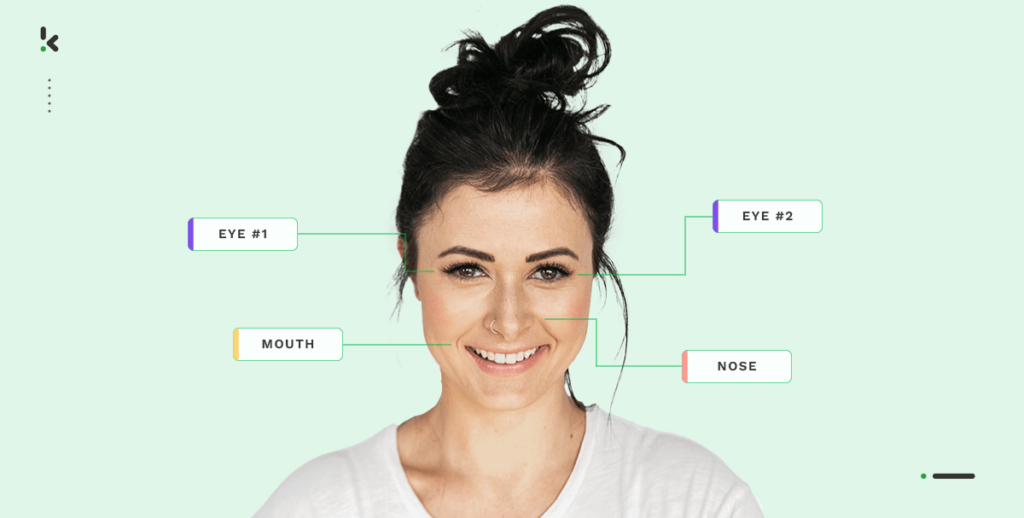
Künstliche Intelligenz (KI) und Machine Learning (ML) sind schnell wachsende Technologien, mit denen wir unglaubliche Dinge erfinden können. Denken Sie an ein selbstfahrendes Auto oder die Entsperrfunktion Ihres Smartphones mit Gesichtserkennung. Haben Sie jemals darüber nachgedacht, wie das eigentlich funktioniert?
Damit eine Maschine die Entscheidung treffen kann, nicht in den nächsten Baum zu fahren, muss sie darauf trainiert werden, bestimmte Informationen zu verstehen. Um solche automatischen Maschinen und Anwendungen zu entwickeln, ist eine enorme Menge an Trainingsdaten erforderlich.
Unternehmen können entweder Trainingsdaten kaufen oder ein Expertenteam von sogenannten Datenannotatoren einstellen, das mit Rohdatensätzen arbeiten kann.
Im Allgemeinen ist die Annotation von Daten ein komplexer und teurer Prozess, der von Experten durchgeführt werden sollte, um ein zufriedenstellendes Ergebnis zu erreichen.
Viele Unternehmen, die sich mit künstlicher Intelligenz beschäftigen, tun sich schwer mit der Datenannotation und wissen nicht, wo sie anfangen sollen. Daher werden wir in diesem Blog erklären, was die Datenannotation ist, welche Methoden für die Datenannotation zur Verfügung stehen und warum Datenannotation heutzutage so notwendig ist.
Was ist Datenannotation?
Kurz gesagt: Datenannotation ist der Prozess der Kennzeichnung von Daten, die in einem Video, Bild oder Text vorhanden sind. Die Daten werden beschriftet, sodass Modelle eine gegebene Datenquelle leicht verstehen und bestimmte Formate, Objekte, Informationen oder Muster in Zukunft erkennen können.
Damit das Modell die dargestellten Bilder, Videos und andere Formate versteht und ihnen einen Sinn gibt, verwendet es ‚Computer Vision‘. Computer Vision ist ein Teilbereich der Künstlichen Intelligenz (KI), der es Software und Computern ermöglicht, digitale visuelle Eingaben zu erkennen und zu interpretieren. Aber was hat das mit der Datenannotation zu tun?
