Im Jahr 2022 wurden jeden Tag unglaubliche 3,5 Quintillionen Bytes an Daten erstellt. Ziemlich beeindruckend, oder? Diese Daten sind für das Wachstum von Unternehmen unerlässlich, da sie das Leben der Menschen erleichtern, Probleme in Unternehmen lösen und Innovationen vorantreiben.
Es gibt jedoch ein Problem: Die meisten Daten liegen in unstrukturierten Formaten wie gescannten Dokumenten oder handgeschriebenen Papieren vor. Das macht es für Unternehmen so gut wie unmöglich, Daten effektiv zu nutzen.
Die Herausforderung besteht darin, dass Unternehmen diese Rohdaten benötigen und sie in andere Formate umwandeln müssen, um sie von einer Software an eine andere weiterzugeben. Zu diesem Zweck müssen sie eine Lösung finden, die die Daten für alle Arten von Unternehmen zugänglich macht. An dieser Stelle kommt das Data Parsing ins Spiel.
Zum jetzigen Zeitpunkt mag Ihnen Data Parsing wie ein abstraktes Konzept vorkommen. Aus diesem Grund werden wir im nächsten Abschnitt erklären, was Data Parsing ist, die verschiedenen Arten von Data Parsing vorstellen und erläutern, warum Data Parsing so wichtig ist.
Kurzübersicht
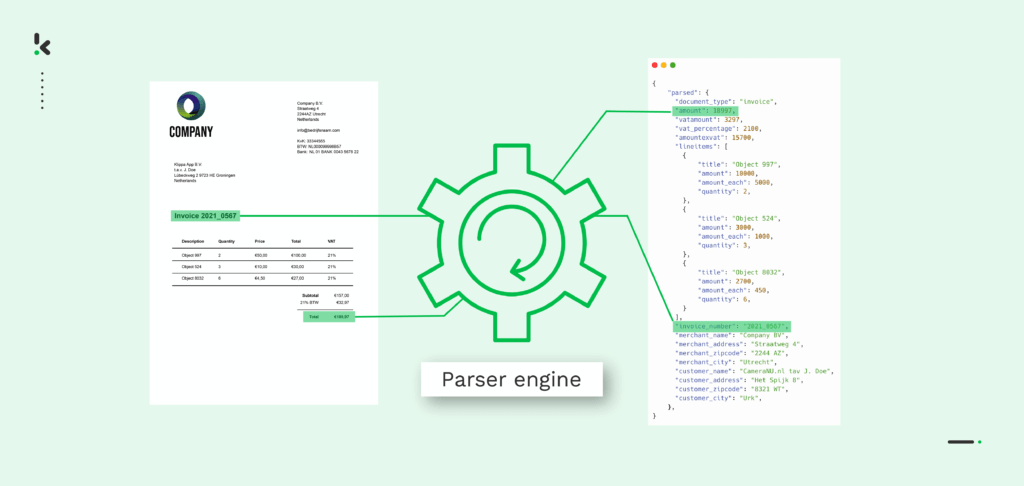
Was ist Data Parsing? Die automatische Umwandlung unstrukturierter Daten in ein strukturiertes, maschinenlesbares Format.
Wie funktioniert es? Daten werden analysiert, extrahiert und in ein standardisiertes Format wie JSON, XML oder CSV überführt.
Welche Vorteile bietet es? Spart Zeit, reduziert manuelle Fehler und erleichtert die Datenverarbeitung.
Wo wird es eingesetzt? Ideal für Rechnungen, Verträge, Formulare, Web-Scraping und viele weitere Anwendungsfälle.
Mit Klippa DocHorizon: Eine leistungsstarke Lösung für effizientes und präzises Data Parsing.
Was ist Data Parsing?
