Las organizaciones manejan a diario grandes cantidades de documentos, que varían en cuanto a tipo, contenido o importancia. Garantizar una clasificación precisa de estos archivos puede convertirse rápidamente en una tarea frustrante, sobre todo si se hace manualmente. Algunos de tus empleados se encargan de organizar manualmente los documentos basándose en estas etiquetas. Esto cuesta tiempo y, en el peor de los casos, los archivos se pierden al estar clasificados de forma inexacta.
Sin embargo, gracias al rápido desarrollo de la tecnología, los empleados ya no dedican un tiempo excesivo a clasificar documentos, dejando estas tareas en manos de la automatización. En este blog, encontrarás una explicación exhaustiva de lo que representa la clasificación de documentos, conocerás el proceso que hay detrás de su automatización y descubrirás una solución “lista para usar” para clasificar los documentos de tu empresa. Empecemos.
¿Qué es la Clasificación de Documentos?
La clasificación de documentos es el proceso de asignar documentos a categorías relevantes para facilitar su gestión y análisis. El objetivo es organizar los archivos con la mayor precisión posible, facilitando la búsqueda y localización de elementos.
Aunque la clasificación de documentos es una tarea importante en sí misma, también forma parte de una iniciativa de automatización mucho mayor, llamada procesamiento inteligente de documentos. Por lo tanto, la clasificación de estos archivos es sólo una de las muchas acciones que pueden automatizarse para mejorar los flujos de trabajo de procesamiento de documentos.
La clasificación de documentos puede realizarse utilizando dos parámetros: la clasificación textual y la clasificación visual. Algunos de estos parámetros pueden verse en los motores de búsqueda de la vida real, lo que permite a los usuarios encontrar lo que buscan sin mucho esfuerzo.
Para entender mejor cómo puede llevarse a cabo la clasificación de documentos, es necesario dar un paso atrás y analizar primero el proceso técnico que hay detrás de la clasificación automatizada de documentos.
Tipos de Clasificación de Documentos
Como ya se ha mencionado, los documentos se clasifican en función de su contenido, ya sea texto o imagen. Para cada tipo de clasificación de documentos, se pueden descubrir diferentes métodos para detectar y analizar el contenido específico, de los que hablaremos en breve.
Clasificación de Texto
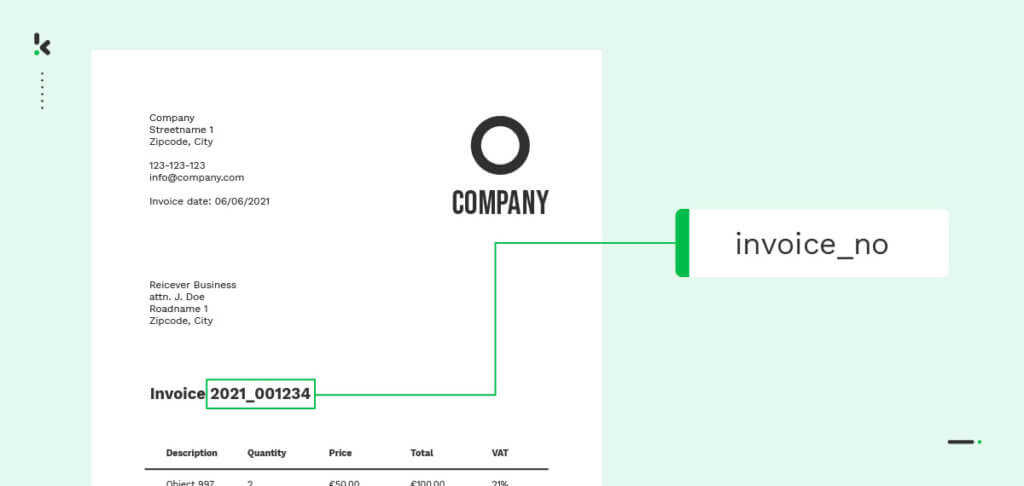
La clasificación de textos se ocupa del procesamiento de la información textual de diversos tipos de documentos. Dado que la mayoría de las empresas dependen de documentos con mucho texto para sus operaciones diarias, la clasificación de textos se ha convertido en el principal objetivo de la mayoría de los proveedores de software, como el software de OCR.