Um Computer Vision beizubringen, Objekte, Muster oder andere Informationen zu erkennen, müssen die Daten präzise annotiert oder, um es technisch auszudrücken, mit einem etablierten Machine Learning Modell versehen werden. Dies wird durch den Einsatz geeigneter Methoden und Werkzeuge erreicht.
Unabhängig davon, ob die Datenannotation manuell oder automatisch erfolgt, besteht das Verfahren im Allgemeinen aus zwei Schritten:
- Kennzeichnung der Daten
- Qualitätskontrollen und Audits
Der erste Schritt der Datenannotation ist die Kennzeichnung von Bild-, Video- oder Textdaten. In diesem Zusammenhang bedeutet Datenkennzeichnung das Hinzufügen einer oder mehrerer informativer Beschriftungen zu Rohdaten (Bilder, Text, Video usw.), um einen Kontext zu schaffen, sodass ein Machine Learning Modell daraus lernen kann.
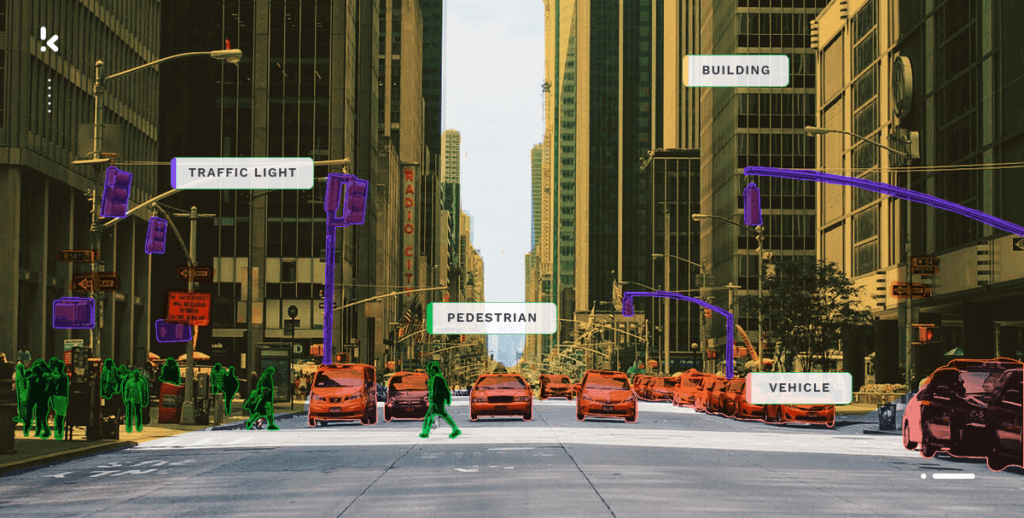
Wie in der Abbildung unten, werden Ampeln, Fußgänger, Fahrzeuge und Gebäude beschriftet, um dem Modell beizubringen, was sie sind.
Der zweite Schritt beginnt, nachdem die Daten beschriftet worden sind. Hier wird der beschriftete Datensatz auf seine Authentizität und Genauigkeit überprüft. Dieser Schritt ist sehr wichtig. Andernfalls wird das erstellte Modell mit falschen Daten trainiert, was zu kostspieligen Nachschulungsmaßnahmen führen kann.
Nachdem wir nun eine allgemeine Vorstellung von Datenanannotationen haben, wollen wir uns die verschiedenen Arten von Annotationen genauer ansehen.
Arten von Datenanotationen
Wie bereits erwähnt, kann der Prozess der Datenannotation auf verschiedene Arten von Layouts angewendet werden. Das bedeutet, dass verschiedene Arten von Datenanotationsmethoden verwendet werden. Aus Gründen der Lesbarkeit des Blogs werden wir uns auf drei der verschiedenen Methoden der Datenannotation konzentrieren. Beachten Sie, dass diese Liste nicht allumfassend ist:
- Bild-Annotation
- Video-Annotation
- Text-Annotation
Bild-Annotation
Für eine Vielzahl von Anwendungen wie Computer Vision, Robotik-Vision, Gesichtserkennung und Lösungen, die sich auf KI stützen, ermöglicht die Bildannotation die Interpretation von Bildern. Bevor dies jedoch anwendbar ist, muss das KI-Modell mit Tausenden von gekennzeichneten Bildern trainiert werden.
