sich Fehler vermeiden, die beispielsweise durch schlechte Bild- oder Dokumentenqualität entstehen könnten. Gleichzeitig wird die Genauigkeit der Datenverarbeitung erheblich verbessert.
Diese Methode kombiniert die Effizienz künstlicher Intelligenz mit der Präzision menschlicher Kontrolle und ermöglicht es Ihrem Unternehmen, sicher und effektiv zu arbeiten.
Data Masking auf dem Smartphone
Wenn Sie selbst eine Applikation haben oder eine entwickeln wollen, ist die einfachste Lösung, diese durch die Integration unserer mobile Scanner SDK mit Data Masking Funktionen zu erweitern.
Unsere mobile Scanner SDK umfasst Data Masking Techniken, mit denen Sie ein Dokument (z. B. einen Personalausweis, eine Rechnung oder einen Reisepass) fotografieren und dann manuell eine schwarze Box zeichnen können, die sensible Informationen maskiert. So wird sichergestellt, dass nur die notwendigen Informationen freigegeben und gespeichert werden.
Wir möchten, dass Sie eine fundierte Entscheidung treffen können. Deshalb stellen wir im Folgenden einige Vorteile der automatischen und manuellen Entfernung sensibler Daten vor.
Welche Vorteile hat die automatische Entfernung sensibler Daten?
Wie viele Dokumente bearbeiten Sie pro Woche? Pro Monat? Wahrscheinlich enthalten nicht alle davon sensible Informationen – aber stellen Sie sich vor, wie viel Zeit und Aufwand Sie sparen könnten, wenn nicht jedes Dokument manuell geprüft werden müsste.
Hier sind die wichtigsten Vorteile der automatisierten Datenentfernung:
- Sekundenschnelles Scannen und Extrahieren von Daten
- Minimierung von Fehlern durch automatische Prozesse
- Reduzierung von Arbeitskosten, Bearbeitungszeiten und manuellen Korrekturen
- Hohe Skalierbarkeit, ideal für wachsende Unternehmen
Um Ihnen den Unterschied zwischen manueller und automatisierter Dokumentenverarbeitung noch deutlicher zu machen, haben wir eine Tabelle erstellt. Sie hilft Ihnen, die jeweiligen Vor- und Nachteile auf einen Blick zu erkennen.
Was sind häufige Anwendungsfälle für die Redaktion von sensiblen Daten?
In den nächsten Abschnitten werden wir drei verschiedene Arten von Anwendungsfällen diskutieren:
- Ausweisdokumente
- Patientenakten
- Finanzielle Dokumente
Blacklining von Ausweispapieren
Einer der häufigsten Anwendungsfälle ist die Anonymisierung von Kopien von Ausweisdokumenten. Informationen wie die Sozialversicherungsnummer auf einem Reisepass oder Personalausweis sind sehr sensibel und dürfen oft nicht in einer Datenbank gespeichert werden.
Eine Sozialversicherungsnummer gehört zu den „besonderen Kategorien personenbezogener Daten“ und unterliegt gemäß den Anforderungen der DSGVO strengen Regeln. Normalerweise haben nur staatliche Einrichtungen die Erlaubnis, Sozialversicherungsnummern in ihrer Datenbank zu speichern, was bedeutet, dass andere Organisationen Wege finden müssen, diese Daten zu entfernen.
Eine Möglichkeit zur Schwärzung der Sozialversicherungsnummer besteht darin, die erforderlichen Informationen auf der Kopie des Dokuments mit intelligenter Software automatisch zu schwärzen.
Blacklining von Patientenakten
Persönliche Gesundheitsdaten sind sensibel und müssen geschützt werden. Wenn Gesundheitsdienstleister und andere Organisationen, die Patientendaten verwenden, bearbeiten oder übermitteln, die oben genannten Anforderungen der Datenschutzgrundverordnung nicht einhalten, sind Strafen und Geldbußen die Folge.
Ein Gesundheitsdienstleister muss Tausende von Dokumenten bearbeiten, und es wäre unmöglich, sie alle manuell durchzugehen. Hier ist eine Software, die automatisch sensible Informationen aus Patientenakten finden und entfernen kann, von entscheidender Bedeutung, um effektiv und effizient arbeiten zu können.
Die Krankenakte eines Patienten enthält Informationen wie die Adresse, die Sozialversicherungsnummer und die Versicherungsnummer des Patienten. Nicht jeder ist berechtigt, diese Informationen einzusehen, weshalb es wichtig ist, die Daten zu schwärzen und somit zu zensieren. Das Schwärzen von Informationen mit Software ist eine Möglichkeit, Daten automatisch zu zensieren und Patienten vor Betrug und Datenschutzverletzungen zu schützen.
Blacklining von Finanzdokumenten
Rechnungen, Kreditkartenkopien und Verträge sind Dokumente, die täglich im Finanzsektor bearbeitet werden. Sie enthalten sensible Informationen, die vor unbefugten Personen geschützt werden sollten.
Die Finanzdienstleistungsbranche sollte die Absicht haben, Betrug zu verhindern und die Einhaltung der Vorschriften zu gewährleisten. Sobald ein Finanzinstitut die Einhaltung der Vorschriften nicht sicherstellt, können schwere Rufschädigungen, Gerichtsverfahren oder staatliche Geldstrafen die Folge sein.
Nehmen wir eine Rechnung als Beispiel: Informationen wie der Name und die Adresse eines Kunden sind Daten, die geschwärzt werden sollten. Durch den Einsatz dieser Technik könnte Betrug durch doppelte oder falsch erstellte Rechnungen verhindert werden.