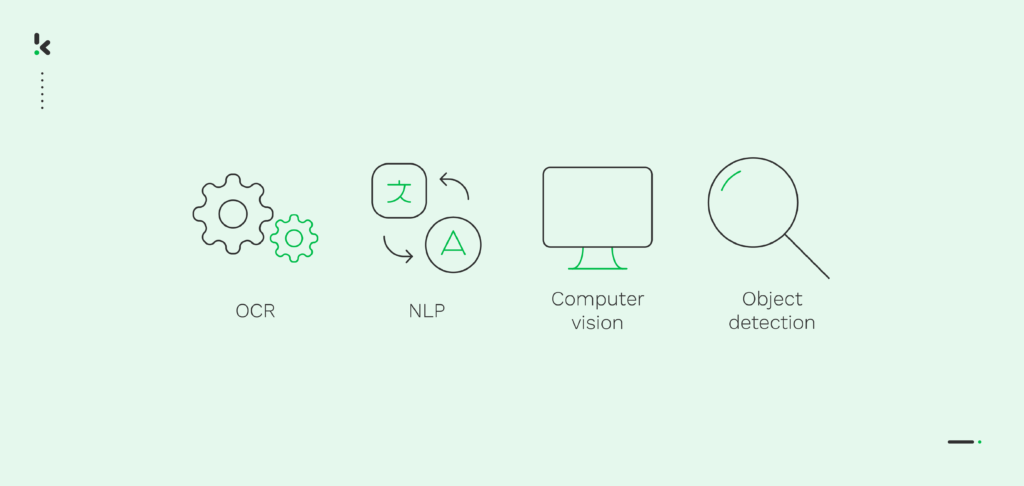
¿Cómo funciona la clasificación de textos? La clasificación de textos suele utilizar tecnologías como el OCR y la NLP (Procesamiento de Lenguaje Natural), que forman parte de la tecnología de machine learning.
El OCR es una tecnología que ayuda a extraer texto de imágenes o documentos escaneados y lo convierte a un formato legible por máquina. A menudo, esta tecnología se combina con la Inteligencia Artificial (IA) y el Machine Learning (ML) para lograr una gran precisión en la extracción de datos.
La NLP es una técnica más compleja, responsable de analizar los datos extraídos y comprender la semántica del texto. La NLP hace posible que los ordenadores entiendan el lenguaje humano en un contexto específico, creando un proceso de extracción de datos de alta precisión y calidad.
Para clasificar automáticamente un documento, es necesario utilizar primero el OCR para extraer la información y la NLP para comprender el contenido de la información.
Clasificación de Imágenes
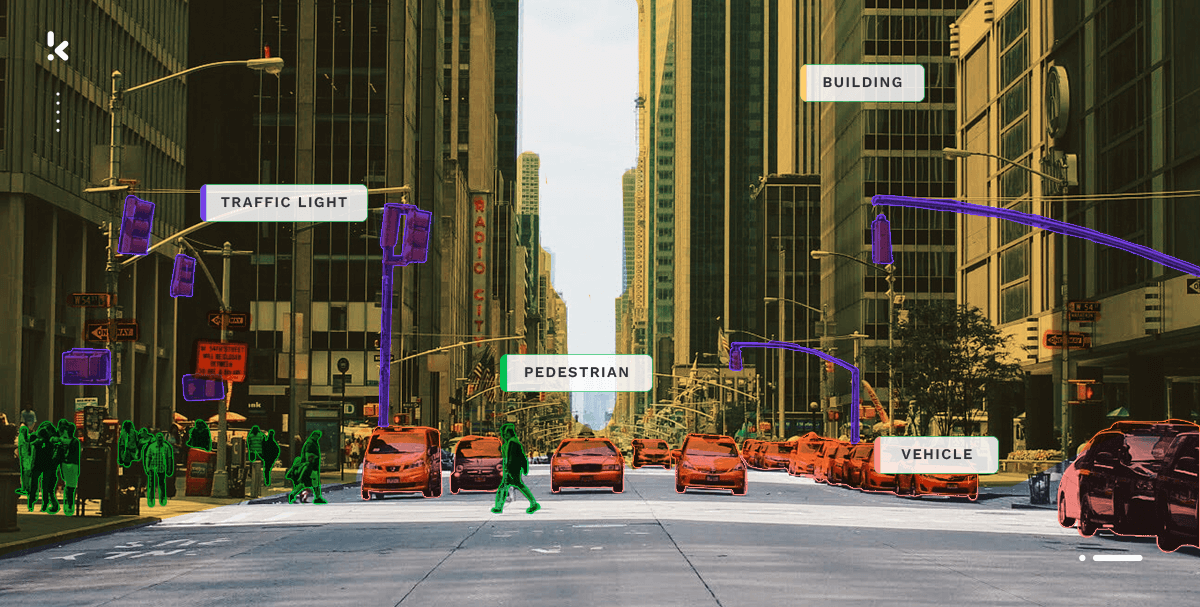
En la clasificación de imágenes, la atención se centra en la estructura visual de los documentos. La detección de imágenes y vídeos en un documento se realiza analizando los píxeles que crean el elemento visual y determinando a continuación su contenido. La identificación y clasificación de imágenes se realiza empleando tecnologías como la Computer Vision y la Detección de Objetos.
La Computer Vision es una tecnología basada en IA capaz de reconocer objetos en imágenes fijas o vídeos. Se puede utilizar para detectar objetos dentro de una imagen, su ubicación en el documento o la acción representada en el contenido visual. La computer vision ayuda a clasificar imágenes aplicando opciones de filtrado y búsqueda.
La detección de objetos se aplica en áreas de negocio que tienen que gestionar grandes cantidades de datos visuales, y donde la clasificación tiene lugar a mayor escala. Por ejemplo, la detección de objetos está muy presente en los departamentos de logística, almacenes e inventarios, donde el escaneo de códigos de barras o códigos QR forma parte de las operaciones diarias.
