
Según el Centro de Recursos contra el Robo, sólo en 2021 se registraron 1.862 filtraciones de datos. Esto supone un aumento del 68% en comparación con el año pasado. Este es un hecho bastante impactante, ya que cada vez hay más datos almacenados y disponibles en sistemas basados en la nube.
Como organización, naturalmente no quieres que los datos sensibles acaben en manos de la persona equivocada. Una de las mejores estrategias para limitar los riesgos al compartir o almacenar datos en línea, es eliminar la mayor cantidad de información sensible posible. Cada fragmento de información que elimines estará reduciendo directamente el riesgo general.
¿Significa eso que tienes que comprobar todos los documentos en busca de información sensible y eliminarla manualmente? Por suerte, no. Puedes implementar soluciones inteligentes que encuentren y eliminen automáticamente la información sensible de los documentos.
Pero, ¿qué se define realmente como información sensible y cómo funciona exactamente la redacción de la información sensible? ¿Puede un software facilitar el proceso?
En este blog, responderemos a las preguntas mencionadas, presentaremos ejemplos relevantes y te mostraremos qué beneficios aporta un sistema automatizado a tu organización.
¿Qué es la información sensible?
Empecemos definiendo la información sensible. La información sensible es información que debe ser protegida de la vista. Es información confidencial, privada o secreta que sólo debe ser accesible por determinadas personas. Que la información sea sensible depende del público al que se revele y del contexto legal de una organización y un país.
En Europa, la información sensible se define en gran medida por la normativa GDPR, mientras que en Estados Unidos la mayoría de las organizaciones deben cumplir con la Legislación de Privacidad del Consumidor de California (CCPA).
La información sensible puede encontrarse en documentos almacenados y organizados de forma impresa o digital, como por ejemplo una foto y un nombre en un CV. En este blog, nos centraremos en la información que se almacena digitalmente.

¿Qué tipos de datos hay que eliminar?
Para iniciar el proceso de búsqueda y eliminación de datos sensibles, una organización necesita definir qué tipos de información suelen compartir los clientes y los empleados, cuáles de ellos son realmente necesarios y cuáles deben eliminarse.
En general, hay cuatro tipos de datos que requieren ser protegidos para evitar el acceso por parte de personas no autorizadas:
- Información de identificación personal: Se trata de cualquier dato que pueda utilizarse para identificar a una persona específica. Información como el nombre completo, el número de seguridad social, el número de la licencia de conducir o el número del pasaporte.

- Información de salud confidencial: Esta información incluye el historial médico, la información demográfica, los resultados de pruebas y análisis, los diagnósticos de enfermedades psiquiatricas, la información del seguro y otros datos personales de salud.

- Información sobre tarjetas de pago: Todas las organizaciones deben seguir la norma de seguridad de información que se aplica cuando se procesan tarjetas de crédito. Aquí, la información sensible se describe como el número de la tarjeta de crédito, el nombre del titular o la fecha de caducidad. Esto puede ser específicamente relevante para las normas PCI/DSS.

- Propiedad intelectual: La información de propiedad intelectual se refiere a las creaciones como inventos, diseños, obras literarias y artísticas, o nombres e imágenes utilizadas en los negocios. En este caso, la información no suele ser redactada, pero el trabajo lleva una marca de agua para indicar al propietario correspondiente.

En este tipo de datos, los siguientes campos se clasifican normalmente como información sensible. Estos pueden ser identificados y eliminados:
- Nombre
- Dirección
- Fecha de nacimiento
- Edad
- Número de cuenta bancaria
- Número de tarjeta de crédito
- Número de seguro social
- Historial laboral y educativo
- Foto
- Firma
Por supuesto, no toda la información mencionada anteriormente se aplica a tu organización, ya que esto difiere para cada industria. Pero ahora que tienes una idea general de la información que debes buscar, tienes una buena base para los siguientes pasos.
¿Por qué debe eliminarse la información sensible de una base de datos?
Hay varias razones por las que una organización debe eliminar la información sensible de su base de datos. No sólo deberías proteger los datos sensibles porque es un requisito legal en tu sector, sino también por respeto a tus clientes y otras personas privadas.
Estas son las 4 razones principales por las que una organización debe eliminar la información sensible:
- Para garantizar el seguimiento de la ley
- Minimizar los riesgos de seguridad
- Obligaciones legales
- Requisitos de los seguros
Los riesgos de las filtraciones de datos son reales y no deben subestimarse. Para evitar daños graves a tu organización y a todos los implicados, debes asegurarte de contar con una buena protección. Esto implica la eliminación de información sensible de los documentos.