Einfach gesagt: Das Parsen von Daten ist der Prozess der Konvertierung von Daten von einem Format in ein anderes. Nehmen wir zum Beispiel an, Sie haben eine PDF-Datei, die Sie als JSON-Datei benötigen. In diesem Fall benötigen Sie einen Datenparser, der PDF-Rohdaten in ein maschinenlesbares Format umwandeln kann.

Im Allgemeinen wird das Parsen von Daten als nächster Schritt angewendet, nachdem Daten aus einem Dokument extrahiert wurden. Meistens liegen die extrahierten Daten in einem Format vor und müssen in ein anderes Format konvertiert werden, damit sie in Ihrer Datenbank gespeichert oder an Software von Drittanbietern weitergegeben werden können.
Die Konvertierung eines Dateiformats in ein anderes ist mithilfe eines Teilbereichs der KI möglich, der als Natural Language Processing (NLP) bezeichnet wird und bei dem eine Reihe von Symbolen, Sonderzeichen und Datenstrukturen analysiert wird. Auf der Grundlage von benutzerdefinierten Regeln werden die Informationen zunächst strukturiert und dann organisiert, wodurch die extrahierten Daten eine Bedeutung erhalten.
Dabei ist zu beachten, dass je nach den kontextuellen Strukturen der extrahierten Daten unterschiedliche Ansätze für das Parsen von Daten angewandt werden können. Schauen wir uns einmal an, wie diese verschiedenen Ansätze funktionieren.
Verschiedene Arten des Data Parsing
Beim Parsen von Daten werden im Allgemeinen zwei verschiedene Ansätze verfolgt: Grammatikgesteuertes Data Parsing und datengesteuertes Data Parsing.
Grammatikgesteuertes Parsen von Daten
Wie der Name schon sagt, basiert das grammatikgesteuerte Parsen von Daten auf einer Reihe von formalen Grammatikregeln. Dabei werden Sätze aus unstrukturierten Daten fragmentiert und anschließend in ein strukturiertes und leicht verständliches Format umgewandelt.
Dieser Ansatz hat jedoch ein Problem: Es fehlt ihm an Robustheit. Um dieses Problem zu überwinden, werden häufig grammatikalische Beschränkungen gelockert. Das bedeutet, dass Sätze, die nicht in den Anwendungsbereich der üblichen Grammatik fallen, von der Analyse des Data Parsing ausgeschlossen werden können.
Da das grammatikgestützte Parsing von Daten seine Grenzen und Ungereimtheiten hat, wurde ein zusätzlicher Weg des Data Parsing gefunden. Hier kommt das datengesteuerte Data Parsing ins Spiel.
Datengesteuertes Parsen von Daten
Im Allgemeinen werden beim datengesteuerten Parsing intelligente statistische Parser und moderne sogenannte Treebanks verwendet, um möglichst viele Sprachen abzudecken. Auf diese Weise können Sie Konversationssprachen und Sätze parsen, die hohe Präzision erfordern, auch wenn sie nicht gekennzeichnet und bereichsspezifisch sind.
Hinweis: Treebanks verbessern NLP-Modelle, sodass eine KI-Software in der Lage ist, geschriebenen Text zu verstehen. Der statistische Parser kann das NLP-Modell nutzen, um die verschiedenen möglichen Bedeutungen innerhalb eines Satzes zu verstehen, und gibt die wahrscheinlichste zurück.
Bei der datengesteuerten Datenanalyse können zwei Ansätze verfolgt werden:
- Regelbasierter Ansatz
- Lernbasierter Ansatz
Regelbasierter Ansatz
Der regelbasierte Ansatz ist für strukturierte Dokumente wie Steuerrechnungen oder Bestellungen geeignet. Die definierten Regeln helfen dem Benutzer, eine Vorlage zu bestimmen, die als Referenz für den Parser verwendet wird, um Daten aus einem Dokument zu extrahieren.
Der größte Nachteil dabei ist die strikte Abhängigkeit von vordefinierten Vorlagen, was bedeutet, dass selbst ein geringfügig abweichendes Dokumentenformat zu einem Fehler beim Parsen der Daten führt. Wie könnte man also Daten flexibler parsen?
