
Der Einsatz einer OCR-Lösung ist bereits weit verbreitet. Tatsächlich wird der weltweite OCR-Markt im Jahr 2021 auf 8,93 Milliarden Dollar geschätzt.
Die meisten Unternehmen kennen daher bereits die Bedeutung von OCR für die Automatisierung der Dokumentenverarbeitung. Aber warum ist das so? Die Antwort ist einfach.
OCR-Lösungen ermöglichen eine einfachere, schnellere und effizientere Verarbeitung von Dokumenten mit wenig oder gar keinem menschlichen Eingriff. Das ist der Schritt, den Unternehmen tun müssen, um wettbewerbsfähig zu bleiben.
Viele dieser Unternehmen verwenden eine Template-basierte OCR, die gut funktioniert, wenn Sie nur einen Dokumententyp in einer Sprache verarbeiten müssen. Grundsätzlich funktioniert dies am besten mit einer bestimmten Struktur ohne Variationen im Layout.
Möglicherweise müssen Sie jedoch mehrere Dokumenttypen wie Rechnungen, Quittungen und Pässe in verschiedenen Sprachen verarbeiten. Die Template-basierte OCR kann solche Dokumente nicht effizient verarbeiten, da sie unstrukturiert sind und nicht immer dem gleichen Layout folgen.
In einem solchen Fall brauchen Sie eine Alternative zur Template-basierten OCR. Eine Alternative, mit der Sie unstrukturierte Daten aus einer Vielzahl von Dokumenten verarbeiten können: OCR basiert auf Machine Learning.
In diesem Artikel erfahren Sie mehr über OCR basiert auf Machine Learning und wie diese Technologie Sie voranbringen kann. Doch zunächst möchten wir näher erläutern, warum die Template-basierte OCR nur der erste Schritt zur Automatisierung Ihrer Dokumentenverarbeitung ist.
Template-basierte OCR, der erste Schritt zur Automatisierung der Dokumentenverarbeitung
Die Template-basierte OCR wird oft auch als traditionelle OCR bezeichnet. Wie jede andere OCR-Software liest, extrahiert und liefert sie Ausgabedaten für die weitere Verarbeitung. Die Hauptbesonderheit der Template-basierten OCR ist, dass sie für die Arbeit mit bestimmten Dokumenttypen, Formaten und Sprachen trainiert ist.
Außerdem kann sie nur mit strukturierten Daten arbeiten, wie Namen, Daten, Adressen oder Bestandsinformationen in standardisierten Formaten. Bei der Template-basierten OCR müssen sich die Daten zudem genau an der Stelle befinden, für die die Software geschult wurde.
Wenn Sie die Template-basierte OCR verwenden, haben wir Ihnen bisher wahrscheinlich nichts Neues erzählt. Sie wissen, wie sie verwendet werden kann und was sie bewirkt.
In diesem Fall sind Sie sich wahrscheinlich auch der Herausforderungen bewusst, die die Verwendung von Template-basierter OCR mit sich bringt, insbesondere was die Skalierbarkeit betrifft. Für jedes neue Dokument, das Sie verarbeiten möchten, müssen Sie neue Vorlagen erstellen. Diese Vorlagen legen im Grunde die Regeln für die Software fest und bestimmen, wo nach welchen Informationen zu suchen ist.
Was wäre, wenn wir Ihnen sagen würden, dass es eine fortschrittlichere Alternative gibt? Eine, die nicht durch Vorlagen und spezifische Layouts eingeschränkt ist: Machine Learning OCR. Im folgenden Abschnitt erfahren Sie mehr über Machine Learning und wie es Ihnen das Leben sehr erleichtern kann.
Was ist Machine Learning?
Machine Learning ist ein Zweig der künstlichen Intelligenz, bei dem mathematische Datenmodelle verwendet werden, um Computern das Lernen ohne menschliche Anweisungen zu ermöglichen. Vereinfacht gesagt, ermöglicht Machine Learning einer Maschine, intelligentes menschliches Verhalten zu replizieren.
Darüber hinaus lernt Machine Learning kontinuierlich, verbessert schrittweise seine Genauigkeit und macht anhand von vergangenen und aktuellen Daten Vorhersagen für die Zukunft.
