Mit weniger mehr zu erreichen, ist ein oft gehörtes Ziel in Managementteams und Unternehmensvorständen. Ob es um die Automatisierung von Arbeitsabläufen oder die Vereinfachung von Prozessen geht, Unternehmen sind immer auf der Suche nach Effizienzsteigerungen und Einsparungen.
Eine IDP-Lösung (Intelligent Document Processing) erreicht diese Ziele, indem sie Mitarbeitern hilft, intelligenter zu arbeiten, schneller zu arbeiten und ihre Produktivität zu steigern.
Die Bedeutung dieser Technologien darf nicht unterschätzt werden. Ein Bericht von Goldman Sachs aus dem Jahr 2018 zeigt beispielsweise, dass Unternehmen 2,7 Milliarden US-Dollar für die manuelle, papierbasierte Zahlungsabwicklung ausgeben, was eine große zeitliche und finanzielle Belastung bedeutet.
Dies ist ein großes Problem für Unternehmen, die mit großen Mengen an Papierdokumenten zu tun haben. Da die Zahl der zu bearbeitenden Dokumente jedes Jahr steigt, können Unternehmen nicht einfach immer mehr Mitarbeiter für die Bearbeitung einstellen, wenn sie ein gesundes Endergebnis erzielen wollen. Denn dies führt zu Skalierbarkeitsproblemen.
Glücklicherweise gibt es Technologien, die Unternehmen bei der Bewältigung dieser Probleme helfen können, z. B. Intelligent Character Recognition (ICR). ICR wird verwendet, um Text aus Bildern oder gescannten Dokumenten wie Quittungen und Rechnungen zu extrahieren, und funktioniert ähnlich wie Optical Character Recognition (OCR).
Aber wie kann diese Technologie Ihrem Unternehmen nützen? Und was sind die Unterschiede zwischen herkömmlicher OCR und ICR?
In diesem Blog finden Sie die Definition von ICR, lernen die Unterschiede zwischen OCR und ICR kennen, erfahren wie ICR funktioniert und wie sie eingesetzt werden kann. Neugierig geworden? Fangen wir an!
Was ist ICR?
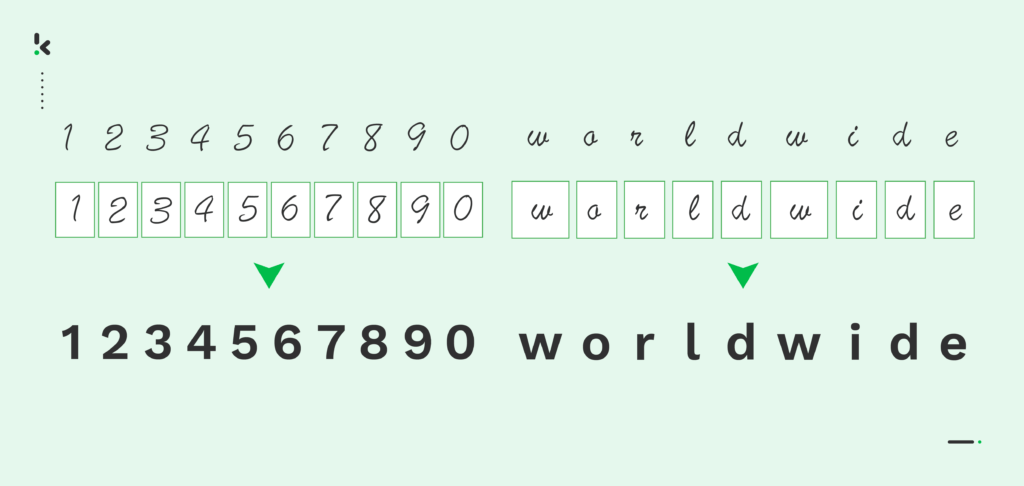
Vereinfacht ausgedrückt ist Intelligent Character Recognition (ICR) eine Technologie, mit der handgeschriebene Texte aus Bilddateien oder Dokumenten extrahiert und in ein maschinenlesbares Format umgewandelt wird.
