
En el rápido panorama empresarial actual, empresas de todos los tamaños se enfrentan a una enorme cantidad de datos. Esto incluye una amplia gama de datos no estructurados, es decir, datos que no están organizados de forma ordenada en un formato de base de datos estructurada tradicional. Ejemplos de datos no estructurados son correos electrónicos, textos, imágenes, vídeos, etc.
Estudios recientes sugieren que hasta el 80% de estos nuevos datos no están estructurados, lo que plantea importantes retos a las empresas a la hora de capturarlos, cuantificarlos, procesarlos y archivarlos de forma eficaz. La capacidad de extraer información esencial de estos datos y convertirla en datos listos para el negocio determinará si las empresas pueden obtener una ventaja competitiva. Aquí es donde entra en juego el procesamiento (parsing) de archivos. Pero, ¿en qué consiste realmente?
En este blog, vamos a explicar qué es el parsing de archivos, las tecnologías que lo sustentan, cómo las empresas pueden aprovecharlo, y cómo Klippa puede ayudarte a automatizar el parsing de archivos.
¿Listo? ¡Empecemos!
¿Qué es el parsing de archivos?
El parsing de archivos es una técnica que las empresas utilizan para extraer información esencial de datos no estructurados. Consiste en analizar el contenido de archivos, como documentos de texto o imágenes, para extraer puntos de datos relevantes y convertirlos en un formato utilizable.

A menudo, las empresas utilizan el parsing de archivos en el procesamiento de datos para convertir datos no estructurados, como archivos PDF, en formatos listos para el uso empresarial, como CSV, XML, JSON, XLMS, etc. El procesado eficaz y preciso de archivos desempeña un papel importante en muchos sectores y ámbitos en los que la entrada de datos es elevada y el procesamiento de datos es una tarea crítica.
Entonces, ¿cómo pueden las empresas procesar la información de los archivos? A continuación responderemos a esta pregunta.
¿Cómo parsear archivos?
Supongamos que tu empresa recibe archivos PDF y necesitas obtener la información relevante de ellos para almacenarla en tu base de datos o introducirla en tu sistema informático. Normalmente, esto lo harían los empleados de back-office, que leerían el archivo PDF y copiarían manualmente la información en el sistema informático.
Con un parser de archivos, puedes procesar (leer) el archivo PDF, extraer la información necesaria y exportarla, por ejemplo, como un archivo JSON en cuestión de segundos. Este archivo puede enviarse y procesarse posteriormente en tu sistema informático, sin necesidad de intervención humana.
Estos son algunos ejemplos comunes de empresas que utilizan el parsing de archivos para extraer datos o convertirlos de formato no estructurado a estructurado:
- Convertir imágenes a texto para reducir la introducción manual de datos
- Exportar datos de archivos PDF a JSON, CSV, XML y muchos otros formatos
- Parsing a través de correos electrónicos para extraer información significativa
- Extraer pares clave-valor de documentos como facturas y recibos
- Extraer datos relevantes de documentos de identidad para la incorporación de clientes
Por supuesto, hay muchos más ejemplos en los que se puede utilizar el parsing de archivos para obtener la información extraída de documentos no estructurados. Ahora que ya sabes dónde se puede utilizar el parsing de archivos, echemos un vistazo a sus componentes más esenciales:
- OCR
- Machine Learning
- Lenguajes de Programación
OCR
El Reconocimiento Óptico de Caracteres (OCR) es la tecnología más esencial en el parsing de archivos, ya que permite extraer información de imágenes o documentos escaneados. Los procesadores de archivos utilizan la tecnología OCR para convertir imágenes a texto que pueda ser leído por máquinas. Este texto convertido se procesa, analiza y transforma en datos estructurados para su uso posterior.
Imagina tener que procesar numerosas facturas escaneadas e introducir manualmente toda la información relevante en un sistema ERP o de contabilidad. Esto puede llevar mucho tiempo y ser propenso a errores. Con el OCR, este esfuerzo manual puede eliminarse, ya que puede extraer texto de documentos escaneados.
Sin embargo, el OCR puede extraer más información de la necesaria desde el punto de vista empresarial. Aquí es donde los parsers de archivos marcan la diferencia, ya que pueden leer e interpretar los datos, produciendo un formato de archivo estructurado que contiene sólo la salida significativa para su uso posterior.
