
La digitalización está en auge, ya que muchas empresas buscan mejores formas de procesar y almacenar documentos. Los archivos tradicionales se trasladan a la nube y cada vez se procesan más documentos en flujos de trabajo digitales.
Aunque la digitalización tiene fantásticas ventajas, hay que tener en cuenta algunos retos. El más importante es cumplir con el estricto Reglamento General de Privacidad de Datos (GDPR) impuesto en mayo de 2018.
Aunque esta normativa mejora la protección de los datos y aclara las responsabilidades de las organizaciones, no evita del todo las violaciones de datos.
De hecho, los costos resultantes de las violaciones de datos aumentaron de 3,86 millones de dólares a 4,24 millones de dólares, que es el costo total promedio más alto registrado visto en 17 años.
Como los ciberdelincuentes son cada vez más sofisticados, las empresas deben encontrar soluciones para proteger mejor los datos almacenados. Una excelente solución para minimizar los riesgos de violación de datos y garantizar el cumplimiento del GDPR es el enmascaramiento de datos.
Este blog cubrirá lo que es el enmascaramiento de datos, cómo funciona y cómo Klippa puede automatizar el enmascaramiento de datos para tu empresa.
¿Qué es enmascarar datos?
El enmascaramiento de datos, también conocido como anonimización de datos, redacción de datos u ofuscación de datos, es una técnica de seguridad para enmascarar datos sensibles. Estos datos son, por ejemplo, los números de la seguridad social o los números de las tarjetas de pago.
El enmascaramiento de datos se aplica para evitar comprometer los datos y reducir los riesgos de seguridad, al tiempo que se cumple con la normativa sobre privacidad de datos.
Por ejemplo, muchas organizaciones necesitan realizar comprobaciones de conocimiento del cliente (KYC) dentro de los procesos de incorporación de clientes. Al realizar estas comprobaciones para validar la identidad de los clientes, las entidades necesitan procesar documentos de identidad.
Sin embargo, algunos datos, como los números de la seguridad social, no pueden almacenarse en virtud del RGPD. Aunque hay excepciones, la mayoría de las organizaciones necesitan anonimizar u ofuscar los datos para garantizar el cumplimiento.
Actualmente, el enmascaramiento de datos está ganando más tracción, y se estima que la industria crecerá de 483,90 millones de dólares en 2020 a 1044,93 millones de dólares en 2026.
Tipos de datos sensibles
El enmascaramiento de datos puede utilizarse para proteger muchos tipos de datos. Los tipos más comunes son
- Información Personalmente Identificable (PII)
- Información sanitaria protegida (PHI)
- Información sobre tarjetas de pago (PCI-DSS)
- Ley de Portabilidad y Responsabilidad del Seguro Médico (HIPAA)
Es esencial saber cómo funciona el enmascaramiento de datos e identificar qué tipos y técnicas son adecuados para los fines de su empresa. Sólo entonces será más fácil utilizar el enmascaramiento de datos para salvaguardar los datos sensibles a la privacidad.
Veamos cómo funciona el enmascaramiento de datos.
¿Cómo funciona el enmascaramiento de datos?
El punto de partida es identificar todos los datos sensibles que su organización posee o procesa. Es esencial tener en cuenta que los datos pueden presentarse en muchas formas: correos electrónicos, faxes, hojas de Excel, información de bases de datos y documentos escaneados como pasaportes, por nombrar algunos.
Una vez completada la identificación de los datos, deben aplicarse algoritmos y técnicas de enmascaramiento de datos. Las organizaciones pueden eliminar, tachar, sustituir o cifrar los datos sensibles en función del caso de uso y de los requisitos legales.
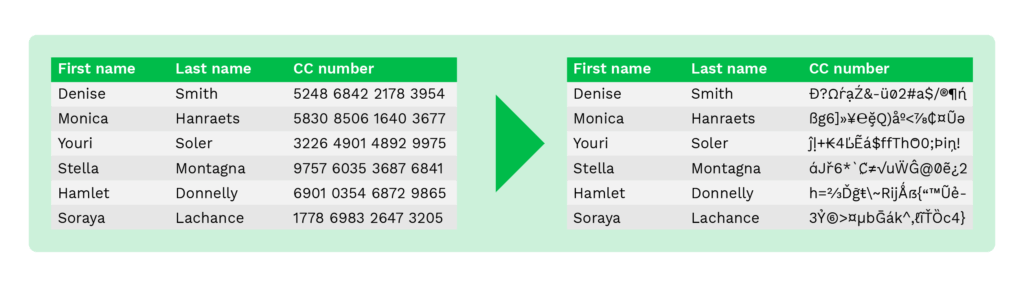
Tomemos como ejemplo una hoja de Excel con datos de clientes, incluyendo información sensible como números de cuentas bancarias. Al almacenar este tipo de información, el enmascaramiento de datos puede ayudar a aumentar la seguridad de los mismos.
Por ejemplo, en lugar de revelar los datos sensibles, los números de las cuentas bancarias pueden sustituirse por una “x”, y sólo se muestran los cuatro últimos dígitos.
