El uso de la extracción automática de datos de documentos puede transformar su negocio. Es bastante fácil de empezar, pero comprender lo que puede hacer por tu negocio puede llevar un tiempo.
¿Tú o tus empleados tienen que procesar manualmente cientos, miles o incluso millones de documentos al mes? ¿Es un proceso del que preferirías deshacerte? No es el único. Por suerte, hay una respuesta: extraer automáticamente los datos de los documentos. Esto acelera todo el proceso.
¿Quieres saber cómo funciona? ¿O quieres familiarizarte con una mejor comprensión general de la extracción de datos? Entonces, continúa leyendo.
En este blog, comprenderá mejor el significado, las técnicas, el proceso, la importancia y obtendrá un ejemplo y una respuesta a la pregunta: “¿Qué es la extracción de datos?”.
¿Qué es la extracción de datos?
Entonces, ¿qué significa extraer datos de documentos? Básicamente se trata de recuperar varios tipos de datos de una o varias fuentes. Estas fuentes suelen estar mal organizadas y completamente desestructuradas.
Extraer los datos permite procesarlos, almacenarlos y analizarlos aún más en otro lugar. Estos tipos de datos suelen utilizarse para mejorar las operaciones de la empresa. Es la base para hacer un análisis crítico en el proceso de toma de decisiones.
Hay tres formas de extracción de datos. Manual, automatizada y human in the loop (que es una combinación de las dos primeras).
Ahora que la definición de extracción de datos está clara, continuemos con la importancia del proceso.
¿Por qué la extracción de datos es tan importante?
Imagina que eres un banco que concede hipotecas a compradores de viviendas. Por ley, usted está obligado a hacer comprobaciones de CSC, registrar los ingresos del comprador y probablemente más.
Para ello, los clientes envían documentos con esta información. Esta información tiene que aterrizar en tu base de datos, o sistema de toma de decisiones.
Lamentablemente, los datos no están estructurados, por lo que se necesita un equipo de backoffice para identificar la presencia de información en los documentos, como el salario de la nómina. Además, hay que introducir la información en los sistemas digitales.
Se trata de una tarea costosa, que consume, aburrida y tediosa, pero no tiene por qué serlo. De hecho, muchas empresas están aprovechando las soluciones y técnicas de extracción automatizada, impulsadas por la IA, para gestionar el proceso de extracción de datos desde el principio hasta el final.
Las principales ventajas de utilizar una solución de extracción automatizada son:
- Mejora de la precisión
- Aumento de la productividad de los empleados
- Reducción de costes
- Ahorro de tiempo
- Escalabilidad
- Mayor tiempo de respuesta
Mayor precisión
La sustitución de la extracción de datos manual por la automatizada disminuye drásticamente la posibilidad de errores humanos. Por lo tanto, conduce a una mayor precisión general.
Si la introducción de grandes cantidades de datos es una tarea diaria para la mayoría de sus empleados, hay muchas posibilidades de que se produzcan algunas inexactitudes y errores debidos a fallos humanos. Sin ningún paso de la capa de verificación, la entrada de datos tiene una tasa de error del 4%.
Si se automatiza el proceso de extracción de datos de los documentos, se obtendrán datos más precisos en general. Una mayor precisión no solo conduce a mejores decisiones empresariales, sino que también es muy beneficiosa para los empleados. Esto nos lleva a la siguiente ventaja.
Mayor productividad de los empleados

Al eliminar la extracción manual de datos y sustituirla por una herramienta automatizada, los empleados pueden dedicar más tiempo a las tareas importantes. Algunas tareas sólo pueden ser realizadas por humanos. Por lo tanto, deje que sus empleados hagan esas y que las tareas que pueden ser automatizadas sean realizadas por una herramienta de extracción de datos automatizada.
No solo aumentará la satisfacción porque los empleados se liberan de las tareas tediosas, sino que también pueden centrarse en tareas más significativas. Esto también conducirá a una mayor satisfacción, lo que (a largo plazo) conducirá a una mayor productividad.
