
El uso de una solución de OCR ya es una práctica muy conocida. De hecho, en 2021, el tamaño del mercado mundial de OCR estaba valorado en 8.930 billones de dólares.
Por lo tanto, la mayoría de las empresas ya conocen la importancia del OCR para automatizar el procesamiento de documentos. Pero, ¿a qué se debe esto? La respuesta es sencilla. Las soluciones de OCR ofrecen una forma más fácil, rápida y eficaz de procesar los documentos con poca o ninguna intervención humana. Es el paso que las empresas necesitan dar para seguir siendo competitivas.
Muchas de estas empresas utilizan el OCR basado en plantillas, que funciona bien si hay que procesar sólo un tipo de documento en un idioma. Básicamente, funciona mejor con una estructura específica sin variaciones en el diseño.
Sin embargo, es posible que tengas que procesar varios tipos de documentos, como facturas, recibos y pasaportes, en diferentes idiomas. El OCR basado en plantillas no puede manejar este tipo de documentos de manera eficiente, ya que no están estructurados y no siempre siguen el mismo diseño.
En este caso, lo que necesitas es una alternativa al OCR basado en plantillas. Una alternativa que puede ayudarte a procesar datos no estructurados de una gran variedad de documentos: El OCR con Machine Learning.
Este artículo te enseñará más sobre el OCR con Machine Learning y cómo esta tecnología puede ayudarte a progresar. Pero primero, vamos a explicar con más detalle por qué el OCR basado en plantillas es sólo el primer paso para automatizar el procesamiento de tus documentos.
OCR de plantillas, el primer paso para automatizar el procesado de documentos
El OCR basado en plantillas suele conocerse como OCR tradicional. Como cualquier otro software de OCR, lee, extrae y proporciona datos para ser procesados más adelante. La característica principal del OCR basado en plantillas es que está capacitado para trabajar con tipos de documentos, formatos e idiomas específicos.
Además, sólo funciona con datos estructurados, como nombres, fechas, direcciones o información bursátil en formato estandarizado. En el caso del OCR basado en plantillas, los datos también tienen que encontrarse en el mismo lugar en el que el software ha sido entrenado para buscarlos.
Si utilizas el OCR basado en plantillas, probablemente no te hayamos contado nada nuevo hasta ahora. Ya sabes cómo se puede utilizar y lo que hace.
En ese caso, es probable que también conozcas los retos que presenta el uso del OCR basado en plantillas, especialmente cuando se trata de la escalabilidad. Con cada documento nuevo que quieres procesar, tienes que crear nuevas plantillas. Estas plantillas básicamente definen las reglas para el software y le indican dónde buscar la información.
¿Y si te decimos que existe una alternativa más avanzada? Una que no está limitada por plantillas y diseños específicos: El OCR con Machine Learning. En la siguiente sección, aprenderás más sobre Machine Learning y cómo puede facilitarte la vida.
¿Qué es Machine Learning?
El Machine Learning es una rama de la IA que utiliza modelos matemáticos de datos para guiar a los ordenadores en su aprendizaje sin necesidad de instrucciones humanas. En pocas palabras, el Machine Learning permite que una máquina reproduzca el comportamiento inteligente de un ser humano.
Además, Machine Learning aprende de forma continua, mejorando gradualmente su precisión, y hace predicciones futuras utilizando datos pasados y presentes.
Pero, ¿qué tiene que ver todo esto con el OCR? ¡Averigüémoslo a continuación!
OCR con Machine Learning
Machine Learning le permite al software de OCR a entender y reconocer el contexto general de un documento. Gracias a la capacidad de Machine Learning para hacer predicciones, el software de OCR no tiene problemas con la variedad de documentos que recibe. Con suficientes datos, puede predecir dónde aparecen determinados datos y los extrae de los documentos según corresponda.
Naturalmente, se necesitan muchos datos para que los modelos de predicción sean precisos. Sin embargo, no es necesario crear nuevas plantillas con reglas estrictas cada vez que se trabaja con un nuevo proveedor o tipo de documento.
Además, algunas soluciones de OCR con Machine Learning son capaces de detectar anomalías en el texto o en las estructuras de los documentos, por lo que se emplean para detectar el fraude en los documentos.
Ahora que ya se han explicado ambas tecnologías, es hora de ver realmente por qué el OCR con Machine Learning es la mejor alternativa al el OCR basado en plantillas.
