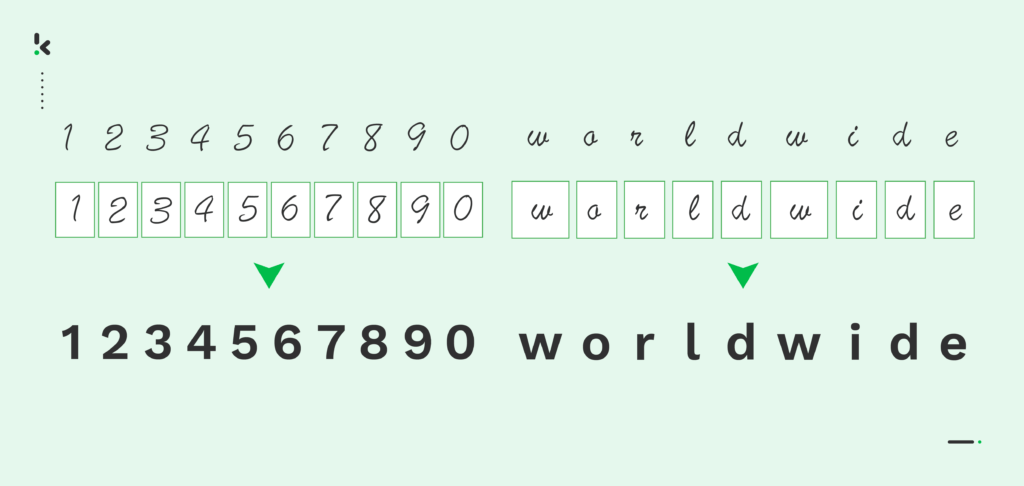
Hacer más con menos es un objetivo que se escucha a menudo en los equipos administrativos y los directorios de las empresas. Tanto si se trata de automatizar flujos de trabajo como de simplificar procesos, las organizaciones siempre buscan ganar eficiencia y conseguir ahorros.
Una solución de Procesamiento Inteligente de Documentos (IDP) logra estos objetivos ayudando a los empleados a trabajar de forma más inteligente, ejecutar más rápido y aumentar su productividad.
No se puede subestimar la importancia de estas tecnologías. Un informe de Goldman Sachs de 2018, por ejemplo, reveló que las empresas gastan 2,7 trillones de dólares en el procesamiento manual de pagos en papel, lo que representa una gran carga en términos de tiempo y dinero.
Este es un gran problema para las empresas que manejan grandes cantidades de documentos impresos. Como el número de documentos que hay que procesar aumenta cada año, las empresas no pueden limitarse a seguir contratando a más personas para procesarlos si quieren mantener unos resultados positivos. Esto plantea problemas de escalabilidad.
Por suerte, existen tecnologías que pueden ayudar a las empresas a resolver estos problemas, como el Reconocimiento Inteligente de Caracteres (ICR). El ICR se utiliza para extraer texto de imágenes o documentos escaneados, como recibos y facturas, y funciona de forma similar al Reconocimiento Óptico de Caracteres (OCR).
Pero, ¿cómo puede beneficiar esta tecnología a tu organización? ¿Y cuáles son las diferencias entre el OCR tradicional y el ICR?
En este blog encontrarás la definición de ICR, conocerás las diferencias entre OCR e ICR, descubrirás cómo funciona ICR y cómo se puede utilizar. ¿Estás curioso? ¡Empecemos!
¿Qué es el ICR?
En pocas palabras, el Reconocimiento Inteligente de Caracteres (ICR) es una tecnología utilizada para extraer texto escrito a mano de imágenes o documentos y convertirlo a un formato legible digitalmente.
Técnicamente, el ICR es una variante del Reconocimiento Óptico de Caracteres. Por eso a veces puede denominarse OCR.
Sin embargo, a diferencia de la tecnología OCR, que se centra en caracteres impresos o computerizados, ICR utiliza Machine Learning e IA para reconocer varios estilos y fuentes manuscritas. Por eso, puede considerarse una versión avanzada del OCR.
La tecnología ICR actualiza sus capacidades de aprendizaje cada vez que se utilizan nuevos patrones escritos a mano. De este modo, la precisión de los datos puede mejorar con el tiempo.
Como ya se ha mencionado, ICR puede confundirse a menudo con OCR y viceversa. La siguiente sección está dedicada a ayudarte a entender las diferencias entre ambos.
Diferencias entre el ICR y el OCR tradicional
El Reconocimiento Inteligente de Caracteres (ICR) y el Reconocimiento Óptico de Caracteres (OCR) comparten muchas similitudes, lo cual es comprensible dado que el ICR es un subgrupo del OCR.
