Provavelmente já ouviu falar de OCR, mas sabe realmente como esta tecnologia pode beneficiar a sua empresa? Em termos simples, OCR (Optical Character Recognition ou Reconhecimento Ótico de Caracteres) é uma tecnologia que permite extrair texto de documentos, recibos e até matrículas de forma automatizada.
O OCR tem vindo a evoluir rapidamente, tornando-se essencial para empresas que procuram reduzir tarefas manuais e aumentar a eficiência. Setores como banca, retalho, saúde, jurídico e transportes já adotaram esta tecnologia para automatizar o processamento de documentos e melhorar a experiência do cliente.
Mas o OCR vai além da simples extração de texto. Soluções avançadas, como o Processamento Inteligente de Documentos (IDP), oferecem recursos inovadores para verificar, converter, anonimizar e até detetar fraudes automaticamente.
Neste artigo, explicamos o que é OCR, como funciona, onde é utilizado e quais os seus benefícios. Também verá como pode implementar esta tecnologia na sua empresa de forma simples e eficiente.
Interessado? Vamos a isso!
Principais Conclusões
- O OCR, também conhecido como reconhecimento de texto, converte documentos físicos em digitais, facilitando a pesquisa, organização e extração de dados.
- É amplamente utilizado em setores como finanças, saúde e logística, ajudando a automatizar tarefas e reduzir erros manuais.
- Quando bem implementado, melhora a produtividade e agiliza o processamento de grandes volumes de documentos.
- A evolução da IA está a tornar o OCR mais preciso, permitindo reconhecer textos em diferentes formatos e línguas.
O que é o Reconhecimento Ótico de Caracteres (OCR)?
O Reconhecimento Ótico de Caracteres (OCR, na sua sigla em inglês) é uma tecnologia que ajuda a extrair texto de imagens ou de documentos digitalizados, transformando esse texto num formato que possa ser lido por um computador.
É bastante útil quando os dados são necessários para serem posteriormente processados, o que acontece, por exemplo, na contabilidade, na gestão de despesas, nas campanhas de marketing de fidelização, ou na verificação de identidade.
A digitalização de documentos pode ser muito mais eficiente com a ajuda do OCR. Este software reconhece letras, palavras, itens de linha, frases e padrões, reduzindo significativamente o trabalho manual.
Muitas soluções de OCR são combinadas com Inteligência Artificial (IA) e Machine Learning (ML) para automatizar processos e melhorar a precisão na extração de dados.
Para obter os melhores resultados, é essencial treinar a tecnologia, fornecendo-lhe um grande volume de dados. Com o tempo, o OCR torna-se mais preciso e consegue reconhecer uma maior variedade de documentos.
Agora que já explicámos o que é o OCR, vamos ver como funciona esta tecnologia na prática.
Como Funciona o OCR?
O OCR funciona de forma semelhante à nossa capacidade de ler e interpretar textos, identificando padrões e caracteres. Normalmente, uma pessoa lê um documento, extrai as informações necessárias e insere os dados manualmente num sistema, ficheiro ou base de dados.
Com o reconhecimento de texto, OCR, este processo torna-se mais rápido e preciso. A tecnologia analisa e melhora a qualidade do texto digitalizado ou da imagem e segue uma série de passos para extrair os dados capturados. A grande vantagem é que reduz o tempo necessário e minimiza erros humanos.
O processo de Reconhecimento Ótico de Caracteres passa por várias etapas:
- Passo 1: Pré-processamento de imagem
- Passo 2: Segmentação
- Passo 3: Reconhecimento de caracteres
- Passo 4: Pós-processamento da saída
Passo 1: Pré-processamento de imagem
Para garantir uma extração de dados precisa, a qualidade da imagem deve ser melhorada. Este processo, conhecido como pré-processamento da imagem, é essencial para melhorar a legibilidade do texto e aumentar a precisão do OCR. Quanto mais nítida e bem digitalizada for a imagem, mais exatos serão os resultados.
