
Dado que los datos son el nuevo oro del mundo empresarial, resulta increíblemente inconveniente para las empresas que información valiosa se quede atascada en formatos de documentos no estructurados, como un PDF. La razón es que los formatos de documentos no estructurados no son legibles digitalmente. Esto significa que, para trabajar con los datos de un documento PDF, hay que extraer la información manualmente y guardarla en la base de datos.
La extracción manual de información es un proceso aceptable siempre que las empresas sólo trabajen con un puñado de documentos PDF. En cuanto una organización necesita procesar cantidades mayores, el proceso manual se vuelve demasiado lento, caro y propenso a errores.
Aquí es donde un parser de PDF puede sustituir al proceso manual tradicional de extracción e introducción de datos. Con el parsing de datos es posible convertir rápidamente datos de un formato a otro, como un archivo PDF a un archivo JSON legible digitalmente.
En este blog hablaremos de qué es un parser de PDF y cómo se analizan los datos PDF. A continuación, explicaremos por qué las empresas deberían utilizar un procesador de PDF en general, y terminaremos el blog con una solución de automatización del parsing de PDFs.
¿Qué es un parser de PDF?
Un parser de PDF (también conocido como PDF scraper) es un software capaz de identificar y extraer datos de documentos PDF. Esto significa que el texto del documento (es decir, los datos no estructurados) se convierte en datos estructurados que pueden ser leídos digitalmente. De este modo, se desbloquea información valiosa que, de otro modo, permanecería inaccesible en el formato no estructurado.
En general, un parser de PDF te permite:
- Extraer texto de los PDFs
- Extraer imágenes de PDFs
- Extraer tablas y otras estructuras de los PDFs
- Convertir el archivo PDF a archivos JSON, XML y HTML
- Utilizar datos estructurados para procesos empresariales
Ahora que ya sabemos qué es un parser de PDF, veamos cómo funciona el parsing para que también puedas utilizarlo en tu negocio.
¿Cómo procesar datos PDF?
Los parsers de PDF utilizan algoritmos avanzados para identificar los datos de un documento PDF. Siempre que el parser de PDF esté bien entrenado, será capaz de identificar todos los tipos de elementos básicos del documento.
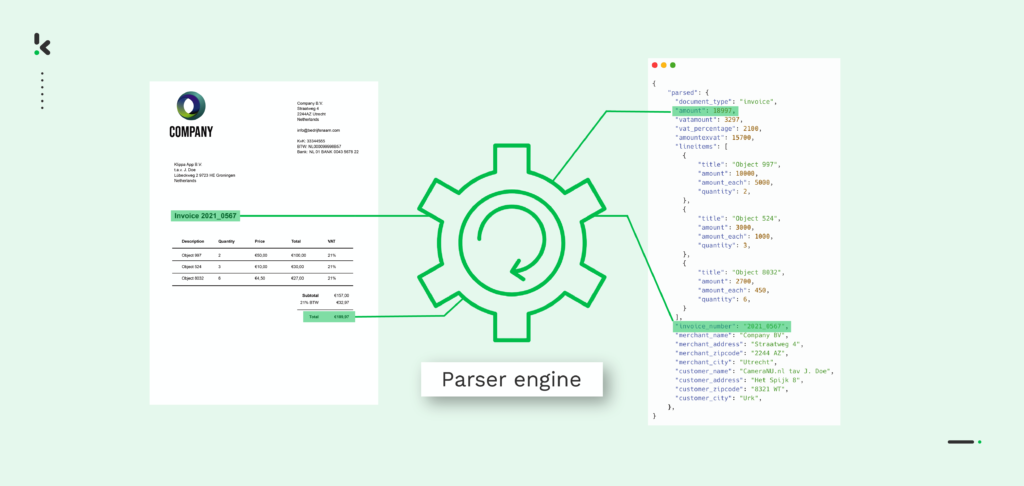
En este proceso participa el Reconocimiento Óptico de Caracteres (OCR) y otras tecnologías de IA como el Procesamiento del Lenguaje Natural (NLP) y el Machine Learning (ML). Sólo con la ayuda de estas tecnologías, puede el parser de PDF escanear un archivo PDF y procesar los datos que contiene.
El proceso podría ser el siguiente:
- Subir un archivo PDF al parser → Hay que subir el PDF a una API para iniciar el proceso de parsing. Es importante que el PDF no contenga ruido de fondo.
- Pre-procesamiento del PDF → Se puede optimizar el brillo del PDF escaneado o mejorar la escala de grises para aumentar la precisión de reconocimiento de los datos.
- Conversión de PDF a texto → En este paso, el documento PDF puede convertirse en un archivo de texto (TXT). Se reconoce cada parte del documento (importe total, dirección, etc.) y luego se extraen los datos.
- Conversión a datos estructurados → En este último paso, el archivo de texto se convierte a un formato estructurado legible digitalmente, como JSON. Ahora, es posible procesar los datos del PDF fácilmente en tu base de datos.
En este punto puede que te estés preguntando qué tipo de datos puede extraer realmente un parser de PDF para ayudarte a decidir si un parser de PDF rinde de acuerdo a tus necesidades.
¿Qué datos de los PDFs se pueden procesar?
Para la mayoría de las empresas, los archivos PDF son la mejor opción para muchos tipos de documentos. Piensa en libros, presentaciones, facturas, órdenes de compra e informes que a menudo se comparten entre organizaciones en forma de archivo PDF.