Coste reducido
Al elegir una herramienta de extracción de datos, tu empresa puede ahorrar dinero tanto a corto como a largo plazo.
A corto plazo, tu empresa ya puede ahorrar mucho dinero al reducir los errores de introducción manual de datos. A largo plazo, tu empresa no tiene que preocuparse por escalar y financiar un gran equipo para gestionar las necesidades de datos de tu empresa. Por ello, los sistemas de introducción y extracción de datos automatizados están en auge.
Ahorro de tiempo
Los estudios demuestran que la automatización inteligente suele suponer un ahorro de costes de entre el 40 y el 75%. El tiempo es dinero, por lo que podría ser uno de los mayores argumentos de venta de una herramienta de extracción de datos.
Escalabilidad
Cuando una empresa crece, la cantidad de documentos entrantes y salientes también crece. Si la extracción de datos de los documentos se sigue haciendo manualmente, la cantidad de documentos se acumulará.
Esto puede evitarse cambiando a un sistema automatizado. De este modo, la empresa puede crecer sin tener que preocuparse por los grandes volúmenes de datos que se acumulan, ni tener que contratar a una gran plantilla.
Tiempo de respuesta más rápido
Gracias a la extracción automatizada de datos, los tiempos de respuesta pueden pasar de días o semanas a segundos. Si un humano tiene que comprobar manualmente un documento, sólo puede hacerlo una vez. Además, las personas sólo pueden trabajar 8 horas al día.
Retos
Si hay ventajas, también debe haber algunos retos en cuanto a la extracción de datos.
Los dos retos son:
- La seguridad de los datos sensibles puede ser un gran reto. Un ejemplo de datos sensibles son los datos financieros. Por lo tanto, hay que garantizar la seguridad en la extracción de datos. Es importante trabajar únicamente con soluciones de software que puedan demostrar que su seguridad se comprueba regularmente y que pueden cumplir con el GDPR y otras legislaciones.
- Otro reto es la coherencia de los datos extraídos de varias fuentes, que es aún mayor si estas fuentes son tanto estructuradas como no estructuradas, ya que hay que asegurarse de que funcionan bien juntas. Los sistemas potenciados por la IA pueden ser entrenados para combinar los datos y hacerlos aptos para las operaciones después del procesamiento.
Por suerte, la mayoría de las soluciones de extracción de datos vienen con un amplio equipo de asistencia técnica para ayudarte a superar estos retos. Ahora, continuemos con los tipos de datos que se pueden extraer.
Tipos de datos
Los datos pueden clasificarse según la estructura de la fuente:
- Datos estructurados: La fuente de datos ya tiene una estructura lógica. Por lo tanto, ya es muy conveniente para la extracción. No es necesario trabajarla o manipularla antes del proceso de extracción de datos. Algunos ejemplos son los archivos CSV y XML.
- Datos no estructurados: La mayoría de los datos existen de forma no estructurada. Las fuentes de datos no estructurados pueden ser, por ejemplo, PDF, textos escaneados, páginas web, correos electrónicos o imágenes. Los datos no estructurados tienen que ser filtrados para poder extraerlos de forma razonable. Por ejemplo, hay que eliminar los espacios en blanco, los resultados duplicados y otros “ruidos” que hay que limpiar del documento.

Técnicas de extracción de datos
Existen dos técnicas diferentes para la extracción de datos: la extracción lógica y la física.