Nesta fase, o motor de OCR analisa automaticamente a imagem, detetando e corrigindo eventuais problemas que possam afetar o reconhecimento do texto. Algumas das técnicas mais utilizadas para melhorar imagens e documentos digitalizados incluem:
- De-skew – O processo no qual uma fotografia ou um documento digitalizado é endireitado e o ângulo corrigido.

- Binarization – O processo em que uma imagem ou um documento digitalizado é convertido a preto e branco. A binarização fornece uma forma mais precisa de separar o texto do fundo.

- Zoning – Também conhecida como análise de layout, é utilizada para identificar colunas, linhas, blocos, legendas, parágrafos, tabelas e outros elementos.

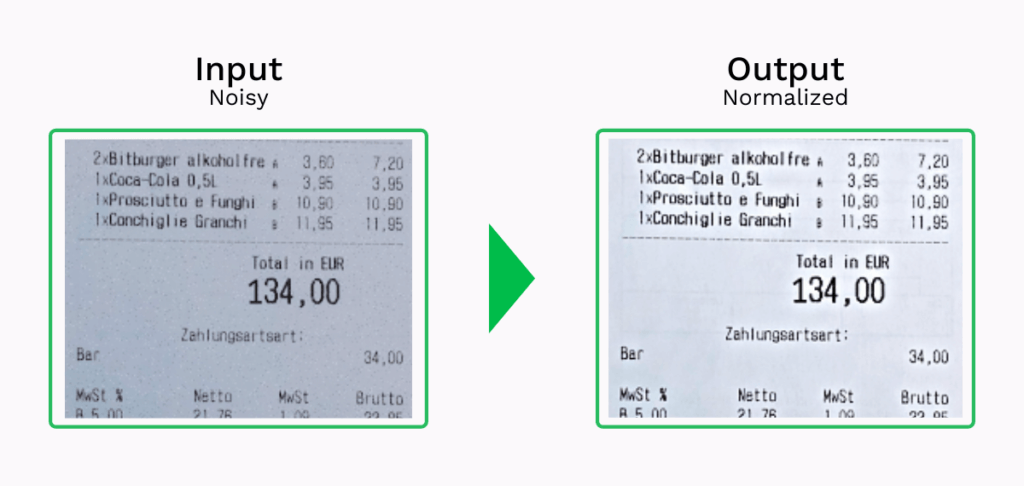
- Normalization – O processo de redução de ruído através do ajuste do valor de intensidade dos pixéis para os valores médios dos pixéis circundantes.
Passo 2: Segmentação
A segmentação é a etapa em que o OCR analisa o texto linha por linha, identificando os diferentes elementos presentes no documento. Este processo é fundamental para garantir que os caracteres e palavras sejam reconhecidos corretamente.
A segmentação passa pelas seguintes etapas:
- Deteção de palavras e linhas de texto – Refere-se à identificação das linhas de texto e das palavras que lhes pertencem.

- Reconhecimento do guião – O processo de identificação do guião baseado em documentos, páginas, linhas de texto, parágrafos, palavras, e caracteres.

Passo 3: Reconhecimento de caracteres
Nesta fase, a imagem ou documento é dividido em áreas específicas, separando diferentes secções ou zonas de texto. Após essa divisão, o OCR analisa cada parte e reconhece os caracteres presentes.
Existem duas abordagens principais para o reconhecimento de caracteres:
- Correspondência de matrizes – Nesta abordagem, cada caractere é comparado a uma biblioteca de modelos predefinidos. O motor de OCR analisa a imagem píxel por píxel, procurando semelhanças entre os caracteres digitalizados e os caracteres armazenados no sistema. Quando há uma correspondência exata, o OCR identifica e extrai corretamente o texto.