Lernbasierter Ansatz
Die Antwort lautet: ein lernbasierter Ansatz für das Parsen von Daten. Dieser Ansatz stützt sich stark auf Machine Learning (ML) und Natural Language Processing (NLP) und wird im Allgemeinen zur Extraktion von Daten aus jeder Art von Dokument verwendet.
Da das Modell mit einer Vielzahl von unstrukturierten Dokumenten trainiert wurde, wird die Fähigkeit, wichtige Felder zu erkennen und Daten aus ihnen zu extrahieren, verbessert.
In der Praxis wird jedoch eine Kombination aus beiden Ansätzen, dem regelbasierten und dem lernbasierten, für das Parsen von Daten verwendet. Diese Kombination ermöglicht es Ihnen, jedes Dokument mit jeder Art von Layout zu verarbeiten, und beschränkt Sie nicht auf ein bestimmtes Layout.
Schauen wir uns also an, wie das Parsen von Daten in verschiedenen Branchen eingesetzt wird.
Anwendungsfälle von Data Parsing
Data Parsing wird in verschiedenen Branchen eingesetzt, um Daten, die in unbrauchbaren Formaten vorliegen, in geschäftsrelevante Daten umzuwandeln. Aus Gründen der Lesbarkeit werden wir uns auf vier Branchen konzentrieren, diese Liste ist jedoch bei weitem nicht vollständig:
- Finanzindustrie
- Gesundheitswesen
- Recht
- Transport und Logistik
Finanzindustrie
Banken und andere Finanzinstitute haben es mit Millionen von Kundendokumenten zu tun, z. B. Ausweisen, Kontoauszügen und Anträgen für das Onboarding. All diese Dokumente müssen analysiert und die relevanten Informationen in der Datenbank der Bank gespeichert werden.
Ebenso hat jedes Unternehmen mit Rechnungen und Belegen zu tun, die oft manuell bearbeitet und in verschiedenen Formaten (PNG, PDF usw.) gespeichert werden. Das macht es sehr schwierig, die Daten zu durchsuchen und effizient mit ihnen zu arbeiten.
Zur Verbesserung der Finanzprozesse kann ein Datenparser in folgenden Fällen eingesetzt werden:
- Automatisierte Dateneingabe
- Kundenonboarding
- Prüfung der Vollständigkeit von Dokumenten
- KYC-Automatisierung
- Automatisierte Rechnungsverarbeitung
- Konvertierung von PDF in Excel
- Extrahieren von Daten aus PDF

Machen Sie sich keine Sorgen, wenn Ihr Fall hier nicht aufgeführt ist. Es gibt viele weitere Anwendungsfälle für die Finanzbranche.
Gesundheitswesen
Das Gesundheitswesen sieht sich häufig mit einem Mangel an Ressourcen, langen Arbeitszeiten und enormen Verwaltungsaufgaben konfrontiert. Dies kann schnell zu Fehlern bei Patientenakten, Folgebehandlungen und Rezepten führen, was schwere Schäden oder sogar den Tod des Patienten zur Folge hat.
In der Gesundheitsbranche könnte ein Datenparser in folgenden Fällen nützlich sein:
- Automatisiertes Onboarding von Patienten
- Datenextraktion aus Patientenakten
- Scannen von Krankenversicherungskarten

Rechtsbranche
Anwälte sind teuer, und Kanzleien wollen, dass sie ihre Zeit nutzen, um Fälle zu lösen, anstatt endlose Mengen von Dokumenten zu sortieren. Da Anwälte jedoch alle Arten von Dokumenten von Kunden in verschiedenen Formaten erhalten, verbringen sie viel Zeit damit, diese zu sortieren. Das macht sie sehr ineffizient und langsam.
