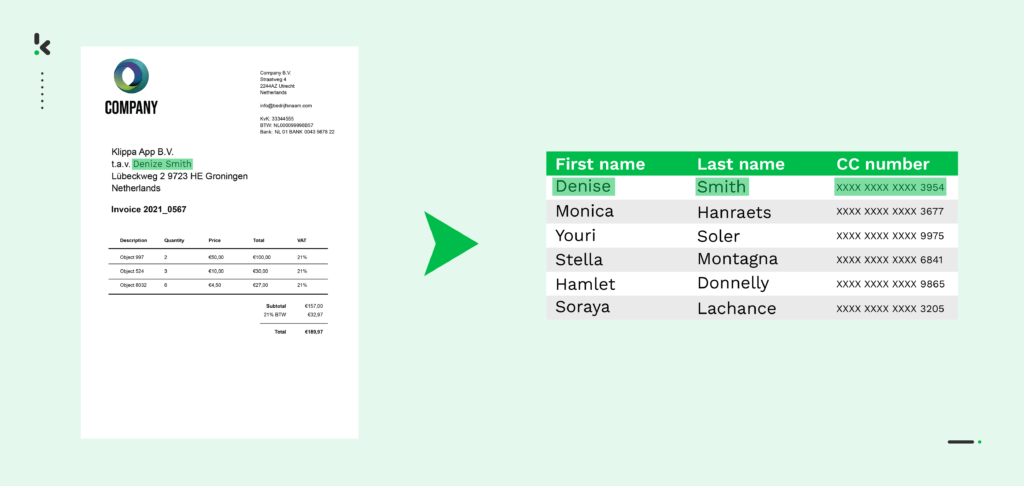
Probablemente no sea nuevo para ti que los datos se consideran el “oro de los tiempos modernos”. Aunque todo el mundo es consciente de la importancia de los datos, todavía hay muchas empresas que no se basan en ellos o que no pueden aprovecharlos. Las razones varían, pero a menudo se debe a que los datos no están bien almacenados, estructurados o incluso no tienen capacidad de búsqueda para ser utilizados.
Aunque los datos estén almacenados, las empresas pueden almacenarlos más de una vez o de forma imprecisa debido a errores humanos. Esto, por supuesto, conduce a una mala calidad de los datos, lo que puede perjudicar seriamente a las organizaciones. De hecho, se ha afirmado que los datos inexactos hacen perder a las empresas un promedio de 15 millones de dólares al año.
Para hacer frente a los retos relacionados con los datos, las organizaciones pueden recurrir a soluciones automatizadas capaces de cotejar datos de dos fuentes de datos diferentes. Con una solución de este tipo, se pueden eliminar fácilmente los datos duplicados y las imprecisiones. Aquí es donde entra en juego la concordancia parcial.
Para entender este concepto técnico, nos tomaremos el tiempo de explicar qué es, por qué es necesario para las organizaciones modernas y cómo se puede implementar.
¡Comencemos!
¿Qué es la coincidencia parcial?
La Coincidencia Parcial (CP), también conocida como coincidencia aproximada de cadenas o fuzzy matching, es una técnica que ayuda a los usuarios a comparar y encontrar una coincidencia aproximada entre dos secciones de datos diferentes o incluso una línea de texto. Esta técnica suele ser posible gracias a tecnologías como la Inteligencia Artificial (IA) y el Machine Learning (ML).
Técnicamente, la Coincidencia Parcial se utiliza como un algoritmo de coincidencia de cadenas (un algoritmo que busca una cadena dentro de otra cadena) con reglas predeterminadas para encontrar cadenas, palabras o entradas duplicadas que sean las más coincidentes entre sí. Con el uso de la Coincidencia Parcial, es posible encontrar nombres, palabras o cadenas abreviadas, acortadas o mal escritas, por ejemplo.
Supongamos que quieres encontrar el “número de factura” en un documento, pero la palabra está mal escrita “númeor de factura” o abreviada como “nmr de factura”. En este caso, no obtendrás una coincidencia exacta al buscar “número de factura”, por lo que no podrás encontrar lo que buscas.

Con un algoritmo de Coincidencia Parcial, esto no es un problema, ya que el algoritmo todavía puede encontrar una coincidencia aproximada con la palabra que está mal escrita o acortada proporcionando una puntuación de coincidencia de 0-100% basada en las “correcciones de edición”. Una corrección de edición es una corrección que el algoritmo de CP tiene que hacer basándose en la lógica para ajustar una cadena determinada para que esa cadena coincida con otra.