- Reconhecimento de características – Este método baseia-se na análise de padrões e traços únicos de cada caractere para identificá-lo corretamente. O OCR examina elementos como tamanho, altura, forma, linhas e estrutura dos caracteres e compara-os com uma biblioteca de referências. Em vez de uma correspondência exata píxel por píxel, este processo foca-se em reconhecer as características distintivas de cada letra ou símbolo, tornando-o mais eficiente para diferentes estilos de escrita e fontes.
Passo 4: Pós-processamento da saída
Nesta fase, são aplicadas técnicas e algoritmos avançados para melhorar a precisão da extração de dados e garantir um resultado mais fiável. Primeiro, os dados são detetados e analisados, sendo corrigidos, se necessário.
Para assegurar maior exatidão, a informação extraída é comparada com um vocabulário ou biblioteca de caracteres, permitindo realizar verificações gramaticais e ajustes contextuais. Esta etapa final refina os resultados e melhora a qualidade do texto processado.
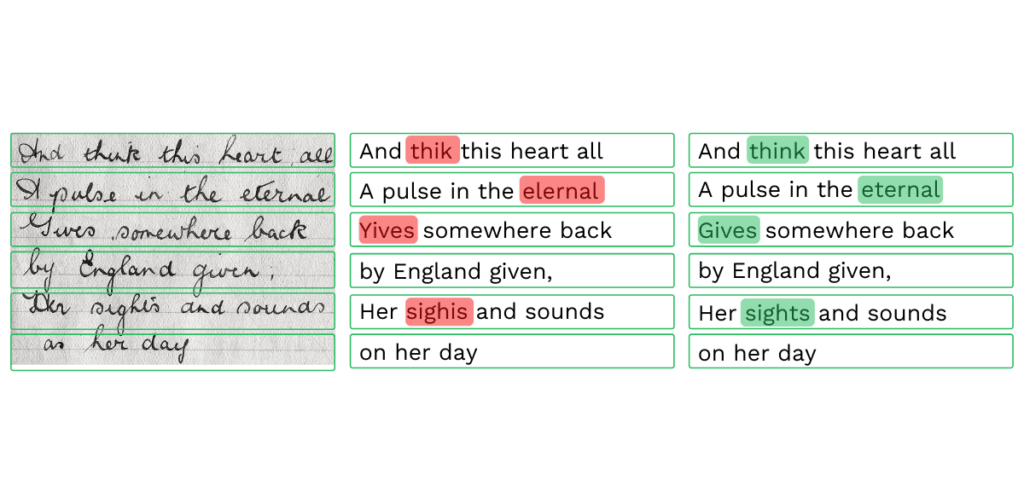
Embora o OCR tradicional seja altamente eficaz na conversão de imagens em texto digital, ainda apresenta algumas limitações. A seguir, vamos explorar os principais desafios desta tecnologia.
Limitações do OCR Tradicional
O OCR tradicional, ou baseado em modelos, foi inicialmente desenvolvido para ajudar pessoas com deficiências visuais a converter texto impresso em áudio. Mais tarde, começou a ser utilizado para reconhecer texto preto sobre fundos brancos. No entanto, esta tecnologia tradicional não foi concebida como uma solução dinâmica para a extração de dados, apresentando vários desafios.
Aqui estão cinco das principais limitações do OCR tradicional:
- Dependência da qualidade da imagem – A precisão do OCR cai significativamente se a imagem for de baixa qualidade ou se os caracteres forem muito pequenos (menos de 20px).
- Baseado em regras fixas – Requer modelos específicos e regras pré-definidas, o que dificulta a extração de dados em documentos não estruturados ou variados.
- Pouca automatização – Para cada novo formato de documento, são necessárias novas regras, tornando o processo pouco flexível e difícil de escalar.
- Custo elevado – Criar e manter essas regras exige tempo e recursos, o que pode tornar o OCR tradicional caro sem garantir total precisão.
- Dificuldade com múltiplos formatos – Funciona bem com documentos simples e padronizados, mas tem dificuldade em lidar com layouts complexos e variados.