Ahora que ya te has familiarizado con las tecnologías utilizadas para mejorar la clasificación de textos e imágenes, vamos a adentrarnos en el tema y a descubrir los métodos empleados en la clasificación de documentos automatizada.
Métodos de Clasificación de Documentos Automatizada con Machine Learning
Métodos de Clasificación de Documentos Automatizada con Machine Learning
La clasificación de documentos automatizada se consigue mediante machine learning. Emplea principalmente la NLP, que requiere grandes cantidades de datos para ser entrenada, con el fin de detectar y definir patrones en los documentos con alta precisión.
Para entrenar el modelo, se le introducen datos preexistentes, que ya se benefician de categorías y conjuntos de características predeterminados. Esto permite al modelo aprender conexiones estadísticas entre palabras y frases.
Los clasificadores de Machine Learning reúnen conjuntos de datos de entrenamiento, por ejemplo, artículos, ensayos o cualquier tipo de texto que pueda utilizarse para extraer palabras clave y definir categorías con las que el modelo pueda aprender. Sin embargo, existen múltiples métodos para clasificar documentos mediante machine learning, que cubriremos en la siguiente sección.
Clasificación de Documentos Supervisada
En la clasificación de documentos supervisada, tú mismo proporcionas la entrada, es decir, entrenas el modelo con documentos que ya tienen una etiqueta. Por lo tanto, la clasificación se realiza evaluando la relación entre el nuevo documento y los datos históricos etiquetados.
Por ejemplo, el modelo se entrena con facturas, recibos y extractos bancarios. El modelo hará un gran trabajo reconociendo y clasificando estos tipos de documentos. Pero si haces que el modelo clasifique documentos de identidad, el resultado será un intento fallido. El modelo no podría encontrar una relación entre los nuevos documentos, es decir, documentos de identidad, y los datos históricos etiquetados, como facturas o recibos, por lo que la clasificación termina siendo inexacta.
