Las empresas almacenan datos en bases de datos y entornos en línea más que nunca. De hecho, el 60% de los datos corporativos del mundo están en la nube. Pero, ¿disponen estas empresas de las herramientas adecuadas para proteger los datos sensibles desde el punto de vista de la privacidad? Aunque existen muchas normativas sobre privacidad de datos que las empresas deben cumplir, como el GDPR en Europa, no siempre salvaguardan los datos de las posibles filtraciones.
Según Verizon, la mayoría de las filtraciones afectan a datos de identificación personal (PII) y datos de tarjetas de pago. Cada vez que una empresa sufre una filtración de datos, puede resultar costoso tomar las medidas adecuadas para minimizar los daños e informar a las distintas partes interesadas a las que conciernen los datos.
Además, puede repercutir negativamente en la reputación de la empresa, lo que a la larga puede ocasionar pérdidas económicas. Por ello, las organizaciones deben encontrar medidas preventivas como la anonimización de datos para salvaguardar los datos sensibles que almacenan y procesan.
En este blog hablaremos de cómo son estas medidas preventivas, qué técnicas se pueden utilizar y cómo automatizar la anonimización de datos con soluciones modernas de IA. ¡Empecemos!
¿Qué es la anonimización de datos?
La anonimización de datos es un método de protección de la información confidencial o personal mediante la eliminación o alteración de los datos de identificación personal que se almacenan en un juego de datos. El objetivo de la anonimización de datos es preservar la credibilidad de los datos almacenados o intercambiados y garantizar el cumplimiento de la estricta regulación sobre privacidad de datos.
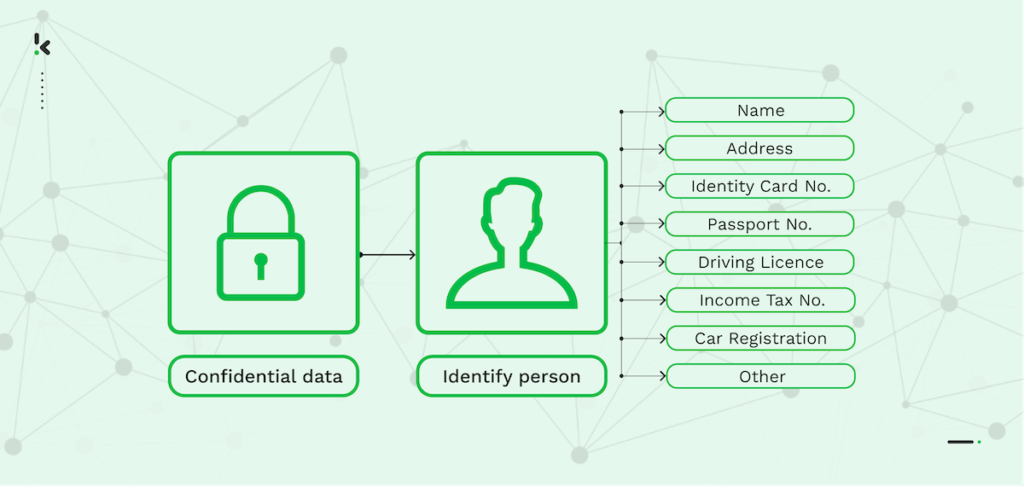
El criterio principal de la anonimización según la el estandard ISO (ISO 29100:2011) es que la información personal identificable (PII) se altere de forma irreversible para que la persona ya no pueda ser identificada directa o indirectamente. Por lo tanto, la información financiera, los datos de contacto, los informes médicos y los datos de pago que contengan IIP deben estar bien protegidos para cumplir la estricta regulación sobre la privacidad de los datos.
Ahora que ya sabes qué es la anonimización de datos, continuemos con cómo anonimizar datos.