ICR ist technisch gesehen eine Variante der Optical Character Recognition. Deshalb wird sie manchmal auch als OCR bezeichnet.
Im Gegensatz zur OCR-Technologie, die sich auf gedruckte oder computergestützte Zeichen konzentriert, verwendet ICR Machine Learning und KI, um verschiedene handgeschriebene Stile und Schriftarten zu erkennen. Aus diesem Grund kann sie als eine erweiterte Version der OCR gesehen werden.
Die ICR-Technologie verbessert ihre Lernfähigkeit jedes Mal, wenn neue handgeschriebene Muster verwendet werden. Auf diese Weise kann die Datengenauigkeit mit der Zeit verbessert werden.
Wie bereits erwähnt, kann ICR oft mit OCR verwechselt werden und umgekehrt. Der nächste Abschnitt soll Ihnen helfen, die Unterschiede zwischen den beiden zu verstehen.
Unterschiede zwischen ICR und herkömmlicher OCR
Intelligent Character Recognition (ICR) und Optical Character Recognition (OCR) haben viele Gemeinsamkeiten, was verständlich ist, wenn man bedenkt, dass ICR eine Untergruppe von OCR ist.
Ein Vergleich der ICR mit der traditionellen, vorlagenbasierten OCR ist jedoch eine andere Geschichte. Diese beiden Technologien unterscheiden sich erheblich voneinander, wie unten dargestellt.
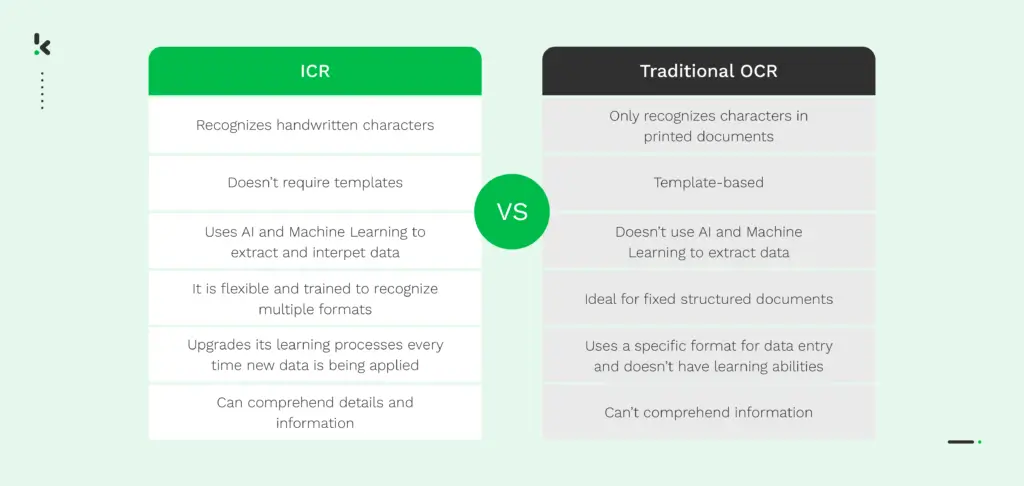
Kurz gesagt: Intelligent Character Recognition (ICR) ermöglicht die Umwandlung von handgeschriebenem Text in Daten, die von einer Maschine einfach zu verstehen, zu suchen und zu ändern sind. Im Gegensatz zu herkömmlicher OCR nutzt ICR, KI und Machine Learning, um Details zu verstehen und Informationen aus den Dokumenten zu extrahieren, was die Integration in verschiedene Geschäftsabläufe erleichtert.
ICR ist eine hervorragende Ergänzung zu Ihrem Datenerfassungsprozess, wenn Sie mit vielen handschriftlichen Dokumenten arbeiten, die sowohl strukturierte als auch unstrukturierte Informationen enthalten.
Wie funktioniert ICR?
ICR funktioniert ähnlich wie OCR bei der Erkennung von Zeichen. Der einzige Unterschied besteht darin, dass ICR handschriftliche Zeichen erkennen kann, was bei der herkömmlichen OCR nicht möglich ist.