Ventajas
- Es una clasificación de documentos precisa
- Es fácil evaluar sus resultados
Desventajas
- Requiere un gran conjunto de datos de entrenamiento
- Puede llevar mucho tiempo y resultar caro clasificar una gran cantidad de datos o el conjunto de entrenamiento
Clasificación de Documentos sin Supervisión
La clasificación de documentos sin supervisión no requiere un conjunto de datos de entrenamiento con el que aprender. Su objetivo es clasificar documentos analizando su contenido y encontrando diferencias entre ellos. A continuación, el modelo crea grupos, o categorías, en los que se colocan los documentos clasificados. Aunque algunos documentos pueden compartir similitudes, las categorías son desconocidas para el modelo, lo que deja espacio para la incertidumbre en la calidad de la clasificación.
Ventajas
- No requiere un conjunto de datos de entrenamiento etiquetados.
- Su uso es más rápido y económico, ya que la clasificación no es necesaria.
Desventajas
- Es más difícil de evaluar
- Es menos preciso que el método supervisado
Clasificación de Documentos Semi-supervisada
La clasificación de documentos semi-supervisada consiste en una combinación entre las clasificaciones supervisada y no supervisada. Utiliza conjuntos de datos de entrenamiento etiquetados y no etiquetados, mejorando el rendimiento de ambos métodos de clasificación, pero sin perfeccionar ninguno.
Ventajas
- Mejora la precisión de ambos métodos de clasificación
- No requiere tantos datos de entrenamiento como la clasificación supervisada
Desventajas
- Es más difícil de implementar que el método supervisado y el no supervisado.
- Puede ser menos preciso que una clasificación completamente supervisada
Ahora que ya conocemos los distintos métodos de clasificación que utilizan el machine learning, veamos cómo es en realidad el proceso de automatización de la clasificación de documentos.
¿Cómo Clasificar Documentos Automáticamente?
La clasificación de documentos automática utiliza métodos de deep learning (un subgrupo de Machine Learning) para clasificar archivos en varias categorías, sin ninguna intervención humana. Para ello, se sigue un proceso sencillo de tres pasos, que es el siguiente:
- Reúne un conjunto de datos: Para entrenar al modelo de clasificación, primero hay que preparar los datos. Esto significa reunir al menos 20 puntos de datos por etiqueta, es decir, 20 documentos por categoría. Esto aumenta la precisión de la salida, dándote un resultado final cualitativo. El algoritmo categoriza el resultado basándose en los datos específicos con los que se ha entrenado. Por ejemplo, si sólo quieres clasificar facturas, lo lógico sería entrenar el modelo con varias facturas. Sin embargo, si quieres clasificar un tipo de documento diferente, por ejemplo, un recibo, el modelo podría tener dificultades para clasificar con precisión los documentos deseados.
- Entrena el modelo: Este paso puede llegar a ser largo y costoso, dependiendo del método de clasificación que elijas, es decir, supervisado, no supervisado o semi-supervisado. Aunque en realidad es una tarea redundante, es necesaria para obtener los resultados más precisos.
- Evalúa los resultados: Comparar los resultados con las expectativas es una práctica esencial para garantizar que el modelo funciona según lo previsto. Esto puede hacerse comparando los resultados de la clasificación con un documento ya predefinido, lo que garantiza una representación exacta en la comparación.
Para comprender realmente este proceso, es necesario tomarse todo el tiempo que sea necesario. Apurarte para introducir datos inexactos en el modelo o no introducir suficientes puntos de datos sólo te complicará la vida a largo plazo. Tomarte el tiempo necesario y comprender realmente este proceso te permitirá obtener los mejores resultados en la clasificación de documentos.
Entendemos que no estés del todo seguro de si aplicar la clasificación de datos automática es beneficioso o no para las necesidades de tu empresa. Por lo tanto, déjanos iluminar algunas de las ventajas que la clasificación de documentos automática puede aportar para tu empresa.
Ventajas de la Clasificación de Documentos para las Empresas
La clasificación de documentos automática permite que tu organización lleve a cabo los procesos empresariales cotidianos con mayor fluidez. Algunas de las ventajas de implementar esta práctica son:
- Le ahorra tiempo y recursos a tu empresa: La clasificación de documentos automática organiza y analiza grandes cantidades de documentos, ahorrándote una cantidad significativa de tiempo y recursos financieros.