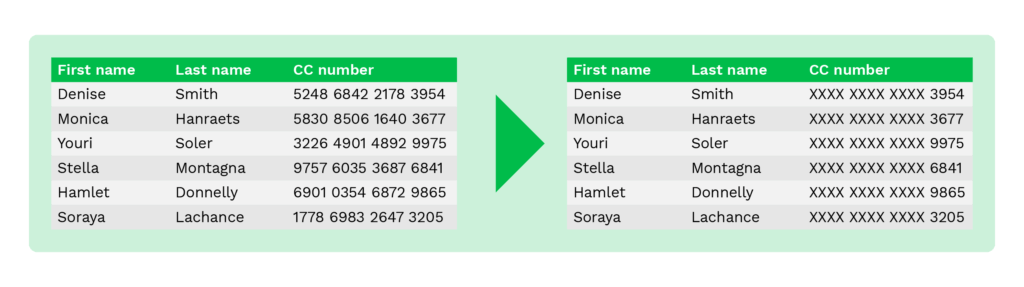
Aunque sólo se muestren los cuatro últimos dígitos, su personal de back-office puede verificar la titularidad de la cuenta bancaria. De este modo, los defraudadores no pueden utilizar el número de cuenta bancaria, aunque consigan la información.
Otro ejemplo podría ser el enmascaramiento de la información en el escaneo de un documento de identidad de un proceso de KYC. A continuación puede ver un antes y un después de un pasaporte enmascarado para garantizar el cumplimiento del GDPR.

Se puede aplicar un enfoque de enmascaramiento de datos similar a los números de seguro, los números de tarjetas de pago o los números de la seguridad social, por nombrar algunos.
Ahora que hemos explicado cómo funciona el enmascaramiento de datos, veamos dos tipos diferentes.
Tipos de enmascaramiento de datos
Hay varios tipos de enmascaramiento de datos, y su uso depende principalmente de los recursos, los casos de uso y los proveedores. Los dos tipos más comunes de enmascaramiento de datos son el estático y el dinámico.
En los siguientes párrafos explicaremos la diferencia.
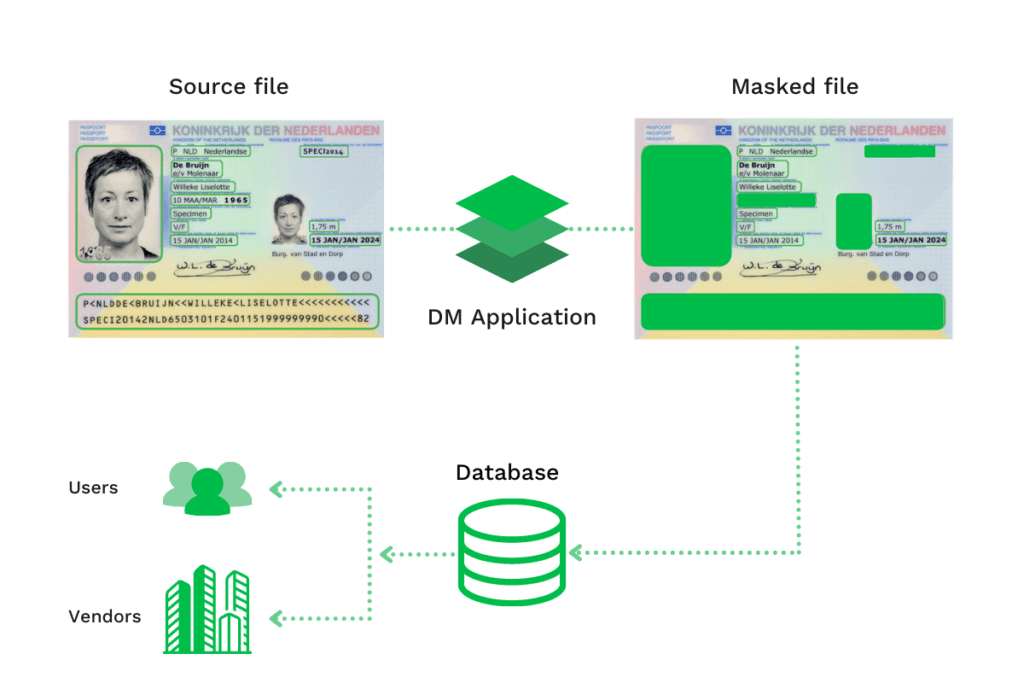
Enmascaramiento de datos estáticos
El enmascaramiento estático de datos (SDM) suele ser necesario para las pruebas de software con el fin de sustituir los datos sensibles mediante la alteración de los datos que se almacenan en un ordenador portátil, un disco duro o en alguna base de datos. Con el enmascaramiento estático de datos, las organizaciones pueden cumplir con las regulaciones de datos y privacidad como GDPR, PCI, PHI, PII, ITAR e HIPAA.
Esta arquitectura de enmascaramiento de datos comienza con la copia original, de la que se enmascaran los datos sensibles antes de enviarlos a su procesamiento posterior (en una base de datos, software, etc.).
Con este enfoque, la información sensible se sustituye de forma permanente para garantizar el cumplimiento de la normativa sobre privacidad de datos y la protección contra las violaciones de datos.