Cómo anonimizar datos
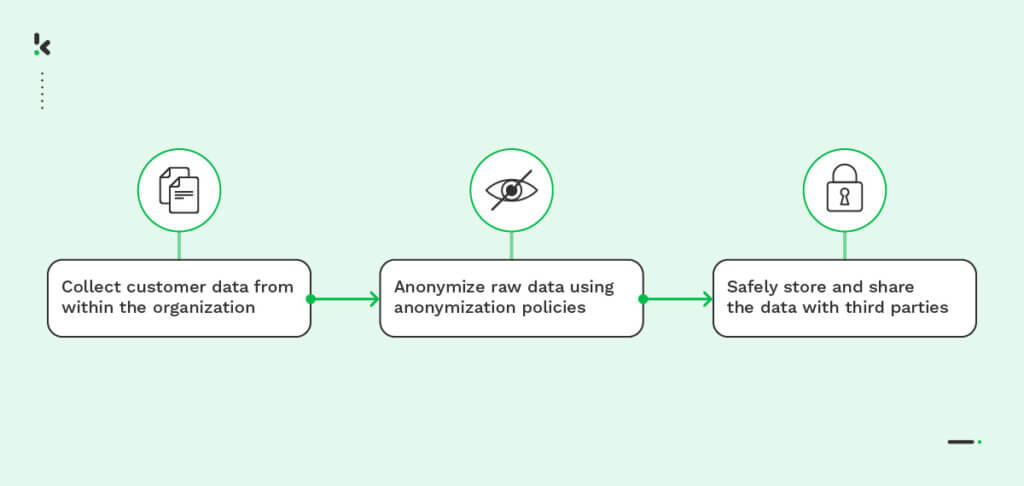
Para anonimizar datos, primero hay que identificar la IIP en el conjunto de datos y luego determinar la técnica de anonimización adecuada en función del riesgo potencial de filtración. Hay varias soluciones de software disponibles que pueden adaptarse a tu caso de uso y requisitos, por ejemplo:
- Software de enmascaramiento de datos
- Software de encriptación de datos
- Software de anonimización de datos
- Software de gobernanza de datos
- Software de procesamiento inteligente de documentos
Cada uno de estos programas utiliza un conjunto diferente de técnicas de anonimización de datos, que analizaremos con más detalle en la siguiente sección.
Técnicas de anonimización de datos
La siguiente lista recoge las técnicas más utilizadas para anonimizar datos sensibles:
- Enmascaramiento de datos
- Seudonimización
- Generalización
- Intercambio de datos
- Perturbación de datos
- Datos sintéticos
Enmascaramiento de datos
El enmascaramiento de datos es el proceso de hacer accesibles los datos con valores modificados. El enmascaramiento de datos puede realizarse modificando los datos en tiempo real (enmascaramiento dinámico de datos) o creando una imagen espejo de una base de datos basada en datos alterados (enmascaramiento estático de datos). La anonimización puede realizarse con una serie de técnicas de enmascaramiento de datos, como el encriptado, la redacción de datos, la mezcla de caracteres, la sustitución de valores, la codificación, etc.
Seudonimización
La seudonimización es un método de desidentificación de datos que consiste en sustituir los identificadores privados por seudónimos (identificadores falsos). Un ejemplo podría ser cambiar el nombre “Jane Smith” por “Janet Doe”. La seudonimización garantiza la precisión estadística al tiempo que asegura la confidencialidad de los datos. Esto significa que los datos pueden seguir utilizándose con fines de entrenamiento, prueba y análisis.
Generalización
La generalización es una técnica que consiste en excluir deliberadamente algunas partes de los datos para hacerlos menos identificables, conservando al mismo tiempo la exactitud de los datos. Con esta técnica, los datos pueden modificarse en un rango de valores con límites lógicos. Por ejemplo, se puede revelar una dirección concreta sin el número de casa, o se sustituye el número dentro de un rango de 140 números de casa del original.
Intercambio de datos
El intercambio de datos, también conocido como barajado o permutación, es una técnica que intercambia y reordena los valores de los atributos del conjunto de datos haciendo que los datos no coincidan con la información inicial. El cambio de atributos que incluyen valores identificables, como el número del seguro social o la fecha de nacimiento, puede influir significativamente en la anonimización.
