Die Rechnungserkennung, auch bekannt als Scan and Recognition oder OCR, ist seit einigen Jahren ein heißes Thema in der Finanzbuchhaltung. Langsam aber sicher stellt das Rechnungswesen auf die automatisierte Buchhaltung um. Die Rechnungserkennung ist in der Buchhaltung ein wichtiger Bestandteil.
Lange Zeit stand die Rechnungserkennung vor allem für die Schlagzeileninformationen wie Kreditor, Debitor, Datum, Rechnungsnummer, Gesamtbetrag etc. zur Verfügung. Die Entwicklung der Technologie hat jedoch zunehmend intelligente maschinelle Lernsysteme ermöglicht.
Bei Klippa zum Beispiel arbeiten wir mit Deep Learning. Mit dieser Technologie ist es möglich, immer mehr spezifische Informationen aus Dokumenten mit immer höherer Genauigkeit zu extrahieren. Deshalb ist eine automatische Rechnungserkennung auf Linienebene auch mit der Klippa OCR API und der Rechnungsbearbeitung möglich!
Warum ist die Einzelposten Erkennung von Rechnungen sinnvoll?
Die automatische Extraktion der Kerninformationen einer Rechnung ist natürlich bereits sehr nützlich, um viele Rechnungen in einen automatisierten Buchungsvorschlag umzuwandeln. Die OCR-Technologie hat sich in diesem Bereich bereits bewährt. Insbesondere bei standardisierten Ledgern wird die Automatisierung von Buchungsvorschlägen immer einfacher.
Es ist jedoch nicht immer möglich, einen kompletten Buchungsvorschlag mit den Kerninformationen zu erstellen. Schließlich haben Rechnungen (und Belege) manchmal mehrere Rechnungszeilen und nicht jede Zeile muss auf dasselbe Hauptbuchkonto, dieselbe Kostenstelle oder dasselbe Projekt gebucht werden.
Durch die Erkennung von Rechnungen auf Einzel-Positionsebene steht unserer selbstlernenden Software mehr Kontext zur Verfügung und fast alle Vorschläge können präzise gemacht werden.
Wie funktioniert die Erkennung der Einzelposten auf Rechnungen?
Wir verwenden ein maschinelles Lernmodell, um die Positionen auf Rechnungen zu erkennen. Es mag eine etwas technische Geschichte sein, aber wir verwenden dafür deep learning.
Eine Form des maschinellen Lernens, bei der die Software selbst aus einem Satz von gekennzeichneten Daten eine Bedeutung ableiten kann. Bei Klippa haben wir einen großen Datensatz entwickelt, in dem die Rechnungspositionen pro Rechnung und Beleg eindeutig gekennzeichnet sind.
Die selbstlernende Software macht dann aus diesem Datensatz ihre Magie, um Muster in ihm zu erkennen. Schließlich entstand daraus ein sogenanntes Modell. Jedes Mal, wenn ein Dokument zur Bearbeitung bei Klippa eintrifft, wird das Dokument mit unserem Modell verglichen.
Auf der Grundlage einer statistischen Analyse untersuchen wir, wie die Struktur des Dokuments aussieht. Sobald dies klar ist, gibt die Software die Position der Rechnungsposten an. Dies kann als eine Art Highlight mit einem Marker angesehen werden, wie man es bei einer Zusammenfassung tun würde.
Sobald Sie die Markierungen im Bereich der Rechnungspositionen angebracht haben, wird ein weiteres Computerprogramm in Betrieb genommen. Wir nennen das einen Parser. Dieser Parser betrachtet alle Informationen im markierten Bereich und weist jeder Information eine Bedeutung zu.
So werden beispielsweise die Beschreibung, die Beträge, die Nummern und die Mehrwertsteuerwerte auf der Rechnung getrennt gehalten und in der Datenbank für jede Rechnungsposition separat gespeichert. Diese Informationen werden zusammen mit den Kopfinformationen schließlich verwendet, um den Buchungsvorschlag auf Positionsebene zu berücksichtigen.
Wie sieht die OCR von Rechnungspositionen aus?
