En 2022 se crearon 2,5 quintillones de bytes de datos cada día. Alucinante, ¿verdad? Estos datos son esenciales para el crecimiento de las organizaciones, ya que facilitan la vida de las personas, resuelven problemas en las organizaciones e impulsan la innovación.
Sin embargo, hay un problema: la mayoría de los datos están almacenados en formatos no estructurados, como documentos escaneados o papeles escritos a mano. Esto hace prácticamente imposible que las empresas utilicen los datos con eficacia.
Lo que lo hace más difícil es que las empresas necesitan estos datos en bruto y luego transformarlos a otros formatos para pasarlos de un software a otro. Para ello, necesitan encontrar una solución que haga que los datos sean accesibles para todo tipo de entidades. Aquí es donde entra en acción el procesamiento de datos.
A estas alturas, el procesamiento de datos puede parecerte un concepto abstracto. Por eso, en el siguiente párrafo, explicaremos qué es el procesamiento de datos, luego presentaremos los distintos tipos de procesamientos de datos y aclararemos por qué el procesamiento de datos es tan esencial.
Empecemos.
¿Qué es el procesamiento de datos?
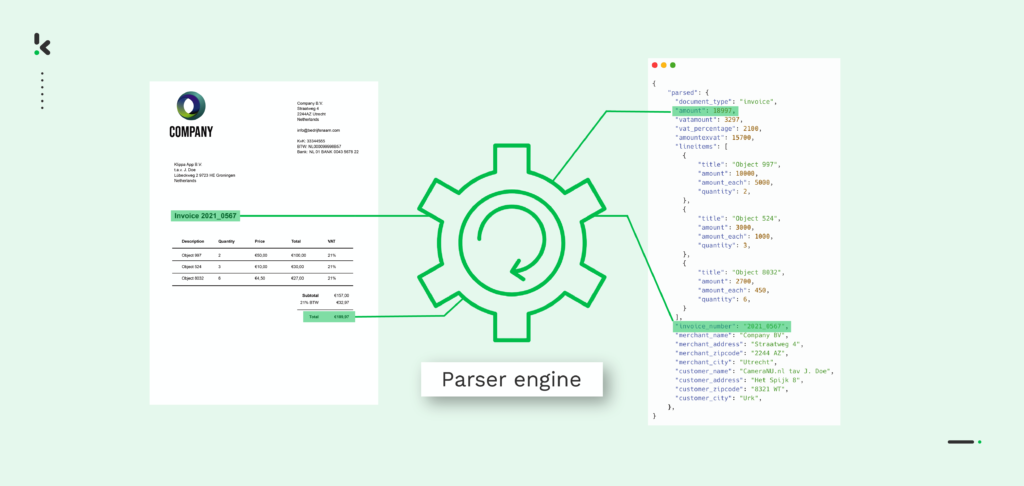
En pocas palabras: El procesamiento de datos (data parsing) es el proceso de convertir datos de un formato a otro. Por ejemplo, supongamos que tienes un archivo PDF y lo necesitas en formato JSON. En este caso, necesitarías un procesador de datos que pueda convertir los datos PDF sin procesar a un formato legible digitalmente.

En general, el procesamiento de datos se realiza como el siguiente paso después de extraer los datos de un documento. La mayoría de las veces, los datos extraídos están en un formato y hay que convertirlos a otro para poder guardarlos en la base de datos o pasarlos a un software de terceros.
La conversión de un formato a otro es posible con la ayuda de un subcampo de la IA, llamado Procesamiento del Lenguaje Natural (NLP), en el que se analizan cadenas de símbolos, caracteres especiales y estructuras de datos. Basándose en reglas definidas por el usuario, la información se estructura primero y se organiza después, lo que le da sentido a los datos extraídos.
Es importante tener en cuenta que, en función de las estructuras contextuales de los datos extraídos, se pueden aplicar distintos enfoques de procesamiento de datos. Veamos cómo funcionan estos enfoques.