Em suma, o OCR tradicional tem as suas limitações, mas isso não significa que seja uma tecnologia ultrapassada. Com o aumento das exigências do mercado e a necessidade de processos mais rápidos e precisos, o OCR tem evoluído significativamente para acompanhar esta transformação.
Agora, vamos explorar uma versão mais avançada desta tecnologia.
A Nova Geração da Tecnologia OCR
A evolução do OCR já é uma realidade! Impulsionada por Inteligência Artificial (IA) e Machine Learning (ML), esta nova geração supera as limitações do OCR tradicional, permitindo um nível de automatização inatingível com modelos baseados em regras. Esta tecnologia inovadora é conhecida como Processamento Inteligente de Documentos (IDP).
O IDP vai além das capacidades humanas, processando, analisando, categorizando e convertendo dados de forma totalmente automática – tudo em questão de segundos.
Um dos seus maiores avanços é a eliminação da dependência de regras fixas, tornando o OCR baseado em IA mais flexível, escalável e acessível para empresas de qualquer dimensão.
Agora, vamos explorar como Machine Learning e IA estão a transformar as soluções modernas de OCR.
A abordagem de Machine Learning
O OCR com Machine Learning (ML) pode reconhecer padrões e interpretar conteúdos sem depender de regras rígidas. Existem três abordagens principais:
- Aprendizagem supervisionada – O modelo é treinado com dados rotulados para classificar informações e prever resultados. Por exemplo, ao analisar emails rotulados como spam ou não spam, o sistema aprende a categorizá-los corretamente.
- Aprendizagem não supervisionada – O modelo trabalha com dados não rotulados, identificando padrões sem regras pré-definidas. No processamento de recibos, por exemplo, pode aprender a reconhecer automaticamente comerciantes e montantes com base em semelhanças.
- Aprendizagem semi-supervisionada – Uma mistura das duas abordagens anteriores. Útil para lidar com grandes volumes de dados, combinando eficiência e precisão.
A boa notícia? Não precisa de escolher uma abordagem! Hoje, muitas soluções de OCR já vêm pré-treinadas e otimizadas.
OCR com Inteligência Artifical
A Inteligência Artificial (IA) leva o OCR a outro nível, tornando-o mais preciso e adaptável.
- Aprende continuamente, melhorando a extração de dados ao longo do tempo.
- Reconhece semântica, idiomas e formatos diferentes, aumentando a versatilidade.
- Imita a inteligência humana, processando informações com alta velocidade e precisão.
Independentemente do seu setor, um OCR inteligente com IA pode automatizar processos e maximizar o valor dos seus dados.
Agora que explorámos Machine Learning e IA, vejamos os benefícios práticos destas tecnologias nas soluções modernas de OCR.
Principais Benefícios do Novo OCR Inteligente
As soluções avançadas de OCR com Inteligência Artificial (IA) e Machine Learning (ML) vão muito além do simples reconhecimento de caracteres. Para entender como esta tecnologia pode revolucionar o processamento de documentos, veja os principais benefícios:
Digitalização rápida e eficiente – Converta documentos físicos em formatos digitais como PDF, JSON, CSV ou XML em segundos, eliminando a necessidade de papel.
Implementação mais rápida – Sem depender de regras rígidas, as soluções modernas exigem menos tempo de configuração, tornando a adoção da tecnologia mais simples e ágil.
Escalabilidade sem limites – O OCR tradicional torna-se caro à medida que o volume de documentos cresce. Já as soluções baseadas na nuvem expandem-se facilmente, sem comprometer a eficiência.
Precisão incomparável – Enquanto o OCR tradicional atinge entre 60% e 85% de precisão, o OCR com IA pode alcançar até 99%, superando até a extração manual, que varia entre 90% e 95%.