Sin embargo, comparar el ICR con el OCR tradicional basado en plantillas es otra historia. Estas dos tecnologías difieren significativamente entre sí, como se ilustra a continuación.
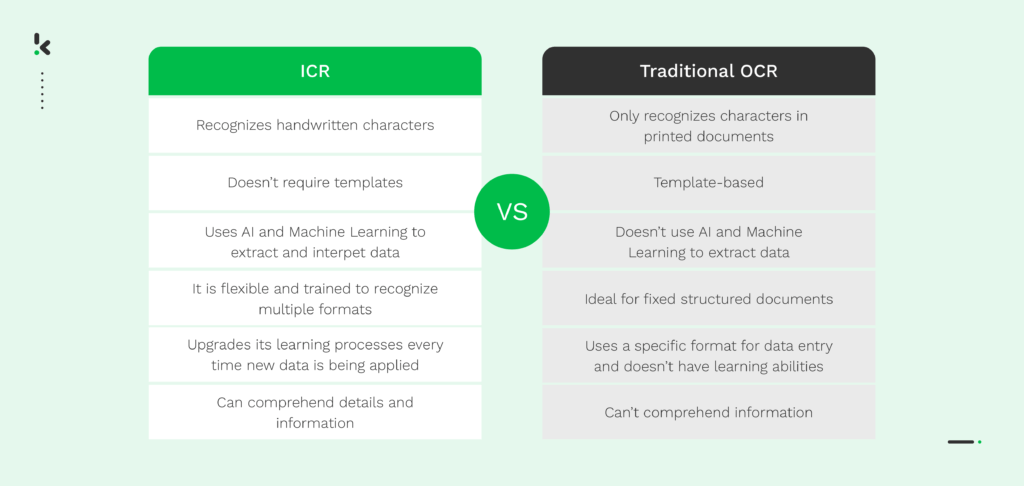
En pocas palabras, el reconocimiento inteligente de caracteres (ICR) permite convertir texto manuscrito en datos que una máquina puede comprender, buscar y modificar fácilmente. A diferencia del OCR tradicional, ICR utiliza IA y Machine Learning para comprender los detalles y extraer información de los documentos, lo que facilita su integración en diversos flujos de trabajo empresariales.
ICR es una excelente adición a tu proceso de captura de datos si trabajas con muchos documentos escritos a mano que contienen información estructurada y no estructurada.
Pero, ¿cómo funciona? Aprende más en la siguiente sección.
¿Cómo funciona el ICR?
El ICR funciona de forma similar al OCR en el reconocimiento de caracteres. La única diferencia es que el ICR puede reconocer caracteres escritos a mano, cosa que el OCR tradicional no puede hacer.
Para entender mejor cómo aborda el ICR estos problemas, examinemos con más detalle los siguientes pasos del proceso ICR:
- Paso 1: Pre-procesamiento de la imagen
- Paso 2: Segmentación
- Paso 3: Reconocimiento
- Paso 4: Post-procesamiento del resultado
Paso 1: Pre-procesamiento de la imagen
Normalmente, los datos en bruto no pueden procesarse directamente. Para extraer con precisión los datos de los documentos, primero hay que pre-procesar las imágenes. Esto significa que hay que mejorar la calidad de la imagen para conseguir una calidad aceptable para el reconocimiento.
Durante la fase de pre-procesamiento se utilizan muchas técnicas para obtener una imagen más clara y mejor. Estas técnicas pueden incluir:
- Enderezamiento – El proceso de enderezar y ajustar el ángulo de una imagen después de haber sido escaneada.

- Eliminación del ruido – Esta estrategia incluye la eliminación de texturas de fondo, trazos que interfieren y otros elementos similares, así como el cambio del rango de intensidad de los píxeles individuales para que coincidan con los valores promedio de los píxeles que los rodean.

- Binarización – A menudo denominada umbralización de imágenes, la binarización es el proceso de convertir una imagen en escala de grises en una imagen en blanco y negro. Esta técnica permite separar con mayor precisión el texto del fondo.

- Normalización – Este proceso tiene como objetivo eliminar los casos de inclinación y desnivel. Estos términos se refieren a la inclinación a nivel de carácter (“inclinación”) o a nivel de palabra (“pendiente”), como puedes ver en la siguiente imagen.