Außerdem betreuen Anwälte mehrere Mandanten gleichzeitig. Daher ist es wichtig, dass alle Dokumente ordnungsgemäß organisiert und geordnet sind. Andernfalls ist es fast unmöglich, den Überblick über die verschiedenen Fälle zu behalten.
Hinzu kommt, dass die meisten Kundendokumente sensible Informationen enthalten, die vor Datenschutzverletzungen und Betrug geschützt werden müssen.
In der Rechtsbranche kann das Parsing von Daten auf folgende Weise nützlich sein:
- Datenerfassung und -organisation
- Klassifizierung von Dokumenten
- Automatisierte Datenextraktion
- Anonymisierung von Informationen

Transport und Logistik
Jedes Unternehmen, das Produkte oder Dienstleistungen online verkauft, muss eine große Menge an Versand- und Rechnungsdaten verarbeiten. Daher müssen Versandetiketten, Lieferscheine, Liefernachweise usw. verwaltet werden.

Hier kann ein Datenparser in Fällen wie dem folgenden eingesetzt werden:
- Automatisierte Dateneingabe
- Compliance Checks
- Automatisierte Rechnungsverarbeitung
- Erkennung von Dokumentenbetrug
- Verwaltung von Paketen
Wenn man sich diese verschiedenen Anwendungsfälle ansieht, wird deutlich, dass das Parsen von Daten für mehrere Branchen von Vorteil ist. Durch die Automatisierung der Datenanalyse kann der Prozess verbessert und noch effizienter gestaltet werden. Werfen wir einen Blick darauf, wie das Parsen von Daten automatisiert werden kann.
Wie automatisiert man das Data Parsing?
Heutzutage sind Sie höchstwahrscheinlich gezwungen, Zeit, Arbeitsaufwand und Kosten für Ihr Unternehmen zu reduzieren, wo immer Sie können. Um dies zu erreichen, scheint die Automatisierung die einzige Lösung zu sein. Wie in den vorgestellten Anwendungsfällen zu sehen ist, bringt das Parsen von Daten selbst bereits große Vorteile mit sich, z. B. die Optimierung von Geschäftsabläufen. Um das Parsen von Daten zu verbessern, können wir den Prozess jedoch automatisieren.
Werfen wir einen Blick auf die verschiedenen Möglichkeiten, das Parsen von Daten zu automatisieren:
- Klassische OCR-Software
- Web-Anwendungen
- Roboter & RPA
Klassische OCR-Software
Die klassische OCR-Software ist eine recht einfache Lösung zur Automatisierung von Prozessen. Sie verfügt über alle grundlegenden Funktionen und Anweisungen, um die Arbeit zu erledigen. Aber ihre Funktionen sind begrenzt.
Daher ist eine klassische OCR-Software für kleinere Dateien und zur Konvertierung einer einfachen PDF-Datei in JSON geeignet. Aufgaben wie das Parsen von Tabellen oder das Einlesen von Bildern können jedoch nicht durchgeführt werden, da sie leistungsfähigere Bibliotheken erfordern, die mehr Rechenleistung und Daten verbrauchen.
Web-Anwendungen
Webanwendungen werden häufig für Benutzeroberflächen (UI) verwendet, um den Datenparsingprozess zu automatisieren. Um bestimmte Dateitypen zu bearbeiten, wird eine bestimmte Backend-Sprache wie Python oder Java gewählt. Die gesamte Kommunikation zwischen der Benutzeroberfläche, dem Backend und anderen Datenbanken erfolgt hauptsächlich über die Datenbank.
Wenn die Website auf einer leistungsstarken Cloud-Lösung betrieben wird, kann OCR integriert werden, um Datenparsing-Verfahren durchzuführen. Diese Lösung kann jedoch zeitaufwändig sein, da sie viele Schritte und Anfragen im gesamten Web durchführt.