Es ist manchmal schwierig, eine gute Visualisierung der Bedienung eines Computerprogramms zu erstellen. Schließlich erledigt die Software die meiste Arbeit im Hintergrund, und nur die Ausgabe wird in einer Benutzeroberfläche visualisiert. Um Ihnen einen Eindruck von der Funktionsweise der OCR Software zu vermitteln, können Sie sich die folgende Visualisierung ansehen.
Hier sehen Sie, wie die Software neben den Kennzahlen auch eine Green Box auf eine Rechnung gesetzt hat. Hier befinden sich die Rechnungszeilen. Anschließend werden schwarze Blöcke um die relevanten Einzelwerte gezeichnet und diese durch schwarze Linien miteinander verbunden. Auf diese Weise werden die Daten ohne Verwendung von Vorlagen extrahiert und miteinander verknüpft.
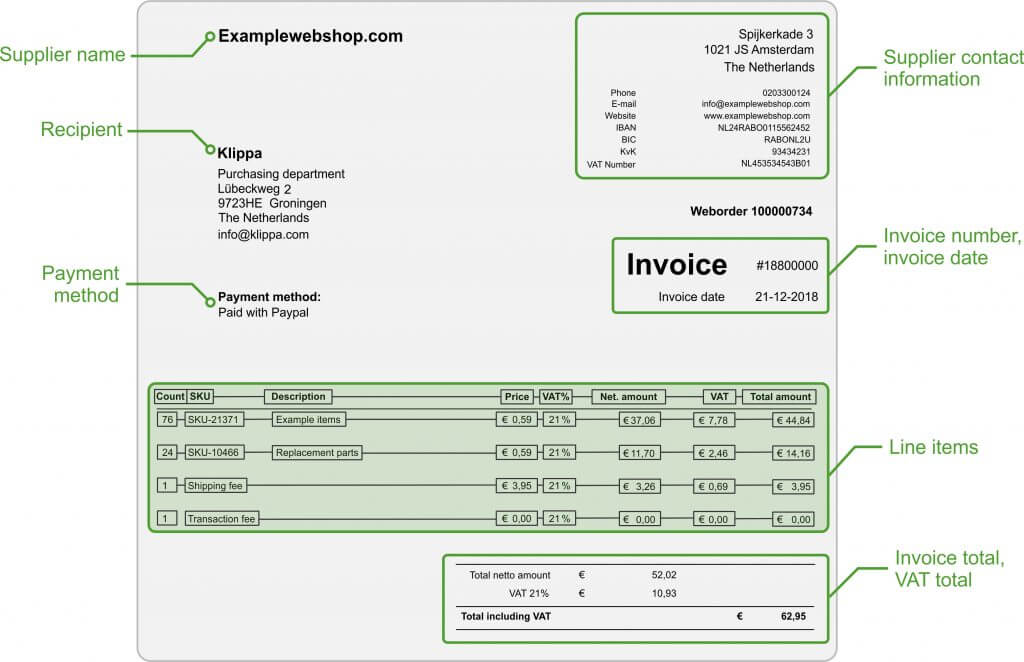
Für welche Sprachen funktioniert es?
Gute Frage! Zum Glück ist die Antwort auch entsprechend gut. Unsere Software kann mit so ziemlich jeder Sprache arbeiten. Es eignet sich am besten für europäische Sprachen wie Niederländisch, Deutsch, Französisch, Italienisch, Spanisch, Englisch und mehr. Unsere Software kann auch trainiert werden, um eine bessere Leistung in bestimmten Sprachen zu erzielen, wenn die Out-of-the-box-Ergebnisse nicht wie gewünscht sind.
Let’s talk!
Bei Klippa implementieren wir unsere intelligenten OCR-Lösungen in unserer eigenen Software, zum Beispiel bei der Rechnungsverarbeitung. Wir bieten unsere Software jedoch auch für Fremdsoftwares an. Zu diesem Zweck stehen uns benutzerfreundliche APIs zur Verfügung. Haben Sie ein Problem mit dem Scannen und Erkennen von Rechnungspositionen? Bitte lassen Sie es uns per Anruf oder E-mail wissen. Wir helfen Ihnen gerne bei der Lösung!