Das Training kann durch die Zuweisung von Metadaten wie Identifikatoren, Beschriftungen und Schlüsselwörtern zu Hunderten von Bildern durchgeführt werden. Mit effektivem Training erhöht sich die Genauigkeit des KI-Modells und Sie können es für zahlreiche Zwecke einsetzen (z. B. für selbstfahrende Fahrzeuge oder die automatische Erkennung von Krankheiten).
Für die Bildannotation selbst gibt es wiederum verschiedene Arten von Methoden für die Annotation, wie z. B.:
- Bounding boxes → Zeichnen Sie ein Rechteck um das Objekt, das Sie in einem bestimmten Bild annotieren möchten. Die Kanten der Bounding boxes sollten die äußersten Pixel des beschrifteten Bildes berühren, um die größtmögliche Genauigkeit zu gewährleisten.

- 3D-Cuboids → Diese Methode ist der Annotation von Bounding boxes sehr ähnlich. Der einzige Unterschied besteht darin, dass der Benutzer den Tiefenfaktor berücksichtigen muss. Es kann verwendet werden, um Ebenen oder Autos auf einem Bild zu beschriften.

- Polygone → Bei der Verwendung von Bounding boxes oder 3D-Cuboids können verschiedene Objekte unbeabsichtigt in den beschrifteten Bereich eingeschlossen werden. Mit dem Polygone-Tool kann eine Linie um das spezifische Objekt im Bild gezogen werden, das annotiert werden soll.

- Keypoint-Tool → Ein Objekt kann durch eine Reihe von Punkten annotiert werden. Dies wird häufig zur Gestenerkennung oder Bewegungsverfolgung verwendet.
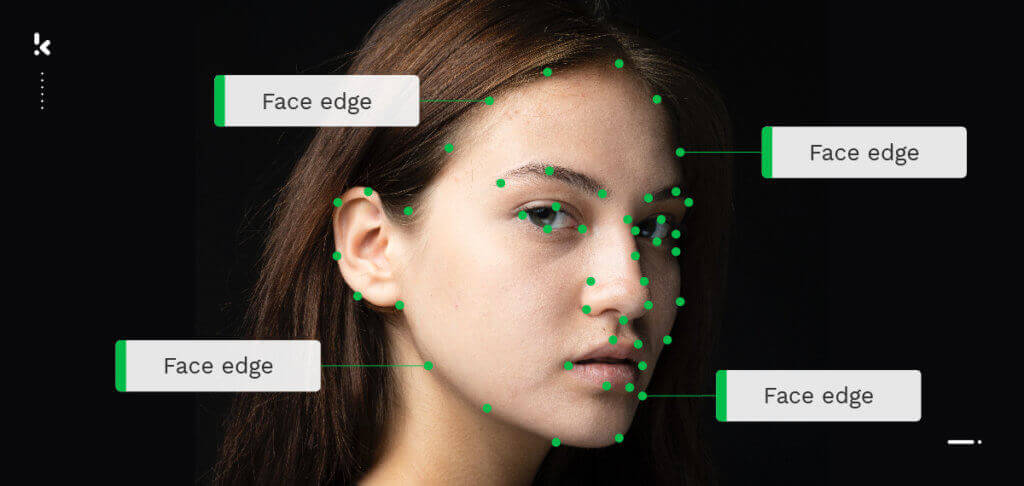
Werfen wir nun einen Blick auf die Videoannotation.
Video-Annotation
Die Videoannotation wird Bild für Bild durchgeführt, um die annotierten Objekte für Machine Learning Modelle erkennbar zu machen. Im Allgemeinen werden dabei die gleichen Techniken wie bei der Bildannotation (z. B. Bounding Boxes) verwendet, um die gewünschten Objekte zu erkennen oder zu identifizieren.