Correcciones de edición de la Coincidencia Parcial
En general, los algoritmos de CP utilizan las siguientes correcciones de edición:
- Inserción – añadir una letra para completar la palabra (por ejemplo, “factur” se convierte en “factura“)
- Eliminación – quitar una letra de una palabra (por ejemplo, “facturaa” se convierte en “factura”).
- Sustitución – cambiar una letra para corregir una palabra (por ejemplo, “facturi” se convierte en “factura“).
- Transposición – cambiar letras para corregir una palabra (por ejemplo, “factrua” se convierte en “factura”).
Cada corrección que haya que realizar atribuirá una “distancia de edición” de 1. Las distancias de edición influyen en la puntuación de coincidencia mencionada anteriormente. Por ejemplo, si tienes una cadena con 11 caracteres y tuvieras que hacer 2 correcciones, entonces la puntuación final de coincidencia sería igual a 81.81%.
Cálculo: 100%- 2 / 11= 81.81%
Además de estas correcciones, CP puede utilizarse para corregir la puntuación, las palabras sobrantes y los espacios que faltan en cadenas o textos.
Para entender mejor cómo funciona la Coincidencia Parcial y cómo se calculan las distancias de edición, la siguiente sección está dedicada a explicar en detalle varios algoritmos de la Coincidencia Parcial.
Algoritmos de Coincidencia Parcial
Las Coincidencias Parciales caen en la categoría de métodos que no tienen un algoritmo específico que cubra todos los escenarios y casos de uso. Por lo tanto, cubriremos algunos de los algoritmos de Coincidencias Parciales más comúnmente usados y confiables para encontrar coincidencias aproximadas de datos:
- Distancia Levenshtein (LD)
- Distancia Hamming (DH)
- Damerau-Levenshtein
Distancia Levenshtein
La Distancia Levenshtein (DL) es una técnica de Coincidencia Parcial que tiene en cuenta dos cadenas a la hora de compararlas y encontrar una coincidencia. Cuanto mayor sea el valor de la Distancia de Levenshtein, más lejos estarán las dos cadenas o “términos” de una coincidencia idéntica.
Entonces, ¿cómo obtenemos el valor de la Distancia de Levenshtein? La DL entre las dos cadenas es igual al número de ediciones necesarias para convertir una cadena en la otra. Para la DL, la inserción, la eliminación y la sustitución de un solo carácter se aplican como operaciones de edición.
Supongamos que quieres medir la DL entre “número de factura” y “nmro de factura”. La distancia entre los dos términos es “1 x u” y “1 x e”, lo que equivaldría a una distancia de 2. ¿Por qué? Porque habría que añadir estos dos caracteres para que coincidieran exactamente. Mira el siguiente ejemplo.
Ejemplo de Distancia Levenshtein
- Número de fatura → Número de factura (inserción de “c“) – Distancia: 1
- Numr de factura → Número de factura (inserción de “e” y “o“) – Distancia: 2
- Nr de factura → Número de factura (inserción de “u,m,e,o“) – Distancia: 4
Distancia Hamming
La Distancia Hamming (DH) no es muy diferente de la Levenshtein. La distancia Hamming se utiliza a menudo para calcular la distancia entre dos cadenas de texto que tienen la misma longitud.
El método DH se basa en la tabla ASCII (American Standard Code for Information Interchange). Para calcular la puntuación de la distancia, el algoritmo de la Distancia de Hamming utiliza la tabla para determinar el código binario asociado a cada letra de las cadenas.
Ejemplo de Distancia Hamming
Tomemos como ejemplo las siguientes cadenas textuales “número” y “lúmero”. Cuando intentamos determinar la DH entre las cadenas, la distancia no es 1 como sería con el algoritmo de Levenshtein. En su lugar, sería 10. Esto se debe a que la tabla ASCII muestra un código binario de (1001110) para la letra N y (1001100) para la letra L.
Ejemplo de cálculo:
D = N – L = 1001110 – 1001100 = 10
Damerau-Levenshtein
El Damerau-Levenshtein también mide la distancia entre dos palabras midiendo los cambios necesarios para ajustar una palabra en la otra. Estos cambios dependen del número de operaciones, como inserciones, eliminaciones o sustituciones de un solo carácter, o la transposición de dos caracteres adyacentes.
