Extraer información de los documentos es una tarea diaria para la mayoría de las organizaciones. Para mejorar la eficiencia al realizar esta tarea, las empresas han recurrido a la automatización. La extracción de datos se realiza ahora utilizando tecnologías modernas, como la IA, la computer vision o el procesamiento del lenguaje natural (NLP). Con la ayuda de la automatización, las empresas reducen su tiempo de procesamiento de documentos y aumentan la precisión de los datos extraídos.
Para mejorar la velocidad y la eficacia del flujo de trabajo, las empresas suelen utilizar el Reconocimiento de Entidades Nombradas (NER) para automatizar los procesos de extracción de información. NER es una de las técnicas de procesamiento del lenguaje natural y puede ser muy beneficiosa para las organizaciones que buscan maximizar sus capacidades de automatización.
En caso de que no estés familiarizado con el término Reconocimiento de Entidades Nombradas, o no estés seguro de cómo implementarlo, no te preocupes. En este blog, explicaremos qué es el Reconocimiento de Entidades Nombradas y cómo se puede construir o entrenar un modelo NER. A continuación, echaremos un vistazo a algunas de las posibilidades de implementar NER utilizando código, especialmente nltk y spaCy.
Comencemos.
¿Qué es el Reconocimiento de Entidades Nombradas (NER)?
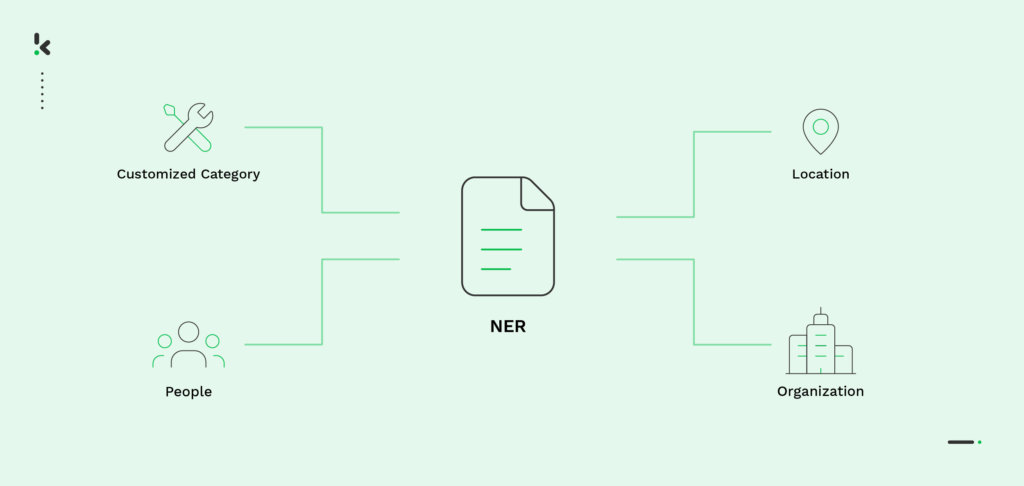
El Reconocimiento de Entidades Nombradas es una técnica basada en el procesamiento de lenguaje natural (NLP) que se utiliza para extraer, identificar y clasificar información en documentos de texto. Detecta entidades (es decir, partes de la oración) y las clasifica en una categoría predeterminada, como nombre o código de país.
Las categorías NER pueden ser genéricas e indicar, por ejemplo, palabras que significan una organización, una persona o una época. Sin embargo, también pueden personalizarse en función de un caso de uso específico. Por poner un ejemplo, el modelo NER puede crearse para reconocer categorías como “nombre del paciente” y “fecha de nacimiento” en documentos médicos o “nombre del comerciante” y “fecha de compra” en facturas. Las posibilidades son infinitas.
Para obtener los resultados mejores y más precisos, el Reconocimiento de Entidades Nombradas requiere amplios conocimientos de matemáticas, machine learning y procesamiento de imágenes. Sin embargo, la lista no termina aquí. El Reconocimiento de Entidades Nombradas puede basarse en múltiples métodos, así que analicemos este tema a fondo y descubramos los distintos enfoques del NER.