Alle Dokumente manuell durchzugehen, wäre eine unmögliche Aufgabe. Deshalb wurden intelligente Dokumentenlösungen wie Klippa entwickelt, die Ihnen helfen, den Prozess zu automatisieren.

Wir haben gerade drei verschiedene Anwendungsfälle beschrieben, aber das Gleiche gilt im Grunde für jeden Dokumententyp oder jedes Bild. Wenn wir Ihren speziellen Fall hier nicht abgedeckt haben und Sie sich fragen, ob wir auch Ihnen helfen können, können Sie uns gerne kontaktieren, um Ihre Fragen zu stellen und weitere Informationen zu erhalten.
Datenschutz mit Klippa DocHorizon: Automatisierte Datenmaskierung
Mit Klippa DocHorizon schützen Sie sensible Informationen in Dokumenten durch intelligente Datenmaskierung und Datenanonymisierung. Unsere IDP-Lösung erkennt und entfernt vertrauliche Daten automatisch – präzise, regelkonform und effizient.
Ihre Vorteile mit Klippa DocHorizon:
- DSGVO-, HIPAA- & ISO-konform – Automatische Anonymisierung personenbezogener Daten zur Einhaltung globaler Datenschutzvorschriften.
- Sekundenschnelle Verarbeitung – Dokumente werden in Sekunden anonymisiert, ohne manuellen Aufwand.
- Flexibles Hosting – Cloud oder On-Premises, passend zu Ihren Datenschutzanforderungen.
- Einfache Integration – Nahtlose Anbindung per API oder Low-Code-Plattform.
- Optional: Human-in-the-loop – Maximale Präzision durch interne Kontrolle oder Unterstützung unseres Annotation-Teams.
- Dokumentenverifikation – Erkennen und authentifizieren Sie Dokumente automatisch, um Betrug zu vermeiden.
Klippa DocHorizon, die beste Software zum automatischen Schwärzen von Dokumenten!
Klippa DocHorizon ist die optimale Lösung, wenn Sie sensible Informationen aus Dokumenten sicher und automatisch entfernen möchten. Mit unserer Software können Sie Dokumente schwärzen, ohne jede Seite manuell durchzugehen – ideal für Datenschutz, Compliance und interne Freigabeprozesse.
Ob personenbezogene Daten, Bankverbindungen oder interne Vermerke: Klippa erkennt sensible Inhalte automatisch und schwärzt sie zuverlässig. Die KI-gestützte Technologie sorgt für Geschwindigkeit, Genauigkeit und volle Kontrolle bei der Dokumentenverarbeitung.
Sparen Sie Zeit, reduzieren Sie Risiken und erfüllen Sie Datenschutzanforderungen mühelos mit einer Lösung, die Ihre Teams sofort entlastet.
Mit Klippa DocHorizon verarbeiten Sie sensible Dokumente sicher und effizient. Testen Sie es selbst in einer kostenlosen Demo!
FAQ
Datenmaskierung ist der Prozess, sensible Informationen in Dokumenten unkenntlich zu machen oder zu anonymisieren. Sie ist essenziell für den Datenschutz, da sie verhindert, dass personenbezogene oder vertrauliche Daten unautorisiert eingesehen oder weitergegeben werden.
Typische Beispiele sind persönliche Daten (Namen, Adressen, Telefonnummern), Bankverbindungen, Steuer- und Sozialversicherungsnummern sowie geschäftskritische Informationen. In regulierten Branchen ist dies besonders wichtig, um Datenschutzvorschriften wie die DSGVO einzuhalten.
Klippa DocHorizon nutzt KI-gestützte OCR-Technologie zur Erkennung und Klassifizierung sensibler Informationen in Dokumenten. Die Software kann Daten gezielt identifizieren und automatisch anonymisieren, basierend auf vordefinierten Regeln oder Machine-Learning-Modellen.
Klippa DocHorizon kann eine Vielzahl von Dokumenten verarbeiten, darunter PDFs, Scans, Bilder (JPG, PNG), Word-Dokumente (DOCX) und strukturierte Datenformate (CSV, JSON, XML).
Ja, Klippa DocHorizon bietet flexible Konfigurationsmöglichkeiten. Unternehmen können genau definieren, welche Daten entfernt oder geschwärzt werden sollen, je nach Compliance-Anforderungen oder internen Richtlinien.
Ja, Klippa DocHorizon entspricht den DSGVO-, HIPAA- und ISO 27001-Standards. Alle Daten werden sicher verarbeitet, und Unternehmen können wählen, ob sie ihre Dokumente in der Cloud oder On-Premises hosten möchten.
Klippa speichert Dokumente standardmäßig nicht. Nach der Verarbeitung können Unternehmen wählen, ob sie die anonymisierten Dokumente speichern oder eine automatische Löschung nach einer bestimmten Zeit aktivieren möchten.
Ja, Klippa bietet eine API-gestützte Lösung, die sich einfach in bestehende ERP-, CRM- oder Dokumentenmanagementsysteme integrieren lässt. Unternehmen können so die Datenmaskierung nahtlos in ihre Workflows einbinden.
Die Verarbeitung erfolgt in Sekunden, unabhängig vom Dokumentenvolumen. Die OCR- und KI-gestützte Erkennung ermöglicht eine hohe Verarbeitungsgeschwindigkeit mit minimalem manuellem Aufwand.