El siguiente ejemplo muestra cómo un analizador de archivos basado en OCR extrae información de la imagen de una factura. Inicialmente, la factura se digitaliza mediante OCR y, a continuación, los campos de datos necesarios, como el nombre y la dirección del comerciante, se identifican mediante el Reconocimiento de Entidades Nombradas (NER). Por último, el motor de procesamiento extrae la información en pares clave-valor que pueden convertirse a un formato legible como JSON. Este proceso permite una extracción eficaz y precisa de los datos de diversos formatos de archivo.
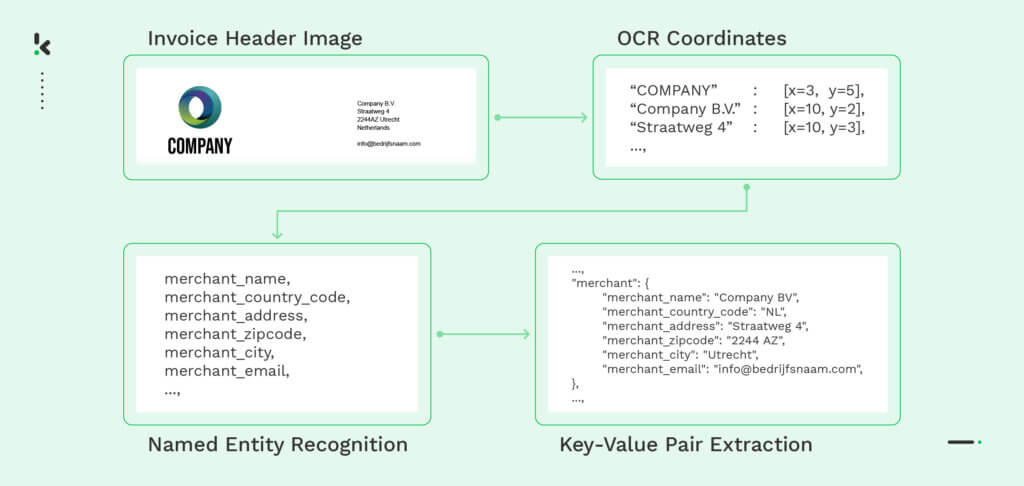
Machine Learning
Los algoritmos basados en Machine Learning, que es un subgrupo de la Inteligencia Artificial (IA), se emplean para mejorar las capacidades de los procesadores de archivos de diversas maneras. Por ejemplo, los algoritmos de Machine Learning pueden entrenarse para reconocer información específica o patrones de documentos para la extracción de datos.
Los parsers de archivos sin Machine Learning pueden tener dificultades para extraer datos con precisión en casos complejos. En estos casos, se pueden utilizar algoritmos de corrección ortográfica, validación de datos o limpieza de datos para identificar y corregir errores en los datos analizados, como faltas de ortografía, valores omitidos o formatos de datos incoherentes. La incorporación del Machine Learning a los parsers mejora la precisión y el rendimiento de las tareas de extracción de datos y procesamiento de archivos.
Lenguajes de Programación
Existen varios lenguajes de programación que proporcionan bibliotecas y funciones integradas o de terceros que le permiten a los desarrolladores construir parsers para extraer y transformar la información almacenada en archivos que tienen formatos o estructuras de datos específicos.
Algunos lenguajes de programación populares para parsers de archivos incluyen:
- Python
- Java
- Javascript
- Golang
- Ruby
Python es un lenguaje de programación versátil conocido por su sencillez y legibilidad. Cuenta con un rico ecosistema de bibliotecas, como parsers de archivos CSV, JSON, XML y binarios, que facilitan el procesamiento sintáctico y la manipulación de archivos en distintos formatos.
Java, un lenguaje de programación muy popular, es conocido por su independencia de plataformas y su sólido soporte para la programación orientada a objetos. Ofrece una amplia gama de bibliotecas que proporcionan amplias capacidades de parseo de archivos; Apache POI para archivos de Microsoft Office, Jackson para archivos JSON y JAXB para archivos XML. Estas bibliotecas hacen que Java sea una opción versátil para tareas de procesamiento de archivos.
JavaScript es un lenguaje de scripting muy popular que se utiliza principalmente para el desarrollo web. Dispone de funciones de procesamiento de JSON integradas, así como de amplias bibliotecas que permiten el parsing de archivos; PapaParse para el parsing de CSV y xml2js para el parsing de XML.
Go, también conocido como Golang, es un lenguaje de programación estáticamente tipado y compilado desarrollado por Google. Go cuenta con bibliotecas estándar que proporcionan sólidas capacidades de procesamiento de archivos; encoding/csv para el parsing CSV, encoding/json para el parsing JSON y encoding/xml para el parsing XML.