Métodos de Reconocimiento de Entidades Nombradas
Como ya se ha mencionado, el Reconocimiento de Entidades Nombradas puede basarse en múltiples métodos. La diferencia entre estos métodos radica en la forma en la que se ha entrenado el modelo para identificar y extraer con precisión los campos de datos.
- Método basado en diccionarios: En este método, se utiliza un diccionario que contiene un amplio vocabulario para entrenar al modelo NER. Se utiliza un algoritmo básico de concordancia de cadenas para verificar si una entidad presente en el texto coincide con algún elemento del vocabulario.
- Método basado en reglas: Según este método, se utiliza un conjunto predeterminado de reglas para la extracción de información. Estas reglas pueden basarse en patrones, utilizando el patrón morfológico de las palabras, o en el contexto, utilizando el contexto de la palabra dada en el documento.
- Método basado en machine learning: Este método se basa en la estadística y consta de dos etapas. En primer lugar, los archivos utilizados para entrenar el modelo pasan por un proceso de anotación de datos. Sólo después de este paso, el modelo NER puede empezar a entrenarse con los datos anotados. El segundo paso permite que el modelo entrenado anote los documentos sin procesar por sí solo.
- Método basado en deep learning: Por último, el método basado en deep learning es el más preciso. Es capaz de comprender las relaciones semánticas y sintácticas entre las palabras de un texto y también de analizar palabras específicas de un tema.
El Reconocimiento de Entidades Nombradas parece ser un gran recurso para extraer información con precisión. Pero, ¿cómo funciona realmente? Entender el proceso que hay detrás de este modelo ayuda a las empresas a tener una mejor idea de lo que implica el Reconocimiento de Entidades Nombradas. Averigüemos cuál es el proceso de construcción y entrenamiento del modelo NER.
Cómo construir y entrenar un modelo NER
Ha llegado el momento de aprender a construir y entrenar un modelo NER desde cero. Uno de los enfoques más comunes para construir un modelo NER es utilizar un modelo de lenguaje, llamado Representaciones Codificadoras Bidireccionales de Transformadores, también conocido como BERT.
Un modelo BERT es un modelo lingüístico preentrenado que puede ajustarse y actualizarse. Esto permite que el modelo preentrenado comprenda mejor los patrones del texto y analice el contexto y el significado. Utiliza la técnica NER en su núcleo, pero ofrece la posibilidad de entrenamiento y perfeccionamiento, lo que mejora su precisión de funcionamiento.
Veamos los cinco pasos necesarios para construir y entrenar el modelo de Reconocimiento de Entidades Nombradas, utilizando el modelo lingüístico BERT:
- Adquisición de datos
- Preparación de la entrada para el Reconocimiento de Entidades Nombradas
- Inicialización de hiperparámetros para el modelo NER
- Entrenamiento y predicción del modelo BERT
- Estimación del rendimiento del modelo de Reconocimiento de Entidades Nombradas
Adquisición de datos
El primer paso en cualquier procedimiento que implique modelos basados en deep learning, como BERT, es alimentar al modelo con datos. De este modo, el algoritmo es capaz de procesar la información dada y asimilarla. Para familiarizarse con las entidades (es decir, nombres, ubicaciones, organizaciones, códigos de países), el modelo necesita tener conocimientos previos. Sólo entonces podrá reconocer y diferenciar entidades en un contexto.
Aunque un modelo BERT se entrena especialmente con frases que contienen la entidad de interés, por ejemplo, “persona”, también puede entrenarse para reconocer palabras utilizando subpalabras. Supongamos que tenemos la entidad “persona”. Una subpalabra de esta entidad sería el nombre de una persona. Con un entrenamiento suficiente, el modelo puede reconocer que toda palabra que sea el nombre de una persona, corresponde a la entidad “persona”. Por eso es necesario disponer de muchos datos.
Preparación de la entrada para el Reconocimiento de Entidades Nombradas
Antes de pasar al segundo paso, es importante recordar que el modelo NER utiliza un esquema de etiquetado específico, a diferencia de otros modelos de procesamiento del lenguaje natural. El esquema de etiquetado preferido es el formato IOB, debido a su facilidad de uso. Se suele utilizar para etiquetar tokens (es decir, entidades, palabras) en una tarea de agrupación (chunking) para el modelo NER.