Roboter und RPA
Robotic Process Automation (RPA) ist eine der neuesten Entwicklungen, die Automatisierung ermöglichen. Anstelle von Menschen, die manuelle Aufgaben ausführen, übernehmen Roboter die Automatisierung dieser Aufgaben. Sie sind mit intelligenten Algorithmen ausgestattet, die sie in die Lage versetzen, bei jeder Iteration zu lernen und Fehler zu minimieren.
Einer der Hauptvorteile besteht darin, dass diese Roboter mit verschiedenen Datenquellen, APIs und anderen Integrationen von Drittanbietern verbunden werden können, was es Ihnen ermöglicht, Daten unterschiedlich zu analysieren.
Nachdem wir nun darüber gesprochen haben, wie das Parsen von Daten automatisiert werden kann, lassen Sie uns einen Blick auf die Vorteile des Parsens von Daten werfen.
Die Vorteile des Data Parsing
Neben dem wichtigsten Vorteil des Data Parsing, nämlich der Möglichkeit, durch eine riesige Datenmenge zu navigieren, gibt es noch weitere Vorteile:
- Zeitersparnis → Data Parser helfen Unternehmen, Daten in ein anderes Format zu konvertieren und den Prozess zu automatisieren, der sonst manuell durchgeführt werden müsste. Das Ergebnis ist, dass die Geschäftsabläufe schneller abgewickelt werden und Mitarbeiter für wertvollere Aufgaben eingesetzt werden können.
- Bessere Zugänglichkeit der Daten → Data Parsing macht Daten leichter zugänglich und erhöht die Durchsuchbarkeit. Geschäftsleute können auf alle erforderlichen Informationen aus der riesigen Datenmenge zugreifen, die ihnen zur Verfügung steht.
- Daten modernisieren → Es kann vorkommen, dass die gespeicherten Daten von Unternehmen Jahre alt sind und daher nicht in modernen Formaten vorliegen. Diese Daten können aber immer noch wertvolle Informationen enthalten, die für das Unternehmen wichtig sind. Mit Data Parsing kann das Format dieser Daten schnell geändert werden, sodass die Unternehmen die Informationen effektiv nutzen können.
Nachdem Sie erfahren haben, was Data Parsing ist, in welchen Fällen es eingesetzt wird und welche Vorteile es bringen kann, fragen Sie sich vielleicht, wie Sie Zugang zu einem Data Parser bekommen. Eine Möglichkeit wäre, einen eigenen Parser zu bauen. Aber ist das wirklich eine gute Idee?
Einen eigenen Parser bauen, oder nicht?
Um diese Frage zu beantworten, werden wir Ihnen die Vor- und Nachteile der Erstellung eines eigenen Parsers erläutern. Danach sollten Sie in der Lage sein, eine fundierte Entscheidung zu treffen.
Vorteile der Erstellung eines eigenen Parsers
- Mehr Kontrolle → Sie haben mehr Kontrolle und können entscheiden, wie Sie Ihren Datenparser aktualisieren oder pflegen. Wenn Sie mit sehr sensiblen Daten zu tun haben, möchten Sie Ihre Informationen vielleicht nicht mit Datenparsern von Dritten teilen.
- Anpassbar an Ihre Bedürfnisse → Wenn Sie Ihren eigenen Parser erstellen, wird er speziell auf Ihr Unternehmen zugeschnitten. Auf diese Weise hilft er den internen Teams, die spezifischen Parsing-Anforderungen Ihres Unternehmens zu erfüllen.
Nachteile der Erstellung eines eigenen Parsers
Um einen eigenen Parser zu erstellen, benötigen Sie ein Team von Entwicklern, die in der Lage sind, Parsing-Anwendungen zu verstehen und zu schreiben. Entwickler mit diesen Fähigkeiten zu finden, kann eine ziemliche Herausforderung sein. Aber das ist nicht die einzige Schwierigkeit. Schauen wir uns an, welche anderen Nachteile die Entwicklung eines eigenen Parsers mit sich bringt:
- Teuer → Die Entwicklung eines eigenen Parsers ist teuer, da viel Zeit und Ressourcen benötigt werden. Darüber hinaus müssen Sie ein ganzes internes Team einstellen und schulen, um Ihren eigenen Parser zu entwickeln.