Aquí es donde la distancia Damerau-Levenshtein difiere de la distancia Levenshtein normal, ya que incluye transposiciones además de las operaciones de edición de un solo carácter para encontrar una coincidencia aproximada (Fuzzy Match).
Ejemplo Damerau-Levenshtein
Cadena 1: Factura
Cadena 2: Fatcur
Operación 1: transposición -> intercambiar los caracteres “t” y “c”.
Operación 2: insertar “a” al final de la cadena 2
Como se necesitaron dos operaciones para que las dos cadenas fueran idénticas, la distancia es igual a 2. En pocas palabras, cada operación, como inserción, eliminación, transposición, etc., cuenta como una distancia de “1”. Sin embargo, con la distancia Levenshtein, necesitaría realizar tres correcciones de edición, lo que equivaldría a la distancia de 3.
Evidentemente, todos los algoritmos de Coincidencia Parcial mencionados difieren entre sí en la forma de calcular la distancia de edición. Esta es la razón por la que no existe un algoritmo CP que se adapte a todos los tamaños. Sin embargo, la distancia Levenshtein es el algoritmo de CP más utilizado en la gestión de datos y la ciencia de datos, entre los tres que se presentaron.
Casos de uso de la Coincidencia Parcial
Existen múltiples formas de utilizar CP en aplicaciones reales, y algunas de ellas aparecen en su vida cotidiana. Veamos algunos ejemplos a continuación (la lista no es exhaustiva):
- Extracción de Datos de Documentos
- Sugerencia Automática con Corrector Ortográfico
- Deduplicación
- Secuencia del Genoma
Extracción de Datos de Documentos
Aunque el OCR, también conocido como tecnología de extracción de imagen a texto, está más avanzado que hace 10 o incluso 20 años, todavía puede producir resultados de extracción de datos inexactos. Dado que muchas empresas manejan una amplia gama de documentos en grandes volúmenes, los resultados imprecisos de la extracción de datos pueden hacerles perder importantes cantidades de dinero.
Para complementar el software de OCR y ayudar a resolver este problema, se puede aplicar la Coincidencia Parcial. En los casos en los que el OCR no encuentra una “coincidencia exacta” al extraer determinados campos de datos y datos de los documentos, la Coincidencia Parcial puede ayudar a encontrar la coincidencia más cercana con una coincidencia de cadenas aproximada utilizando la Distancia de Levenshtein.
De este modo, las empresas pueden seguir extrayendo datos de los documentos en lugar de que el software de OCR no produzca ningún resultado cuando no se encuentra una coincidencia exacta.
Sugerencia Automática con Corrector Ortográfico
Es probable que hayas encontrado o utilizado varios motores de búsqueda a lo largo de tu vida. Al hacerlo, también habrás notado cómo a veces los motores de búsqueda nos proporcionan el contenido que buscamos a pesar de las palabras o frases mal escritas.
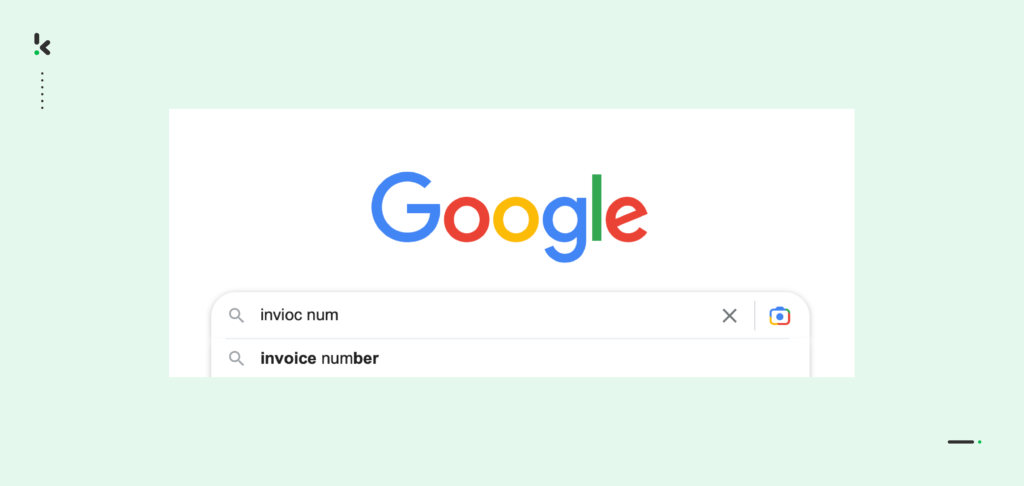
Esto sólo ocurre porque los motores de búsqueda como Google utilizan algoritmos de Coincidencia Parcial. Google entiende lo que quieres escribir como consulta principal y te ofrece una opción para la palabra de búsqueda mientras escribes en la barra de búsqueda.
