OCR software helps you read, extract, classify, and convert any kind of document or image that contains typed, handwritten, or printed text. It does so by leveraging Optical Character Recognition technology, which turns unstructured documents into structured, machine-readable data.
The need for well-performing OCR software is constantly growing. Documents such as emails, images, or scanned files pose a big challenge to organizations, due to their unstructured nature. Manually extracting information from these files is a time-consuming and repetitive task, as unstructured data needs further processing, delaying your business processes even more.
As the market offers many OCR solutions, it’s important to go through all the viable options and compare them before coming to a decision. In this blog, you will find a list of the best OCR software in 2025. Let’s get started!
Key Takeaways
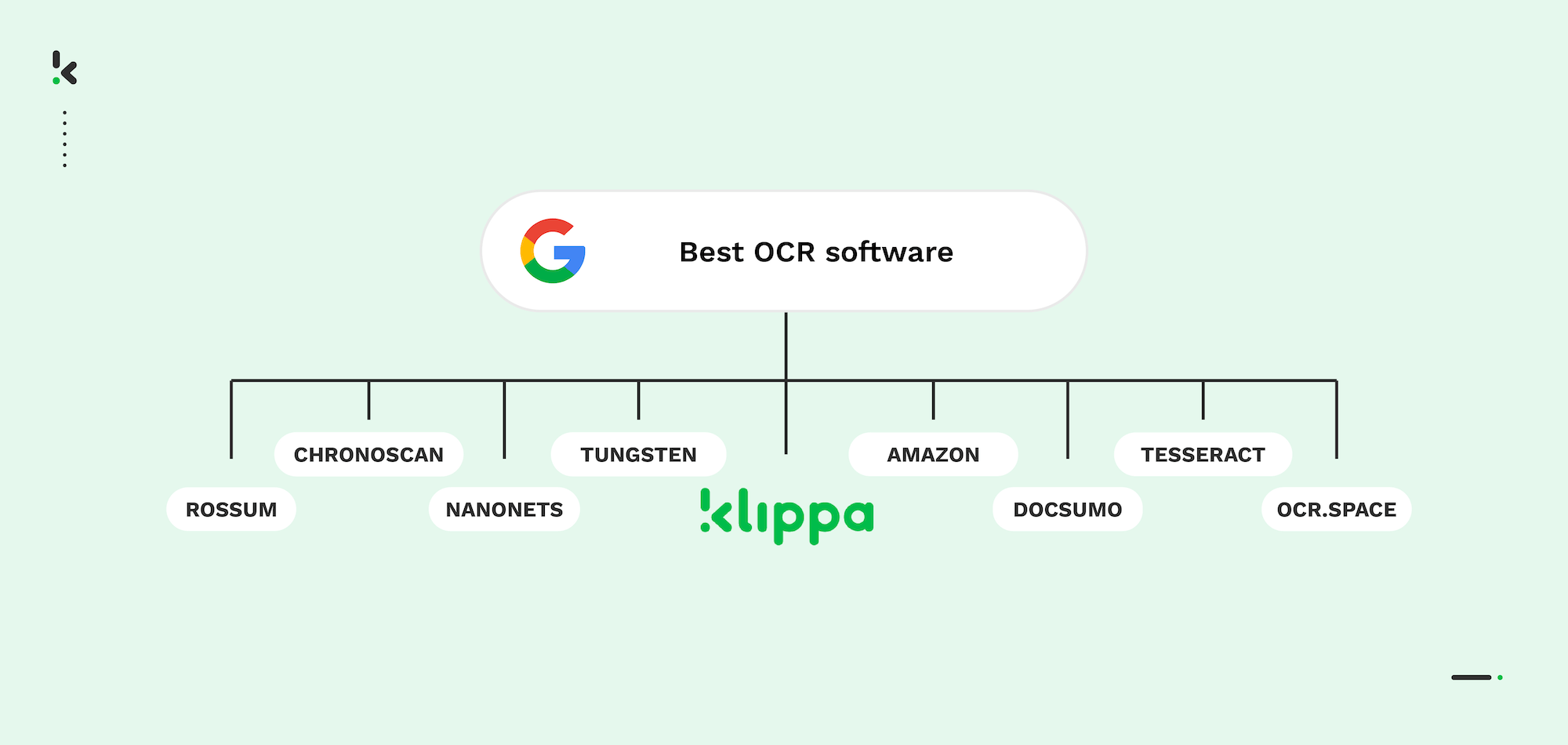
The 9 Best OCR Software Solutions for 2025 are:
- Klippa OCR: Our top choice for 2025 🏆 Best for high-volume document processing across industries like finance, healthcare, and legal, offering AI-powered data extraction and automation.
