Recientemente, la legislación sobre el GDPR (siglas en Inglés, General Data Protection Regulation) ha entrado en vigor en Europa.
Por consiguiente, las empresas son más conscientes que nunca de sus responsabilidades en relación con el almacenamiento y la gestión de la información personal.
Se requiere un claro consentimiento del cliente antes de que una empresa pueda almacenar cualquier información personal.
En este artículo, explicaremos cómo la anonimización automática de documentos puede ayudar a su empresa a cumplir con la legislación de la GDPR.
Los retos para cumplir con GDPR
Para muchas empresas la legislación sobre el GDPR trajo nuevos desafíos legales. Porque, ¿qué hacer con la información personal ya almacenada? A veces en archivos físicos, a veces en archivos digitales en todo tipo de bases de datos y tipos de documentos.
Para muchas empresas falta el consentimiento para todos o parte de sus datos. En la mayoría de los casos, esto lleva a las empresas a tener tres opciones:
- Eliminar todos los documentos de la base de datos que contengan información personal.
- Intentar adquirir un consentimiento compatible con el pasado de los clientes para seguir almacenando la información.
- Anonimizar todos los documentos de la base de datos.
La primera opción suele ser una decisión difícil de tomar. Otra información de los documentos almacenados puede seguir siendo relevante o incluso vital para, por ejemplo, la contabilidad y el aspecto jurídico.
La segunda opción está lejos de ser fácil de alcanzar, porque ¿cómo se contacta con alguien para obtener un consentimiento? ¿Y qué pasa si no se obtiene una respuesta o no se obtiene el consentimiento? Las posibilidades de poder ponerse en contacto con todos y obtener el consentimiento de todos son muy pocas.
Eso nos deja con la tercera opción: anonimizar todos los documentos o seudonimizar todos los documentos. Esto se puede hacer en archivos como contratos, pasaportes, identificaciones, facturas y más. El problema aquí es que hacerlo manualmente puede ser una tarea enorme. Manualmente será muy largo, todavía necesitará algún tipo de interface de software y el riesgo de cometer errores es alto.
Pero, ¿qué pasaría si los documentos anonimizados se pudieran hacer automáticamente con un software de anonimización preciso? Aquí es donde Doxis viene al rescate!
¿Qué es Doxis?
Doxis es especialista en la extracción de datos de contratos, facturas, recibos, pasaportes, documentos de identidad y más. En muchas aplicaciones diferentes nuestro software inteligente se utiliza para extraer información como nombres, fechas y cantidades de documentos.
Algunos ejemplos de uso son el procesamiento de facturas, la gestión de gastos y la automatización de procesos KYC. La extracción de datos adecuada comienza con el software de reconocimiento de texto y la localización de la información en los documentos.
Dado que esta tecnología ya constituye el núcleo de nuestro software, Doxis ha decidido ampliar sus servicios con un software de anonimización de documentos y de seudonimización.
Entonces, ¿cómo funciona eso?
Doxis establece un servidor seguro en el país que elija. Su organización puede enviar documentos a este servidor a través del correo, la API o una subida manual. En cuanto se reciben los documentos, se activa el software de Doxis.
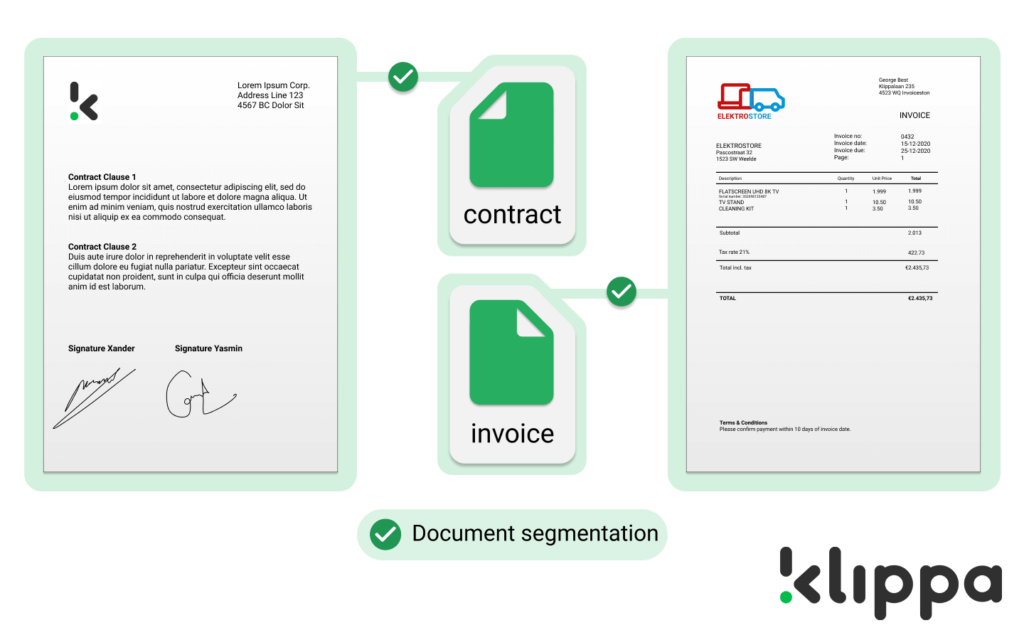
El primer paso del proceso se llama segmentación de documentos. En este paso el software de Doxis utiliza un modelo de machine learning para determinar el tipo de documentos que se envían y los divide en carpetas virtuales. En este paso Doxis separa, por ejemplo, los contratos de las facturas.
En el siguiente paso se utiliza un conjunto único de reglas para cada tipo de documento que se clasifica. Estas reglas determinan qué cambios se están haciendo en cada tipo de documento y se asegura de que todos los datos que quiere anonimizar sean anonimizados y que el resto de la información se deje intacta.

Anonimizar la información personal en los documentos
Ahora que está claro qué tipos de documentos están presentes y qué información es relevante para los casos de uso específicos, es el momento de nuestro software de reconocimiento inteligente. Paso a paso, el software de Doxis tomará un documento, lo convertirá a un formato legible y usará el reconocimiento de patrones para encontrar tipos de información predefinidos.
Los patrones identificados (información personal) son entonces extraídos del documento y reemplazados por un identificador predefinido. Esto puede ser algo sin significado como un espacio vacío, una cadena de ‘-‘, o una variable como ‘NOMBRE’ o ‘NÚMERO DE TELÉFONO’. Los valores originales son, según sus preferencias, eliminados permanentemente del documento y no son recuperables en el futuro por nadie.
Como último paso, todos los documentos son almacenados y enviados a la base de datos del cliente. ¿El resultado? Una base de datos completamente digital y completamente anonimizada con documentos conformes a la norma GDPR!

Cuando sea necesario, se puede configurar una interfase de control antes de que los documentos sean marcados definitivamente como ‘anonimizados’. En esta interfase los empleados de su organización pueden comprobar todos los documentos o realizar comprobaciones a modo de muestra como sello final de aprobación.
¿Su organización se enfrenta a desafíos en las áreas de extracción de datos, OCR o anonimización? Póngase en contacto con nosotros y Doxis le ayudará a resolver estos desafíos de una manera eficaz.