Junto con la IA o el ML, la Coincidencia Parcial ha ayudado a mejorar motores de búsqueda como Google y YouTube para mejorar la experiencia de búsqueda.
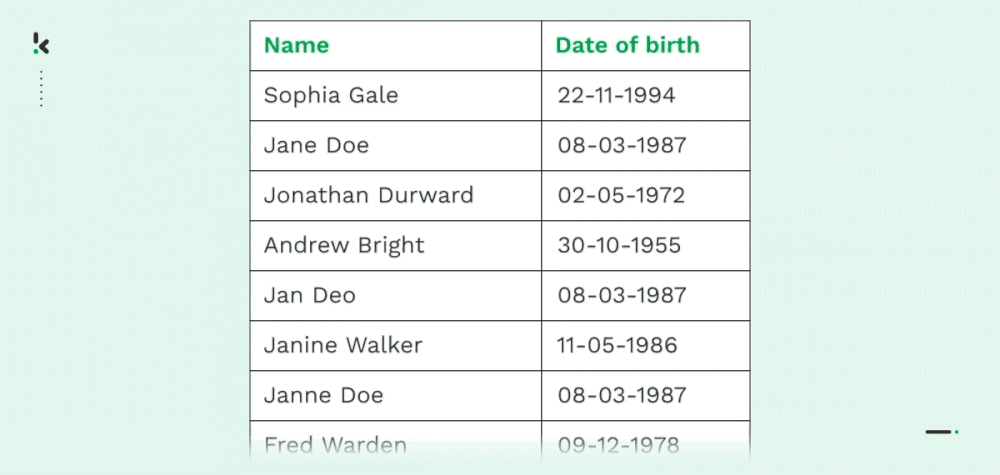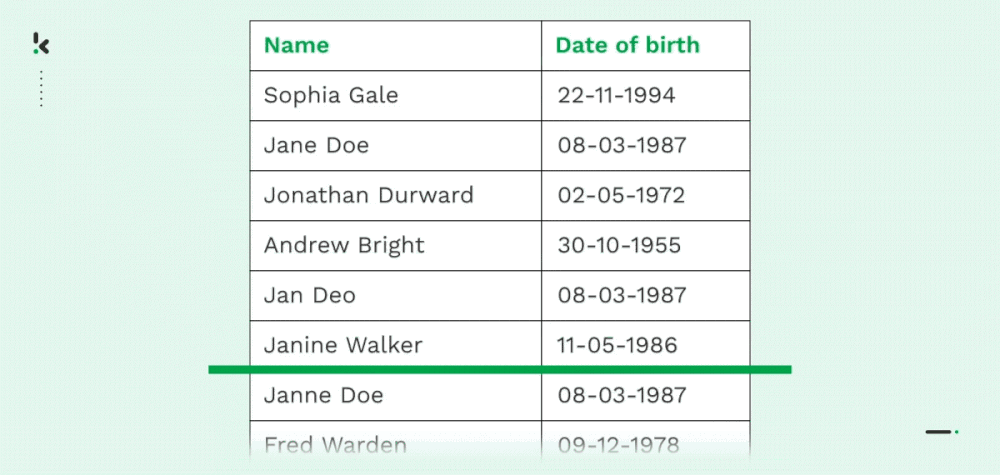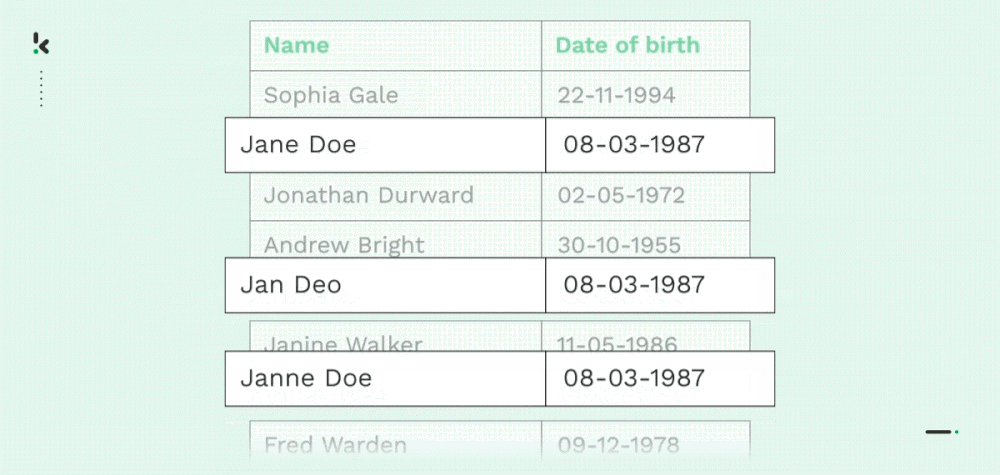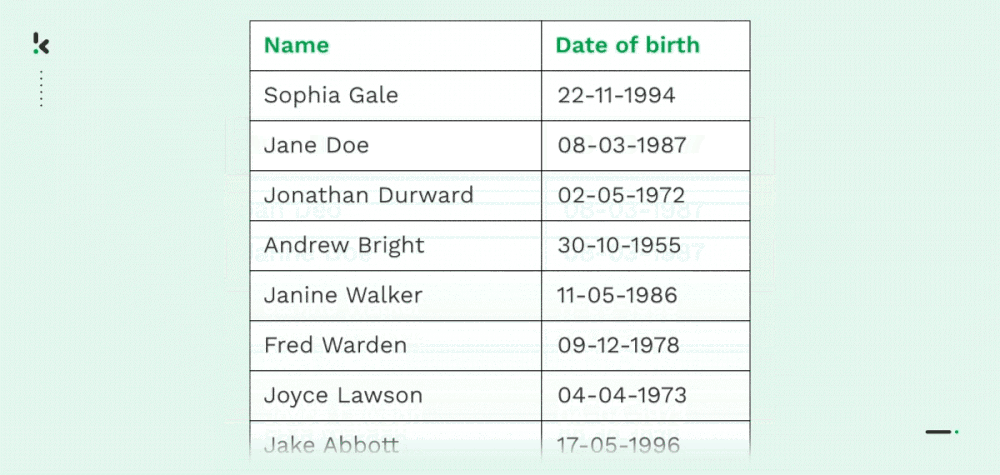
Deduplicación
Como ya se ha mencionado, numerosas empresas sufren duplicidad de datos, principalmente debido a transferencias de datos, falta de control o errores en la introducción de datos. Tanto las copias al carbón de un registro (nombre, dirección, correo electrónico, número de teléfono, etc.) como los duplicados parciales son habituales en las organizaciones.
Con la Coincidencia Parcial, las organizaciones pueden fusionar, eliminar o reorganizar datos encontrando coincidencias aproximadas. Esto permite a las organizaciones racionalizar sus registros y la gestión de datos, lo que conlleva varias ventajas que se comentan más adelante en este blog.
La deduplicación también es muy útil cuando se entrenan modelos de OCR para extraer información de documentos. Al eliminar las muestras de datos duplicados de los conjuntos de datos de entrenamiento, el entrenamiento se vuelve más eficiente y la precisión de predicción de los modelos OCR mejora significativamente.
Secuencia del Genoma
En el campo médico y científico, la Coincidencia Parcial puede ser muy útil, sobre todo en la secuenciación del genoma. Permite que los investigadores encuentren una coincidencia aproximada con una secuencia genómica concreta ejecutando un algoritmo en la secuencia.
Con el algoritmo de Coincidencia Parcial, son capaces de encontrar la secuencia o conjunto de secuencias que más se aproxima para determinar a qué organismo pertenece la secuencia en función del resultado. Un ejemplo sería encontrar la coincidencia más cercana a una determinada bacteria o virus para encontrar la cura adecuada.
En otras palabras, la Coincidencia Parcial puede ayudar a los investigadores a encontrar una cura para ciertas enfermedades. Interesante, ¿verdad?
A estas alturas, debería estar claro que el uso de la CP es flexible y se puede aplicar en varios casos de uso. Cualquiera que sea tu caso de uso, hay varios beneficios que la Coincidencia Parcial trae consigo.