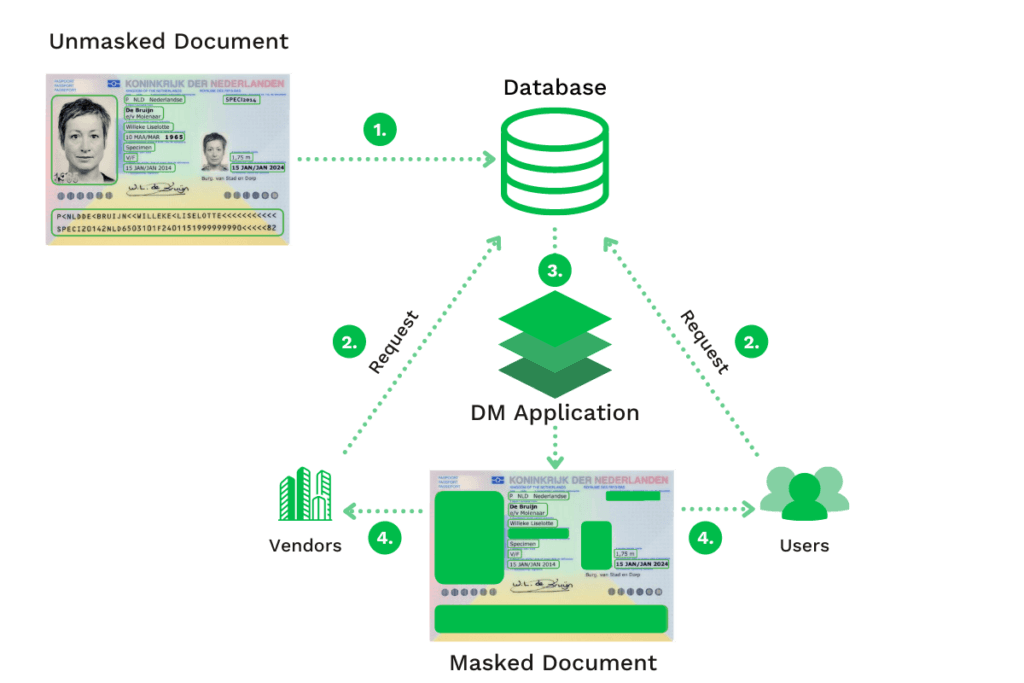
Enmascaramiento dinámico de datos
La arquitectura de enmascaramiento dinámico de datos (DDM) difiere de la estática. Se utiliza para enmascarar datos sensibles en tránsito (es decir, utilizados activamente), dejando la copia original inalterada. Con este enfoque, los datos desenmascarados son visibles en la base de datos real.
El DDM se utiliza principalmente para procesar las consultas de los clientes y gestionar los historiales médicos dentro de las aplicaciones de seguridad basadas en roles. En algunos sectores es necesario ocultar los datos sensibles a determinados usuarios.
Con DDM, las organizaciones pueden utilizar las consultas modificadas (es decir, las solicitudes de datos) que llegan a la base de datos original para enmascarar dinámicamente los datos y pasarlos a la parte que los solicita.
Este tipo de enmascaramiento de datos se utiliza a menudo cuando las organizaciones envían datos a un proveedor externo o a partes interesadas internas, que no están autorizadas a ver datos sensibles. Estos datos pueden ser números de la Seguridad Social (SSN) o números de tarjetas de pago.
Ahora que los tipos más comunes de enmascaramiento de datos están cubiertos, vamos a ver las técnicas de enmascaramiento de datos.
Técnicas de enmascaramiento de datos
El enmascaramiento de datos viene acompañado de varias técnicas, que se explican a continuación.
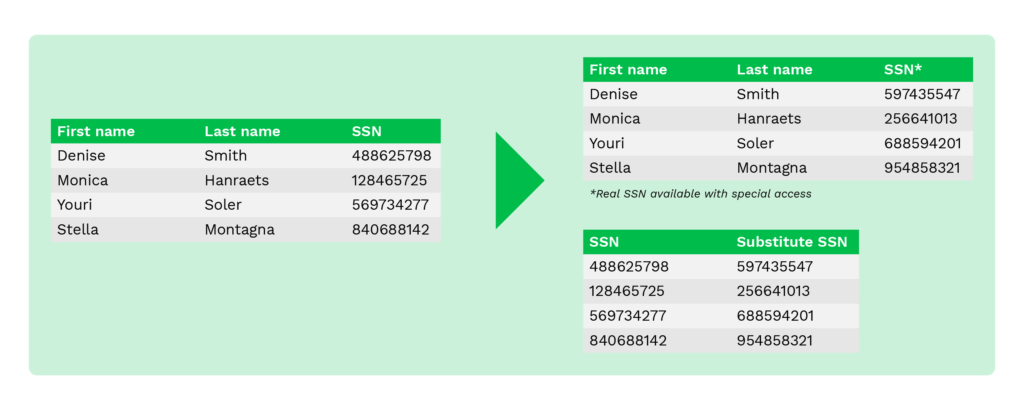
Substitución
La sustitución, también denominada seudonimización, es una técnica que se utiliza para sustituir los datos originales por datos aleatorios procedentes de archivos de búsqueda suministrados o personalizados. Resulta útil cuando las organizaciones necesitan preservar el aspecto auténtico de los datos y al mismo tiempo disfrazar los datos sensibles.
Esta técnica puede proteger eficazmente los datos de las filtraciones y ayudar a controlar el acceso interno.
Mezclando
El barajado es una técnica similar a la sustitución. También se utiliza para sustituir los datos originales por otros que parezcan auténticos. La diferencia es que las entidades de una misma columna se barajan aleatoriamente.
Por ejemplo, las organizaciones pueden utilizar esta técnica para barajar las columnas de los nombres de los empleados de varios registros de empleados de forma aleatoria. Esta técnica puede ser propensa a la ingeniería inversa si alguien pone sus manos en el algoritmo de barajado.