El intercambio de datos se utiliza a menudo cuando se trata de datos identificables dentro de columnas almacenadas en archivos Excel, por ejemplo, registros de clientes o empleados.
Perturbación de datos
La perturbación de datos es una técnica que modifica ligeramente el conjunto de datos inicial añadiendo ruido aleatorio y utilizando métodos de redondeo de valores. Los valores deben ser proporcionales a la perturbación empleada para conservar la utilidad de los datos. Por ejemplo, si la base utilizada para modificar los valores originales es demasiado pequeña, los datos no se pueden anonimizar suficientemente. Y si la base es demasiado grande, los datos pueden no ser reconocibles o utilizables.
Por ejemplo, a menudo se utiliza un valor base de 5 para redondear valores como la edad.
Datos sintéticos
Los datos sintéticos son conjuntos de datos artificiales generados algorítmicamente sin relación a ningún caso original. Este método es posible gracias al uso de modelos matemáticos basados en patrones que residen en el conjunto de datos original. Tales modelos incluyen regresiones lineales, desviaciones estándar, medianas u otros modelos estadísticos útiles para crear resultados sintéticos.
Con el uso de conjuntos de datos artificiales, no hay riesgos de comprometer la protección de datos y la privacidad, ya que no incluyen información de identificación personal real.
Es posible que algunas de estas técnicas se hayan cruzado en tu camino en algún momento si tu organización trabaja con datos sensibles para la privacidad. Si no es así, esperamos poder aclararte en el siguiente párrafo si es relevante para ti al presentarte varios casos de uso de la anonimización de datos.
Casos de uso de la anonimización de datos
Para que este blog sea fácil de leer, sólo cubriremos los casos de uso de la anonimización de datos con los que nos encontramos más a menudo. La siguiente lista no es exhaustiva:
- Incorporación Remota de Clientes
- Procesamiento de Información Financiera
- Desarrollo de Software y Productos
Incorporación Remota de Clientes
Las organizaciones que necesitan verificar y almacenar la información de sus clientes durante los procesos de incorporación remota están sujetas a diversas regulaciones como KYC, GDPR y AML, por nombrar algunas. A menudo, los clientes necesitan escanear sus documentos de identidad para que la empresa pueda verificar su identidad o realizar la debida diligencia del cliente.
Para proteger la PII, como los números del seguro social (SSN) o la fecha de nacimiento, de un uso indebido, las organizaciones pueden aplicar la anonimización de datos a través de diversas técnicas de enmascaramiento.
Procesamiento de Información Financiera
Las instituciones financieras necesitan proteger la privacidad de sus clientes cuando procesan información financiera. A menudo esto se consigue eliminando u ocultando la PII de los conjuntos de datos mediante técnicas de anonimización de datos como el enmascaramiento o la generalización de datos.
Estas técnicas pueden aplicarse a varios tipos de información financiera, como informes de transacciones, informes de crédito, información de pagos, facturas, extractos bancarios y solicitudes de préstamos.

Desarrollo de Software y Productos
Los desarrolladores necesitan utilizar datos reales cuando desarrollan software y herramientas para superar problemas de la vida real, realizar pruebas y mejorar las soluciones existentes. La razón por la que los datos suelen anonimizarse es que el entorno de desarrollo puede ser vulnerable a filtraciones o a que los datos se compartan entre varios equipos. En última instancia, esto puede poner en peligro datos sensibles.
Por qué deberías anonimizar los datos
Hay varias razones por las que deberías anonimizar los datos. Entre las más importantes se encuentran las siguientes:
- Protección contra el uso indebido de los datos: La anonimización de datos garantiza que las partes interesadas internas no puedan hacer un uso indebido de los datos y minimiza el riesgo de que los datos sean explotados en caso de que la organización sea atacada por delincuentes externos.
- Cumplimiento de las regulaciones de privacidad de datos: El Reglamento General de Protección de Datos (GDPR) en la Unión Europea y la Ley de Privacidad del Consumidor de California (CCPA) en los Estados Unidos requieren que las empresas protejan los datos personales de los individuos y proporcionen ciertos derechos a los sujetos de datos. Anonimizar los datos ayuda a las empresas a cumplir estos requisitos y evitar multas por incumplimiento de las regulaciones.
