Businesses store data in online databases and environments more than ever before. In fact, 60% of the world’s corporate data is in the cloud. But do these businesses have the right tools to protect privacy-sensitive data? While there are many data privacy regulations that businesses must adhere to, such as GDPR in Europe, they do not always safeguard data from data breaches.
According to Verizon, most of the breaches involve stolen credentials and types of human actions, including mistakes, social engineering attacks (like phishing), and privilege misuse. Every time a business undergoes a data breach, it can become costly to take appropriate measures to minimize the damages and inform various stakeholders of the data concerns.
Next to that, it can have a negative impact on the reputation of the business, which can result in financial losses in the long run. This is why organizations should find preventive measures, such as data anonymization and its automation, to safeguard the sensitive data they store and process.
How these preventive measures look, which techniques can be used, and how to automate data anonymization with modern AI solutions will be discussed in this blog.
Let’s get started!
Key Takeaways
- Data anonymization is the process of irreversibly altering or removing personally identifiable information (PII) to prevent individuals from being identified. It helps organizations comply with data privacy laws like GDPR and CCPA while maintaining the usefulness of the data.
- Manual anonymization is time-consuming, error-prone, and not scalable. Automated solutions use AI and machine learning to detect, classify, and anonymize data in a fast, reliable, and compliant way.
- Typical use cases for automated data anonymization are remote client onboarding, financial information processing, and software development.
- With Klippa’s OCR and AI-power solution, you can extract, classify, and anonymize data from documents like PDFs and images while being compliant with privacy regulations.
What is Data Anonymization?
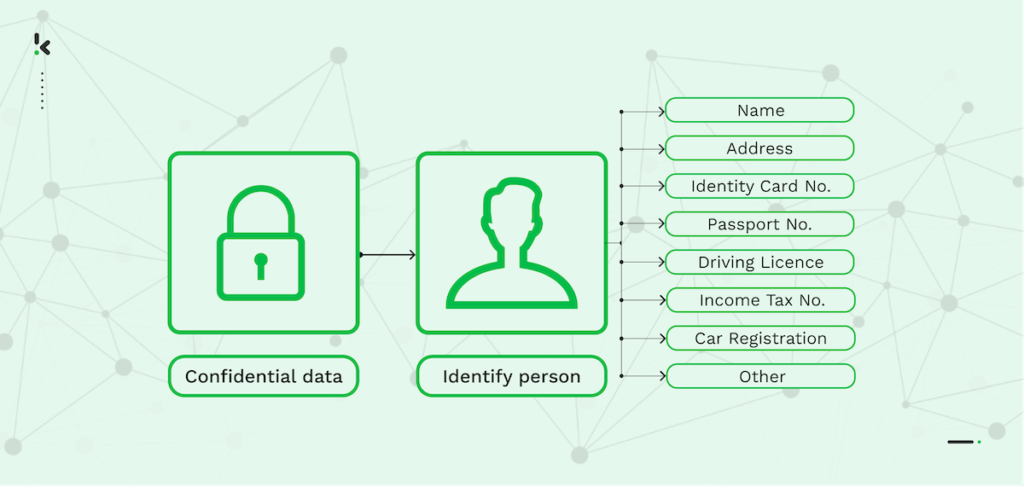
Data anonymization protects confidential or personal information by deleting or altering personally identifiable data (PII) that are being stored in a dataset.
The goal is to preserve the credibility of the data stored or exchanged and ensure compliance with strict data privacy regulations. For example, the ISO standard’s main criteria of anonymization is that PII is irreversibly altered so that the person can no longer be identified directly or indirectly.
While the human factor accounts for one-third of the total data breaches, some companies still rely on manual anonymization. This involves an employee manually reviewing and modifying databases to meet privacy regulations.
Other companies leverage AI and machine learning technologies to streamline this process. These solutions automatically detect and classify sensitive data, apply constant anonymization techniques, and ensure compliance with privacy frameworks.
Now that you know what data anonymization is and the difference between manual and automated data anonymization, let’s continue with why data anonymization is so important.
Why You Should Anonymize Data
There are various reasons why you should anonymize data. The most important reasons may include the following :
- Safeguarding against data misusage: Data anonymization ensures that internal stakeholders cannot misuse the data and minimizes the risk of data being exploited if the organization ever gets breached by external perpetrators.
- Complying with data privacy regulations: The General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States require companies to protect individuals’ data and provide certain rights to data subjects. Anonymizing data helps companies meet these requirements and avoid fines for not complying with the regulations.