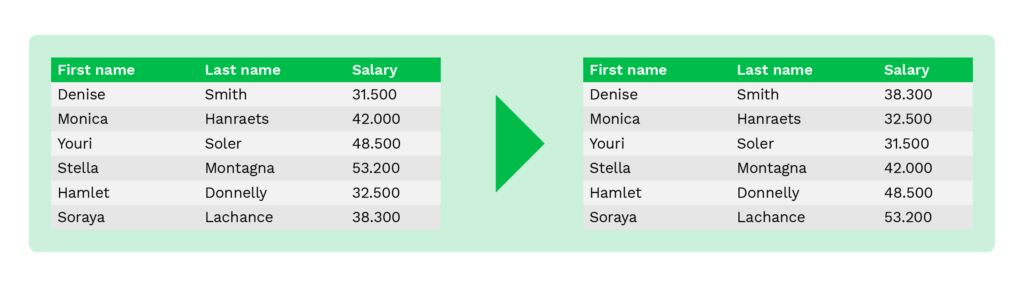
Promedio
Promediar es un método para sustituir los valores originales por un valor medio de las columnas de la tabla. Por ejemplo, en lugar de mostrar los salarios o los saldos de las cuentas de los individuos, el iniciador muestra sólo el valor medio de los salarios o los saldos de las cuentas.
Este método ayuda a mantener el valor agregado y se utiliza comúnmente para el análisis estadístico o la recopilación de datos de las instituciones financieras.
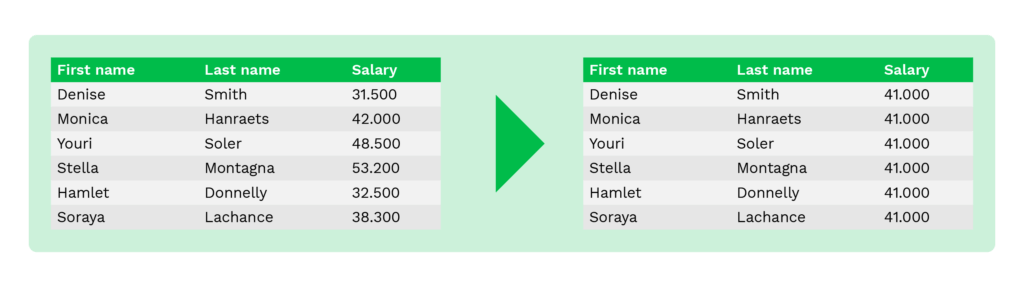
Anulación (borrado)
La anulación es una técnica que consiste en sustituir los datos sensibles por un valor nulo para evitar que los usuarios no autorizados vean los datos originales. Simplemente significa eliminar la información o sustituirla por un valor vacío en los documentos.

En algunos casos de uso, la información de ciertos documentos se omite por completo, como la fecha de nacimiento en los currículos. A menudo, esto se hace para eliminar los riesgos de prácticas de contratación poco éticas.

Enmascarado de datos (blacklining)
Enmascarar datos, también conocida como blacklining, es un método similar a la anulación, ya que sólo se enmascara una parte de los datos originales.
Por ejemplo, en el entorno de las compras en línea sólo se muestran a los clientes los cuatro últimos dígitos del número de la tarjeta de pago para evitar el fraude.
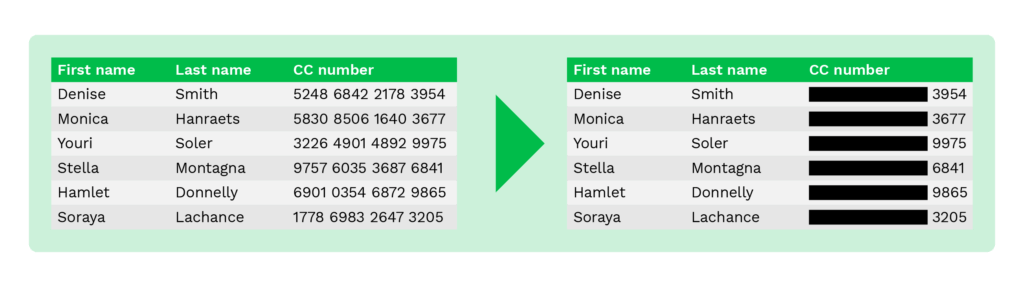

El mismo método puede aplicarse a cualquier documento que contenga información sensible a la privacidad. A continuación puede ver el ejemplo con un pasaporte, en el que varios campos están redactados.
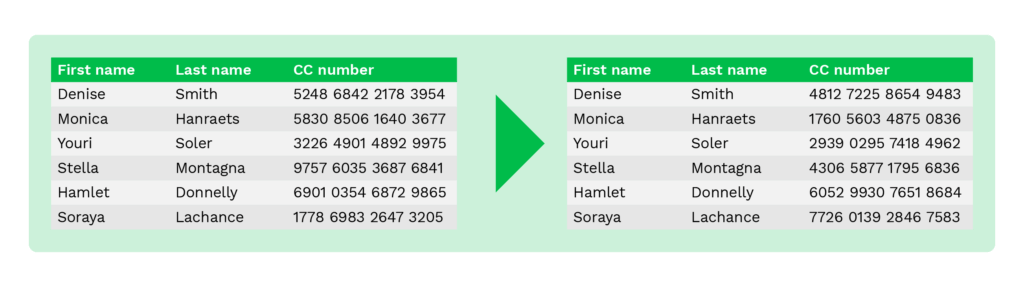
Codificación de datos
La técnica de codificación de datos se utiliza para alterar los datos reordenando aleatoriamente el orden de los caracteres o números con un algoritmo específico.