- Rossum: Best for cognitive data capture and anomaly detection, ideal for mid-market businesses in industries like IT, health & wellness, and more.
- ChronoScan OCR: Best for high-volume document management with batch processing, line item and table extraction, and barcode recognition.
- Tungsten Automation (Kofax): Best for enterprise-level invoice processing, offering field and line item extraction and integration with ERP systems.
- Nanonets: Best for customizable OCR with handwriting recognition and table extraction, making it ideal for accounts payable and insurance document automation.
- Amazon Textract: Ideal for machine learning-driven workflows, offering text and table extraction with custom smart search indexing for document-heavy workflows.
- Docsumo OCR: Best for simple document types, providing fast and efficient OCR with high accuracy for structured documents like invoices.
- OCR.space: Best for small-scale document processing, offering a free and easy-to-use OCR solution for occasional or light use.
- Tesseract: Best for free, open-source OCR for developers needing a customizable solution, though it requires technical setup and expertise.
Comparison of the best OCR software in 2025:
The Top 9 OCR Software in 2025
Without beating around the bush for too long, let’s dive straight into the top 9 OCR software tools you should consider in 2025.
To help you choose, we’ve looked into their features and explored real user feedback from trusted review platforms. The result is a clear overview of what each app does well and where it might fall short based on what actual users are saying.
1. Klippa OCR: The Best AI‑Powered OCR for 2025 🏆
Klippa OCR is an advanced AI-powered solution for automating data extraction from over 100 document types, including invoices, receipts, bank statements, passports, and more. Built entirely in-house, Klippa’s technology offers unmatched customization, reliability, and control, making it ideal for businesses with high-volume document processing needs.
Whether you need document automation for your loyalty programs, cashback campaigns, identity verification, or document processing, the AI-driven OCR solution can successfully help you capture the data you need.
Pros
- Upload files via app, web, and email
- Process documents within seconds with up to 99% accuracy
- Process PDF, JPG, PNG, XLSX, and other formats
- Utilize image pre-processing
- Extract key data from any document without relying on templates
- Validate data and flag any missing or potentially fraudulent information
- Forward structured data in your CRM, ERP or database directly
- Convert and export files as JSON, XLS, CSV, UBL, XML, and more
Cons
- No support for non-Latin languages
- May require onboarding for non-technical users
Pricing
- €25 free credit
- License or usage-based pricing model
- Contact the team for pricing details
Ideal business type and size: Klippa’s OCR is best suited for businesses with large volumes of documents.
2. Rossum: OCR with Cognitive Data Capture and Anomaly Detection
Rossum offers an AI-powered OCR to its users. Rossum’s solution helps users reduce manual data entry and facilitate data extraction from various document types.
Pros
- Up to 95% data extraction accuracy with AI-powered OCR
- Detection of duplicate documents
- Document classification with AI
- Data privacy and security compliance
- Multiple integrations available
Cons
- Lack of available documentation for integration
- Based on user reviews, the software occasionally fails to accurately extract data from specific kinds of documents (Software Advice)
Pricing
- Custom pricing, depending on the business’s requirements and needs
Ideal business type and size: Rossum is best suited for medium to large-sized businesses that handle a high volume of invoices primarily in the English language.