- Oportunidades para compartir datos: Los datos que contienen información de identificación personal no pueden compartirse con otras compañías, lo que limita la búsqueda de nuevas oportunidades de negocio. Sin embargo, con la anonimización de datos, las empresas pueden compartirlos con socios o investigadores para obtener nuevos conocimientos y desarrollar nuevos productos. Por ejemplo, los datos anonimizados pueden utilizarse para entrenar modelos de machine learning con el fin de mejorar productos y servicios.
Aunque la anonimización de datos es importante y puede ser beneficiosa para tu organización, existen algunas desventajas que quizás quieras tener en cuenta.
Desventajas de la anonimización de datos
A continuación se presentan algunas de las desventajas de la anonimización de datos:
- Pérdida de la utilidad de los datos: Las regulaciones exigen que los sitios web reciban permiso de los visitantes para recolectar información personal como cookies y direcciones IP. Sin embargo, al eliminar los identificadores y anonimizar los datos se puede restringir la capacidad de utilizar los datos en los resultados. Por ejemplo, los datos de usuario anonimizados no pueden utilizarse con fines de marketing personalizado o de orientación.
- Depende de recursos técnicos: La anonimización de datos puede ser un proceso que requiera muchos recursos técnicos. Las organizaciones necesitarían tener conocimientos y experiencia especializados para implementarlo. Además, su mantenimiento puede llevar mucho tiempo y ser costoso. Debido a la sofisticación de los hackers y los métodos de filtración de datos, las empresas deben actualizar continuamente sus técnicas de anonimización para garantizar que los datos permanezcan realmente anónimos.
Ahora que ya tienes una idea de las ventajas y desventajas de la anonimización de datos, te explicaremos cómo puedes anonimizar datos.
Anonimizar tus datos con Doxis AI.dp
Si quieres anonimizar los datos de los documentos que reúnes, digitalizas y extraes, Doxis puede ayudarte. Nuestro software de procesamiento inteligente de documentos AI.dp utiliza el reconocimiento óptico de caracteres (OCR) para extraer texto de imágenes y modelos de IA para reconocer, clasificar y anonimizar datos según tus necesidades. ¿Cómo?
AI.dp puede entrenarse para tachar y enmascarar determinados campos y textos de los documentos que se envían al motor de procesamiento. Estos documentos pueden enviarse por correo, web o aplicación móvil en forma de JPG, PNG y PDF, por ejemplo. Una vez aplicada la anonimización de datos, puedes recibir los datos anonimizados en el formato que elijas, como JSON, XLSX, XML o CSV.
La implementación de nuestra solución de anonimización de datos es muy sencilla gracias a la documentación adecuada disponible y puede realizarse a través de API o SDK. Nuestra API te será útil si quieres construir tu propia línea de extracción de información y anonimización y conectarla con tus sistemas de software existentes.
Nuestro SDK, por otro lado, te permite convertir tus dispositivos móviles en dispositivos de captura de datos con la capacidad de enmascarar datos de forma selectiva. Esto es útil si quieres añadir funciones de anonimización de datos a tu aplicación móvil existente o que vayas a lanzar próximamente.
Con AI.dp, puedes obtener las siguientes ventajas:
- Conservación de la utilidad de los datos al extraerlos y anonimizarlos automáticamente
- Mayor cumplimiento de las regulaciones y requisitos de privacidad de datos
- Reducción de costos, ya que no es necesario adquirir varias soluciones para crear un proceso de anonimización de datos.
- Mayor rapidez en la anonimización y el procesamiento de datos gracias a la automatización.
- Escalabilidad facilitada con baja dependencia de los recursos humanos
¿Estás listo para automatizar la extracción y anonimización de datos? Complete el siguiente formulario para obtener una demostración gratuita de nuestro software. Si tienes más preguntas, ponte en contacto con nuestros expertos para obtener más información.