Además, la redacción de la información puede garantizar el cumplimiento de los requisitos del GDPR de tu país o empresa.
En la UE, estos reglamentos son bastante estrictos e implican, por ejemplo, el procesado legal, justo y transparente de la información y la limitación del almacenamiento y la transferencia de datos. Es importante cumplir con los requisitos indicados si quieres almacenar tus datos en un servidor Europeo.
Antes de pasar a la siguiente parte, queremos aclarar algunos términos técnicos y responder a la pregunta:
¿Cómo se llama cuando se elimina la información sensible de un documento?
En pocas palabras: se llama enmascaramiento de datos. También se conoce como redacción de datos, anonimización de datos y ofuscación de datos.
El enmascaramiento de datos se puede utilizar de varias maneras, como en la sustitución, el barajado, el promediado, la anulación, la redacción de datos, la codificación de datos y la encriptación de datos.
Aquí no queremos entrar en detalles sobre cada técnica, pero si estás interesado en aprender más, deberías leer nuestra guía definitiva de enmascaramiento de datos.
Si aún no estás familiarizado con la tecnología de enmascaramiento de datos, puedes seguir leyendo este blog, ya que en la siguiente sección explicaremos la tecnología que permite eliminar automáticamente los datos sensibles de los documentos.
¿Cómo eliminar automáticamente los datos sensibles de los documentos?
Si sólo tienes unos cuantos archivos que necesitan la eliminación de datos sensibles, no hay problema en hacerlo manualmente. Sin embargo, en organizaciones más grandes, el volumen de documentos y datos suele ser muy elevado.
Esto hace que sea una tarea que requiere mucho tiempo para hacerla a mano. El costo y el tiempo invertido serían muy elevados, los tiempos de entrega largos y los errores frecuentes.
Por suerte, existe una alternativa a la anonimización manual de la información. En el proceso de búsqueda y eliminación de información sensible de los documentos, casi todos los pasos pueden ser automatizados y realizados por un software de procesamiento inteligente de documentos (IDP).
Una solución IDP como Klippa DocHorizon, por ejemplo, es capaz de revisar y redactar documentos en cuestión de segundos. En Klippa, ofrecemos varias opciones para encontrar y enmascarar automáticamente los datos sensibles, como por ejemplo:
- Enmascaramiento de datos totalmente automatizado con IA
- Automatización con ayuda humana
- Enmascaramiento de datos en el móvil
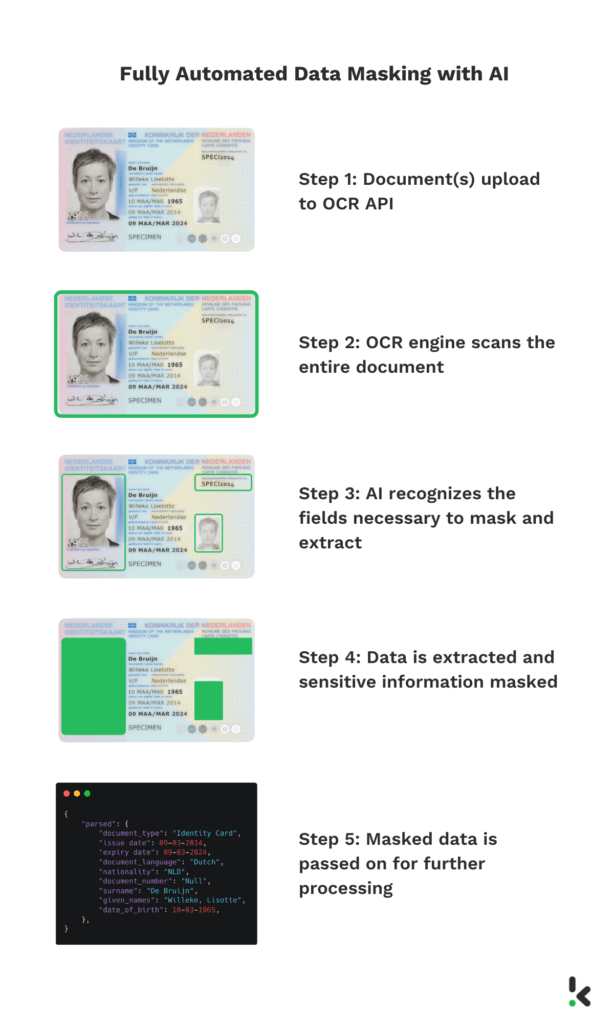
Enmascaramiento de datos totalmente automatizado con IA
Con una solución de enmascaramiento de datos totalmente automatizada, ya no son necesarias las intervenciones humanas. Klippa ha desarrollado la API DocHorizon que te permite reconocer, localizar y redactar automáticamente la información sensible de los documentos en un par de segundos.