Ruby es un lenguaje de programación dinámico y orientado a objetos, conocido por su elegante sintaxis y facilidad de uso. Tiene soporte integrado para el parsing de archivos de texto, y también tiene bibliotecas; CSV para el parsing CSV, Nokogiri para el parsing XML y HTML, y JSON para el parsing JSON.
Estos son algunos ejemplos de los numerosos lenguajes de programación que pueden utilizarse para crear procesadores de archivos. Como ya te habrás dado cuenta, la selección de un lenguaje de programación depende de las necesidades específicas del formato de archivo que se esté procesando, de las consideraciones de rendimiento y de la familiaridad con el lenguaje.
Sin embargo, la amplia versatilidad de Python lo convierte en un lenguaje de programación muy popular en el ámbito del parsing de archivos. En las siguientes secciones, veremos con más detalle cómo se utiliza Python para procesar datos de archivos.
Parsing en Python
Como se mencionó anteriormente, Python es una de las opciones más populares como lenguaje de programación de procesamiento de archivos. Esto se debe no sólo a su versatilidad, sino también a su facilidad de uso y a la amplia disponibilidad de bibliotecas y módulos. Gracias a las sólidas capacidades de manipulación de cadenas de Python, se ha convertido en un lenguaje de preferencia para el parsing de varios tipos de archivos, incluyendo texto, CSV, XML, JSON, y más.
Una de las principales ventajas de Python para las tareas de parsing es su amplio ecosistema de bibliotecas. Python ofrece un amplio conjunto de módulos integrados para operaciones con archivos, expresiones regulares y manipulación de cadenas, lo que hace que las tareas de procesamiento sean sencillas y eficientes. Además, hay muchas bibliotecas de terceros que proporcionan funcionalidades especializadas para procesar formatos de archivo específicos.
Además, la sintaxis fácil de entender de Python lo convierte en un lenguaje fácil de usar para tareas de parsing de archivos. Con la infraestructura adecuada, puedes extraer, manipular y validar rápidamente datos de archivos con estructuras complejas con el parsing de Python. Las capacidades de multiprocesamiento de Python también le permite a los desarrolladores paralelizar las tareas de parsing, mejorando el rendimiento y la escalabilidad.
Por lo tanto, si quieres crear tu propio parser, Python es el lenguaje de programación que recomendamos. Sin embargo, crear tu propio parser en Python puede consumir muchos recursos (tiempo y dinero) y requerir amplios conocimientos de programación de los que tu organización puede no disponer. Por este motivo, en la siguiente sección hemos enumerado algunas soluciones que no requieren que construyas tus propios procesadores.
Parsing automatizado de información de archivos
Las empresas que buscan reducir el esfuerzo humano, el tiempo y los gastos ya no pueden permitirse extraer manualmente la información de los archivos e introducirla en un sistema informático. Dicho esto, las empresas pueden automatizar el parsing de archivos utilizando diversas tecnologías. A continuación, algunas opciones:
- Software OCR integrado con IA
- Aplicaciones Web
- Robots y Bots
Software OCR integrado con IA
El software de Reconocimiento Óptico de Caracteres (OCR) permite escanear documentos y extraer texto en un formato legible automáticamente. Sin embargo, para automatizar el parsing de archivos, a menudo es necesario usar software de OCR que incluya IA. Con una solución de este tipo, las empresas pueden crear un flujo de trabajo optimizado para procesar automáticamente la información de archivos como facturas, recibos, tarjetas de identidad, pasaportes, licencias de conducir, formularios y muchos otros.
La IA puede ayudar de muchas maneras, no sólo en el procesamiento, sino también en la verificación de la autenticidad de un documento, la detección de fraudes o el enmascaramiento de datos sensibles. Por eso sería más beneficioso para las empresas integrar un software de OCR en la nube que desarrollar internamente un simple parser con muchas limitaciones utilizando Python o cualquier otro lenguaje de programación.
Aplicaciones Web
Hay varias aplicaciones web y herramientas en línea disponibles para que las empresas procesen archivos de forma gratuita. Algunas de estas herramientas pueden procesar automáticamente datos de archivos como PDF, CSV, hojas de cálculo Excel y otros formatos de archivo comunes. A menudo, los usuarios pueden subir sus archivos a estas aplicaciones web, que utilizan algoritmos de parseo para extraer los datos relevantes y convertirlos en un formato utilizable. Echa un vistazo, por ejemplo, a nuestro conversor gratuito de imágenes a texto.