En caso de que te lo estés preguntando, el “chunking” es un proceso de NLP que se utiliza para identificar partes del discurso dentro de una frase. Estas partes se refieren a lo que conocemos como sustantivos, verbos, adjetivos, etcétera. Una tarea de chunking, por tanto, se encarga de identificar estas entidades y clasificarlas según corresponda.
El formato IOB significa “Inside, Outside, Beginning” (dentro, fuera, principio) y funciona de la siguiente manera:
- El prefijo “I” antes de una etiqueta indica que el token está dentro de un chunk.
- El prefijo “O” indica que un token no pertenece a ningún chunk.
- El prefijo “B” antes de una etiqueta indica que la etiqueta correspondiente es el principio de un chunk y sigue inmediatamente a otro chunk sin la etiqueta “O” entre ellos. Sin embargo, si un chunk sigue después de un prefijo “O”, el primer token del chunk lleva un prefijo “I”, en lugar del “B”.

Una alternativa al esquema de etiquetado IOB es utilizar marcos existentes, como TensorFlow. En este caso, es necesario utilizar clases de preprocesador para realizar el etiquetado.
Inicialización de hiperparámetros para el modelo NER
El tercer paso del proceso consiste en introducir el modelo lingüístico BERT a el programa e inicializar los hiperparámetros. Estos hiperparámetros representan un punto de referencia para el modelo BERT, de modo que el entrenamiento pueda evaluarse con precisión.
Para encontrar los parámetros adecuados, es necesario ajustar el modelo en función de su rendimiento con los datos proporcionados. Los datos anotados se suben al programa, para que actúen como tensores para el entrenamiento del modelo en una red neuronal (deep neural network). Una red neuronal profunda, o simplemente DNN, es un subconjunto del machine learning y del deep learning, que procesa datos de forma compleja, empleando modelos matemáticos.
Para mejorar la precisión de la predicción de entidades, estos hiperparámetros tienen un papel fundamental en el modelo.
Entrenamiento y predicción del modelo BERT
Tras establecer los hiperparámetros, es hora de entrenar el modelo BERT. El entrenamiento del modelo BERT consta de dos fases. En primer lugar, se establecen las guías de entrenamiento, seguidas del entrenamiento real del modelo.
- Establecer las pautas de entrenamiento implica escribir un bucle basado en el número de epochs. Un epoch es el número de veces que el algoritmo de aprendizaje trabajará a través de todo el conjunto de datos de entrenamiento. En esta fase, también es importante comprobar las unidades de procesamiento gráfico, o GPU. Estas unidades de procesamiento gráfico aceleran los procesos computacionales para el deep learning, optimizando así el modelo para un entrenamiento más rápido.
- La siguiente fase es el verdadero entrenamiento del modelo. Ahora tenemos que activar los parámetros que se establecieron previamente e inicializar la función de pérdida y la función optimizadora. Estas funciones ayudan a mejorar el rendimiento del modelo, aumentando la precisión del resultado.
La función de pérdida mide la diferencia entre la salida pronosticada y la salida actual, mientras que el optimizador ajusta los parámetros del modelo para minimizar la función de pérdida.
En esencia, el objetivo principal es entrenar el modelo de forma que se minimicen los errores y aumente la precisión de los índices de predicción.
Estimación del rendimiento del modelo de Reconocimiento de Entidades Nombradas
Por último, tenemos que hacer una estimación del rendimiento del modelo. Esta estimación puede hacerse de distintas formas, pero las más comunes son la puntuación F1 y la puntuación de coincidencia relajada.
- Puntuación F1: La puntuación F1 es una métrica de evaluación en ML que combina las puntuaciones de precisión y de recuperación. Muestra cuántas veces un modelo ha realizado una predicción correcta en el conjunto completo de datos. Esta métrica sólo es precisa si cada clase del conjunto de datos tiene el mismo número de muestras.