Extracción lógica
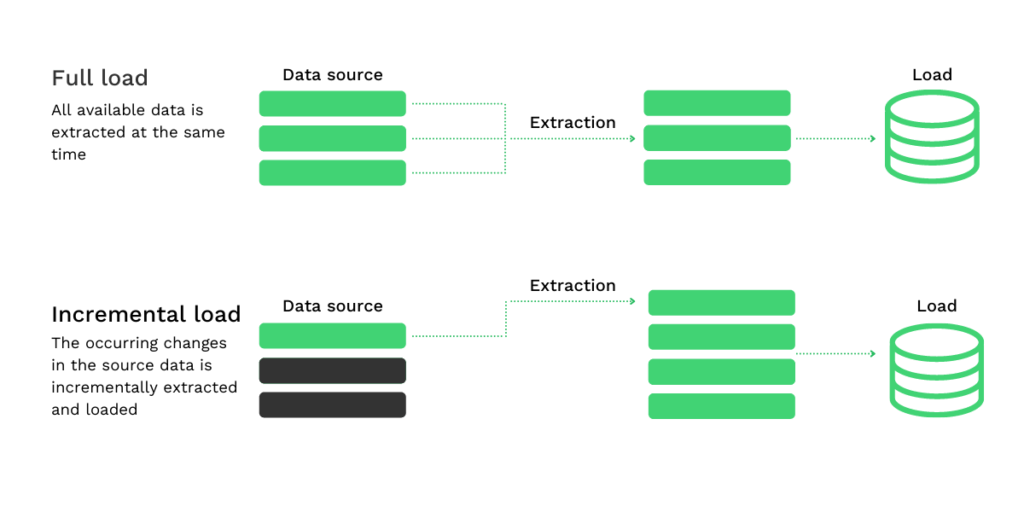
La extracción lógica es la técnica más utilizada. Puede dividirse en dos subtipos:
- Extracción completa: Todos los datos se extraen completamente al mismo tiempo, sin necesidad de información (tecno)lógica adicional. La extracción completa es un método que se utiliza cuando hay que extraer y cargar los datos por primera vez. Refleja los datos que están disponibles en ese momento en el sistema de origen.
- Extracción incremental: Desde la última extracción de datos realizada con éxito (indicada por una marca de tiempo), se rastrean los cambios que se producen en los datos de origen. Estos cambios se extraen y cargan de forma incremental.
Extracción física
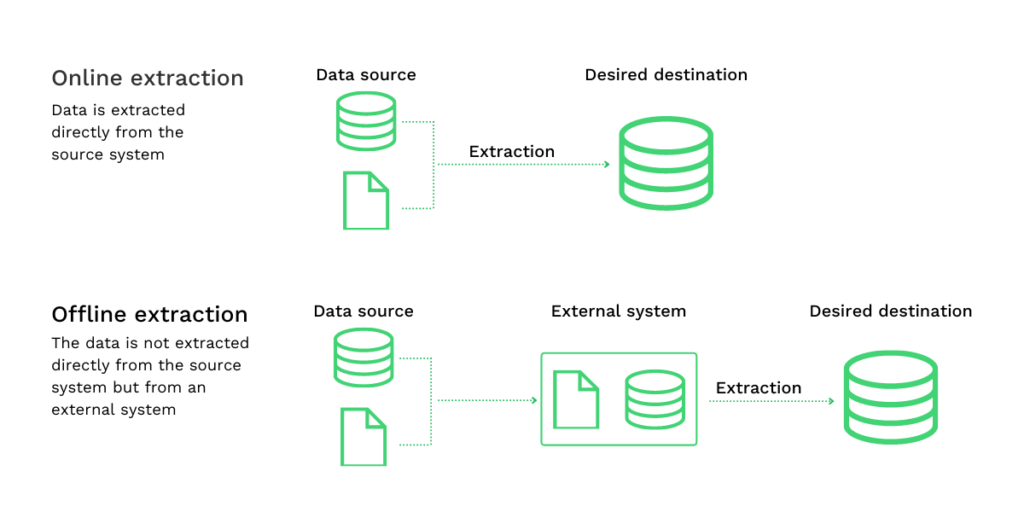
Si la extracción de datos de sistemas de almacenamiento de datos caducados o restringidos mediante la extracción lógica es difícil, la única forma de obtener estos datos es aplicar técnicas de extracción física. La extracción física puede dividirse en dos tipos:
- Extracción en línea: Existe una conexión directa entre el sistema de origen y el archivo final. Con el método de extracción en línea, los datos extraídos están más estructurados que los datos de origen.