- Data sharing opportunities: Data having personally identifiable information cannot be shared with third-party companies, which creates a limitation in finding new business opportunities. However, with data anonymization, companies can share data with partners or researchers to gain new insights and develop new products. For instance, anonymized data can be used to train machine learning models to improve products and services.
While it is important and can be beneficial for your organization to anonymize data, the approach you choose counts in the long run of your business. As mentioned, manually anonymizing data is quite risky and – from our point of view – shouldn’t even be considered when automation solutions are still on the market. What makes us think like this?
How Does Automating Data Anonymization Work?
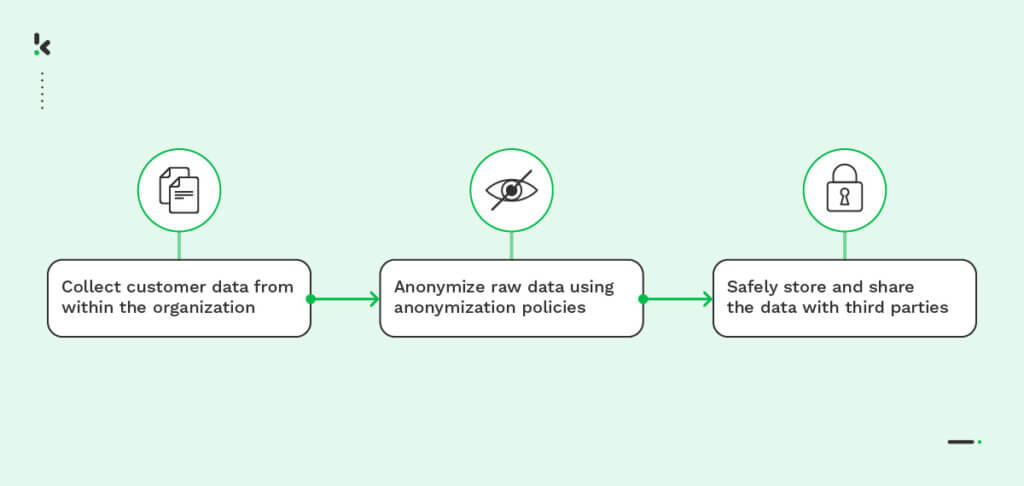
Automating data anonymization begins with the AI-powered software automatically identifying PII in the dataset and then determining the right anonymization technique depending on the potential risk of breaches. There are various software solutions available that can support your use case and requirements, for example:
- Data Masking Software
- Data Encryption Software
- Data Anonymization Software
- Data Governance Software
- Intelligent Document Processing Software
Each of these software uses a different set of data anonymization techniques, which can be executed automatically. In the next section, we will discuss this more in-depth.
Automated Data Anonymization Techniques
The following list consists of the most commonly used techniques to anonymize or remove sensitive data:
- Data Masking
- Pseudonymization
- Generalization
- Data Swapping
- Data Perturbation
- Synthetic Data
Data Masking
Data masking is the process of making data accessible with modified values. Automated data masking can be done by modifying data in real time (dynamic data masking) or by creating a mirror image of a database based on altered data (static data masking). This can be performed with a range of data-masking techniques such as encryption, data redaction, character shuffling, value substitution, scrambling, etc.
Pseudonymization
Pseudonymization is a data de-identification method to replace private identifiers with pseudonyms (false identifiers). An example could be switching the name “Jane Smith” with “Janet Doe”. Automated pseudonymization ensures statistical precision while ensuring that data is confidential. This means that data can still be used for training, testing, and analysis purposes.
Generalization
Generalization is a technique to purposefully exclude some parts of data to make it less identifiable while retaining data accuracy. By automating this technique, data can be modified into a range of values with logical boundaries without intervention. For example, a specific address can be revealed without a house number, or the number is replaced within a range of 140 house numbers of the original one.
Data Swapping
Data swapping is a technique that swaps and rearranges dataset attribute values, making the data unmatched with the initial information. Switching attributes that include identifiable values such as social security number or date of birth can significantly influence anonymization.
Data swapping is often used when dealing with identifiable data inside columns stored in excel files, customer or employee records. Algorithms can automatically shuffle data within columns so there is no link between the records and the individuals.
Data Perturbation
Data perturbation is a technique that slightly modifies the initial dataset. The software can add random noise and use value rounding methods. The values must be proportional to the disturbance employed to retain data usability. For example, if the base used to modify the original values is too small, data cannot be sufficiently anonymized. If the base is too large, the data may not be recognizable or usable.