Um besser zu verstehen, wie ICR diese Probleme angeht, wollen wir die folgenden ICR-Prozessschritte genauer untersuchen:
- Schritt 1: Vorverarbeitung des Bildes
- Schritt 2: Segmentierung
- Schritt 3: Erkennung
- Schritt 4: Nachbearbeitung der Ausgabe
Schritt 1: Vorverarbeitung des Bildes
Rohdaten können in der Regel nicht direkt verarbeitet werden. Um Daten genau aus Dokumenten zu extrahieren, müssen die Bilder zunächst vorverarbeitet werden. Das bedeutet, dass die Qualität des Bildes verbessert werden muss, um eine akzeptable Form für die Erkennung zu erreichen.
In der Vorverarbeitungsphase werden viele unterschiedliche Techniken eingesetzt, um ein klareres und besseres Bild zu erhalten. Zu diesen Techniken gehören unter anderem:
- De-Skewing – Der Prozess der Begradigung und Winkelanpassung eines Bildes, nachdem es gescannt wurde.

- Rauschentfernung – Diese Strategie umfasst die Entfernung von Hintergrundtexturen, störenden Strichen und anderen ähnlichen Elementen sowie die Änderung des Intensitätsbereichs einzelner Pixel, um sie an die Durchschnittswerte der umgebenden Pixel anzupassen.

- Binarisierung – Bei der Binarisierung wird ein Graustufenbild in ein Schwarzweißbild umgewandelt, was oft auch als Bildschwellenwert bezeichnet wird. Diese Technik ermöglicht eine genauere Trennung von Text und Hintergrund.

- Normalisierung – Dieser Prozess zielt darauf ab, das Auftreten von Schräglage und Neigung zu beseitigen. Diese Begriffe beziehen sich auf die Neigung auf Zeichenebene (Schräglage) oder auf Wortebene (Neigung), wie Sie in der folgenden Abbildung sehen können.

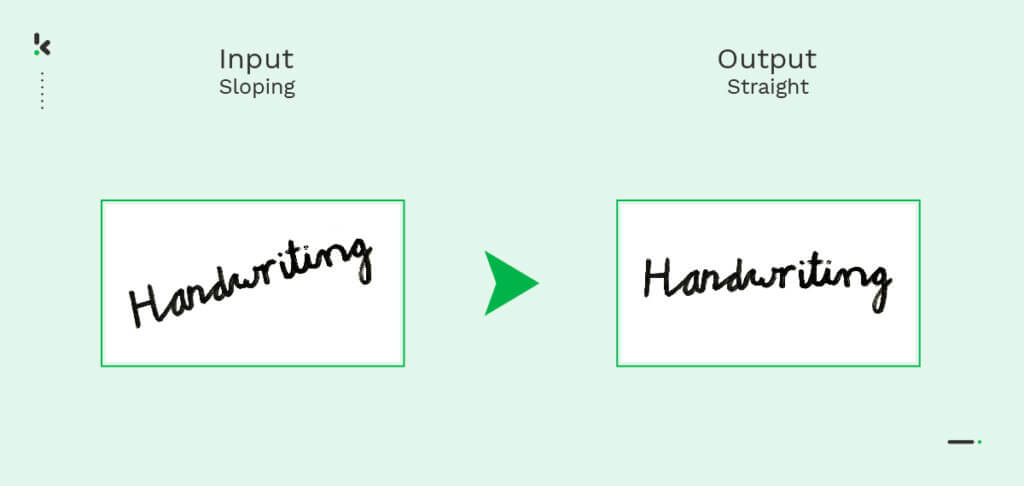
Das Endergebnis der Vorverarbeitungsphase muss ein klares Bild mit leicht erkennbaren Zeichen und ohne störende Elemente sein.
Schritt 2: Segmentierung
Bei der Segmentierung werden Informationen im Text voneinander getrennt, um die weitere Datenanalyse zu erleichtern. Diese Kategorien sind an dieser Technik beteiligt:
- Zeilensegmentierung – Die Isolierung der Textzeilen im Bild.