Esto es posible gracias a la tecnología OCR potenciada por la IA, que ha sido entrenada con cientos de documentos para reconocer determinados campos y, por ejemplo, poner líneas negras a la información sensible.
El enmascaramiento de datos totalmente automatizado libera el tiempo de tus empleados y les permite utilizar sus habilidades para tareas complicadas. De este modo, la eficiencia de tu organización aumentará.
Automatización con ayuda humana
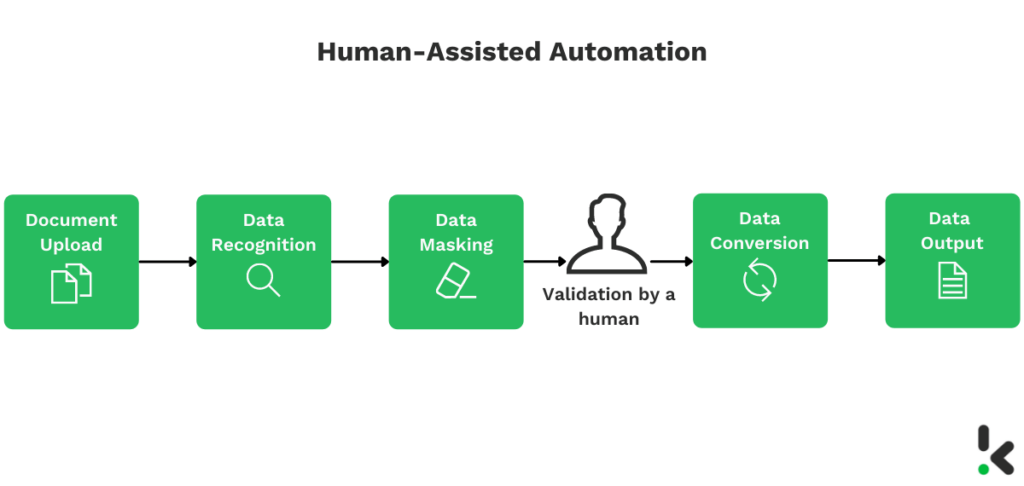
Si tu organización requiere una precisión del 100%, puede ser conveniente implementar la automatización asistida por humanos. Antes de almacenar los datos en la base de datos, un humano comprueba el documento enmascarado en lugar de que los datos se guarden automáticamente.
De este modo, se evitan los errores causados por la mala calidad de la imagen o del documento y se aumenta la precisión.
Esta solución combina lo mejor de la inteligencia artificial con lo mejor de la inteligencia humana, permitiendo que tu organización sea eficiente y eficaz.
Enmascaramiento de datos en el móvil (Solución semiautomática)
Si tienes una aplicación propia o quieres crear una, la forma más fácil de enriquecerla con capacidades de enmascaramiento de datos es integrar nuestro SDK de escáner móvil en la aplicación.
Nuestro SDK para escáner móvil incluye técnicas de enmascaramiento de datos que te ofrecen la solución para tomar una foto de un documento (por ejemplo, un documento de identidad, una factura o un pasaporte) y luego dibujar manualmente un recuadro negro que enmascare la información sensible. Esto garantiza que sólo se comparta y almacene la información necesaria.
Queremos que puedas tomar una decisión informada, por lo que a continuación te presentamos algunas ventajas de la eliminación automatizada y manual de información sensible.
¿Cuáles son las ventajas de la eliminación automatizada de datos sensibles?