- Extracción fuera de línea: La extracción real de los datos tiene lugar fuera del sistema de origen. En los procesos de extracción fuera de línea, los datos se estructuran por sí mismos o se estructuran mediante rutinas de extracción.
Categorías de herramientas de extracción
Las herramientas de extracción de datos extraen automáticamente los datos de la fuente. El tipo de servicio y la finalidad son parámetros muy importantes. Para entender qué categoría de herramientas funcionaría mejor para su empresa, tiene que comprender la diferencia entre las tres:
- Herramientas de procesamiento por lotes: Pueden ser interesantes para las empresas que necesitan transferir datos de una a otra ubicación, pero se presentan desafíos. Los retos podrían ser los datos almacenados en formas obsoletas, o los datos heredados. El procesamiento por lotes también puede ser útil para las empresas que desean trasladar datos en sus instalaciones o en un entorno cerrado.
- Herramientas de código abierto: Son las preferidas por las empresas con presupuesto. Pueden adquirir software de código abierto para replicar los datos proporcionados, o extraer datos. Las herramientas de código abierto son en su mayoría suficientes para las empresas de menor tamaño.
- Herramientas basadas en la nube: la mayoría de las herramientas de extracción disponibles hoy en día están basadas en la nube. Las herramientas basadas en la nube destacan por su rapidez y fiabilidad en la extracción de datos. Al utilizar las herramientas basadas en la nube, las empresas ya no tienen que preocuparse por el cumplimiento de la normativa y los problemas de seguridad internos. Además, se eliminan los retrasos causados por el procesamiento por lotes.
Hoy en día hay muchas soluciones basadas en la nube disponibles en el mercado. Una de ellas es Klippa. Klippa se especializa en la extracción de datos de documentos no estructurados y puede ayudarle a convertir documentos no estructurados en datos estructurados.
Ejemplo de extracción de datos
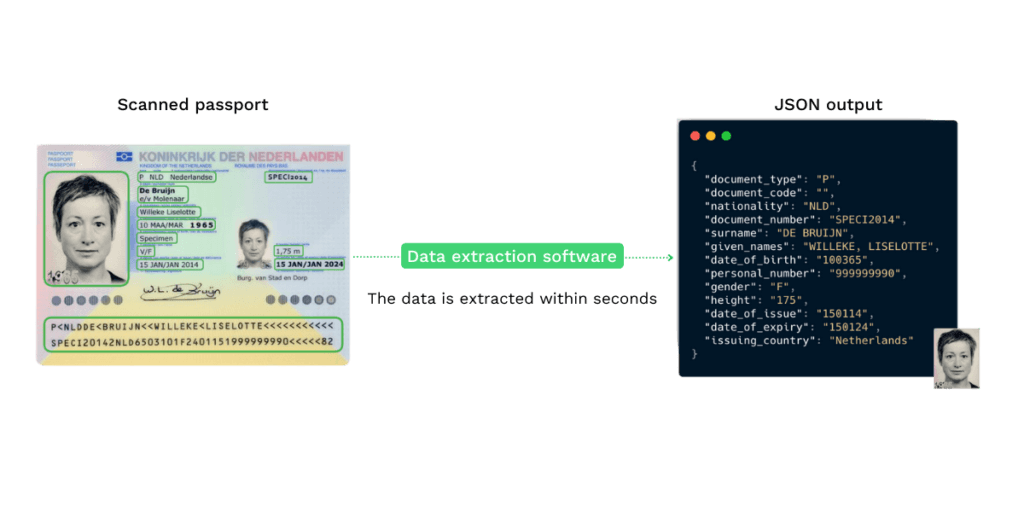
Veamos, pues, qué puede hacer por usted una solución de extracción. Tomemos un pasaporte como ejemplo.