Diese Annotationsmethode ist eine wesentliche Technik für Computer-Vision-Aufgaben wie Lokalisierung und Objektverfolgung, bei der ein Algorithmus die Bewegung eines Objekts verfolgen kann. Daher ist die Videobeschriftung für verschiedene Branchen wie den medizinischen Sektor, die Fertigung und das Verkehrsmanagement hilfreich.
Als letzte Art der Datenannotation wollen wir über Textannotation sprechen. Text ist die am häufigsten verwendete Datenkategorie, da die meisten Unternehmen in verschiedenen Geschäftsprozessen stark auf Text angewiesen sind.
Text-Annotation
Unter Textannotation versteht man das Hinzufügen von Metadaten oder Labels zu Textstücken. Schauen wir uns einmal genauer an, was das bedeutet.
Hinzufügen von Metadaten
Das Hinzufügen von Metadaten bedeutet, dass dem Lernalgorithmus relevante Informationen zur Verfügung gestellt werden. Auf diese Weise kann er Prioritäten setzen und sich auf bestimmte Wörter konzentrieren.
Beispiel: „Hier ist die Rechnung (Dokumententyp) für den neuen Computer (Bestellung), den Sie gestern (Uhrzeit) bestellt haben.“
Die in den Klammern hinzugefügten Metadaten liefern dem Lernalgorithmus die relevanten Informationen, damit er in Zukunft die Informationen erkennen kann, für die er trainiert wurde.
Zuweisung von Etiketten
Durch das hinzufügen von Etiketten kann in einem Satz Wörter zugeordnet werden, die seine Art beschreiben. Ein Satz kann z. B. mit Gefühlen oder Fachlichkeit beschrieben werden.
Beispiel: „Das Produkt entspricht nicht meinen Anforderungen, ich möchte es zurückgeben“. Hier könnte das Label „unglücklich“ vergeben werden.

Dies hilft dem Algorithmus, die Stimmungslage und die Absicht eines Textes zu verstehen, und ist eng mit der Erkennung benannter Einheiten verbunden. Schauen wir uns einmal an, warum das so ist.
Name Entity Recognition (NER)
‘Name Entity Recognition’ (NER) bedeutet im deutschen ‘Die Erkennung benannter Entitäten’ welches zu der Suche nach Wörtern auf der Grundlage ihrer Bedeutung dient. Sie zielt darauf ab, vordefinierte, benannte Entitäten und Ausdrücke in einem Satz zu erkennen. Im Allgemeinen ist NER nützlich bei der Extraktion, Klassifizierung und Kategorisierung von Informationen.
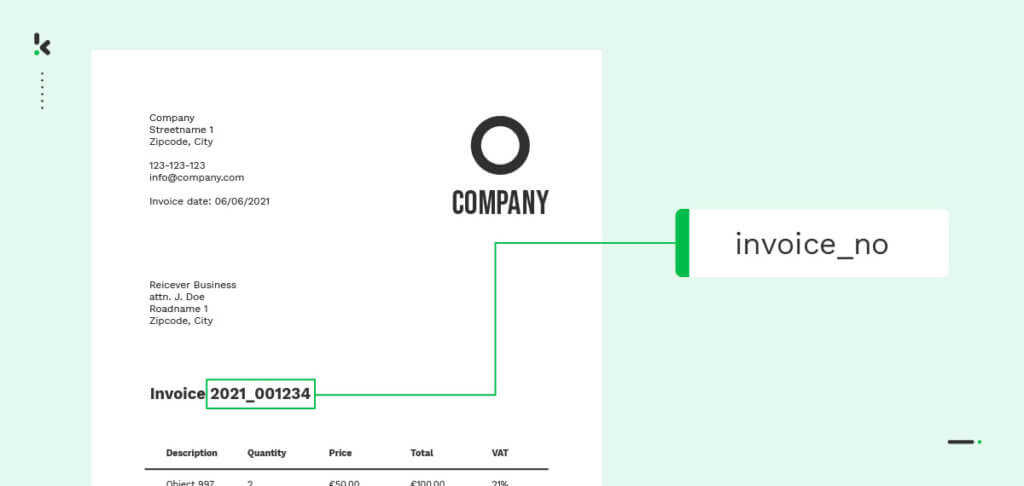
Nehmen wir das Beispiel einer Rechnung. Wenn das Modell auf das Wort „Rechnungsnummer“ und die Merkmale einer Rechnungsnummer (z. B. die Anzahl der Ziffern) trainiert wird, kann es das Dokument als Rechnung klassifizieren.