¿Cuántos documentos procesas cada semana? ¿Cada mes? Quizá no todos ellos contengan datos sensibles que deban ser redactados. Pero imagínate el tiempo que podrías ahorrar si no tuvieras que revisar manualmente cada uno de los documentos. Otras ventajas son:
- Escaneo y extracción de datos en segundos
- Se limitan los errores
- Reducción del costo de la mano de obra, del tiempo de procesamiento y de los errores
- Escalabilidad
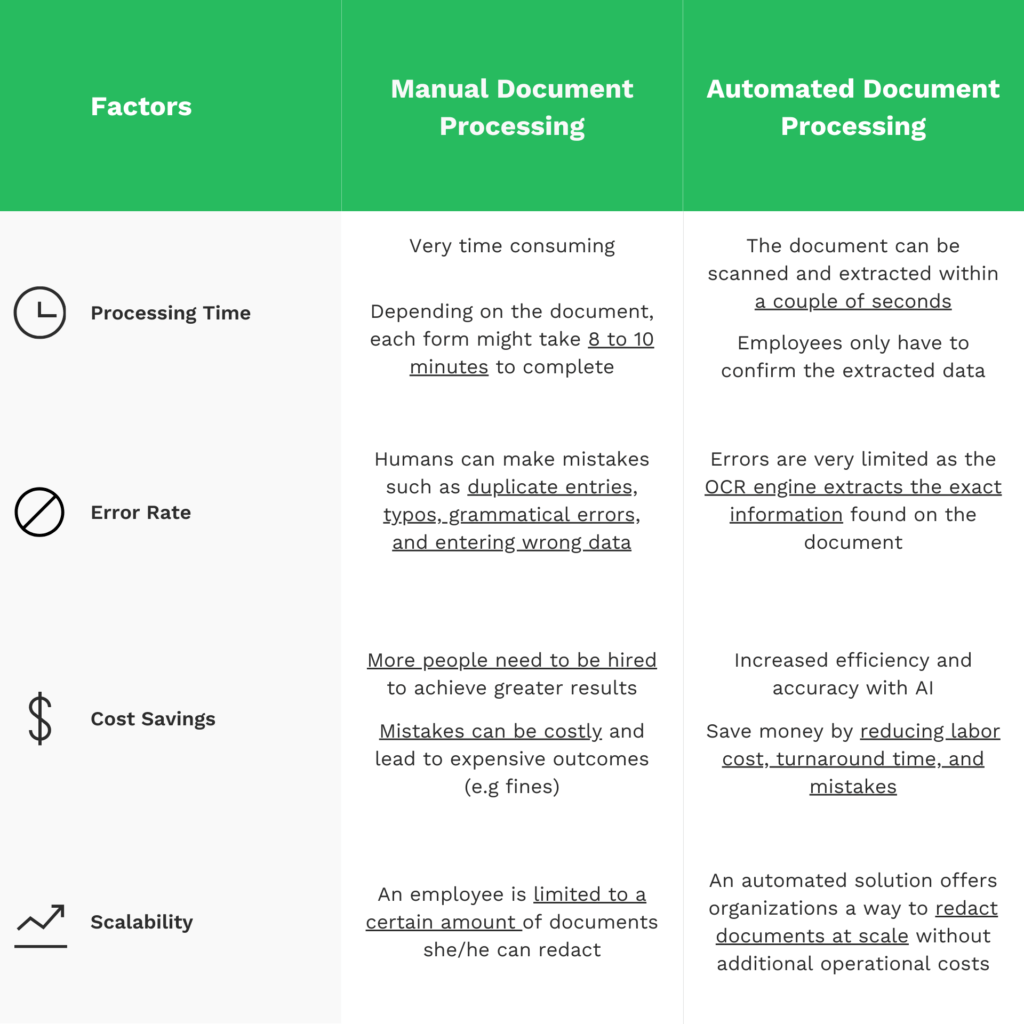
Hemos creado una tabla para visualizar y comparar el procesamiento de documentos manual y el automatizado. De este modo, puede resultarte más fácil ver las ventajas y desventajas de cada proceso.
¿Cuáles son los casos de uso más comunes para la redacción de datos sensibles?
En los siguientes párrafos, hablaremos de tres tipos diferentes de casos de uso:
- Documentos de identidad
- Historiales médicos de pacientes
- Documentos financieros
Anonimización de documentos de identidad
Uno de los casos de uso más comunes es la anonimización de copias de documentos de identidad. Información como el número del seguro social (SSN) en un pasaporte o documento de identidad es muy sensible y a menudo no se permite su almacenamiento en una base de datos.
Un SSN pertenece a “categorías especiales de datos personales” y está sujeto a normas estrictas según los requisitos del GDPR. Por lo general, solo las instituciones gubernamentales tienen permiso para almacenar los SSN en su base de datos, lo que significa que otras organizaciones deben encontrar formas de eliminar estos datos.
Una forma de redactar los SSN consiste en tachar automáticamente la información necesaria en la copia del documento con un software inteligente.
Restringir los historiales médicos de los pacientes
La información médica personal es sensible y debe ser protegida. Si los proveedores de servicios de salud y otras organizaciones que utilizan, manejan o transmiten información de los pacientes no cumplen con los requisitos del GDPR mencionados anteriormente, el resultado serán sanciones y multas.