Supongamos que su cliente cargó este pasaporte a la izquierda en un proceso de KYC y usted utiliza un software de extracción de datos para obtener la información que necesita. Por ejemplo, el nombre completo, el número de documento y el MRZ.
En 3 segundos el sistema es capaz de convertir la imagen no estructurada en los datos estructurados que aparecen en la imagen de la derecha.
Solución de extracción en la nube de Klippa
Klippa es una empresa de procesamiento inteligente de documentos. El software que construimos está hecho para automatizar los procesos de negocio que implican documentos. Nuestras soluciones ayudan a aumentar la productividad, la eficiencia y a reducir los costes y los errores humanos.
Klippa ofrece una solución integral de extracción de datos de documentos basada en la nube, que ayuda a las empresas a procesar automáticamente cualquier tipo de documento en cuestión de segundos.
¿Cómo funciona el proceso de extracción de documentos no estructurados?
Pero, ¿cómo se realiza la extracción de datos? El proceso de extracción de datos de un documento se puede explicar brevemente en un par de pasos. El proceso descrito es cómo funciona el proceso de extracción en Klippa.
- Cargar el documento
En primer lugar, hay que transformar el documento en papel en un documento digital. Normalmente, esto se hace escaneando el documento con un teléfono móvil. También se puede hacer subiendo un archivo al sistema. La entrada puede estar en múltiples formatos, como JPG, PDF, PNG, TXT y otros. - Imagen a TXT
Ahora que la carga está terminada, puede comenzar la extracción de datos. El único problema es que el ordenador aún no puede leer lo que hay en el documento o la imagen. Por lo tanto, hay que transformarlo en un archivo TXT. Para ello, entra en juego la tecnología OCR (reconocimiento óptico de caracteres). Esta tecnología extrae todos los datos del documento, pero aún no está estructurado. - Parsing a JSON
En el último paso, se necesita un analizador sintáctico para leer y comprender el texto del archivo. El parser convierte el archivo TXT en un archivo JSON estructurado. Una vez terminada la conversión, los datos pueden procesarse fácilmente en la base de datos. Además de JSON, también son posibles otras salidas como XML, XLSX y CSV. Nuestra API de OCR es muy flexible. - Verificar los datos extraídos con fuentes de terceros
Opcionalmente, podemos verificar los datos extraídos con fuentes de terceros. Puede tratarse de su propia base de datos, pero también de las bases de datos de la Cámara de Comercio y de las listas contra el blanqueo de capitales. Esto garantiza que la calidad de los datos es buena y se ajusta a la normativa.
API de extracción de datos
La solución de extracción de datos mencionada anteriormente está siendo utilizada por empresas de todo el mundo y en diversos sectores. Algunos ejemplos de sectores son los servicios financieros (por ejemplo, en los procesos KYC), el comercio minorista (por ejemplo, en las campañas de fidelización), la contabilidad, las aduanas y la sanidad.
Por supuesto, se puede intentar construir una cadena de extracción completa por uno mismo, pero eso es complicado y lleva mucho tiempo. También es costoso de mantener, y a menudo el ROI de construirlo será muy malo en comparación con el uso de un servicio existente.
Por lo tanto, implementar una API de terceros para la extracción de datos en documentos es una buena opción. A través de nuestra API, la solución puede integrarse en cualquier software existente. Como resultado, los datos se pueden extraer directamente en el software.
Contacta a nuestros especialistas
Si está buscando una forma de aumentar la productividad, mejorar la precisión, ahorrar mucho tiempo, permitir la escalabilidad y reducir los costes, la solución de extracción de Klippa es la elección correcta para usted.
¿Quieres saber más sobre el proceso de extracción, la técnica y el método que utilizamos? Ponte en contacto con uno de nuestros expertos o programa una demostración gratuita en línea a través del siguiente formulario de demostración.