Diferentes formas de procesar datos
En general, el procesamiento de datos adopta dos enfoques diferentes: procesamiento de datos basado en la Gramática y procesamiento de datos basado en los Datos.
Procesamiento de datos basado en la gramática
Como su nombre indica, el procesamiento de datos basado en la gramática basa su proceso en un conjunto de reglas gramaticales formales. Funciona fragmentando frases de datos no estructurados y transformándolas después en un formato estructurado y fácil de entender.
Sin embargo, este enfoque tiene un problema: carece de solidez. Para superar este problema, a menudo se suavizan las restricciones gramaticales. Esto significa que las frases que no entran en el ámbito de la gramática habitual pueden excluirse del procesamiento de datos.
Como el procesamiento de datos basado en la gramática tiene sus limitaciones e incoherencias, se ha encontrado otra forma de procesar los datos. Aquí es donde entra en juego el procesamiento de datos basado en los datos.
Procesamiento de datos basado en los datos
En general, el procesamiento de datos basado en datos utiliza analizadores estadísticos inteligentes y treebanks (Corpus parseado) modernos para cubrir el mayor número posible de idiomas. Esto te permite procesar lenguajes conversacionales y frases que exigen una gran precisión, incluso aunque no estén etiquetadas y sean específicas a un dominio.
Nota: un treebank mejora los modelos de NLP, de modo que un software de IA es capaz de comprender texto escrito. El procesador estadístico puede utilizar el modelo de NLP para comprender los diferentes significados posibles de una frase y proporciona el significado más probable.
En el procesamiento de datos basados en datos, se pueden aplicar dos enfoques:
- Enfoque basado en reglas
- Enfoque basado en el aprendizaje
Enfoque basado en reglas
El enfoque basado en reglas es adecuado para documentos estructurados, como facturas de impuestos u órdenes de compra. Las reglas definidas ayudan al usuario a determinar una plantilla que se utiliza como referencia para que el procesador extraiga los datos de un documento.
La desventaja principal es la estricta dependencia de las plantillas predefinidas, lo que significa que incluso un formato de documento ligeramente diferente provocará un fallo en el procesamiento de los datos. Entonces, ¿cuál podría ser una forma de analizar los datos de forma más flexible?
Enfoque basado en el aprendizaje
La respuesta es: Un enfoque basado en el aprendizaje para el procesamiento de datos. Este enfoque se basa en el Machine Learning (ML) y el Procesamiento del Lenguaje Natural (NLP) y se utiliza generalmente para extraer datos de cualquier tipo de documento.
Como el modelo se entrena con un conjunto diverso de documentos no estructurados, se mejora la capacidad de reconocer fácilmente los campos importantes y extraer datos de ellos.
Sin embargo, en práctica se utiliza una combinación de ambos enfoques, el basado en reglas y el basado en aprendizaje, para realizar el procesamiento de datos. Esta combinación te permite procesar cualquier documento con cualquier tipo de diseño, y no te limita a un solo diseño.
Teniendo esto en cuenta, veamos cómo se utiliza el procesamiento de datos en distintos sectores.
Casos de uso del procesamiento de datos
El procesamiento de datos se utiliza en varios sectores para convertir los datos a formatos inutilizables para las empresas. Para facilitar la lectura, nos centraremos sólo en cuatro sectores, pero ten en cuenta que esta lista no es exhaustiva:
- Industria Financiera
- Sector Médico
- Legal
- Transporte y Logística
Industria Financiera
Los bancos y otras instituciones financieras manejan millones de documentos de clientes, como documentos de identidad, estados de cuenta bancarios y solicitudes de incorporación. Todos estos documentos deben procesarse y la información pertinente debe almacenarse en la base de datos del banco.
Del mismo modo, cualquier tipo de empresa maneja facturas y recibos que a menudo se procesan manualmente y se guardan en distintos formatos (PNG, PDF, etc.). Esto dificulta enormemente la búsqueda de datos y, por tanto, el trabajo eficiente con ellos.