Aber was hat das alles mit OCR zu tun? Das wollen wir als Nächstes herausfinden!
Machine Learning OCR
Machine Learning ermöglicht es der OCR-Software, den allgemeinen Kontext eines Dokuments zu verstehen und zu erkennen. Dank der Fähigkeit von Machine Learning, Vorhersagen zu treffen, hat die OCR-Software keine Probleme mit der Vielfalt der Dokumente, die sie erhält. Mit genügend Daten kann sie vorhersagen, wo bestimmte Datenfelder erscheinen, und die Daten entsprechend aus den Dokumenten extrahieren.
Natürlich sind viele Daten erforderlich, damit die Prognosemodelle genau sind. Sie müssen jedoch nicht jedes Mal neue Vorlagen mit strengen Regeln erstellen, wenn Sie es mit einem neuen Lieferanten oder Dokumententyp zu tun haben.
Darüber hinaus sind einige OCR-Lösungen mit Machine Learning in der Lage, Anomalien im Text oder in der Dokumentenstruktur zu erkennen, weshalb sie zur Aufdeckung von Dokumentenbetrug eingesetzt werden.
Nachdem nun beide Technologien erläutert wurden, ist es an der Zeit zu sehen, warum Machine Learning OCR die beste Alternative zur Template-basierten OCR ist.
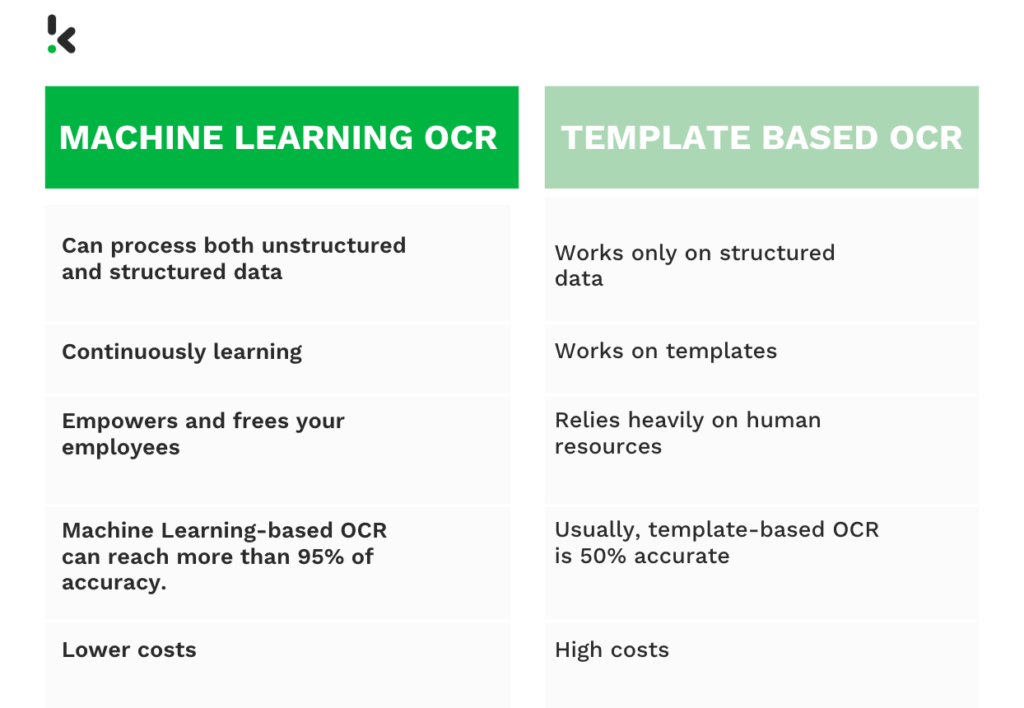
Template OCR vs. Machine Learning OCR
Um zu beweisen, dass Machine Learning OCR die beste Alternative zur templatebasierten OCR ist, werden wir beide Ansätze in den folgenden Punkten vergleichen:
- Fähigkeit zur Verarbeitung strukturierter und unstrukturierter Daten
- Lernfähigkeit
- Einbeziehung der Mitarbeiter
- Genauigkeit
- Kosten- und Zeitersparnis
Nehmen wir jeden dieser Punkte und sehen wir, warum Machine Learning OCR die beste Lösung für die Dokumentenverarbeitung ist.