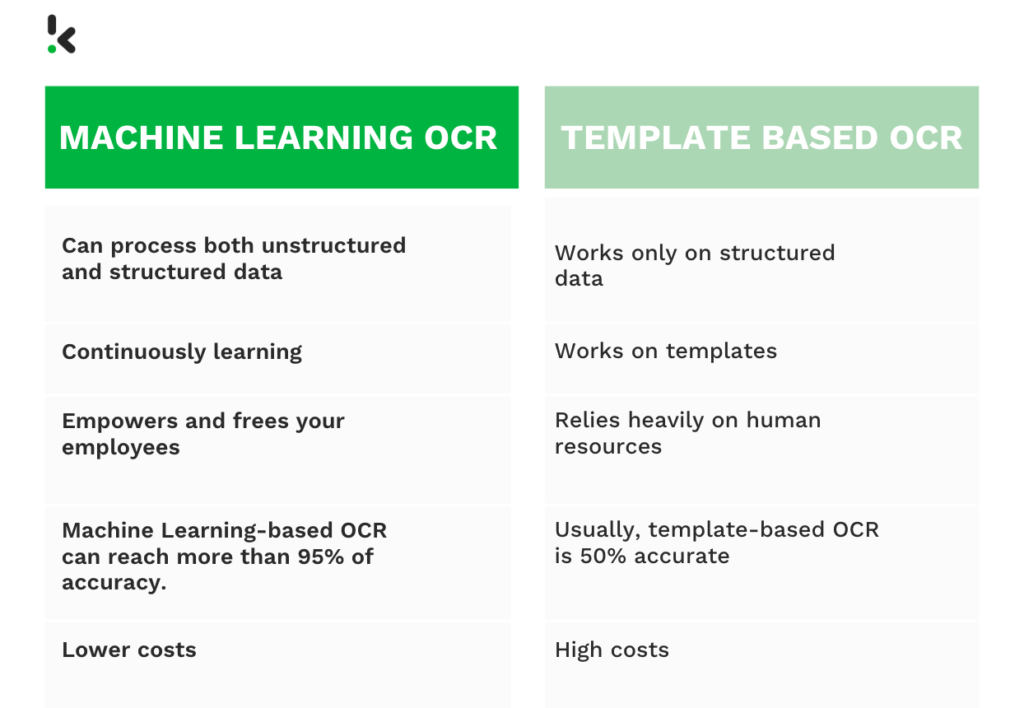
OCR basado en plantillas vs OCR con Machine Learning
Para demostrar que el OCR con Machine Learning es la mejor alternativa al OCR basado en plantillas, compararemos ambos métodos según los siguientes puntos:
- Capacidad para procesar datos estructurados y no estructurados
- Capacidad de aprendizaje
- Participación de los empleados
- Precisión
- Ahorro de tiempo y dinero
Tomemos cada uno de estos puntos y veamos por qué el OCR con Machine Learning es la mejor opción cuando se trata de procesar documentos.
Capacidad para procesar datos estructurados y no estructurados
El OCR con Machine Learning puede procesar tanto los datos estructurados como los no estructurados de un documento. Tomemos como ejemplo una factura. Si se entrena adecuadamente, el OCR con Machine Learning entenderá qué datos son montos, detalles del comerciante, partidas, etc. No en una plantilla de factura específica, sino en cada factura que recibas.
Dado que el OCR con Machine Learning trabaja con predicciones e imita la inteligencia humana, puede clasificar los documentos en función del contenido y la estructura. Todos los documentos pueden ser procesados con precisión siempre que el motor haya sido suministrado con suficientes datos.
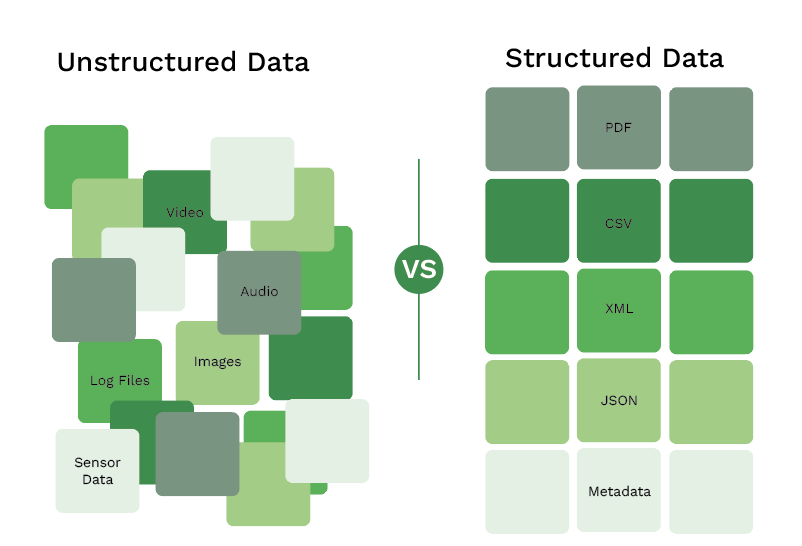
Con Machine Learning, puedes procesar todo tipo de documentos, tanto si contienen datos estructurados como no estructurados. En cambio, el OCR basado en plantillas sólo funciona con datos estructurados. Esto es un inconveniente importante, ya que limita la escalabilidad de tu organización respecto al procesamiento de documentos.