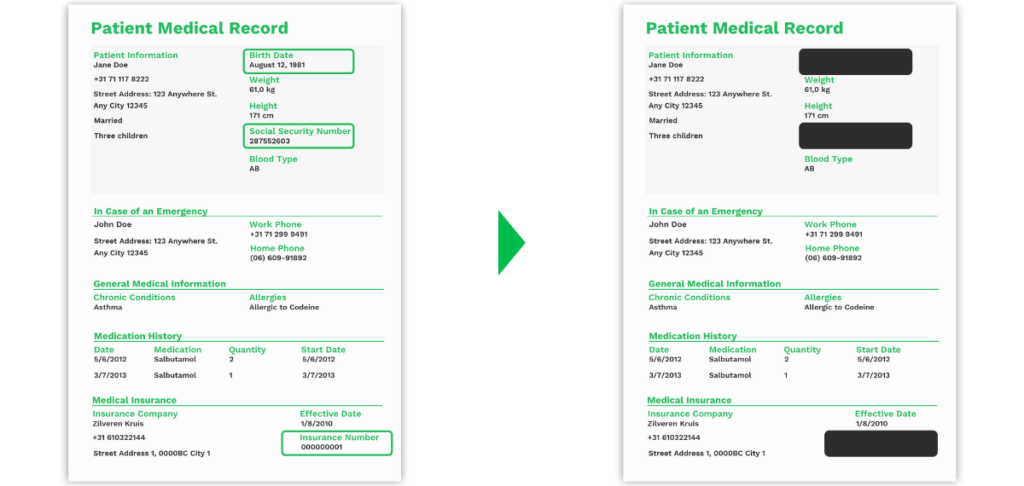
Un proveedor de servicios sanitarios tiene que procesar miles de documentos, y sería imposible revisarlos todos manualmente. En este caso, es crucial contar con un software que pueda encontrar y eliminar automáticamente la información sensible de, por ejemplo, los historiales médicos de los pacientes, para poder trabajar de forma eficaz y eficiente.
Los historiales médicos de los pacientes contienen información como la dirección, el número del seguro social y el número de seguro del paciente. No todo el mundo está autorizado a ver esta información, por lo que es importante enmascarar los datos. Ocultar la información con un software es una forma de redactar los datos de forma automática y proteger a los pacientes del fraude y las filtraciones de datos.
Enmascaramiento de documentos financieros
Las facturas, las copias de las tarjetas de crédito y los contratos son documentos que se procesan a diario en el sector financiero. Contienen información sensible que debe protegerse de personas no autorizadas.
El sector de los servicios financieros debe tener la intención de prevenir el fraude y garantizar el cumplimiento de las normas. En cuanto un instituto financiero no garantice el cumplimiento, el resultado podría ser un grave daño a la reputación, demandas judiciales o multas gubernamentales.
Si tomamos como ejemplo una factura, información como el nombre y la dirección de un cliente son datos que deben ser tachados. Utilizando esta técnica, se podría evitar el fraude mediante facturas duplicadas o falsas.
Revisar todos los documentos manualmente sería una tarea imposible. Por eso se han desarrollado soluciones documentales inteligentes, como Klippa, que te ayudan a automatizar el proceso.

Acabamos de describir tres casos de uso diferentes, pero lo mismo se aplica básicamente a cualquier tipo de documento o imagen. Si no hemos cubierto tu caso específico aquí, y te preguntas si también podemos ayudarte, puedes ponerte en contacto con nosotros para hacer preguntas y recibir más información.
Uso de Klippa para enmascarar datos
Klippa se especializa en muchas formas de automatización de documentos. Todos los ejemplos citados son casos que resolvemos a diario para clientes alrededor del mundo.
Con Klippa no sólo puedes encontrar y eliminar información sensible de los documentos. Puedes mejorar la calidad de tu trabajo administrativo, reducir los costos operativos y prevenir costosos errores.
Enmascarar tus datos con nuestra solución IDP, Klippa DocHorizon, hace que cumplir con el GDPR sea de lo más fácil. Además, Klippa le ofrecerá a tu organización los siguientes beneficios:
- Experiencia en muchos sectores
- Clientes internacionales de más de 30 países
- Cumplimiento del GDPR
- Opciones de alojamiento en varios países
- Anonimización de documentos en segundos
¿Suena esto como una solución que necesita tu organización? Déjanos ayudarte a llevar a tu empresa al siguiente nivel. Reserva una demostración gratuita a continuación para que puedas conocer nuestra solución, o ponte en contacto con uno de nuestros expertos para empezar. Nos encantaría trabajar contigo.