Fähigkeit zur Verarbeitung strukturierter und unstrukturierter Daten
Machine Learning OCR kann sowohl strukturierte als auch unstrukturierte Daten in einem Dokument verarbeiten. Nehmen wir eine Rechnung als Beispiel.
Wenn sie richtig trainiert ist, versteht Machine Learning OCR, welche Daten Beträge, Händlerdetails, Einzelposten usw. sind. Und das nicht nur auf einer bestimmten Rechnungsvorlage, sondern auf jeder Rechnung, die Sie erhalten.
Da Machine Learning OCR, mit Vorhersagen arbeitet und die menschliche Intelligenz imitiert, kann sie Dokumente auf der Grundlage des Inhalts und der Struktur klassifizieren. Alle Dokumente können genau verarbeitet werden, solange die Maschine mit genügend Daten gefüttert wurde.
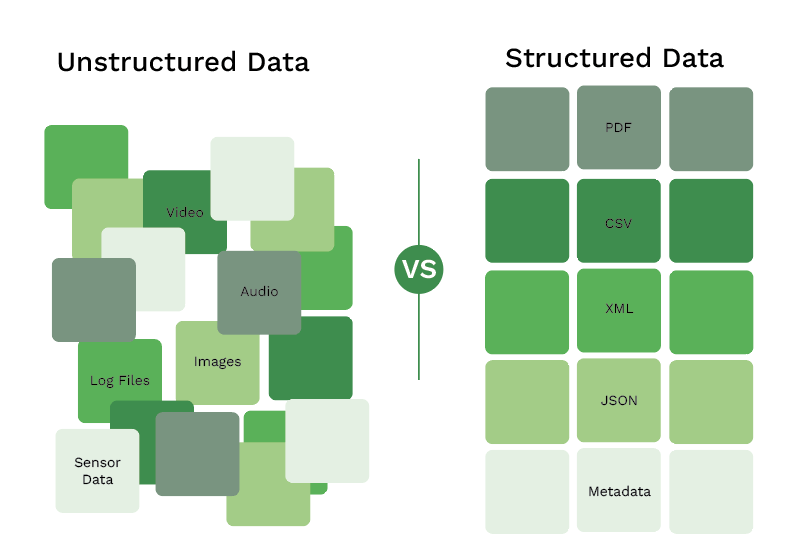
Mit Machine Learning sind Sie in der Lage, alle Arten von Dokumenten zu verarbeiten, unabhängig davon, ob sie strukturierte oder unstrukturierte Daten enthalten. Die Template-basierte OCR hingegen funktioniert nur bei strukturierten Daten. Dies ist ein erheblicher Nachteil, da es die Skalierbarkeit der Dokumentenverarbeitung in Ihrem Unternehmen einschränkt.
Lernfähigkeiten
Das Hauptziel des Machine Learning besteht darin, Computern zu ermöglichen, autonom und ohne menschliche Beiträge zu lernen. Lassen Sie uns diesen Lernprozess näher erläutern.
Die Machine Learning OCR basiert auf Vorhersagemodellen, die aus Algorithmen und Trainingsdaten erstellt werden. Zunächst werden die Modelle auf der Grundlage aller verarbeiteten Dokumente und Datensätze erstellt.
Anstatt eine bestimmte Position auf einem Dokument zu suchen, sagen die Algorithmen anhand aller bereits gelesenen und verarbeiteten Beispiele voraus, wo sich die Daten befinden sollten.
Auf der Grundlage der Erfahrungen, die die Engine mit anderen Dokumenten gemacht hat, lernt Machine Learning OCR ständig dazu. Deshalb brauchen Sie weniger Ressourcen, um sie zu verbessern.
Da weniger Ressourcen für die Verbesserung der OCR-Lösung benötigt werden, können sich Ihre Mitarbeiter mehr wertschöpfenden Aufgaben widmen. Darauf wollen wir als Nächstes eingehen.
Einbeziehung der Arbeitnehmer
Machine Learning OCR kann für Ihr Unternehmen ein großer Gewinn sein. Durch die Automatisierung weiterer Prozesse werden Ihre Mitarbeiter von lästigen Dateneingaben befreit und müssen sich weniger mit der Erstellung von Templates für die OCR-Software beschäftigen. Ihr Team kann sich nun auf wichtigere Aufgaben konzentrieren, die zum Wachstum Ihres Unternehmens beitragen.