- Puntuación de coincidencia relajada: Con esta métrica, el rendimiento se calcula en función del número de entidades que el modelo identificó como el tipo de entidad correcto. Veamos el siguiente ejemplo:
Supongamos que en un texto hay 3 entidades “persona” y 2 entidades “lugar”. Si, en cambio, el modelo identifica 4 entidades “persona” y 1 entidad “ubicación”, el rendimiento es del 75% sobre el 100%. La métrica de puntuación de coincidencia relajada sigue reconociendo el modelo como acertado. ¿Por qué? Aunque la identificación exacta no fue posible, el modelo reconoció las 3 “entidades persona”, lo que se considera un resultado positivo.
Acabamos de aprender a construir y entrenar un modelo de Reconocimiento de Entidades Nombradas desde cero, utilizando el modelo de lenguaje BERT. El verdadero truco está en implementar el modelo NER. Descubramos cómo implementar este modelo basado en NLP utilizando código.
Implementación del Reconocimiento de Entidades Nombradas
El uso de código es la opción preferida a la hora de implementar el NER. Aunque existen múltiples lenguajes de programación utilizados para esta acción, nos centraremos en dos de ellos, spaCy y nltk. Ambos están basados en Python y permiten realizar tareas avanzadas de PLN.
Reconocimiento de Entidades Nombradas con spaCy
SpaCy es una biblioteca NLP de código abierto para tareas avanzadas de procesamiento del lenguaje natural en Python. Se utiliza para diversas tareas y hace uso de métodos integrados para el Reconocimiento de Entidades Nombradas.
Un modelo SpaCy funciona bien con todo tipo de datos de texto, pero puede ajustarse para categorías específicas. Como alternativa, spaCy dispone de varios modelos preentrenados que pueden utilizarse para realizar tareas como el Reconocimiento de Entidades Nombradas o la extracción de información de datos específicos.
Es bueno tener en cuenta que para implementar NER con spaCy es necesario disponer de las últimas versiones de Python 3, Pip y, por supuesto, spaCy. Además, también se recomienda descargar los modelos pre-entrenados del núcleo de spaCy para utilizarlos en los programas directamente. ¡Comencemos!
En primer lugar, utilizamos un terminal o símbolo del sistema y escribimos el siguiente comando:

A continuación, añadimos el código correspondiente:
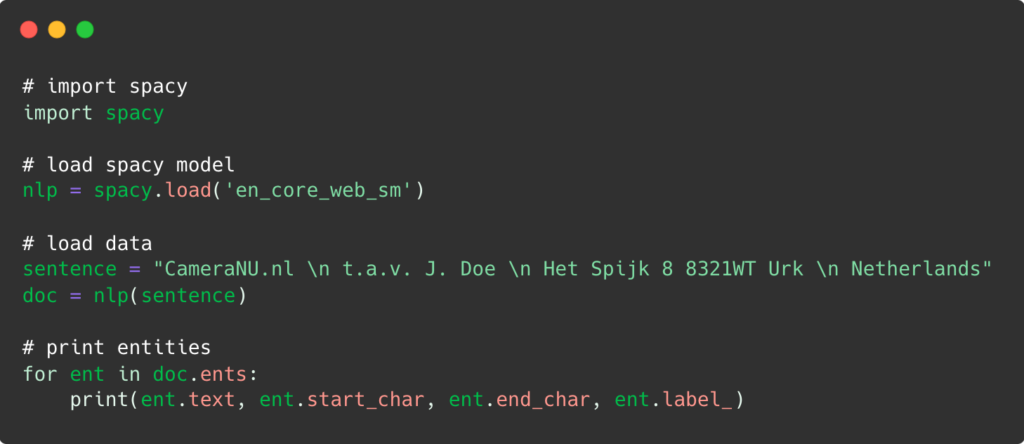
Después de que el Reconocimiento de Entidades Nombradas procesa la información dada, es decir, lee el texto, identifica las entidades y las categoriza, obtenemos el resultado final:

Esto es de lo más sencillo. Por supuesto, la precisión de los datos extraídos y categorizados depende también en gran parte del tamaño del texto. En ese caso, podemos utilizar distintos modelos en función del tamaño del texto:
- En_core_web_sm – para textos de tamaño pequeño
- En_core_web_md – para textos de tamaño mediano
- En_core_web_lg – para textos de tamaño grande
Ya hemos visto cómo se puede implementar el Reconocimiento de Entidades Nombradas utilizando spaCy. Pero, ¿qué pasa con la implementación de NER utilizando otra plataforma basada en Python? Veamos cómo se implementa el NER usando nltk.