Menos erros manuais – A introdução manual de dados está sujeita a falhas, especialmente em tarefas repetitivas. O OCR com IA minimiza erros, aumentando a fiabilidade dos dados extraídos.
Processamento ultra-rápido – A extração manual demora entre 10 a 20 minutos por documento, enquanto o OCR tradicional reduz esse tempo para menos de metade. Já o IDP (Processamento Inteligente de Documentos) faz tudo em apenas 15 segundos, poupando até 98% do tempo.
Redução significativa de custos – O custo médio do processamento manual de documentos varia entre 4€ e 6€ por documento. O OCR tradicional reduz esse valor para 1€ a 2€, enquanto o IDP pode baixar para menos de 0,50€ por documento.
Deteção de fraudes – A análise de imagem e metadados (EXIF) permite identificar possíveis fraudes documentais, protegendo empresas contra perdas financeiras internas e externas.
Melhoria da experiência do cliente – No setor bancário, por exemplo, o OCR com IA torna o processo de integração de novos clientes mais rápido e sem complicações, permitindo cadastros e verificações diretamente pelo telemóvel.
Comparação dos Métodos de Processamento de Documentos
Já explorámos os principais benefícios das tecnologias avançadas de OCR, mas com tantas opções disponíveis, como escolher a melhor solução para o seu negócio? O processamento de documentos pode ser feito de várias formas, e cada método tem as suas vantagens e limitações.
Para ajudar na decisão, criámos uma tabela comparativa que destaca as diferenças entre os métodos tradicionais e as soluções mais inovadoras.

No geral, o OCR oferece grandes benefícios para as empresas, mas as tecnologias mais avançadas, como o IDP (Processamento Inteligente de Documentos), proporcionam um desempenho muito superior às soluções convencionais. Nenhuma tecnologia é perfeita, mas a evolução do OCR tem permitido superar muitas das suas limitações, tornando os processos mais ágeis, precisos e eficientes.
Agora que já analisámos os benefícios, vamos explorar algumas das aplicações mais comuns desta tecnologia.
Para que é utilizado o OCR?
O OCR com IA permite automatizar tarefas repetitivas e de grande volume, tornando o processamento de documentos mais rápido, preciso e eficiente. Abaixo, destacamos alguns dos principais casos de uso desta tecnologia:
1. OCR em Recibos para Programas de Fidelização
Muitos programas de fidelização baseiam-se na submissão de recibos como prova de compra para acumular pontos ou cashback. Este processo pode ser trabalhoso e propenso a erros quando feito manualmente.
Com um OCR para recibos, as empresas podem:
- Verificar automaticamente os recibos, validando compras em segundos.
- Evitar fraudes, detetando tentativas de envio duplicado através da análise de imagem.
- Extrair dados essenciais, como nome do comerciante, montante total, IVA, data da compra e itens adquiridos.
2. Extração de Dados de Documentos de Identificação para o Onboarding de Clientes
No setor financeiro, a verificação de identidade (KYC – Conheça Seu Cliente) é um requisito essencial. No entanto, quando feita manualmente, pode ser demorada e sujeita a falhas.
O OCR permite:
- Extrair dados-chave, como nome, nacionalidade, data de nascimento, validade e número do documento.
- Digitalizar e extrair dados automaticamente de documentos de identificação, acelerando o onboarding.
- Comparar informações com bases de dados para deteção de fraudes.
- Reduzir a introdução manual de dados, eliminando erros e poupando tempo.
3. Processamento Automatizado de Faturas (Contas a Pagar)
O processamento de faturas e contas a pagar envolve organização, verificação e aprovação antes do pagamento.
Tradicionalmente, este fluxo de trabalho é manual e demorado, mas com OCR, as empresas podem:
- Capturar e organizar dados de faturas automaticamente.
- Eliminar a inserção manual, reduzindo erros e poupando tempo.
- Automatizar a integração com sistemas ERP e de contabilidade.
- Aumentar a eficiência – estudos mostram que empresas com automação de AP processam mais faturas com menos recursos.