Es importante ser consciente de las limitaciones de estas herramientas. Pueden ser útiles para pequeños volúmenes de parseo de archivos, pero hay limitaciones en el número de archivos que se pueden analizar con una cuenta gratuita, y los costos pueden acumularse rápidamente. La privacidad de los datos también es una preocupación importante. ¿Realmente dan prioridad estas herramientas gratuitas a la seguridad de los datos de los usuarios, o se centran sobre todo en ganar dinero rápidamente? Aunque puede ser prudente evitar depender únicamente de estas herramientas, todavía podría valer la pena explorarlas como una opción.
Robots y Bots
Los Robots y Bots, en el contexto de la Automatización Robótica de Procesos (RPA), son programas de software que pueden utilizarse para el parsing automatizado de datos de archivos. Dentro de la RPA, los robots o bots se encargan de la automatización de tareas manuales, eliminando la necesidad de intervención humana.
Una de las principales ventajas de utilizar robots RPA para el parsing de datos de archivos es su alto nivel de precisión y eficiencia. Los robots RPA pueden trabajar 24 horas al día, 7 días a la semana, sin intervención humana, lo que reduce el riesgo de errores causados por la introducción manual de datos y aumenta la productividad. Además, pueden conectarse sin esfuerzo con diversas fuentes de datos, APIs e integraciones de terceros, lo que ofrece una ventaja significativa a la hora de recolectar y procesar datos para parsearlos de diversas formas.
Parsing de archivos con Klippa DocHorizon
El software de OCR Klippa DocHorizon, basado en la IA y preparado para el futuro, sirve a varias empresas para automatizar los flujos de trabajo de procesamiento de documentos, incluido el parsing de archivos. Se trata de una solución de procesamiento de archivos potente y versátil que le permite a las empresas extraer datos valiosos de varios formatos de archivo de forma eficiente.
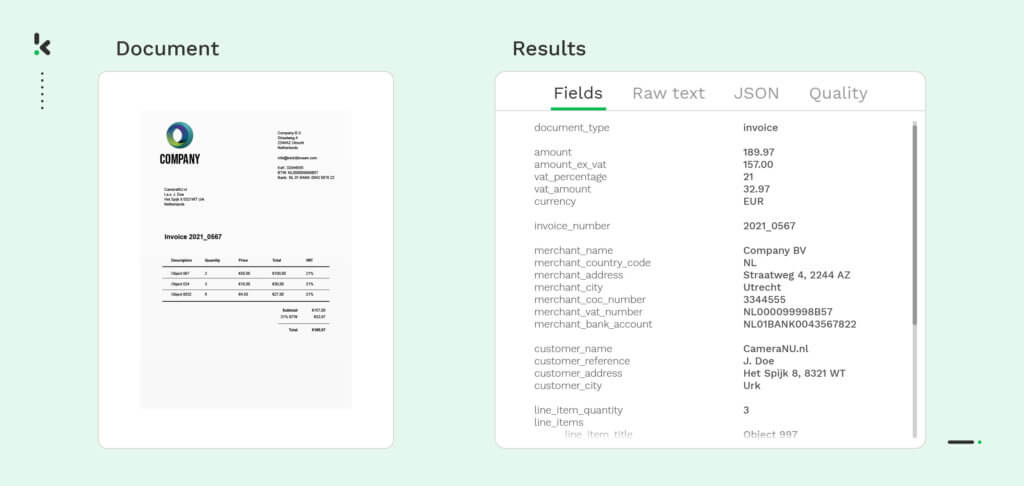
Además del parsing de archivos, DocHorizon puede verificar la autenticidad de un documento, detectar documentos fraudulentos, clasificar documentos y enmascarar datos confidenciales automáticamente, haciendo que tu flujo de trabajo documental esté preparado para el futuro. Puedes integrar DocHorizon en tu flujo de trabajo o sistemas de software existentes utilizando nuestra API.
Si estás interesado en potenciar tus aplicaciones móviles actuales con funcionalidades de OCR o parsing de archivos, también puedes consultar nuestros SDK de escaneo móvil. Nuestras soluciones ofrecen numerosas ventajas, entre ellas:
- Extracción de datos de hasta el 99% con OCR interno potenciado por la IA
- Escalabilidad más allá de tu imaginación
- Reducción de gastos generales gracias a la automatización
- Minimización de los errores de introducción de datos
- Cumplimiento de las regulaciones de privacidad de datos, ya que los datos procesados no se almacenan en los servidores de Klippa
¿Listo para transformar tus datos no estructurados a información útil? Programa una demo gratuita usando el formulario a continuación o ponte en contacto con uno de nuestros expertos para obtener información.