Capacidad de aprendizaje
El objetivo principal de Machine Learning es permitir que los ordenadores aprendan de forma autónoma sin la intervención humana. Vamos a explicar este proceso de aprendizaje con más detalle.
El OCR con Machine Learning se basa en modelos de predicción, construidos a partir de algoritmos y datos de entrenamiento. En primer lugar, los modelos se crean en función de todos los documentos y juegos de datos que ha procesado. En lugar de buscar una posición específica en un documento, los algoritmos predicen dónde deben estar los datos según todos los ejemplos que ya ha leído y procesado.
Basándose en la experiencia que el motor ha obtenido de otros documentos, el OCR con Machine Learning sigue aprendiendo. Por eso se necesitan menos recursos para mejorarlo.
Al necesitar menos recursos para mejorar la solución de OCR, tus empleados pueden trabajar en tareas de mayor importancia. Vamos a hablar de ello a continuación.
Participación de los empleados
El OCR con Machine Learning puede representar un gran cambio para tu empresa. Al automatizar más procesos, tus empleados se liberan del tedioso trabajo que supone la introducción de datos y tienen que dedicarse menos a la creación de plantillas para el software de OCR. Ahora tu equipo puede centrarse en tareas más importantes que contribuyen al crecimiento de tu empresa.
Hasta aquí todo bien, pero ¿qué pasa con la precisión de ambos métodos? Averigüemos si hay alguna diferencia entre los dos.
Precisión
La precisión es una de las principales razones por las que las empresas optan por la automatización cuando se trata de la extracción de datos.
El Machine Learning combinado con la tecnología OCR presenta un porcentaje de precisión superior al 95%. Para alcanzar este porcentaje de precisión, el modelo de Machine Learning analiza e interpreta los datos sin procesar. Este paso permite que las soluciones de OCR con Machine Learning reconozcan patrones y luego detecten y extraigan los datos con gran precisión.
Toda esta información y experiencia de comprensión del documento se utiliza luego para predecir otras similitudes en el próximo documento.
Mientras que el OCR convencional, como el que se basa en plantillas, tiene una precisión de extracción de datos de entre el 60% y el 85%, muchas soluciones más avanzadas integradas con IA y Machine Learning pueden llegar hasta el 99%.

Gracias a Machine Learning, el software de OCR es casi totalmente autónomo. Extrae datos con un alto índice de precisión. Esto te ayuda a ahorrarle tiempo a tu equipo y a reducir los costos operativos. Más sobre esto a continuación.
Ahorro de tiempo y dinero
En general, el OCR con Machine Learning es menos costoso que el OCR de plantilla. Para corroborar nuestro punto de vista, echemos un vistazo a los siguientes factores:
- Se necesitan menos aportes humanos – Una mayor eficiencia conduce a una reducción de los costos operativos.
- Mayor precisión – Un menor número de errores en la introducción de datos te permite ahorrar una gran cantidad de dinero a largo plazo.
- No es necesario crear costosas plantillas – Ahorra tiempo y dinero para tu organización.
A estas alturas, ya has aprendido que el OCR tradicional no es el software más eficiente para la extracción de datos. Utilizando el OCR con Machine Learning, puedes procesar todos tus documentos más rápidamente, con mayor precisión y menores costos.
Si quieres saber cómo el OCR con Machine Learning de Klippa puede ayudarte a alcanzar este objetivo, encontrarás más información a continuación.
Introduciendo Klippa DocHorizon
A estas alturas, ya has leído el blog y te has enterado de las diferencias entre el OCR basado en plantillas y el OCR con Machine Learning. ¿Hemos despertado tu interés por una solución de OCR con Machine Learning precisa y eficaz? Entonces sigue leyendo, la cosa se pone aún más interesante.
Klippa es un experto en el procesamiento automatizado de documentos. Nuestra empresa ofrece software de OCR inteligente, como el Klippa DocHorizon, que automatiza la extracción, clasificación, verificación y la anonimización de datos. Todo nuestro software está basado en Machine Learning e IA.
Klippa DocHorizon es capaz de procesar todo tipo de documentos: documentos financieros, documentos de identidad, documentos logísticos, etc. Pruébalo con los ejemplos que te ofrecemos a continuación o envíanos tú mismo un documento y comprueba el rendimiento de nuestra solución OCR con Machine Learning.
Try it Out Yourself
El documento se procesa en pocos segundos, generalmente entre 1 y 5 segundos. Tu documento se escanea y todos los datos se entregan en el formato estructurado que elijas.
¿Estás preparado para automatizar el procesado de tus documentos? Reserva una demostración con uno de nuestros especialistas, quienes estarán encantados de mostrarte las posibilidades.