- Reduzir custos em +70% e diminuir o tempo de processamento em até 70%.
4. Verificação Automatizada do Preenchimento de Documentos
Setores como o legal e bancário lidam frequentemente com documentos que precisam de ser validados antes de serem considerados oficiais. A ausência de assinaturas ou cláusulas pode tornar um contrato inválido e trazer problemas legais.
O OCR permite:
- Verificar se documentos contêm todas as assinaturas necessárias.
- Identificar informações em falta ou campos não preenchidos.
- Classificar automaticamente documentos, garantindo que estão completos.
- Verificar dados cruzados com bases de dados internas ou externas para maior segurança.

O OCR pode transformar completamente a forma como a sua organização processa documentos, aumentando a eficiência e reduzindo custos. Agora que conhece os seus principais benefícios, vamos explorar como integrar esta tecnologia nas suas operações.
Como Começar a Integrar o OCR?
Antes de integrar o OCR na sua empresa, é importante considerar alguns fatores, como o tipo de documento, o volume de processamento, os recursos disponíveis e o seu caso de utilização.
Para facilitar a decisão, aqui estão as principais opções de integração:
1. Integração com OCR API
Se já tem um software ou aplicação e quer adicionar OCR, uma API de OCR permite processar documentos enviados por aplicação móvel, e-mail ou portal web.
- Vantagens: Comunicação direta com o fornecedor de OCR, envio de documentos em segundos e retorno dos dados em formato estruturado.
- Ideal para: Empresas que já possuem uma aplicação e querem incorporar OCR sem grandes mudanças na infraestrutura.
2. Solução de Digitalização Móvel
Para empresas que precisam de capturar dados de forma ágil e remota, uma solução de digitalização móvel permite que os funcionários fotografem recibos e documentos, eliminando a necessidade de armazenamento físico.
- Vantagens: Poupança de tempo, redução de custos e possibilidade de digitalizar até objetos, como contadores de utilidade.
- Requisitos: Um Kit de Desenvolvimento de Software (SDK) para integrar a tecnologia na sua aplicação móvel.
- Escolha certa se: Precisa de OCR diretamente no telemóvel. Se apenas quer fazer upload de documentos num portal, uma API é a melhor opção.
3. Solução de Ponta a Ponta
Para uma implementação rápida e sem esforço, uma solução de OCR completa é a melhor escolha.
- Vantagens: Automação total de extração de dados, classificação, conversão e verificação.
- Exemplo: Plataformas como o Klippa DocHorizon agilizam o processamento documental sem necessidade de programação.
- Ideal para: Empresas que querem um sistema pronto a usar, sem necessidade de desenvolver internamente.
Vá Além do OCR Tradicional com a Klippa
O OCR tradicional já não é suficiente para acompanhar as exigências do mercado. As empresas precisam de mais precisão, rapidez e automação para melhorar a eficiência operacional e a experiência do cliente.
É aqui que a Klippa faz a diferença! Com tecnologia de OCR avançado, IA e Machine Learning, conseguimos não só extrair dados de documentos, mas também:
✔️ Verificar a autenticidade e garantir que os documentos são válidos.
✔️ Converter ficheiros para diferentes formatos como JSON, CSV, XML e muito mais.
✔️ Anonimizar dados sensíveis, garantindo conformidade com regulamentações como o RGPD.
✔️ Detetar fraudes, identificando padrões suspeitos e prevenindo perdas financeiras.
✔️ Automatizar todo o fluxo de trabalho, eliminando tarefas manuais e aumentando a eficiência.
Transforme a gestão documental da sua empresa com a Klippa!
Quer precise de integrar OCR através de uma API ou SDK, ou prefira uma solução completa pronta a usar, temos a tecnologia ideal para si.
Preencha o formulário abaixo para uma demonstração gratuita ou contacte-nos para mais informações. Estamos prontos para ajudar!