Para mejorar los procesos financieros, se puede utilizar un procesador de datos en los siguientes casos:
- Introducción de datos automatizada
- Incorporación de clientes
- Comprobación de integridad de documentos
- Automatización KYC
- Procesamiento automatizado de facturas
- Conversión de PDF a Excel
- Extracción de datos de PDF

No te preocupes si tu caso no aparece en esta lista. Hay muchos otros casos de uso para el sector financiero.
Sector Médico
El sector de la salud se enfrenta a menudo a la escasez de recursos, largas jornadas laborales y enormes tareas administrativas. Esto puede dar lugar rápidamente a errores en los historiales de los pacientes, los tratamientos de seguimiento y las prescripciones, lo que se traduce en daños graves o incluso la muerte del paciente.
Además, el ingreso del paciente está repleto de todo tipo de documentos, lo que obliga a los empleados a dedicar mucho tiempo a introducir datos de los formularios a los ordenadores.
En el sector médico, un procesador de datos puede ser útil en los siguientes casos:
- Incorporación automatizada de pacientes
- Extracción de datos de historiales médicos
- Escaneo de tarjetas de seguro médico

Legal
Los abogados son caros, lo que significa que las empresas de abogados definitivamente quieren que utilicen su tiempo para resolver casos en lugar de clasificar interminables cantidades de documentos. Pero como los abogados reciben todo tipo de documentos de los clientes en varios formatos, pasan mucho tiempo clasificándolos. Esto los vuelve muy ineficaces y lentos.
Además, los abogados atienden a varios clientes al mismo tiempo. Por lo tanto, es esencial que todos los documentos estén debidamente organizados y clasificados. De lo contrario, es casi imposible tener una buena idea general y hacer un seguimiento de los distintos casos.
Además, la mayoría de los documentos de los clientes contienen información sensible que debe protegerse de las filtraciones de datos y el fraude.
En el caso del sector jurídico, el procesamiento de datos puede resultar útil de las siguientes maneras:
- Colección y organización de datos
- Clasificación de documentos
- Extracción de datos automatizada
- Anonimización de la información

Transporte y Logística
Cualquier empresa que venda productos o servicios en línea necesita gestionar una gran cantidad de información de envío y facturación. Por tanto, es necesario gestionar las etiquetas de envío, los albaranes, los comprobantes de entrega, etc.

Aquí, el procesamiento de datos puede utilizarse en casos como:
- Introducción de datos automatizada
- Verificaciones de conformidad
- Procesamiento de facturas automatizado
- Detección de fraude documental
- Administración de paquetes
Si se observan estos diferentes casos de uso, resulta obvio que el procesamiento de datos es beneficioso para varios sectores. La automatización del procesamiento de datos permite mejorar el proceso y hacerlo aún más eficaz. Veamos cómo se puede automatizar el procesamiento de datos.
¿Cómo automatizar el procesamiento de datos?
Hoy en día, lo más probable es que te veas obligado a reducir el tiempo, el esfuerzo humano y los gastos de tu empresa por todos los medios posibles. Para lograrlo, la automatización parece ser la única solución. Como se ha visto en los casos de uso presentados, el procesamiento de datos en sí ya aporta grandes beneficios, como la optimización del flujo de trabajo empresarial. Sin embargo, para mejorar el procesamiento de datos, podemos automatizar este proceso.
Veamos las distintas formas de automatizar el procesamiento de datos:
- Software OCR Clásico
- Aplicaciones Web
- Robots y RPA
Software OCR Clásico
El software OCR clásico es una solución bastante sencilla para automatizar procesos. Dispone de todas las funciones e instrucciones básicas para realizar el trabajo. Pero sus características son limitadas.