So weit, so gut, aber wie sieht es mit der Genauigkeit der beiden Ansätze aus? Wir wollen herausfinden, ob es einen Unterschied zwischen den beiden gibt.
Genauigkeit
Die Genauigkeit ist einer der Hauptgründe, warum Unternehmen bei der Datenextraktion auf Automatisierung setzen.
Machine Learning in Kombination mit OCR-Technologie bietet eine Genauigkeitsrate von mehr als 95 %. Um diese Genauigkeitsrate zu erreichen, analysiert und interpretiert das Machine Learning-Modell die Rohdaten. Dieser Schritt ermöglicht es Machine Learning OCR-Lösungen, Muster zu erkennen und dann Daten mit hoher Genauigkeit zu erkennen und zu extrahieren.
All diese Informationen und Erfahrungen beim Verstehen des Dokuments werden dann verwendet, um weitere Ähnlichkeiten im nächsten Dokument vorherzusagen.
Während herkömmliche OCR, z. B. auf Template basierende OCR, eine Datenextraaktionsgenauigkeit von 60 % bis 85 % aufweist, können viele fortschrittlichere Lösungen, die mit KI und Machine Learning ausgestattet sind, bis zu 95 % erreichen.

Dank des Machine Learning ist die OCR-Software fast völlig autonom. Sie extrahiert Daten mit einer hohen Genauigkeitsrate. Das hilft Ihnen, die Zeit Ihres Teams zu sparen und die Betriebskosten zu senken. Dazu gleich mehr.
Kosten- und Zeitersparnis
Im Allgemeinen ist Machine Learning OCR kostengünstiger als OCR mit Templates. Um dies zu belegen, sollten wir uns die folgenden Faktoren ansehen:
- Weniger Personalbedarf – Höhere Effizienz führt zu niedrigeren Betriebskosten.
- Höhere Genauigkeit – Weniger Fehler bei der Dateneingabe sparen Ihnen auf lange Sicht viel Geld.
- Keine teure Vorlagenerstellung erforderlich – Spart Ihrem Unternehmen Zeit und Geld.
Sie haben inzwischen gelernt, dass die herkömmliche OCR nicht die effizienteste Software für die Datenextraktion ist. Mit Machine Learning OCR können Sie all Ihre Dokumente schneller, mit höherer Genauigkeit und niedrigeren Kosten verarbeiten.
Wenn Sie wissen möchten, wie die Machine Learning OCR von Klippa Ihnen dabei helfen kann, finden Sie unten weitere Informationen.
Wir stellen vor: Klippa DocHorizon
An dieser Stelle haben Sie den Blog gelesen und sich über die Unterschiede zwischen Template-basierter OCR und Machine Learning OCR informiert. Haben wir Ihr Interesse an einer genauen und effizienten Machine Learning OCR-Lösung geweckt? Dann lesen Sie weiter, es wird noch interessanter.
Klippa ist ein Experte für automatisierte Dokumentenverarbeitung. Unser Unternehmen bietet intelligente OCR-Software wie Klippa DocHorizon, die Datenextraktion, Klassifizierung, Überprüfung und Anonymisierung automatisiert. Unsere gesamte Software basiert auf Machine Learning und KI.
Klippa DocHorizon ist in der Lage, alle Arten von Dokumenten zu verarbeiten: Finanzdokumente, Ausweisdokumente, Logistikdokumente und so weiter. Probieren Sie es mit unseren Beispielen unten aus oder senden Sie selbst ein Dokument ein und sehen Sie, wie unsere Machine Learning OCR-Lösung funktioniert.
Try it Out Yourself
Innerhalb weniger Sekunden, in der Regel zwischen 1 und 5 Sekunden, wird das Dokument verarbeitet. Ihr Dokument wird gescannt, und alle Daten werden in dem von Ihnen gewählten strukturierten Ausgabeformat geliefert.
Sind Sie bereit, Ihre Dokumentenverarbeitung zu automatisieren? Buchen Sie eine Demo mit einem unserer Spezialisten, der Ihnen gerne die Möglichkeiten aufzeigt.