Das Gleiche gilt auch für verschiedene Wörter in verschiedenen Dokumenten, d. h. Sie können die Methode der ‘Named Entity Recognition’ verwenden, um verschiedene Dokumente anhand von Datenfeldern zu klassifizieren.
Darüber hinaus kann ein KI-Algorithmus speziell darauf trainiert werden, die Stimmung und die Absicht eines Satzes zu verstehen, da dies für das Verständnis des menschlichen Verhaltens sehr wichtig ist. Schauen wir uns an, was das bedeutet.
Sentiment-Annotation
Wie bereits erwähnt, werden bei der Sentiment-Annotation dem Text Labels zugewiesen, die menschliche Emotionen darstellen. Zu diesem Zweck werden Bezeichnungen wie traurig, glücklich, frustriert oder wütend verwendet. Diese können dann für die Stimmungsanalyse verwendet werden, z. B. im Einzelhandel, um die Kundenzufriedenheit zu verstehen.
Absichts-Annotation
‘Intent-Annotation’ bedeutet im Grunde, dass Sätzen, die eine bestimmte Absicht oder ein bestimmtes Bedürfnis ausdrücken, Labels zugewiesen werden. Dies kann z. B. für den Kundenservice sehr hilfreich sein.
Nehmen wir einen Chatbot als Beispiel. Wenn ein Kunde den Satz „Ich habe Probleme beim Bezahlen mit meiner Kreditkarte“ eingibt, kann die Person sofort an das Finanzteam weitergeleitet werden.
Dies ist möglich, weil der Algorithmus mit Hunderten von Sätzen trainiert wurde, die ein ähnliches Bedürfnis ausdrücken.
Wörter wie „Ärger“ drücken eine Emotion (Sentiment) des Kunden aus. Darüber hinaus wurden Wörter wie „Kreditkarte“ zuvor als „Zahlungsmethode“ oder ähnliche Bezeichnungen gekennzeichnet, sodass der Algorithmus den Kunden an die Finanzabteilung weiterleiten konnte.
Bevor wir erklären, warum Sie überhaupt die Datenannotation benötigen, möchten wir den Unterschied zwischen automatisierter und manueller Datenannotation näher beleuchten.