Por lo tanto, un software de OCR clásico es utilizable para archivos más pequeños y para convertir, por ejemplo, un PDF simple a JSON. Sin embargo, tareas como el procesamiento de tablas o la lectura de imágenes no se pueden realizar, ya que requieren bibliotecas más potentes, que consumen más potencia de cálculo y datos.
Aplicaciones Web
Las aplicaciones web se utilizan a menudo para interfaces de usuario (UI) que automatizan el procesamiento de datos. Para operar con determinados tipos de archivos, se elige un lenguaje de servidor específico, como Python o Java. Toda la comunicación entre la UI, el servidor y otras bases de datos se realiza principalmente a través de la base de datos.
Si la página web funciona con una potente solución en la nube, se puede integrar el OCR para realizar el procesamiento de datos. Sin embargo, esta solución puede llevar mucho tiempo, ya que realiza muchos pasos y solicitudes en toda la web.
Robots y RPA
La automatización robótica de procesos (RPA) es uno de los últimos avances que permiten la automatización. En lugar de que los humanos realicen tareas manuales, los robots se encargan de automatizarlas. Están equipados con algoritmos inteligentes que les permiten aprender y minimizar los errores con cada iteración. Por eso se utiliza la RPA en contabilidad.
Una de las principales ventajas es que estos robots pueden conectarse con diferentes fuentes de datos, API y otras integraciones de terceros, lo que te permite analizar los datos de forma diferente.
Ahora que hemos hablado de cómo se puede automatizar el procesamiento de datos, echemos un vistazo a sus beneficios.
Los beneficios del procesamiento de datos
Además de la ventaja más significativa del procesamiento de datos, que consiste en poder examinar una enorme cantidad de datos, existen más beneficios:
- Ahorro de tiempo → Los procesadores de datos ayudan a las empresas a convertir los datos a otro formato y automatizar el proceso que, de otro modo, se haría manualmente. El resultado es que las operaciones empresariales se ejecutan con mayor rapidez y que los trabajadores pueden dedicarse a tareas más valiosas.
- Datos más accesibles → El procesamiento de datos hace que los datos sean más accesibles y aumenta la capacidad de búsqueda. Los profesionales de las empresas pueden acceder a toda la información necesaria de entre la enorme cantidad de datos que tienen a mano.
- Modernización de datos → Puede darse el caso de que los datos almacenados de las empresas tengan años y, por tanto, no estén disponibles en formatos modernos. Pero estos datos podrían seguir conteniendo información valiosa necesaria para el negocio. El procesamiento de datos puede cambiar rápidamente el formato de estos datos y permitir a las empresas utilizar la información de forma eficaz.
Después de repasar qué es el procesamiento de datos, en qué casos se utiliza y qué ventajas puede aportar, es posible que te preguntes cómo acceder a un procesador de datos. Una opción podría ser crear tu propio procesador. Pero, ¿es realmente una buena idea?
¿Construir tu propio procesador o no?
Para responder a esta pregunta, te explicaremos las ventajas y las desventajas de crear tu propio procesador. Después, podrás tomar una decisión informada.
Ventajas de crear tu propio procesador
- Te da más control → Tienes más control y puedes decidir cómo actualizar o mantener tu procesador de datos. Además, si estás trabajando con datos muy sensibles, puede que prefieras no compartir tu información con procesadores de datos de terceros.
- Personalizable según tus necesidades → Al construir tu propio procesador, se personaliza específicamente para tu empresa. De ese modo, ayuda a los equipos internos a satisfacer los requisitos específicos de procesamiento de tu organización.
Desventajas de crear tu propio procesador
En general, para construir tu propio procesador, necesitarás un equipo de desarrolladores que tenga la capacidad de entender y crear aplicaciones de procesamiento. Encontrar desarrolladores con estas habilidades puede ser todo un reto. Pero esta no es el único inconveniente. Veamos qué otras desventajas tiene construir tu propio procesador:
- Caro → Construir tu propio procesador es caro, ya que se necesita mucho tiempo y recursos. Además de eso, tendrás que contratar y capacitar a todo un equipo interno para construir tu procesador personalizado.