Los beneficios de las Coincidencias Parciales
Los beneficios más comunes para las organizaciones que utilizan la Coincidencia Parcial como su enfoque para identificar coincidencias incluyen:
- Precisión de los Datos – Las organizaciones pueden lograr una alta precisión en la coincidencia de datos, ya que la CP tiene la capacidad de buscar coincidencias aproximadas mediante el análisis de las cadenas y el cálculo de la puntuación de distancia de “edición” utilizando algoritmos.
- Datos con Capacidad de Búsqueda – La Coincidencia Parcial le permite a los usuarios encontrar coincidencias a pesar de las variaciones debidas a errores como faltas de ortografía, mayúsculas o formato de palabras o cadenas.
- Flexibilidad – Hay muchas maneras en que los algoritmos pueden ayudar a resolver incluso los problemas más complejos.
- Base de Datos más Limpia – Los algoritmos de Coincidencias Parciales pueden ayudar a las organizaciones a encontrar registros de datos duplicados para obtener una base de datos más sana, limpia y precisa.
Desventajas de la Coincidencia Parcial
No todo en la coincidencia parcial de cadenas es perfecto. Por el contrario, CP viene con varias limitaciones incluyendo:
- Vinculación Incorrecta – A pesar de que la Coincidencia Parcial es excelente en la búsqueda de coincidencias aproximadas, a veces resulta en una gran cantidad de falsos positivos que conducen a vinculaciones incorrectas, especialmente con bases de datos más grandes.
- Requiere Mantenimiento – Los algoritmos deben ser constantemente probados y las reglas en ellos actualizadas con el fin de hacer coincidencias de cadenas con precisión.
Aunque existen desventajas, la utilización dela Coincidencia Parcial beneficia más a las empresas en lugar de crear desafíos. Entonces, ¿cómo puedes implementarlo en tus propias soluciones? Veámoslo a continuación.
Implementación de la Coincidencia Parcial
Puedes implementar algoritmos de Coincidencia Parcial usando varios lenguajes de programación incluyendo:
- Python – La librería Fuzzywuzzy Python aplica el enfoque de la Distancia Levenshtein para realizar el emparejamiento aproximado de cadenas.
- Java – Es muy difícil implementar CP en Java, sin embargo, se hace a través de un repositorio GitHub para implementar la librería Fuzzywuzzy en Java.
- Excel – Fácil de implementar la CP a través de complementos como Exis Echo, Fuzzy Lookup e incluso utilizando la función nativa VLOOKUP.
Por supuesto, construir tus propias soluciones para encontrar coincidencias aproximadas de cadenas es posible, pero lleva tiempo y requiere recursos. A menudo es mejor adquirir una solución que utilice algoritmos de Coincidencia Parcial para apoyar tu caso de negocio.
Si tienes curiosidad por saber cómo usamos en Klippa la Coincidencia Parcial en nuestras soluciones, ¡sigue leyendo!
¿Cómo utiliza Klippa la Coincidencia Parcial?
Muchos programas de OCR como Klippa DocHorizon se centran principalmente en encontrar una coincidencia exacta en los campos de datos para la extracción de datos. Sin embargo, no todos los software de OCR pueden encontrar siempre coincidencias exactas al extraer datos debido a diversas razones como el uso de abreviaturas, palabras acortadas, etc. Por eso es importante utilizar la Coincidencia Parcial para garantizar que se puedan extraer datos relevantes de los documentos.
En este sentido, Klippa utiliza la Distancia Levenshtein para encontrar coincidencias aproximadas y asegurarse de que se extraen todos los datos relevantes. Una vez finalizada la extracción de datos, la salida de datos se proporciona en formato JSON con una puntuación de coincidencia. Con la puntuación de coincidencia, los clientes de Klippa pueden determinar si necesitan que una persona verifique los resultados para evitar obtener resultados inexactos.
Además de la extracción de datos, Klippa utiliza la Coincidencia Parcial para eliminar los datos duplicados de los conjuntos de datos para entrenar los modelos de OCR. De esta forma, el proceso de entrenamiento es más eficiente y aporta mejores resultados de mejora, ya que no se pierde tiempo y se reducen las posibilidades de falsos positivos (en los resultados de extracción y reconocimiento de datos).
¿Estás interesado en utilizar la Coincidencia Parcial para mejorar la extracción de datos o la gestión de datos de tu organización? No dudes en programar una demostración a través del siguiente formulario para ver cómo funciona nuestra solución con Coincidencia Parcial. Si quieres realizar una consulta u obtener más información, ponte en contacto con uno de nuestros expertos.