Reconocimiento de Entidades Nombradas con nltk
Nltk también es una biblioteca basada en Python que realiza tareas de procesamiento del lenguaje natural. Estas tareas van desde el procesamiento de datos de texto, el modelado de datos o el etiquetado de partes del discurso. En cuanto a configuraciones adicionales, es sencillo y puede utilizarse ampliamente en todos los sistemas operativos.
Para poder utilizar nltk para implementar NER, es necesario instalar los paquetes estables Python 3, Pip y nltk. La implementación del reconocimiento de entidades nombradas mediante nltk consta de tres pasos.
En primer lugar, hay que importar nltk y descargar los paquetes necesarios:

Después de haber preparado todos los paquetes necesarios, es hora de introducir los datos. En este caso, hemos elegido una frase que se encuentra en una factura.

Por último, la plataforma identifica las entidades del texto, encuentra las partes pertinentes de la oración y delimita las palabras del documento. Al procesar la información, se genera el siguiente resultado:

Podemos ver que utilizar nltk para implementar el Reconocimiento de Entidades Nombradas también es un proceso sencillo, igual que con spaCy. Sin embargo, saber cómo funciona el NER no aporta ningún beneficio a las organizaciones si éstas no reconocen sus ventajas. En la siguiente sección, hemos destacado algunos de los casos de uso más importantes en los que el Reconocimiento de Entidades Nombradas puede ser de gran ayuda para las organizaciones.
Casos de uso de NER
Para las empresas que desean elevar sus procesos operativos, el Reconocimiento de Entidades Nombradas puede ser un gran recurso. Puede ayudar a las organizaciones a realizar tareas como el procesamiento de datos, lo que permite una automatización de entrada de datos precisa. Estos son sólo algunos de los ejemplos de cómo el NER beneficia a las organizaciones:
- Atención al cliente: Las empresas pueden mejorar el índice de satisfacción del cliente y reducir el tiempo de respuesta utilizando NER. El modelo diferencia las quejas, preguntas o solicitudes de los usuarios recibidas a través de chatbots, mediante la identificación y categorización de las palabras clave utilizadas por los clientes.
- Categorización de contenidos: El contenido se clasifica fácilmente en varias categorías con el Reconocimiento de Entidades Nombradas. El algoritmo lee el documento y puede diferenciar al instante un blog de un correo electrónico o una entrada de diario. Este modelo se utiliza para archivar bibliotecas digitales, ofrecer recomendaciones de películas en servicios de streaming o tiendas online.
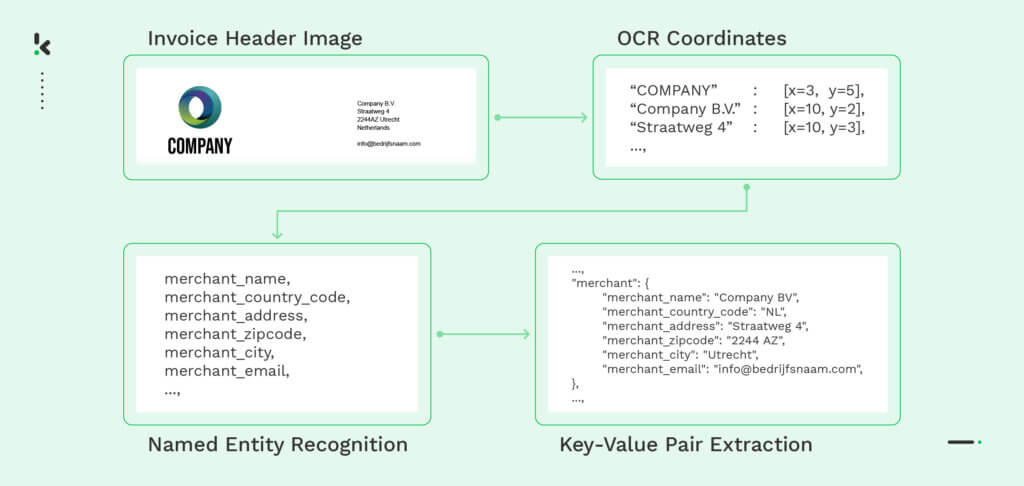
- Clasificación de documentos: El Reconocimiento de Entidades Nombradas se entrena para diferenciar varios tipos de documentos, como facturas, recibos o pasaportes. Mediante la simple identificación de números concretos o campos de datos individuales, el NER clasifica los documentos en diferentes clases.