Los datos originales ya no pueden obtenerse después de completar el proceso, ya que los datos están codificados.

Encriptación de datos
El cifrado de datos es una técnica que sólo permite acceder a los datos con la clave de descifrado.
Es el algoritmo de enmascaramiento de datos más complejo y el más seguro. Además de la complejidad, requiere una gestión adecuada de la clave de cifrado para garantizar la seguridad.

¿Por qué es importante el enmascaramiento de datos?
Desde que se impuso el GDPR, la protección de datos se ha convertido en la máxima prioridad para muchas empresas. Como resultado, las organizaciones han encontrado esencial implementar el enmascaramiento de datos como una de las herramientas para proteger sus datos sensibles.
Entonces, ¿por qué es necesario el enmascaramiento de datos? En principio, el enmascaramiento de datos ofrece a las organizaciones una vía segura para crear versiones alternativas de datos utilizables y bien protegidos.
Con el uso del enmascaramiento de datos, las organizaciones pueden obtener los siguientes beneficios.
Enmascaramiento de datos para el cumplimiento del GDPR
El enmascaramiento de datos ayuda a las organizaciones a cumplir con las leyes y reglamentos de privacidad de datos. Con varias técnicas de enmascaramiento de datos disponibles, numerosas organizaciones pueden eliminar la exposición de datos sensibles.
Sin embargo, no todas las organizaciones utilizan el enmascaramiento de datos para cumplir con el RGPD.
Por ejemplo, en 2020, el gran minorista de ropa de moda H&M fue multado con 35 millones de euros debido a violaciones del GDPR. El incidente consistió en que la dirección accedió a datos sensibles, como creencias religiosas y cuestiones familiares, a través de grabaciones de reuniones. Estas grabaciones se utilizaban como base para evaluar el rendimiento de los empleados.
Este incidente podría haberse evitado redactando todos los datos sensibles de las grabaciones documentadas de estas reuniones.
Protección contra la violación de datos
Uno de los principales beneficios del enmascaramiento de datos es hacer que los datos sean inútiles para los ciberatacantes, preservando al mismo tiempo su utilidad para la organización. Incluso si los datos son violados debido a ciberataques, muchas técnicas de enmascaramiento de datos pueden evitar que los intrusos obtengan información sensible.
En 2018, se informó que Panera Bread filtró al menos 37 millones de registros de clientes debido a la falta de control de acceso y medidas de seguridad. Datos como correos electrónicos personales, direcciones e información de tarjetas de crédito fueron accesibles a través del rastreo.
Una vez más, este escenario podría haberse evitado con diversas técnicas de enmascaramiento de datos.
Reducción de los riesgos de seguridad de los datos
Muchas empresas colaboran con terceros y proveedores dentro de su perímetro, a los que se ceden algunos datos. Además, los empleados y otras partes interesadas internas también pueden tener acceso a los datos.
En pocas palabras, siempre existe la amenaza de que los datos se pierdan. El enmascaramiento de datos puede proporcionar los medios para asegurar los datos contra personas o partes que no están autorizadas a verlos.
Sólo se pueden ver los datos falsos, a menos que se haya concedido la autorización para desenmascarar los datos. Así, la anonimización de datos puede reducir los riesgos de seguridad de los datos internos y las filtraciones de datos.
En general, el enmascaramiento de datos proporciona impresionantes beneficios, que pueden ayudar a las empresas a obtener una ventaja competitiva. Pero, ¿cuáles son los casos de uso más comunes? Veamos algunos de ellos.
Casos de uso del enmascaramiento de datos
Hay muchos casos de uso para el enmascaramiento de datos, entre ellos los siguientes:
- Enmascaramiento de números de tarjetas de pago
- Anonimizar los números de la seguridad social
- Redacción de currículos
- Enmascaramiento de datos para su archivo digital
- Redacción o encriptación de información sanitaria personal
- Redacción o codificación de documentos gubernamentales
- Redacción de documentos legales y casos judiciales públicos
- Anonimización de grabaciones de reuniones
- Control de acceso interno
- Cifrado de documentos de propiedad intelectual
- Intercambio de datos con terceros
A continuación, profundizamos en las cuatro primeras con más detalle.
Bloqueo de números de tarjetas de pago
En algunas circunstancias, un miembro de su organización puede necesitar acceder a la información de una tarjeta de crédito o de pago. Por lo tanto, utilizar el enmascaramiento de datos para poner en negro los últimos cuatro dígitos del número de la tarjeta puede evitar la exposición a componentes sensibles como los números de las tarjetas de pago.
Es un método muy extendido para que los bancos y otras instituciones financieras manejen la información de pago de sus clientes. Al poner en negro el número de la tarjeta de pago, las organizaciones pueden garantizar el cumplimiento de la PCI-DSS.

Anonimizar los números de la seguridad social
La información como el SSN en documentos de identidad como pasaportes y tarjetas de identificación es altamente sensible. A menudo, las organizaciones que no son instituciones gubernamentales no pueden almacenar el SSN en su base de datos
En los Países Bajos, el burgerservicenummer (BSN) es equivalente al SSN. El BSN es un número personal único de servicio al ciudadano que se utiliza para identificar a cada ciudadano registrado. Por ejemplo, el BSN es utilizado por las instituciones gubernamentales para encontrar datos de cada ciudadano, a menudo con fines fiscales.