3. ChronoScan OCR: OCR for High-Volume Document Management
ChronoScan is a multipurpose software designed to help you with document processing and data capture, and extraction using OCR technology. This complete suite for data entry works in a fast way, enabling you to organize your documents in minutes.
Pros
- Batch processing for high-volume documents
- Line item and table extraction
- Barcode extraction
- Can be integrated into third-party applications, such as CRM or ERP systems
- Document management for scanned and digitized files
Cons
- Only converts PDF files to XML or CSV
- Does not offer onboarding support for its solution
- No fraud detection for documents or images.
- Based on user reviews, extended features like workflow automation and archiving are only available with the premium version (Capterra)
Pricing
- Professional: For small applications, for €245/one time
- Advanced: For medium/big applications for €595/one time
- Enterprise: For big/scalable applications, custom pricing
Ideal business type and size: ChronoScan OCR is best suited for freelancers, small, medium, and large companies that mainly process PDF documents to XML or CSV formats.
4. Tungsten Automation: OCR Built for Enterprise Invoice Processing
Tungsten Automation OCR solution – OmniPage, helps convert and edit documents, as well as make them searchable and shareable. Tungsten offers fast OCR, ICR, barcode recognition, PDF compression, and image processing.
Pros
- Capturing and validation of invoices from paper, PDF, email attachments, and electronic formats
- Recognition and capturing of fields, line items, and tables
- Search, edit, and access documents on any device
- Support of 100+ OCR languages
- Integration with popular ERP and accounting systems, such as Microsoft D365 and Oracle
Cons
- Lack of available output formats
- Based on platform reviews, the invoice verification software displays occasional issues with data extraction accuracy (Trust Radius)
- Based on user reviews, the software lacks customization options, particularly for reporting and workflow adjustments (Capterra)
- Based on user reviews, the implementation and learning curve for the software are tedious (Gartner)
Pricing
- Custom pricing, depending on the business’s requirements and needs
Ideal business type and size: Tungsten Automation is best suited for medium to large-sized enterprises with high document volumes and multi-entity operations.
5. Nanonets: OCR with Customizable Handwriting and Table Extraction
Nanonets is an OCR software provider that offers a modern and functional solution for automating document-related processes. Nanonets helps companies automate document-heavy business processes like accounts payable, order processing, and insurance underwriting.

Pros
- Data extraction from PDFs, images, scans, tables, emails, and websites
- Handwriting recognition
- End-to-end document management system
- Good customer support
- Line item and custom data field extraction
Cons
- Limited outputs are available for the extracted data
- Limited line item extraction options
- Based on user reviews, the software is relatively expensive for smaller businesses and lacks quality customer support (TechRadar)
Pricing
- Starter plan: Try out the platform with limited features and 500 pages, then $0.3/page + $0.5/step of workflow integration
- Pro plan: Advanced on-platform tools for $999/month/workflow
- Enterprise plan: Custom workflow add-ons, custom pricing
Ideal business type and size: Nanonets is best suited for small to medium-sized businesses.
6. Amazon Textract: OCR with Machine Learning for Document Workflows
Amazon Textract is a good solution for businesses that need to extract printed text from various document types. This software uses machine learning to extract both structured and unstructured data from your files.
Pros
- Extraction of printed text, handwriting, layout elements, and data
- Table extraction and signature detection
- Custom smart search indexes
- Custom document processing workflows
- Document classification for improved archiving
Cons
- Only processes documents in English, Spanish, Italian, French, Portuguese
- Only supports PNG, JPEG, and PDF formats
- Processing large volumes of documents is only possible with the premium version
- Based on user reviews, the OCR has a lot of accuracy issues (G2)
Pricing
- Custom pricing, depending on the business’s requirements and needs
Ideal business type and size: Amazon Textract is best suited for medium to large enterprises with document-heavy workflows.