- Mitarbeiterschulung → Sie müssen Ihr gesamtes Personal im Umgang mit der Datenparsertechnologie schulen.
- Wartung → Ein Datenparser erfordert regelmäßige Wartung, was bedeutet, dass Sie mehr Zeit und Geld aufwenden müssen.
- Infrastruktur → Der Aufbau eines Datenparsers erfordert viel Planung und einen eigenen Server. Das bedeutet, dass Sie möglicherweise einen leistungsstarken Server bauen oder kaufen müssen, der schnell genug ist, um Informationen zu analysieren.
Für die meisten Organisationen überwiegen die Nachteile die Vorteile, einfach, weil es teuer und extrem schwierig ist, erfahrene Leute für die Erstellung eines Parsers zu finden. Wenn das jedoch der Fall ist, gibt es keinen Grund zu verzweifeln.
Wir haben eine weitere Option für Sie. Sie können Ihr Unternehmen mit einem Datenparser ausstatten, der in Tausenden von Entwicklerstunden von einem anderen Unternehmen bereits erstellt wurde.
Data Parsing mit Klippa – Strukturierte Daten aus jeder Quelle extrahieren
In Unternehmen fallen täglich zahlreiche Dokumente an – Rechnungen, Verträge, Formulare oder Quittungen. Oft liegen diese in unstrukturierten Formaten vor, was die Datenverarbeitung erschwert.
Mit Klippa DocHorizon, unserer KI-gestützten OCR-Software, können Sie Daten aus jeglicher Art von Dokumenten präzise extrahieren und in verwertbare Formate umwandeln. Unsere intelligente Parsing-Technologie erkennt und strukturiert relevante Informationen, unabhängig vom Dateiformat oder Layout.
- Automatisierte Extraktion: Wandeln Sie unstrukturierte Dokumente in durchsuchbare und analysierbare Daten um.
- Flexible Integration: Exportieren Sie die extrahierten Informationen direkt in Ihre ERP-, CRM- oder Buchhaltungssysteme.
- Höchste Genauigkeit: Dank Machine Learning und Optical Character Recognition (OCR) werden selbst komplexe Dokumente fehlerfrei erfasst.
Egal ob Sie Rechnungsdaten für die Buchhaltung benötigen oder Kundeninformationen aus Formularen extrahieren möchten – Klippa bietet Ihnen eine effiziente, automatisierte Lösung für Ihr Datenmanagement. Machen Sie Schluss mit manueller Dateneingabe! Kontaktieren Sie uns und erfahren Sie, wie Sie Ihre Dokumentenverarbeitung mit Klippa optimieren können.
FAQ – Data Parsing
Data Parsing ist der Prozess der Umwandlung von unstrukturierten oder halbstrukturierten Daten in ein strukturiertes, maschinenlesbares Format.
Es automatisiert die Verarbeitung großer Datenmengen, reduziert manuelle Fehler und verbessert die Effizienz von Geschäftsprozessen.
Data Parsing funktioniert mit Textdateien, PDFs, Tabellen, JSON, XML, CSV und gescannten Dokumenten.
OCR (Optical Character Recognition) erkennt und extrahiert Text aus Bildern oder Dokumenten. Data Parsing strukturiert diese Daten für die weitere Verarbeitung.
Ja, moderne Parsing-Lösungen wie Klippa DocHorizon lassen sich nahtlos in ERP-, CRM- oder Buchhaltungssysteme integrieren.
Klippa bietet eine KI-gestützte Lösung zur automatisierten Datenextraktion, die sich flexibel an verschiedene Dokumentenformate anpasst und Prozesse optimiert.