Los SSN y los BSN están estrictamente prohibidos por el GDPR ya que pertenecen a “categorías especiales de datos personales.” Por supuesto, hay casos en los que se permite el almacenamiento de estos datos. Pero solo con una excepción legal especial o con el consentimiento de la persona.
Por lo tanto, es común anonimizar los números SSN o BSN utilizando varias técnicas de enmascaramiento de datos.

Redacción de currículos
A pesar de toda la formación para reducir los prejuicios en el proceso de contratación, una gran cantidad de reclutadores son culpables de basar sus decisiones en diferentes prejuicios. Por desgracia, sigue siendo habitual que si dos candidatos tienen habilidades y experiencia similares, se contrate al más atractivo.
Aunque es ilegal discriminar de cualquier manera en el proceso de contratación, muchas empresas siguen haciéndolo. De hecho, la mitad de los casos de discriminación se dan en el 20% de las empresas de Estados Unidos.
Las organizaciones han empezado a redactar los currículos para eliminar los prejuicios y la discriminación en la fase inicial del proceso de contratación. Según el informe de HRO Today, los campos más comunes que se redactan en los currículos son
- Dirección del domicilio
- Nombre
- Imagen (atractivo, género, raza)
Con el enmascaramiento de datos, los responsables de la selección de personal pueden evaluar mejor a los candidatos basándose únicamente en sus habilidades y experiencia. Es importante tener en cuenta que, al fin y al cabo, los reclutadores son sólo humanos.

Enmascarar los datos para archivarlos digitalmente
El almacenamiento de datos en papel ya no es una opción para muchas organizaciones. Las razones por las que las organizaciones se orientan hacia la digitalización con el avance de la tecnología incluyen:
- Una enorme acumulación de datos sin organizar
- Control de acceso interno
- Ahorro de tiempo y costes
- Respeto al medio ambiente
- Cumplimiento del GDPR
- Fácil accesibilidad a los datos
Aunque el archivo de datos puede ser muy beneficioso, su reto es cumplir con las obligaciones legales relativas a las leyes de privacidad de datos. En este sentido, el enmascaramiento de datos es una solución segura y sólida para garantizar el cumplimiento del GDPR.
Antes de archivar, las empresas pueden utilizar simplemente el enmascaramiento de datos para redactar todas las partes sensibles, como nombres, números de pacientes y números de la seguridad social, de los documentos o sustituirlos por datos estructuralmente idénticos (la misma cantidad de números o caracteres).
Las organizaciones han adoptado este método en sectores como el jurídico y el sanitario, por nombrar algunos.
Ahora que hemos cubierto algunos de los casos de uso, echemos un vistazo a la transformación de la redacción de documentos.
Transformación de la redacción de documentos
Desde que tenemos uso de razón, la redacción manual de documentos se ha utilizado en varios sectores. Es una tarea tediosa de realizar y tiene muchos problemas subyacentes. Uno de los principales problemas es la escalabilidad.
El personal humano tiene dificultades para mantener la precisión, la eficacia y la coherencia a lo largo del tiempo. Esto da lugar a tiempos de entrega lentos, clientes insatisfechos y costes elevados.
Tomemos como ejemplo el sector jurídico. Un flujo de trabajo típico implica equipos de abogados y asistentes jurídicos que revisan una gran pila de documentos durante cientos de horas.
En lugar de utilizar sus conocimientos y experiencia para realizar tareas significativas, se encargan de añadir, modificar y eliminar las redacciones de los documentos. Por no hablar de los costes de contratación de este personal.
Añadir más personal a medida que aumenta el volumen de documentos dispara rápidamente los costes. Así que seamos sinceros. Redactar manualmente los documentos no es una opción escalable (al menos no si se quiere ser rentable).
Por suerte, es posible automatizar la redacción de documentos con la tecnología actual. Hay dos formas que las organizaciones pueden aprovechar: el enmascaramiento de datos totalmente automatizado y la automatización del enmascaramiento de datos con asistencia humana.
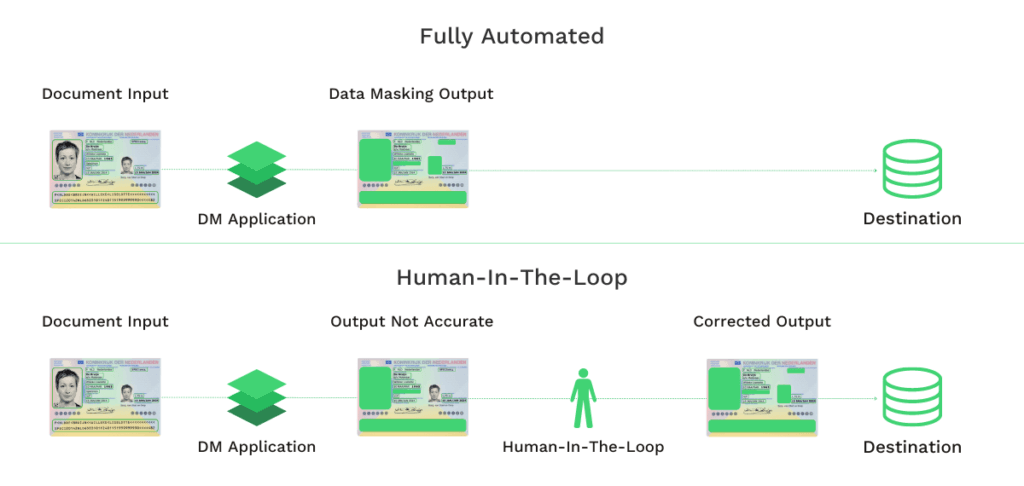
Enmascaramiento de datos totalmente automatizado
En una solución de enmascaramiento de datos totalmente automatizada, no es necesaria la intervención humana. Con tecnologías como el Reconocimiento Óptico de Caracteres (OCR) potenciado por la IA, es posible reconocer, localizar y redactar automáticamente el campo de información de los documentos que se requiere.