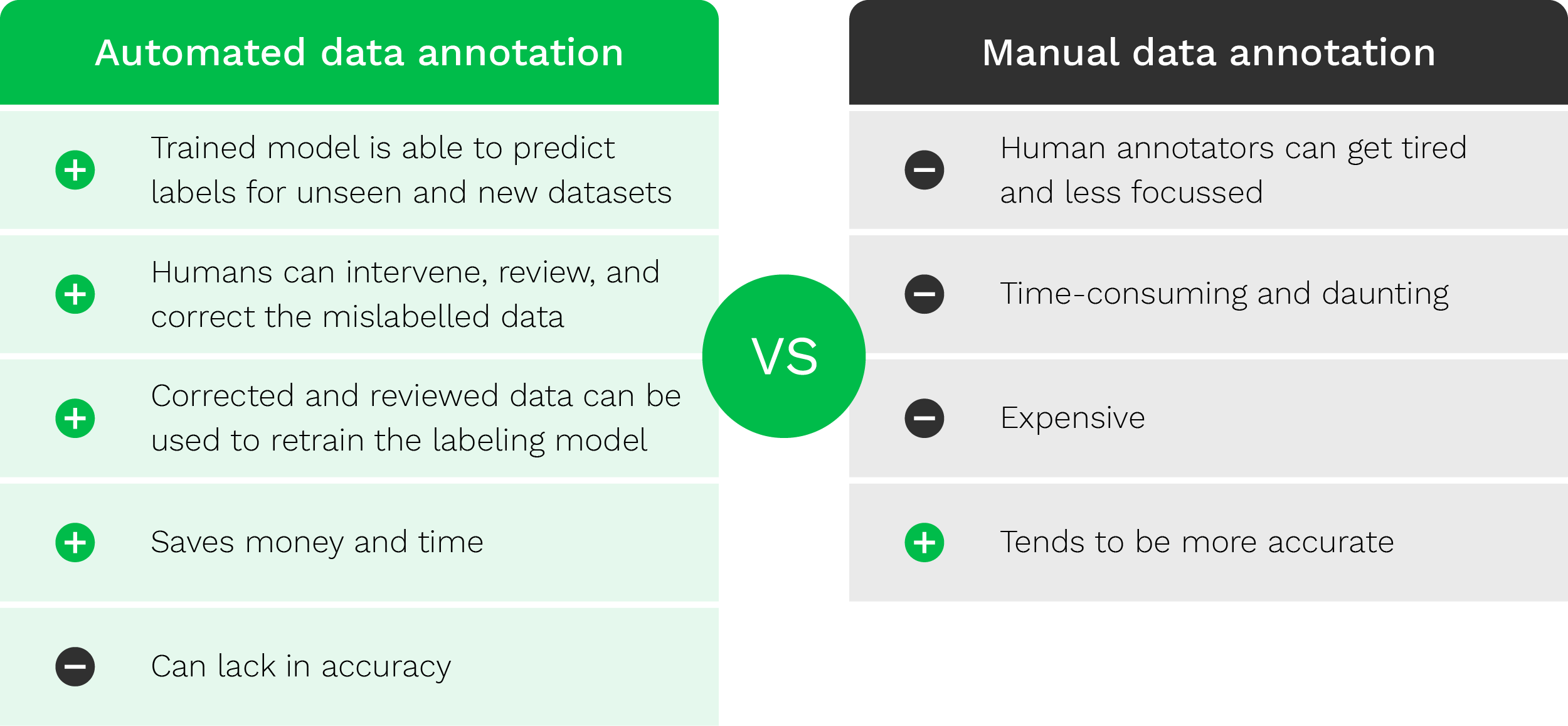
Automatisierte Datenannotation vs. Manuelle Datenannotation
Bei der manuellen Datenannotation ist, wie der Name schon sagt, der Mensch beteiligt und geht folgendermaßen vor:
- Der Datenannotator erhält Rohdatensätze (Videos, Bilder, Text usw.) zur Annotation
- Auf der Grundlage der Spezifikationen und des gewünschten Ergebnisses wissen die Annotatoren, welche Methode (Bounding Box, Keypoint-Tool usw.) sie für die Annotation der relevanten Elemente verwenden müssen
- Der Datenannotierungsexperte beschriftet alle erforderlichen Elemente manuell
- Danach ist der Datensatz bereit für das Training eines Modells
Die Annotation eines Bildes kann bis zu 15 Minuten dauern, je nach Qualität des bereitgestellten Dokuments, das Annotationstool und der Anforderungen. Stellen Sie sich vor, Sie haben ein Projekt mit bis zu 50.000 Bildern. Das bedeutet, dass ein erfahrener Annotator 12.500 Stunden mit der Annotation dieser Bilder verbringt. Es muss einfach einen besseren Weg geben.
Automatisierte Datenannotation
Um den Weg für eine schnellere Datenannotation zu ebnen, gewinnen Modelle zur automatischen Datenannotation zunehmend an Bedeutung. Bei der automatischen Datenannotation übernehmen KI-Systeme den Prozess der Datenannotation.
Dies funktioniert aufgrund von vordefinierten Regeln und Bedingungen, die von Menschen festgelegt werden. Ein Datensatz durchläuft diese vordefinierten Regeln, um eine bestimmte Bezeichnung zu validieren. Dies ist zwar effizienter, aber es gibt immer noch ein Problem. Sobald sich Datenstrukturen häufig ändern, wird es schwierig, Bedingungen und Regeln festzulegen, was es für ein Modell fast unmöglich macht, eine fundierte Entscheidung zu treffen.