- Wortsegmentierung – Die Isolierung der einzelnen Wörter in den Textzeilen.

- Zeichensegmentierung – Die Isolierung von Zeichen der Wörter.

Schritt 3: Erkennung
Nach der Segmentierung werden die isolierten Wortfragmente erkannt. Dieser Prozess erfolgt durch vortrainierte Modelle, d. h. die Zeichen werden anhand einer bereits vorhandenen Datenbank als Referenzpunkt erkannt.
Dabei wird für jedes Zeichen eine Punktzahl vergeben. Normalerweise ist das erkannte Zeichen dasjenige mit der höchsten Punktzahl im Vergleich zu den Zeichen in der vorgegebenen Datenbank.
Wie bereits erwähnt, ist die ICR lernfähig, d. h. sie verbessert ihre Genauigkeit jedes Mal, wenn neue handgeschriebene Stile und Schriftarten in das System hochgeladen werden.

Schritt 4: Nachbearbeitung der Ausgabe
Dieser Schritt ist für die Verbesserung der Genauigkeit der Datenextraktion von entscheidender Bedeutung, da er sich ganz auf die Methoden und Algorithmen konzentriert, die die besten Ergebnisse liefern.
Nach dem Korrekturlesen und der Überprüfung auf Rechtschreibfehler weist ICR auf Anomalien hin (falls entdeckt), die der Benutzer beheben kann.
Sobald die Daten korrigiert und genau beschriftet sind, können sie in einer Datenbank Ihrer Wahl gespeichert werden.
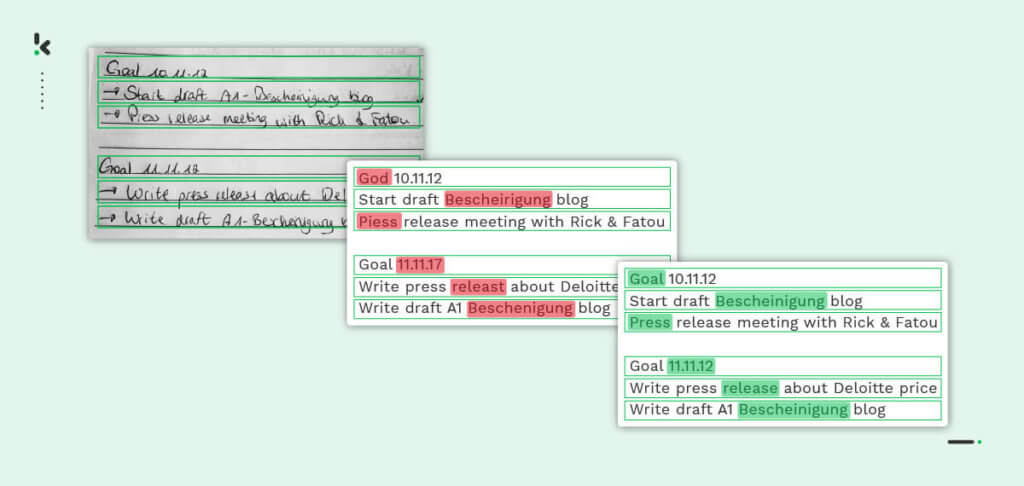
Mit ICR können Unternehmen unstrukturierte Daten, wie z. B. handgeschriebenen Text, in geschäftsfähige Daten umwandeln, die in ihren dokumentenbezogenen Arbeitsabläufen weiterverwendet werden können. Das bringt natürlich zahlreiche Vorteile mit sich.
Vorteile von ICR
Jedes Unternehmen, das regelmäßig eine Vielzahl von Formularen, Briefen und Papieren bearbeitet, z. B. im Finanz-, Rechts- oder Gesundheitssektor, kann von ICR profitieren. Diese Vorteile umfassen:
- Weniger Fehler bei der Dateneingabe – Unternehmen, die mit großen Datenmengen arbeiten, müssen mit einer Fehlerquote von bis zu 4 % rechnen. Eine ICR-Lösung mithilfe von KI und Machine Learning kann Ihnen helfen, diese Fehler deutlich zu reduzieren.