Todo lo que hay que hacer es alimentar el motor de OCR con los documentos que necesitan ser enmascarados, y él hace el resto. Esta opción libera sus recursos humanos, que puede destinar a tareas más complicadas. De este modo, puede maximizar la eficiencia de su organización.
Enmascaramiento de datos con ayuda humana
La otra solución es utilizar la automatización asistida por humanos, es decir, la automatización human-in-the-loop (HITL). Esta solución utiliza la IA para la automatización y permite que el personal humano realice las comprobaciones finales para verificar la finalización del enmascaramiento de datos.
La ventaja de la automatización human-in-the-loop es que permite una mayor precisión en la redacción de documentos. Esto no es una sorpresa, ya que la solución HITL combina lo mejor de la inteligencia artificial con lo mejor de la inteligencia humana.
A veces puede haber problemas con la tecnología (calidad de la imagen, calidad del documento, etc.), que le impiden realizar las tareas de enmascaramiento de datos. Por lo tanto, la revisión de la entrada o salida de datos puede ayudar a reducir los errores.
Crear cualquiera de estas soluciones desde cero es difícil, costoso y requiere mucho tiempo. Por ello, en Klippa hemos decidido combinar nuestra tecnología de OCR con las funcionalidades de enmascaramiento de datos para ayudar a diversas organizaciones. Podemos ayudar a nuestros clientes a automatizar el enmascaramiento de documentos a escala.
¿Por qué debería tu organización automatizar el enmascaramiento de datos? Analicemos las ventajas que conlleva.
Beneficios del enmascaramiento de datos automatizado
Si bien las organizaciones pueden salvaguardar los datos de las filtraciones y garantizar el cumplimiento del GDPR con el enmascaramiento de datos, la automatización añade muchos más beneficios. Estos beneficios incluyen:
- Tiempos de respuesta más rápidos: la automatización de la redacción de documentos o datos permite a su personal centrarse en tareas más importantes. Se necesitarán menos personas para realizar estas tediosas tareas y se acelerará el tiempo de respuesta.
- Precisión: Con una solución automatizada de enmascaramiento de datos que utilice IA, las empresas pueden lograr una mayor precisión simplemente porque las máquinas y los ordenadores no se cansan.
- Velocidad: Con una solución automatizada, el proceso de redacción de datos puede ser hasta 90 veces más rápido. Puede ver un cálculo simplificado en la siguiente sección.
- Ahorro de costes: Con la mayor eficiencia y precisión que se consigue con la IA, las organizaciones pueden ahorrar mucho dinero (horas de trabajo, reducción de errores, etc.).
- Escalabilidad: Hay un límite en el número de documentos que un empleado medio puede redactar. La automatización del enmascaramiento de datos ofrece a las empresas una forma de redactar documentos a escala sin aumentar los costes operativos.
Parece que son muchos los beneficios que las organizaciones pueden disfrutar de una solución de enmascaramiento de datos automatizada. Pero, ¿qué significa para usted en términos de negocio?
Para hacerlo tangible para usted, hemos proporcionado un ejemplo de cálculo de un posible retorno de la inversión (ROI) en la siguiente sección.
El ROI de la solución de enmascaramiento de datos automatizado
Supongamos que tiene 100.000 documentos de identidad, de los que necesita redactar los números de la seguridad social. Supongamos también que, por término medio, un empleado de oficina experimentado puede redactar dos documentos de identidad manualmente cada minuto. Esto supone 120 documentos de identidad en una hora. Calculemos que el coste de contratar a un oficinista experimentado (incluyendo el seguro, el salario por hora y otros costes) es de 25,00 euros por hora.
Para asegurarse de que la redacción se hace correctamente, habría que contratar a otro empleado de la oficina para que verifique dos veces los documentos redactados. Supongamos que un empleado idéntico puede volver a comprobar la exactitud de cada redacción a un ritmo de 360 documentos de identidad por hora.
El coste total de redactar manualmente 100.000 documentos de identidad superaría los 27.700 euros. Las horas de trabajo que se necesitarían para completar el proyecto son más de 1.110.
Si se compara con la solución Klippa, que puede redactar 10.000 documentos por hora, se podría completar el proyecto en 10 horas. Eso supone un ahorro de aproximadamente 1.100 horas de trabajo.
Como estimación, a su organización le costaría 4.000 euros completar este proyecto con nuestra solución (dependiendo del volumen y tipo de documentos). Podría completar el proyecto más de 90 veces más rápido y con un ROI de 6,9.

Prueba tú mismo nuestra calculadora de retorno de la inversión en enmascaramiento de datos.