Aus diesem Grund wird das Zusammenspiel von menschlicher und künstlicher Intelligenz wahrscheinlich das bestmögliche Ergebnis liefern. Mithilfe eines Human-in-the-loop werden die Ergebnisse des KI-Modells konsequent validiert, verifiziert und optimiert, während das Modell die Datenannotation übernimmt.
Um einen Überblick über den Unterschied zwischen automatischer und manueller Datenannotation zu geben, stellen wir die folgende Tabelle zur Verfügung.
Aber warum sollten Sie sich eigentlich für all das interessieren? Nun, es gibt eine Reihe von Gründen, warum Datenannotationen erforderlich sind. Schauen wir uns das mal an.
Warum Sie Datenannotation brauchen
Unser ständig wachsendes Bedürfnis nach Innovation macht Datenannotation notwendig. Wie sonst könnte ein Auto jemals selbst fahren? Ohne Datenannotation wäre jedes einzelne Bild für Maschinen gleich, da sie kein inhärentes Wissen über irgendetwas in der Welt haben.
Das heißt, ohne das Modell zu trainieren, was ein Fahrzeug, eine Straße, ein Bürgersteig oder ein Fußgänger ist, würde das selbstfahrende Auto einfach bedenkenlos in alles fahren, was seinen Weg kreuzt.
In ähnlicher Weise trainieren viele Unternehmen KI-Modelle zur Identifizierung von Dokumenttypen, um Kategorisierungs- und Datenextraktionsprozesse zu automatisieren. Da viele Unternehmen mit Lieferanten zu tun haben, nehmen wir Rechnungen als Beispiel.
Damit das Modell den Dokumententyp korrekt kategorisieren kann, werden die Merkmale einer Rechnung zunächst gekennzeichnet und dann dem Algorithmus zugeführt.
Dies ist nicht auf Rechnungen beschränkt und kann auf jede Art von Dokument angewendet werden. Für Sie bedeutet das, dass alle Ihre dokumentenbezogenen Arbeitsabläufe optimiert werden können und Ihr Team von der Aufgabe entlastet wird, die Dokumente selbst zu identifizieren und zu kategorisieren.
Werfen wir also einen kurzen Blick auf die wichtigsten Vorteile der Datenannotation.
Die Hauptvorteile der Datenannotation
Neben dem Zeit- und Kostenersparnis hat die Datenannotation noch eine Reihe weiterer Vorteile. Diese Vorteile sind wie folgt:
- Höhere Effizienz → Durch das Labeln von Daten können maschinelle Lernsysteme besser trainiert werden, was sie bei der Erkennung von Objekten, Wörtern, Stimmungen, Absichten usw. effizienter macht.
- Ein höheres Maß an Präzision → Korrekte Datenbeschriftung führt zu genaueren Daten für das Training eines Algorithmus. Dies wird in Zukunft zu einer höheren Genauigkeit bei der Datenextraktion führen.
- Weniger menschliches Eingreifen → Je besser die Datenannotation, desto besser der Output des KI-Modells. Ein präziser Output des Algorithmus bedeutet, dass weniger menschliche Eingriffe erforderlich sind, was Kosten und Zeit spart.
- Skalierbarkeit → Dies gilt für die automatisierte Datenannotation, die es Ihnen ermöglicht, Datenannotationsprojekte zu skalieren, um KI- und ML-Modelle zu verbessern.
Nun, neben den Vorteilen bringt jede Lösung auch ihre Einschränkungen mit sich. Um das Gesamtbild zu verstehen, ist es daher wichtig, diese als Nächstes zu erörtern.
Die Einschränkungen der Datenannotation
Auch wenn Datenannotation für das Training von KI- und ML-Modellen unerlässlich sind, haben sie auch ihre Grenzen. Schauen wir uns an, welche das sind:
- KI- und ML-Modelle benötigen zum Lernen eine riesige Menge an gekennzeichneten Daten. Daher müssen Unternehmen eine hohe Anzahl von Mitarbeitern einstellen, die diese enorme Menge an gekennzeichneten Daten erzeugen können. Das ist nicht nur teuer, sondern schränkt auch die Effizienz und Produktivität dieser Unternehmen ein.