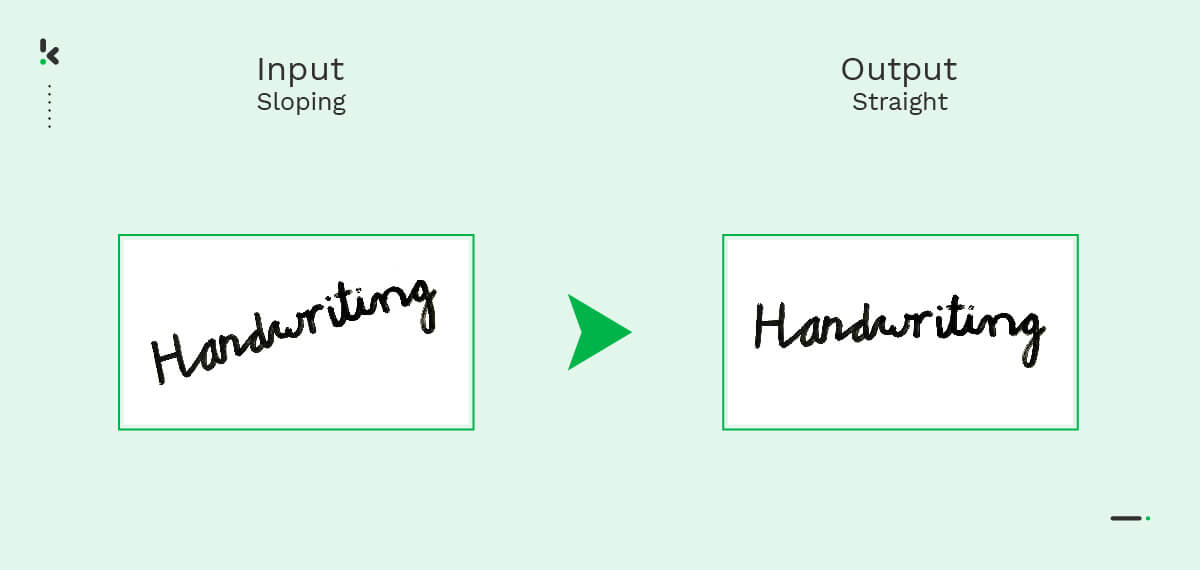
El resultado final de la etapa de pre-procesamiento debe ser una imagen clara con caracteres fácilmente identificables y sin elementos que distraigan la atención.
Paso 2: Segmentación
La segmentación es el proceso de separar la información dentro del texto para facilitar el análisis posterior de los datos. En esta técnica intervienen las siguientes categorías:
- Segmentación de líneas – Aislamiento de las líneas de texto en la imagen.

- Segmentación de palabras – Aislamiento de las palabras en las líneas de texto.

- Segmentación de caracteres – Aislamiento de caracteres en las palabras.

Paso 3: Reconocimiento
Tras la segmentación, se reconocen los fragmentos de palabra aislados. Este proceso se realiza mediante modelos pre-entrenados, lo que significa que los caracteres se reconocen utilizando como punto de referencia una base de datos preexistente.
Esto funciona otorgando una puntuación a cada carácter. Normalmente, el carácter reconocido es el que tiene la puntuación más alta, cuando se compara con los que están dentro de la base de datos predeterminada.
Como ya se ha mencionado, el ICR tiene capacidad de aprendizaje, lo que significa que mejora su precisión cada vez que se cargan en el sistema nuevos estilos manuscritos y fuentes.

Paso 4: Post-procesamiento del resultado
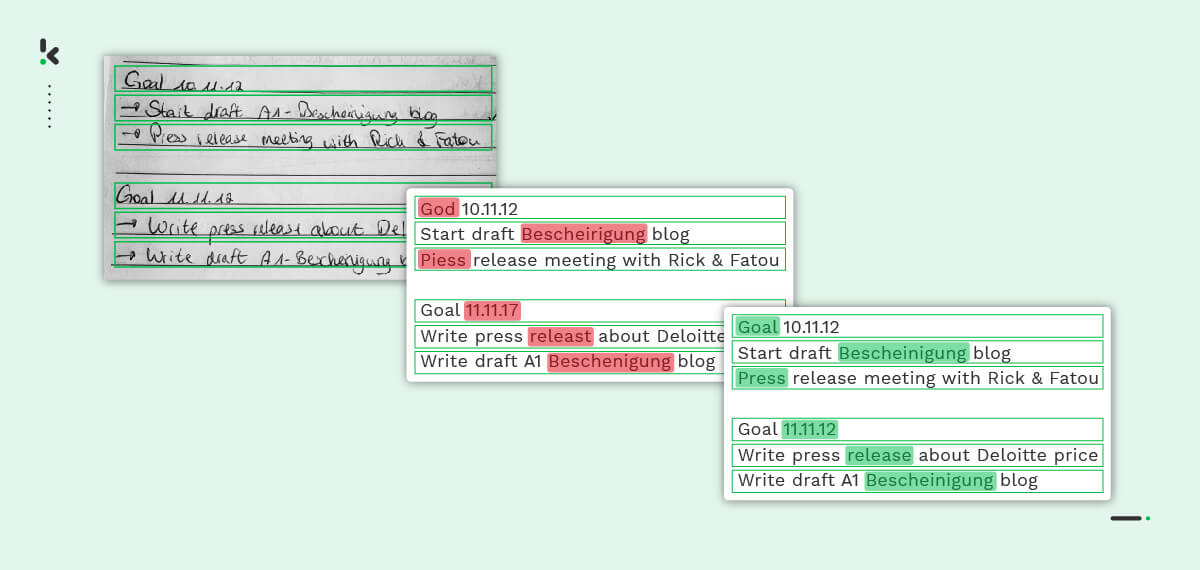
Este paso es crucial para mejorar la precisión de la extracción de datos, ya que se centra por completo en los métodos y algoritmos que producen los mejores resultados.