Cómo enmascarar sus datos con Klippa
Klippa fue fundada en 2015 con el propósito de ayudar a las empresas a digitalizar y automatizar el procesamiento de documentos a escala mediante el uso de tecnologías de vanguardia. Con tecnologías como el aprendizaje automático, la IA y el OCR, somos capaces de ayudar a nuestros clientes de diversas industrias en todo el mundo.
Nuestra solución de Procesamiento Inteligente de Documentos (IDP), Klippa DocHorizon, está diseñada para ayudar a las organizaciones a automatizar inteligentemente el procesamiento de documentos; digitalizar, extraer, clasificar, verificar y anonimizar datos de varios documentos.
Con Klippa DocHorizon, su organización puede reducir los tiempos de entrega, los costes y los errores humanos a la vez que protege los datos sensibles.
Aunque nuestro software de OCR basado en IA incluye funciones de enmascaramiento de datos, hemos desarrollado una API de enmascaramiento de datos para permitir la integración con los sistemas existentes de gestión de documentos, planificación de recursos empresariales (ERP) o historia clínica electrónica (EHR) de nuestros clientes.
Además de la API, hemos desarrollado un SDK de enmascaramiento de datos para que las empresas puedan aprovechar nuestra tecnología dentro de su sistema.
API de enmascaramiento de datos
Para ayudar a nuestros clientes a deshacerse del trabajo repetitivo en los procesos administrativos, hemos desarrollado una API de enmascaramiento de datos OCR. Permite a nuestros clientes tachar determinados campos e imágenes de los documentos.
Nuestro motor de análisis puede ser entrenado para reconocer campos específicos que necesitan ser tachados. Procesamos numerosos campos ya preparados, pero se pueden añadir o eliminar campos personalizados a petición del cliente.
El motor de análisis puede recibir varias entradas, como JPG, PNG y PDF. La salida por defecto que reciben nuestros clientes es un archivo JSON, que puede ser reenviado a los destinos deseados, como los sistemas de planificación de recursos empresariales (ERP). Sin embargo, las salidas pueden personalizarse, por ejemplo, a CSV, XLSX o XML si es necesario. Además del JSON estructurado, también es posible obtener los documentos enmascarados en JPG, PDF o tipos de archivo similares.
Nuestra API de OCR de enmascaramiento de datos está disponible actualmente a través de una API RESTful, lo que permite a nuestros clientes integrarla en aplicaciones basadas en la web. Para ayudar a nuestros clientes, proporcionamos una documentación clara.
Enmascaramiento de datos en el móvil
Si necesitas una solución de enmascaramiento de datos para móviles, Klippa también puede ayudarte. Ofrecemos un SDK de escáner para móviles que incluye funcionalidades de enmascaramiento de datos. Los clientes utilizan este SDK de escáner para enmascarar cierta información en documentos de identidad, recibos, facturas y muchos otros tipos de documentos.
Actualmente, nuestro SDK para escáneres está disponible tanto para Android como para IOS. Además, ofrecemos wrappers para lenguajes multiplataforma como ReactNative, Flutter, Cordova y Nativescript. En general, se puede integrar en cualquier solución móvil.
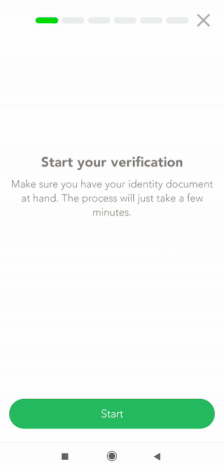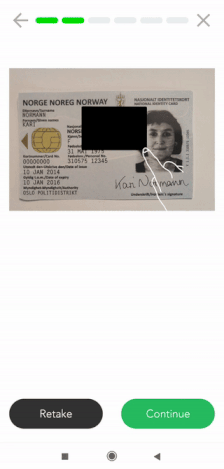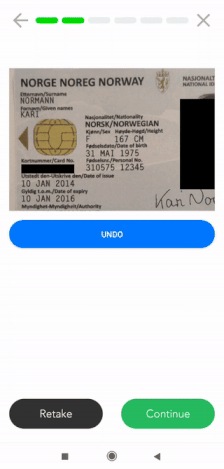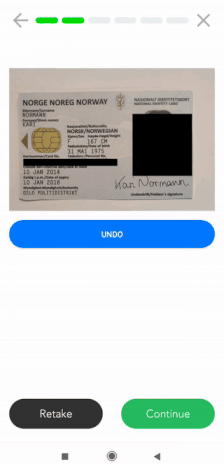
Marca de agua en documentos
En caso de que uno de los enfoques de enmascaramiento de datos no sea posible para usted, Klippa también ofrece el marcado de agua de documentos digitales como alternativa. De este modo, puede proteger los derechos de autor de sus documentos, permitir a sus clientes compartir datos de forma más segura y reducir los riesgos de seguridad al almacenar datos sensibles.
Simplemente carga a Klippa DocHorizon un documento, y éste le devolverá el mismo documento con una marca de agua. Esa marca de agua contiene algo de acuerdo a sus necesidades. Por ejemplo, el nombre de su empresa + la fecha de escaneo.

Tanto si buscas una solución integral como una integración API / SDK para automatizar el procesamiento de tus documentos, Klippa está aquí para ayudarte. Completa el siguiente formulario para una demostración gratuita, o contacta a nuestros expertos para ver cómo Klippa puede ayudarte.