- Capacitación del equipo → Tendrás que entrenar a todo tu equipo en el uso de la tecnología de procesamiento de datos.
- Mantenimiento → Un procesador de datos requiere un mantenimiento regular, lo que significa que tendrás que invertir más tiempo y dinero.
- Infraestructura → Construir un procesador de datos requiere mucha planificación y tener tus propios servidores. Esto significa que puede que tengas que construir o comprar un servidor potente que sea lo suficientemente rápido para procesar la información.
Para la mayoría de las organizaciones, las desventajas superan a las ventajas, simplemente porque es caro y extremadamente difícil encontrar personas con experiencia para construir un procesador. Si ese es el caso, no hay por qué desesperar. Tenemos otra opción para ti. Puedes potenciar a tu organización con un procesador de datos que ha sido construido con miles de horas de trabajo de desarrolladores.
Procesamiento de datos con Klippa
Klippa es una de las empresas que puedes utilizar para procesar datos de cualquier tipo de documento. Para procesar datos, se necesita un software de Reconocimiento Óptico de Caracteres (OCR).
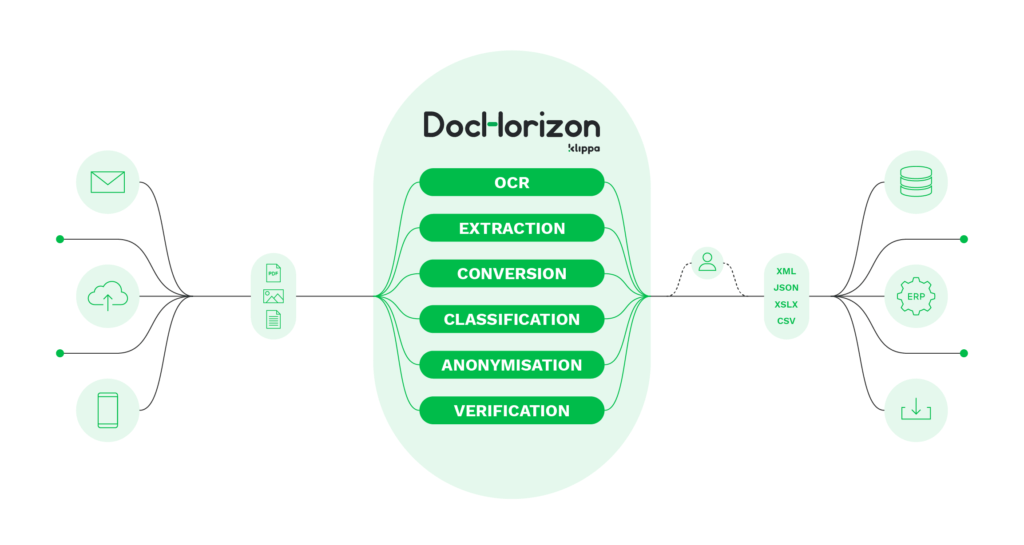
Klippa DocHorizon, nuestro software de OCR basado en la IA, se puede utilizar para procesar datos de cualquier tipo de documento que tu organización necesite procesar. Con la tecnología OCR, puedes extraer con precisión la información relevante de formatos de datos no estructurados y convertir esos datos al formato que desees.
Además, DocHorizon puede clasificar los tipos de documentos, verificar y anonimizar los datos, y al mismo tiempo eliminar la introducción manual de datos. DocHorizon ya reconoce una amplia gama de documentos en más de 100 idiomas.
¿Quieres transformar tus datos en formatos inutilizables y convertirlos en datos listos para ser utilizados? Estaremos encantados de mostrarte cómo hacerlo con nuestra solución. Sólo tienes que reservar una demostración gratuita a continuación o ponerte en contacto con uno de nuestros expertos.