Una vez corregidos y comprobados los errores ortográficos, el ICR indica las anomalías (si se detectan) para que el usuario las corrija.
Una vez corregidos y clasificados con precisión, los datos pueden almacenarse en la base de datos que se elija.
Con ICR, las empresas pueden transformar datos no estructurados, como texto escrito a mano, en datos listos para la empresa que pueden transmitirse posteriormente en sus flujos de trabajo relacionados con documentos. Por supuesto, esto conlleva innumerables beneficios.
Beneficios del ICR
Cualquier empresa que maneje con regularidad una amplia gama de formularios, cartas y documentos, como las de los sectores financiero, jurídico o de salud, puede beneficiarse del ICR. Estos beneficios incluyen:
- Reducción de los errores de introducción de datos – Las empresas que trabajan con grandes cantidades de datos pueden esperar una tasa de error de hasta el 4%. Una solución ICR, con la ayuda de la IA y Machine Learning, puede ayudarte a reducir estos errores significativamente.
- Menores costos operativos – Como se mencionó anteriormente, el procesamiento manual de documentos puede ser altamente costoso. ¡Con ICR puedes reducir estos costos hasta en un 90%!
- Menor tiempo de procesamiento – La extracción y verificación manual de datos lleva entre 10 y 20 minutos por cada documento, mientras que ICR puede ahorrar el 70% de ese tiempo.
- Escalabilidad – El sistema ICR es muy flexible, lo que te permite analizar distintos tipos de documentos o procesar grandes cantidades.
ICR es utilizado por muchas industrias, ya que es una solución rápida y barata para procesar grandes cantidades de documentos. En la siguiente sección de este blog, veremos algunos de sus casos de uso.
Casos de uso del ICR
Si tu empresa está realizando la transición a flujos de trabajo digitales pero todavía necesitas manejar grandes cantidades de documentos en papel que contienen escritura a mano (como órdenes de compra, formularios de aduanas o documentos logísticos), la tecnología ICR puede ayudarte a digitalizar esos archivos.
El reconocimiento inteligente de caracteres es beneficioso en una gran variedad de situaciones. A continuación se enumeran algunos de los casos de uso más populares de ICR (la lista no es exhaustiva):
- Automatizar procesos de cuentas por pagar
- Convertir imagen en texto
- Automatizar la entrada de datos
- Extraer información de un PDF
- Automatizar procesos de formularios
Como puedes ver, ICR tiene muchas aplicaciones que pueden potenciar tu fuerza de trabajo, amplificar la eficiencia y mejorar la precisión de los datos.
No te preocupes si tu caso de uso no está en la lista porque hay una buena posibilidad de que Klippa pueda ayudarte con una solución ICR refinada para automatizar tus flujos de trabajo relacionados con documentos.
¿Por qué elegir la solución ICR de Klippa?
Si hemos despertado tu interés por el software ICR, no tienes que buscar más porque te presentamos Klippa DocHorizon. Esta solución de procesamiento inteligente de documentos reúne lo mejor de las tecnologías ICR y OCR.
Con Klippa DocHorizon, puedes extraer datos de documentos tanto estructurados como no estructurados, incluyendo firmas manuscritas o valores numéricos gracias a la IA y al Machine Learning. A diferencia del OCR tradicional, DocHorizon no requiere el uso de plantillas y es lo suficientemente sofisticado como para aprender continuamente e interpretar los datos con precisión.
Además de la automatización de la extracción de datos, puedes automatizar las siguientes tareas que tradicionalmente suelen ser realizadas por personas:
- Clasificación de Documentos – Reconocimiento de documentos para archivarlos fácilmente
- Conversión de Documentos – Convierte documentos estructurados y no estructurados a un formato legible digitalmente (JSON, CSV, XML, XSLS).