7. Docsumo: Fast and Efficient OCR for Simple Document Types
Docsumo‘s OCR is a quick and efficient way to extract data from images or PDF documents. It uses deep learning to create machine-readable text. Docsumo’s solution makes scanning and data extraction easy, no matter how complicated the layout is.
Pros
- Up to 90% accuracy in data extraction
- Option to review the extraction output for increased accuracy
- Convert the documents to JSON, Excel, CSV, or TXT
- Does not store processed documents on its servers
- Table extraction, from PDF to Excel
Cons
- The only supported input format is PDF
- Only processes 4 files simultaneously
- Cannot process files larger than 200MB
- Based on user reviews, Docsumo provides categories for documents that can be processed, and if users go outside of these categories (e.g., unique invoices), the software experiences issues with data extraction (Software Advice)
Pricing
- Growth plan: For businesses that need to automate one or two document types from $500+/month
- Business plan: Platform for businesses that need to capture specific data points from documents and train on their data, with custom pricing
- Enterprise plan: for enterprises that need to process multiple document types, train on their data, and implement custom workflows, with custom pricing
Ideal business type and size: Docsumo’s OCR is best suited for small to medium-sized businesses that mainly process and scan relatively simple, structured documents.
8. OCR.space: Affordable OCR for Small-Scale Document Processing
Ocr.space is a cloud-based service that uses OCR to convert scanned documents or images containing text into editable PDF files. This OCR solution allows you to upload images or files in PNG, JPG, WEBP, or PDF formats, or paste your URL to the source file.
Pros
- Automatic image pre-processing
- Table recognition system
- Auto-enlarge documents for the best quality
- Searchable system for converted documents
- Ideal for a small volume of documents
Cons
- File size restriction for documents bigger than 1MB in the free plan
- Template-based OCR, which comes with limitations
- Extraction output can only be in JSON format
- Bulk processing is available only with the premium plan
Pricing
- Free plan: Up to 25,000 requests with a file size limit of 1 MB per image
- PRO plan: Up to 300,000 requests with a maximum file size of 5 MB per image for $30/month
- PRO PDF plan: Up to 300,000 requests with a file size limit exceeding 100 MB for $60/month
- Enterprise plan: Customizable solutions and unlimited conversions for $999/month
Ideal business type and size: OCR.space is best suited for freelancers and small businesses with occasional OCR needs or limited technical expertise.
9. Tesseract: Open-Source OCR for Developers
Tesseract is an open-source OCR software used to extract text from images. Tesseract can recognize more than 100 languages, and it is compatible with many programming languages and frameworks.
Pros
- Free and open-source OCR solution
- Recognition of 100+ languages
- Performs well with high-quality scans and structured text
- Can be wrapped and coupled with Python OCR libraries
- Extraction of text from multi-page PDFs and various image formats
Cons
- Time-consuming and expensive to set up
- Lack of document types available for processing
- Does not perform document verification
- Does not cross-validate data
- Not compliant with data privacy regulations
- Not able to detect document fraud or forgery
- Based on user reviews, Tesseract OCR can be highly inaccurate, especially while processing medium and low-quality images (Reddit)
Pricing
- Free
Ideal business type and size: Tesseract is best suited for smaller businesses and start-ups needing a free, open-source OCR solution for on-premise or customizable document processing, but it requires technical expertise for setup and optimization.
Free OCR Solutions
When you have a simple use for OCR with a low document processing volume, you may want to consider free OCR solutions available. Some of these options include:
While these solutions are free, they do come with certain limitations you want to take into consideration:
- Lack of scalability: Often, these free optical character recognition software solutions don’t offer the scalability that you may need, especially when your document volume is set to increase, while your business is steadily growing.
- Low data extraction accuracy: Most of the free solutions don’t have data extraction capabilities to get information extracted accurately, creating more bottlenecks than they solve.
- Require resources to develop: Open-source OCR software like Tesseract is a good option; however, it requires time and money to build, train, and maintain, so it may not fit your business needs.