- Te ayuda a identificar documentos fraudulentos: Clasificar documentos automáticamente también significa identificar documentos fraudulentos a través de anomalías o errores humanos presentes en estos archivos. La automatización ayuda, por tanto, a reducir el fraude documental en tu organización, como el fraude de facturas.
- Ayuda a automatizar el ordenamiento de documentos: La clasificación manual de los documentos puede llegar a ser confusa fácilmente, haciéndote dudar sobre qué etiqueta darles, dando lugar a errores y a una toma de decisiones inexacta. La clasificación automática resuelve este problema, ordenando los documentos en función de categorías predeterminadas por ti y tu equipo.
Puede que estas ventajas no parezcan impactantes al principio, pero pueden suponer una gran diferencia en la forma en que diriges tu negocio. Para poder entender este asunto y ver el panorama general, vamos a discutir algunos casos de uso de la clasificación automática de documentos en la vida real.
Casos de Uso y Aplicaciones de la Clasificación de Documentos
Conocer la teoría en la que se basa la clasificación de documentos no basta para realmente comprender su uso. Déjanos presentarte algunos casos de uso en los que la clasificación de documentos automatizada tiene un impacto positivo en tu negocio:
- Detección de spam en correos electrónicos: La clasificación de documentos automatizada ayuda a identificar los correos electrónicos que entran en la categoría de spam. Suelen incluir texto que no suena natural, errores gramaticales o faltas de ortografía, que levantan sospechas en comparación con los correos electrónicos normales. Mediante la clasificación de documentos, los correos electrónicos que marcan estas casillas se guardan en la bandeja de entrada de spam correspondiente, manteniendo a tu empresa libre de enlaces peligrosos o correspondencia no solicitada.
- Procesamiento de los comentarios de los clientes: Analizando la semántica y el tono del texto, lo que descubrimos se hace utilizando NLP, se pueden separar los comentarios positivos de los constructivos. Por lo tanto, tu organización obtiene un mejor acceso a las sugerencias dirigidas a mejorar los procesos empresariales, lo que te ayuda a ofrecer mejores servicios a tus clientes.
- Facilitar la atención al cliente: Mediante la clasificación de documentos, los empleados de atención al cliente pueden separar fácilmente las reclamaciones, reembolsos, consultas u otros comentarios, basándose en el texto. Esto mejora la eficacia del flujo de trabajo, al enviar los comentarios correspondientes a los departamentos designados.
- Digitalización de documentos: Es posible que tu empresa maneje varios tipos de documentos, por ejemplo, facturas, recibos o contratos. Si utilizas un software de digitalización de documentos para escanearlos, digitalizarlos y clasificarlos, tus procesos se agilizarán considerablemente.