- Anonimización – Enmascara los datos sensibles para cumplir con la regulación GDPR
- Verificación de Datos – Verifica los datos con bases de datos de terceros
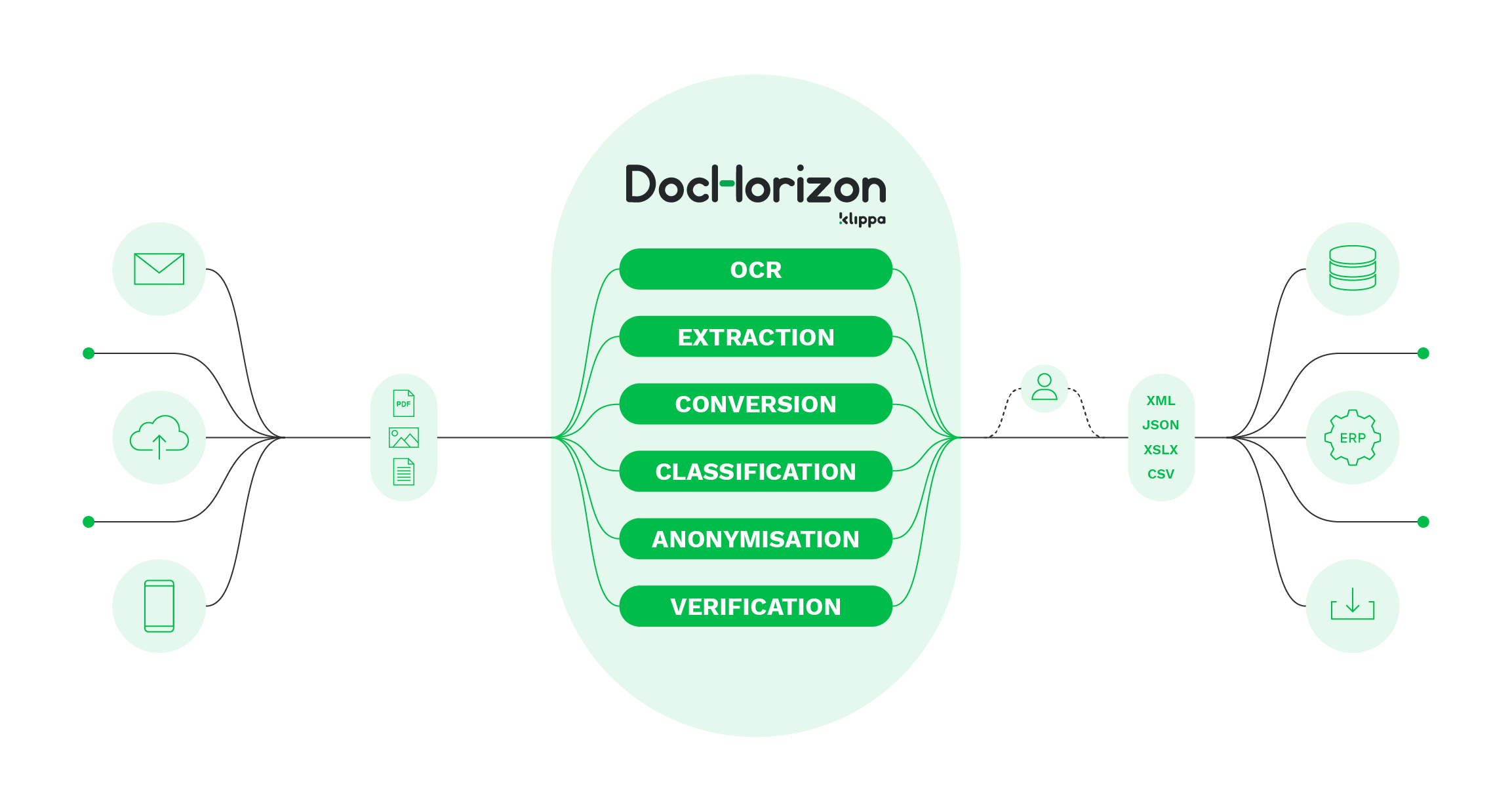
Con estas funciones, DocHorizon es la mejor solución para ayudarte a digitalizar documentos en cuestión de segundos, mejorar la precisión, reducir los errores de introducción manual, eliminar el fraude y mejorar la experiencia del cliente.
¿Quieres saber más sobre nuestra solución? Puedes programar una demostración a continuación o ponerte en contacto con nosotros si tienes alguna pregunta.