- Geringere Betriebskosten – Wie bereits erwähnt, kann die manuelle Verarbeitung von Dokumenten sehr teuer sein. Mit ICR können Sie diese Kosten um bis zu 90 % senken!
- Kürzere Bearbeitungszeit – Die manuelle Datenextraktion und -überprüfung dauert 10 bis 20 Minuten pro Dokument, während Sie mit ICR 70 % dieser Zeit einsparen können.
- Skalierbarkeit – Das ICR-System ist sehr flexibel, sodass es verschiedene Arten von Dokumenten analysieren oder große Mengen verarbeiten kann.
ICR wird in vielen Branchen eingesetzt, da es eine schnelle und kostengünstige Lösung für die Verarbeitung großer Mengen von Dokumenten ist. Im nächsten Abschnitt dieses Blogs werfen wir einen Blick auf einige Anwendungsfälle.
ICR-Anwendungsfälle
Wenn Ihr Unternehmen auf digitale Arbeitsabläufe umstellt, aber immer noch große Mengen an handschriftlichen Papierdokumenten (z. B. Bestellungen, kundenspezifische Formulare oder Logistikdokumente) bearbeitet werden müssen, kann die ICR-Technologie Sie bei der Digitalisierung dieser Dateien unterstützen.
Intelligent Character Recognition ist in einer Vielzahl von Szenarien von Vorteil. Nachstehend sind einige der gängigsten ICR-Anwendungsfälle aufgeführt (die Liste erhebt keinen Anspruch auf Vollständigkeit):
- Automatisieren Sie Prozesse in der Kreditorenbuchhaltung
- Bild in Text umwandeln
- Dateneingabe automatisieren
- Informationen aus einer PDF-Datei extrahieren
- Prozesse für Formulare automatisieren
Wie Sie sehen, bietet ICR zahlreiche Anwendungen, mit denen Sie Ihre Mitarbeiter unterstützen, die Effizienz steigern und die Datengenauigkeit verbessern können.
Machen Sie sich keine Sorgen, wenn Ihr Anwendungsfall nicht aufgeführt ist, denn es ist gut möglich, dass Klippa Ihnen mit einer ausgefeilten ICR-Lösung dennoch helfen kann, Ihre dokumentenbezogenen Arbeitsabläufe zu automatisieren.
Warum Klippa ICR wählen?
Wenn wir Ihr Interesse an ICR-Software geweckt haben, müssen Sie nicht weiter suchen, denn wir präsentieren Ihnen Klippa DocHorizon. Diese intelligente Dokumentenverarbeitungslösung vereint das Beste aus ICR und OCR-Technologien.
Mit Klippa DocHorizon können Sie dank KI und Machine Learning, Daten sowohl aus unstrukturierten als auch aus strukturierten Dokumenten extrahieren, einschließlich handgeschriebenen Unterschriften oder numerischer Werte. Im Gegensatz zu herkömmlicher OCR benötigt DocHorizon keine Vorlagen und ist ausreichend entwickelt, um kontinuierlich zu lernen und Daten genau zu interpretieren.