For example, often a base value of 5 is used for rounding values such as age.
Synthetic Data
Synthetic Data is algorithmically generated artificial datasets with no relation to any original case. This method is enabled by the use of mathematical models based on patterns residing in the original dataset. Such models include linear regressions, standard deviations, medians, or other statistical models useful for creating synthetic outcomes. AI models can instantly understand trends from real datasets and generate artificial ones where the real PII is hidden.
With the use of artificial datasets and automated solutions, there are no risks of compromising data protection and privacy as they don’t include any more personally identifiable information.
These techniques may have crossed your path if your organization works with privacy-sensitive data. However, manually dealing with them is difficult, especially when high volumes of data are involved. In the next section, we’ll explore how you can automate these anonymization methods using modern software solutions.
How to Automate Data Anonymization?
As data privacy concerns increase, businesses are trying to find reliable solutions to protect themselves and their customers’ data. But what to do to avoid a nightmare like a data breach?
Let’s see what the professionals are saying. In a study by Ponemom Institute, a whopping 70% of cybersecurity professionals say that AI is highly effective in detecting threats that previously would’ve gone unnoticed. This is great! Finally, a solution that can help you, vetted by experts!
However, there is a catch. Without a concrete plan, adopting such a complex technology will take time and resources, which you might not have. To make things easier, we created a step-by-step guide on how to automate the data anonymization process. So you don’t have to worry about anything and can just get started.
- Identify and classify sensitive data using AI-powered detection tools – You must first locate and understand which data is considered sensitive. AI-powered tools can scan data sources to detect PII, such as names, addresses, financial data, etc. Also, they use pattern recognition, natural language processing (NLP), and machine learning to automatically classify data based on risk level and sensitivity.
- Choose the right anonymization technique based on automation capabilities – Depending on your use case, you may opt for techniques like masking, pseudonymization, generalization, or synthetic data generation. Automated platforms can apply the most appropriate method based on data type and use case.
- Implement anonymization using software or APIs – Once the method is selected, the anonymization process can be applied through specialized platforms or via APIs that integrate into your current system. Many of them support real-time processing and perform anonymization automatically as data enters or exits your systems.
- Test and validate anonymized data through automated compliance checks – It’s critical to verify whether the data still has identifiable information or not. Automated tools can verify anonymized datasets for residual PII, and some of them even have built-in compliance scoring or red flag alerts so that anonymization can meet legal and internal regulations.
- Ensure compliance with legal regulations using automated monitoring – Data processing and anonymization are strictly regulated by privacy laws like GDPR, HIPAA, and CCPA. Automated AI-powered tools can make your business compliant and reduce human error by monitoring anonymized data usage, generating audit trails, and notifying teams of any potential violations.
- Continuously update anonymization techniques with AI-driven solutions – Data privacy threats evolve, and so must anonymization processes. Since AI-powered tools can learn from data patterns and privacy risks over time, the accuracy and efficiency of data anonymization improves constantly. Regularly updating detection algorithms, policy rules, and anonymization logic is needed to ensure the chosen solution is effective against new threats and regulatory changes.
And there you have it! A simple yet effective plan to help you protect sensitive information and stay compliant with privacy regulations. The next question might be if this is something relevant for you and your business. In the next section, we aim to make things easier by presenting the best data anonymization use cases.
Best Data Anonymization Use Case
To keep this blog readable, we only cover the cases we come across most often and where automated data anonymization has the most benefits. The following list is not exhaustive:
- Remote Client Onboarding
- Financial Information Processing
- Software & Product Development
Remote Client Onboarding
Organizations that need to verify and store their client information during the remote onboarding processes are subject to various regulations, such as KYC, GDPR, and AML, to name a few. Oftentimes, clients need to scan their identity documents in order for the business to verify their identity or perform customer due diligence.
To protect PII such as social security numbers (SSN) or dates of birth from being misused, organizations can use automated document processing solutions to detect and anonymize PII.
For example, Intelligent Document Processing (IDP) applies automatic masking techniques to hide sensitive fields from scanned documents – without manual effort and with minimized risks.
Financial Information Processing
Financial institutions need to protect the privacy of their customers when processing financial information. Using automated anonymization software, they can instantly remove or obscure PII from data sets across transaction reports, credit reports, payment information, invoices, bank statements, and loan applications.