Mientras que los PDFs son un gran formato de archivo para integrar contenido enriquecido, los parsers de PDF te permiten extraer la siguiente información de ellos:
- Párrafos de texto → Aunque se trata de la forma más básica de datos, copiarlos y pegarlos manualmente daría lugar a problemas de formato. Un parser de PDF es capaz de extraer texto con el formato adecuado para que puedas utilizarlo fácilmente en otros procesos.
- Tablas y listas → En este caso, vale la pena hacer una investigación adicional, ya que solo los parsers de PDF más modernos pueden identificar la presencia de tablas. La mayoría de los parsers de PDF antiguos consideran las tablas como un párrafo y se hacen un lío al interpretarlas, lo que significa que es necesario extraer los datos manualmente.
- Imágenes → Un parser de PDF es capaz de extraer las imágenes presentes en el documento PDF. Esto es especialmente útil cuando quieres reutilizar imágenes del documento en otro lugar y te evitas la molestia de tomar capturas de pantalla de baja calidad.
- Campos de datos individuales (números de seguimiento, códigos QR, códigos de barras, etc.) → Si un PDF contiene campos con datos individuales, un parser de PDF puede extraerlos con precisión y organizar los datos de forma ordenada en un campo concreto.
Teniendo esto en cuenta, ahora deberíamos echar un vistazo a por qué un parser de PDF es valioso para las empresas.
¿Por qué deberían las empresas utilizar el parsing de PDF?
Los diferentes diseños y estructuras de los archivos PDF los hacen complejos y difíciles a la hora de extraer datos de ellos. Por eso, la extracción manual de datos lleva mucho tiempo y, por tanto, puede costar mucho dinero. También da lugar a diversos errores y a una extracción de datos inexacta.
Con un parser de PDF se pueden evitar los errores y la extracción inexacta. Como hemos visto anteriormente, con la ayuda de las tecnologías modernas, un parser de PDF es capaz de identificar y extraer información de los PDFs con precisión y sin problemas de formato.

Como puedes imaginar, esto lleva a una reducción significativa del tiempo dedicado al procesamiento de PDFs, lo que a la larga reduce costos y el uso de otros recursos que pueden dedicarse a tareas que aporten más valor. Una duración reducida del procesamiento de documentos tiene como resultado flujos de trabajo optimizados, lo que facilitará las operaciones de tu empresa.
Como puedes leer, un software para el parsing de PDFs aporta varios beneficios. Por eso hay varias empresas de software que han desarrollado una solución con la que puedes beneficiarte. Una de estas soluciones de software es Klippa DocHorizon.
Automatización del parsing de PDFs con Klippa DocHorizon
Klippa DocHorizon es nuestro software de OCR basado en la IA que puede utilizarse para procesar información de PDFs y otros documentos con los que trabaje tu empresa. Con nuestra tecnología de OCR, puedes extraer con precisión datos relevantes de formatos de datos no estructurados (como PDFs) y convertirlos al formato que quieras.
Además, DocHorizon puede clasificar tipos de documentos, verificar y anonimizar datos, todo ello eliminando la introducción manual de datos. DocHorizon reconoce una gran variedad de documentos en más de 100 idiomas.
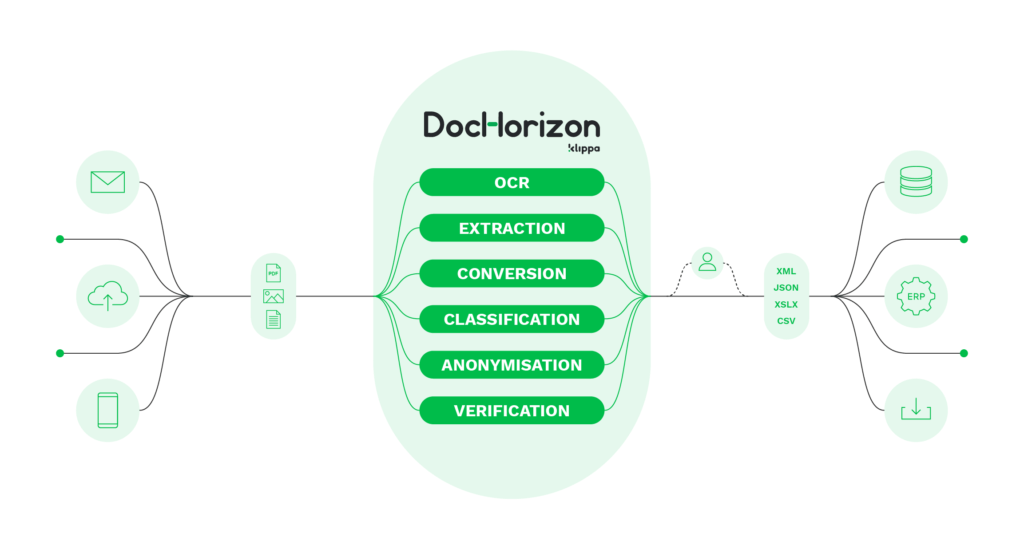
Nuestra solución está disponible a través de API y SDK, lo que le permite a tus empleados extraer y guardar rápidamente toda la información relevante en la base de datos de tu organización.
¿También quieres transformar tus datos atascados en formatos inutilizables a datos listos para el negocio? Estaríamos encantados de mostrarte cómo hacerlo con nuestra solución. Sólo tienes que reservar una demostración gratuita a continuación o ponerte en contacto con uno de nuestros expertos.