- Oft haben die Unternehmen nur begrenzten Zugang zu geeigneten Tools und Technologien, die einen präzisen Datenannotationsprozess ermöglichen. Das bedeutet, dass diese Unternehmen mit ungenauen Daten und einem langsamen Trainingsprozess von Modellen konfrontiert werden.
- ML-Modelle sind sehr empfindlich. Selbst der kleinste Fehler kann Unternehmen viel kosten. Wenn das Modell mit ungenauen Daten trainiert wird, lernt es auf die falsche Art und Weise und kann daher in Zukunft Daten falsch vorhersagen.
- Mangelndes Prozesswissen kann dazu führen, dass die Datensicherheitsrichtlinien nicht eingehalten werden. Unternehmen haben häufig mit sensiblen Daten zu tun, wie z. B. der Identifizierung von Gesichtern, die mit äußerster Sicherheit behandelt werden müssen. Wenn das Labeln von Daten falsch vorgenommen wird, können Fehlinformationen oder kleine Fehler zu schrecklichen Ergebnissen führen.
Sie sehen, dass die Datenannotation ein sensibles Verfahren ist, das zu falsch trainierten KI-Modellen führen kann. Wenn das passiert, wird Ihr selbstfahrendes Auto gegen den nächsten Baum fahren oder einen unschuldigen Fußgänger überfahren.
Da wir das auf keinen Fall wollen, ist es ratsam, auf andere Unternehmen zurückzugreifen, die über stundenlange Erfahrung bei der Annotation von Daten verfügen.
Klippa ist eines der Unternehmen, das Tausende von Stunden mit dem Labeln von Daten verbracht hat, um unsere KI-basierte Software zu verbessern.
Was Klippa für Sie tun kann
Wir bei Klippa haben unsere Modelle trainiert, um Unternehmen bei der Automatisierung der Dokumentenverarbeitung zu unterstützen.
Da wir unsere KI-gestützte OCR-Engine seit vielen Jahren trainieren, können Sie sicher sein, dass unsere Software DocHorizon zuverlässig und genau arbeitet. Mit unserer Lösung ersparen Sie sich die mühsame Aufgabe der Datenannotation und können trotzdem alle Vorteile nutzen.
Klippa DocHorizon
Im Allgemeinen kann Klippa DocHorizon jedes Bild in Text umwandeln. Darüber hinaus kann diese intelligente Software Daten aus allen Arten von Dokumenten wie Quittungen, Rechnungen, Pässen und Personalausweisen extrahieren, klassifizieren und verifizieren. Das bedeutet, dass Sie jedes Datenfeld automatisch extrahieren und in Ihrer Datenbank speichern lassen können.
Bevor die Daten in Ihrer Datenbank gespeichert werden, ist unsere IDP-Software (Intelligent Document Processing) in der Lage, Dokumentenbetrug zu erkennen und sensible Daten zu maskieren, um die gesetzlichen Vorschriften zu erfüllen.
Wenn Sie Ihre bestehende Software ergänzen oder Daten aus anderen Objekten als Dokumenten extrahieren möchten, können wir Ihnen sicherlich auch weiterhelfen.
Objekt-Erkennung SDK
Unser SDK für die Objekterkennung kann so trainiert werden, dass es alles erkennt, was Sie benötigen. Von einem Stromzähler bis hin zu einer Rechnung – mit genügend beschrifteten Datensätzen kann unser Datenannotation-Team Kunden dabei helfen, unser Objekterkennungsmodell so zu trainieren, dass es jedes beliebige Objekt erkennt.
Dies bedeutet, dass Sie Ihrem Team eine zuverlässige Lösung zur Verfügung stellen können, die es Ihnen ermöglicht, Daten mithilfe von Smartphones zu erfassen.
Sind Sie an unserer Lösung interessiert und möchten gerne mehr sehen? Wir zeigen Ihnen gerne, wie unsere Software funktioniert. Vereinbaren Sie einfach unten eine kostenlose Demo oder kontaktieren Sie einen unserer Experten für weitere Informationen.