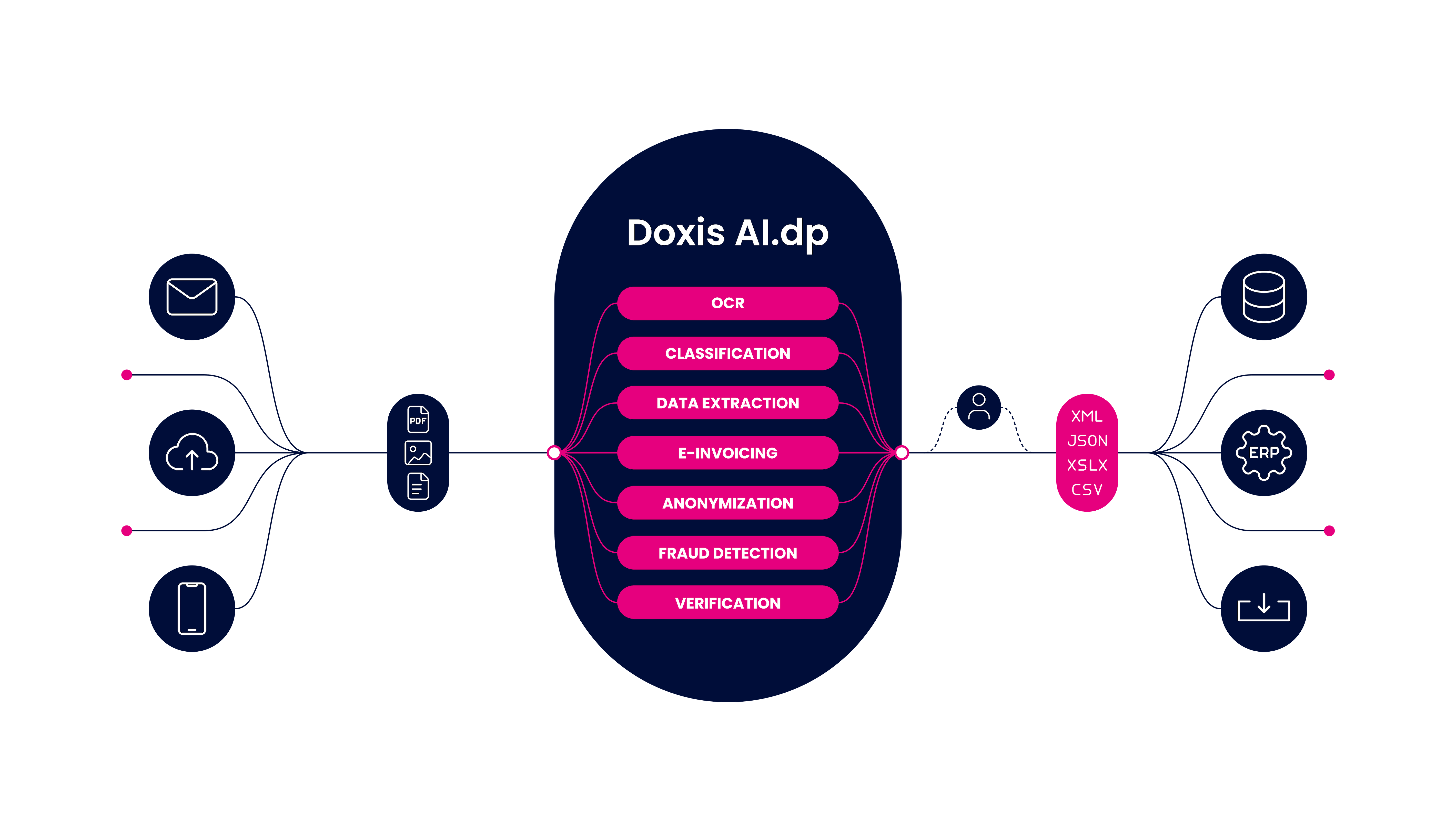
Tu empresa se merece un software que haga posibles todos los casos de uso anteriores, y más. Así es Doxis AI.dp, que te ayuda a automatizar cualquier flujo de trabajo de procesamiento de documentos, incluida la clasificación de documentos, ofreciendo a tu organización beneficios inigualables.
Ve Más Allá de la Clasificación de Documentos Automatizada con Doxis
Doxis AI.dp es una solución de procesamiento inteligente de documentos impulsada por IA, destinada a agilizar las operaciones empresariales diarias a escala. No solo te ayuda a conseguir una clasificación de documentos precisa, sino que también ayuda a tu empresa en otras áreas:
- Captura datos de múltiples tipos de documentos mediante OCR de alta precisión
- Automáticamente anonimiza datos e imágenes para el máximo cumplimiento de las regulaciones de privacidad
- Convierte documentos al formato deseado, como CSV, XML, JSON o PDF
- Una integración perfecta con las soluciones de software existentes a través de SDK o API
- Previene el fraude en tu organización con la verificación de documentos automatizada
- Clasifica y categoriza múltiples tipos de documentos
- Procesa documentos en función a campos de datos específicos
Con Doxis AI.dp, tu negocio está preparado para el éxito. Si estás interesado en obtener más información sobre nuestro producto, ponte en contacto con nuestros expertos o reserva una demostración a continuación.