- Procesamiento (parsing) de archivos: En lugar de extraer manualmente los datos de documentos no estructurados, los procesadores de archivos basados en NER pueden leer el archivo y extraer la información más importante. Además, es capaz de convertir los datos a un formato útil para su procesamiento posterior.
Limitaciones a la hora de construir un modelo NER
Construir o entrenar un modelo de Reconocimiento de Entidades Nombradas desde cero no es imposible, como acabamos de aprender. Sin embargo, puede ser un proceso extenso que presenta muchas limitaciones:
- Es caro: Construir un código desde cero puede ser un proceso costoso, ya sea creando el código internamente o externalizándolo. No obstante, hay que gastar recursos financieros en expertos informáticos o en código externo.
- Lleva mucho tiempo: tener que entrenar, por no hablar de construir un modelo de NER desde el principio, lleva mucho tiempo. Este proceso puede representar un posible inconveniente para la mayoría de las empresas, especialmente las PYME.
- Puede ser vulnerable a las filtraciones de datos: Optar por construir y entrenar un modelo NER desde cero puede dar lugar a posibles filtraciones de datos. Si el modelo no se construye adecuadamente, el algoritmo puede volverse vulnerable a los estafadores y a las filtraciones de datos.
- Falta de datos de entrenamiento: Reunir suficientes datos de entrenamiento para alimentar el modelo NER no es una tarea fácil. Las empresas acaban teniendo que buscar una alternativa, que suele consistir en invertir grandes sumas de dinero en la creación de datos sintéticos.
En lugar de enfrentarse a un proceso extenso y bastante complicado para crear un modelo NER desde cero, las empresas pueden optar por una solución lista para usar, es decir, un software de OCR.
Aunque hay muchos ejemplos de software de OCR de buen rendimiento, sólo unos cuantos son capaces de realizar las tareas necesarias que pueden sustituir a la tecnología de Reconocimiento de Entidades Nombradas. Klippa DocHorizon, por ejemplo, es capaz de capturar, extraer y verificar datos, eliminando la necesidad de crear un código completamente nuevo.
Alternativa de Klippa al Modelo de Reconocimiento de Entidades Nombradas
Klippa DocHorizon es una solución de Procesamiento Inteligente de Documentos que utiliza IA para automatizar los flujos de trabajo relacionados a los documentos. Con la ayuda de la tecnología OCR, las empresas pueden escanear documentos móviles, procesar archivos, verificar documentos, enmascarar datos y mucho más.
Klippa DocHorizon le permite a las organizaciones
- Procesar documentos financieros, legales, de identidad y muchos otros
- Extraer datos con una precisión de hasta el 99%.
- Minimizar los errores de introducción de datos
- Prevenir el fraude de documentos verificando su autenticidad
- Cumplir con las regulaciones de privacidad de datos, ya que los datos procesados no se almacenan en los servidores de Klippa
En lugar de aventurarte en un proceso costoso y que requiere mucho tiempo, piensa en la opción de elegir una solución inteligente de procesamiento de documentos todo en uno.
Reserva una demostración gratuita a continuación o ponte en contacto con nosotros si necesitas ayuda en tu caso de uso de NER.