They can use data anonymization techniques such as data masking or generalization and apply them automatically at scale, ensuring privacy while maintaining data usability for analytics or compliance checks.

Software & Product Development
Developers need to use real data when developing software and tools to overcome real-life problems, perform testing, and improve existing solutions. Data anonymization is often automated because the development environment can be vulnerable to breaches due to leakages or data being shared across multiple teams. This can ultimately lead to sensitive data becoming compromised.
By having an AI-based solution that generates synthetic data and automates pseudonymization, companies can now simulate realistic scenarios without exposing any personal data.
How to Overcome Common Challenges in Data Anonymization
While anonymizing your data has countless benefits, it’s not perfect and comes with challenges. Fortunately, many of them can be addressed and resolved through the use of automation. Here are the most common 2 disadvantages of automated data anonymization and how automation can help overcome them:
Loss of data utility
Whether manual or automated, data anonymization reduces its usability. For example, removing identifiers and anonymizing data may restrict the ability to make use of the data in the results, as the data cannot be used for personalized marketing or targeting purposes.
With automation, data can be anonymized selectively based on context, business goals, and legal requirements. This way, only the minimum necessary is anonymized, and the analytical value is preserved.
By using techniques like pseudonymization or differential privacy, the software can still generate insights while protecting personal identifiers. Also, synthetic data can stimulate the real one without exposing the actual PII.
Relies on technical resources
Automating data anonymization can be a technically and resource-intensive process. Organizations would need to have specialized knowledge and expertise to implement. Next to that, it can be time-consuming and costly to maintain.
Due to sophisticated hackers and data breach methods, companies must continuously update their anonymization techniques to ensure that data remain truly anonymous.
Automated anonymization platforms have built-in rule engines and pre-configured templates for compliance, and the AI models can detect and handle PII across large databases. By handing detection, anonymization, and even logging or audit trails in the background, they can successfully minimize your team’s manual intervention and effort.
Now that you have the complete picture of the pros and cons of data anonymization, maybe you are ready to finally see which options are out there. We will present you what is – in our opinion – a great solution for automating data anonymization processes while enjoying benefits like customizable workflows, automatic fraud detection, wide document support and many more!
Automated Data Anonymization with Klippa DocHorizon
If you want to automate data anonymization from documents that you collect, digitize, and extract, Klippa can help you. Our Intelligent Document Processing software, DocHorizon, uses Optical Character Recognition (OCR) to extract text from images and AI models to recognize, classify, and anonymize data according to your needs. How?
DocHorizon can be trained to blackline and mask certain fields and text from documents that are sent to the parsing engine. These documents can be sent via mail, web, or mobile application in the form of JPG, PNG, and PDF, for example. After the data anonymization is applied, you can receive the anonymized data in the form of your choice, including JSON, XLSX, XML, or CSV.
Implementation of our automated data anonymization solution is very easy due to the proper documentation available and can be done via API or SDK. Our API will be useful for you if you want to build your own information extraction and anonymization pipeline and connect it with your existing software systems.
Our SDK, on the other hand, enables you to turn your mobile devices into data capture devices with the ability to mask data selectively. This is useful if you want to add data anonymization features to your existing or soon-to-be-released mobile app.
Even more benefits on top of what we already mentioned? Yes! With DocHorizon, you can also:
- Retain data utility while automatically extracting and anonymizing data
- Enhance compliance with data privacy regulations and requirements
- Reduce costs as you don’t need to buy multiple solutions to create your data anonymization pipeline
- Have faster turnaround times of data anonymization and processing with automation
- Enable scalability with low dependency on human resources
Ready to automate your data extraction and anonymization? Simply click the button below to get a free demonstration of our software. If you have any further questions, contact our experts for more information.
FAQ
Automated data anonymization utilizes AI and machine learning algorithms to detect and classify sensitive data within datasets. Once identified, appropriate anonymization techniques are applied automatically, ensuring efficiency, consistency, and compliance with privacy regulations.
While anonymization reduces the risk of re-identification, it’s not foolproof. Techniques like data linkage can sometimes re-identify individuals, especially if anonymization isn’t thorough. Therefore, it’s crucial to apply sound anonymization methods and regularly assess their effectiveness.
Klippa’s anonymization feature automatically detects and masks sensitive information within documents using AI models. Users can customize which data fields to anonymize, ensuring flexibility and adherence to specific privacy requirements.
Klippa offers integration via API and SDK, enabling the seamless incorporation of its anonymization and document processing features into your current workflows and applications.