Neben der Automatisierung der Datenextraktion können Sie auch die folgenden Aufgaben automatisieren, die traditionell oft von Menschen erledigt werden:
- Dokumentenklassifizierung – Dokumenterkennung zur einfachen Archivierung von Dokumenten
- Dokumentenkonvertierung – Konvertierung unstrukturierter und strukturierter Dokumente in maschinenlesbare Formate (JSON, CSV, XML, XSLS)
- Anonymisierung – Maskierung sensibler Daten zur Einhaltung der DSGVO-Vorschriften
- Datenüberprüfung – Überprüfen von Daten mit Datenbanken von Drittanbietern
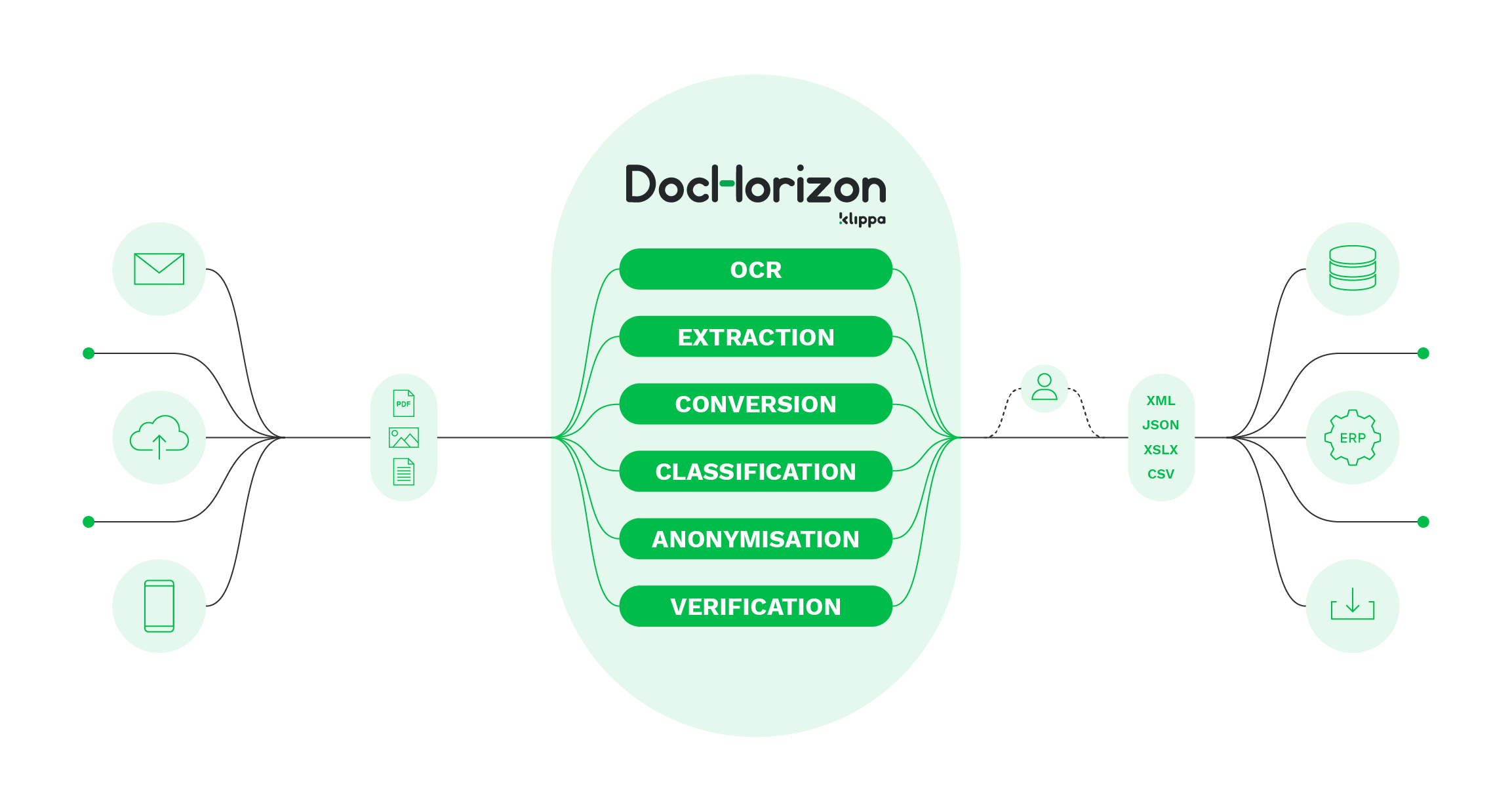
Mit diesen Funktionen ist DocHorizon die beste Lösung, um Dokumente innerhalb von Sekunden zu digitalisieren, die Genauigkeit zu erhöhen, manuelle Eingabefehler zu reduzieren, Betrug zu verhindern und die Kundenerfahrung zu verbessern.
Möchten Sie mehr über unsere Lösung erfahren? Vereinbaren Sie einfach einen Termin für eine Demo oder nehmen Sie Kontakt mit uns auf, wenn Sie Fragen haben.