Why Klippa Stands Out Among the Best OCR Software Tools
Klippa isn’t just another OCR tool; it’s a full AI-powered document processing platform, combining smart pre-processing, deep learning models trained on complex documents, low-code workflow automation, and built-in fraud detection to deliver accurate, scalable, and secure data extraction from any document type.
Now part of the SER Group, a recognized Leader in the Gartner® Magic Quadrant™ for Document Management, Klippa delivers advanced OCR and intelligent document processing capabilities to teams across industries, making it the top OCR platform choice for 2025.
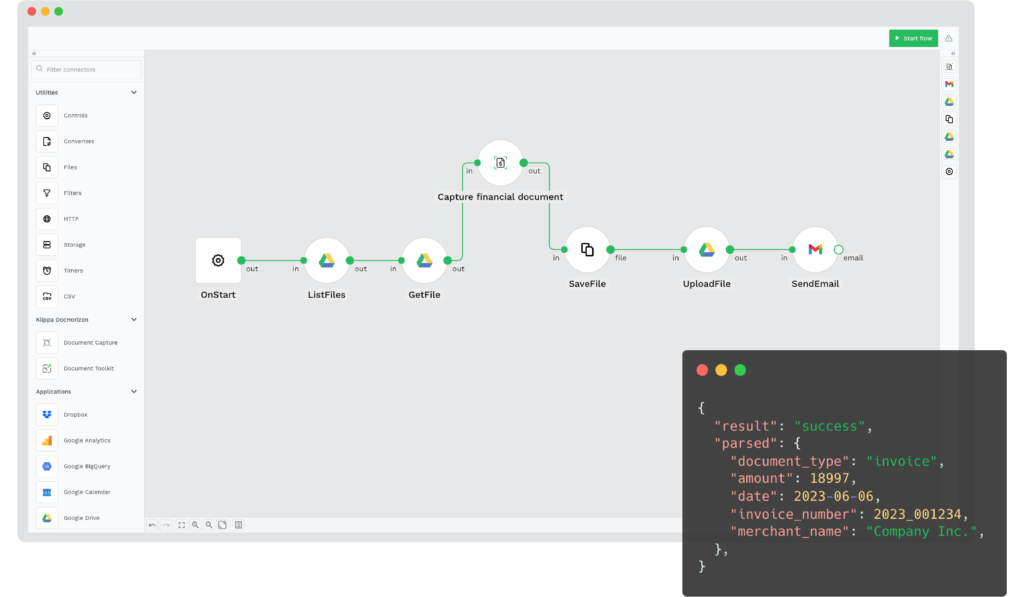
Klippa’s low-code platform, DocHorizon, makes it easy to automate and optimize every step of your document workflow. With powerful features and intuitive controls, you can:
- Create your own flows with an easy drag-and-drop user interface
- Indicate the tasks you wish to be carried out in the workflow
- Retrieve documents from existing databases, device folders, email, Google Drive, and many more
- Shorten document processing times with data entry automation
- Send data to existing applications with seamless document conversion
- Certify the authenticity of documents with document verification
- Stay compliant with personal data protection requirements with smart data anonymization
- Ensure accurate document verification processes with document fraud detection
- Streamline the digital archive of your business with document classification and sorting
Contact our experts for more insight into our OCR software capabilities or book a free demo down below!
FAQ
OCR stands for Optical Character Recognition. It’s a technology that identifies and extracts text from scanned documents, images, or PDFs, converting it into machine-readable data.
OCR software is a tool that uses OCR technology to recognize, extract, classify, and convert text from various types of documents or images, turning unstructured data into structured information.
OCR software is primarily used to automate the extraction of text from unstructured documents like receipts, invoices, passports, and emails. This automation speeds up data entry and reduces manual processing, helping organizations manage data more efficiently.
The best OCR technology depends on your business needs. In 2025, Klippa stands out for its high accuracy, AI-driven document processing, and robust API integrations, making it ideal for high-volume workflows.