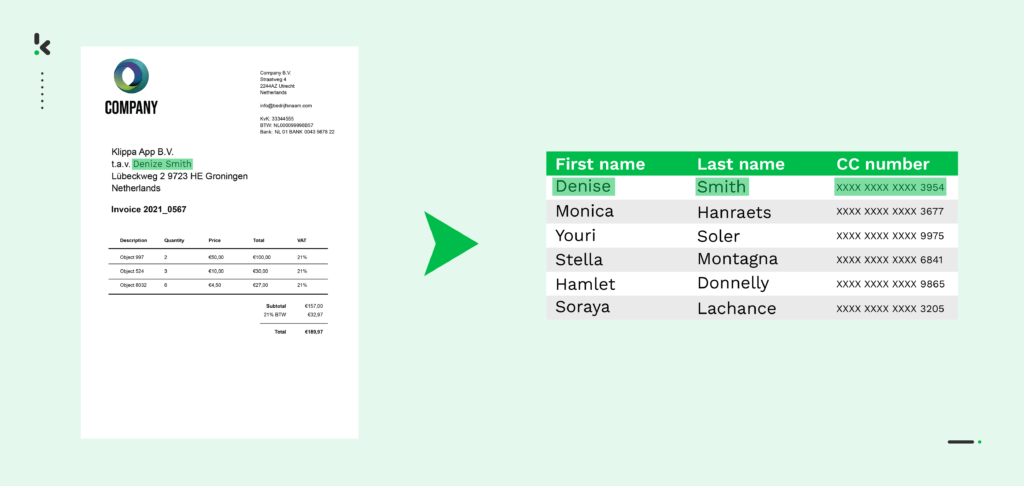
Sometime in your life, you’ve been using either Google to search for information or things to buy, or Netflix to find the right show that you are looking for. Obviously, you don’t always type it right, but the search engine is still able to find what you are looking for. That’s mainly because of fuzzy matching.
It’s not only helpful in this context but also in the context of data-matching challenges when there are multiple resources in play. It has been stated by Gartner that inaccurate data causes businesses to lose an average of $15 million a year. This is why technologies like fuzzy matching can be valuable for many businesses that deal with data.
This blog will help you understand what it is, why it’s necessary for modern organizations, how it works, and how it can be implemented.
Let’s get into it!
What is Fuzzy Matching?
Fuzzy Matching (FM), also known as fuzzy logic, approximate string matching, fuzzy name matching, or fuzzy string matching is a technique that helps users compare and find an approximate match between two different data sections or even one line of text.
This technique is often powered by technologies such as Artificial Intelligence (AI) and Machine Learning (ML). Fuzzy Matching, in particular, functions as a string-matching algorithm designed to search for a string within another string using predetermined rules. This allows it to find duplicate strings, words, or entries that are the closest match to each other. As a result, Fuzzy Matching can effectively identify names, words, or strings that are abbreviated, shortened, or misspelled.
Let’s say you want to find “invoice number” on a document, but the word is misspelled “invoic number” or is shortened as “invoice nr”. In this situation, you would not get an exact match when searching “invoice number”, thus you cannot find what you are looking for.

With the Fuzzy Sting Matching algorithms, this is not a problem, as the algorithm can still find an approximate match to the word that is misspelled or shortened by providing a match score of 0-100% based on the “edit corrections”. An edit correction is a correction that the FM algorithms have to make based on logic to adjust a certain string for that string to match with another string.
Fuzzy Data Matching Edit Corrections
In general, FM algorithms use the following edit corrections:
- Insertion – adding a letter to complete the word (e.g. “invoic” becomes “invoice”)
- Deletion – removing a letter from a word (e.g “Invoicee” becomes “invoice”)
- Substitution – swapping a letter to correct a word (e.g “onvoice” becomes “invoice”)
- Transposition – swapping letters around to correct a word (e.g “invioce” becomes “invoice”)
Each correction that needs to be performed, will attribute an “edit distance” of 1. The edit distances influence the match score mentioned earlier. For example, if you have a string with 11 characters and you would need to make 2 corrections, then the final match score equals 81.81%.
Calculation: 100%- 2 / 11= 81.81%
Next to these corrections, FM can be used to correct punctuations, extra words, and missing spaces in strings or texts.
To get a better understanding of how Fuzzy Matching works and the edit distances are calculated, the next section is dedicated to explaining various Fuzzy Matching algorithms in detail.
Fuzzy Matching Algorithms
Fuzzy Matching falls into the category of methods that don’t have one specific algorithm that covers all scenarios and use cases. Therefore, we will cover some of the most commonly used and reliable Fuzzy Matching algorithms in finding approximate data matches:
- Levenshtein Distance (LD)
- Hamming Distance (HD)
- Damerau-Levenshtein
Levenshtein Distance
The Levenshtein Distance (LD) is a Fuzzy Matching technique that takes two strings into account when comparing and finding a match. The higher the value of Levenshtein Distance is, the more the two strings or “terms” are far from an identical match.
So how do we get the value of the Levenshtein Distance? The LD between the two strings equals the number of edits needed to convert one string into the other. For the LD, insertion, deletion, and substitution of a single character apply as the edit operations.
Let’s say you want to measure the LD between “invoice number” and “invoice nmbr”. The distance between the two terms is “1 x u” and “1 x e”, which would equal a distance of 2. Why? Because you would need to add these two characters for them to be an exact match. See the examples below.
Levenshtein Distance Example
- Invoce number → Invoice number (insertion of “i”) – Distance: 1
- Invoice nmbr → Invoice number (insertion of “u” & “e”) – Distance: 2
- Invoice nr → Invoice number (insertion of “u,m,b,e”) – Distance: 4
Hamming Distance
The Hamming Distance (HD) is not too different from the Levenshtein. The Hamming Distance is often used to calculate the distance between two textual strings that are equal in length.
The HD method is based on the ASCII (American Standard Code for Information Interchange) table. To calculate the distance score, the Hamming Distance algorithm uses the table to determine the binary code associated with each letter in the strings.
Hamming Distance Example
Let’s take the following textual strings “number” and “lumber” as an example. When we try to determine the HD between the strings, the distance is not 1 like it would be with the Levenshtein algorithm. Instead, it would be 10. This is because the ASCII table shows a binary code of (1001110) for the letter N and (1001100) for the letter L.
Example calculation:
D = N – L = 1001110 – 1001100 = 10
Damerau-Levenshtein
The Damerau-Levenshtein also measures the distance between two words by measuring the required changes needed to be done to adjust one word into the other. These changes depend on the number of operations such as insertions, deletions, or substitutions of a single character, or transposition of two adjacent characters.
This is where the Damerau-Levenshtein distance differs from the regular Levenshtein distance, as it includes transpositions on top of just single-character edit operations to find an approximate match (Fuzzy Match).
Damerau-Levenshtein Example
String 1: Invoice
String 2: Invioc
Operation 1: transposition -> swap characters “i” and “o”
Operation 2: insert “e” at the end of string 2
As two operations were required to make the two strings identical, the distance equals 2. o put it simply, each operation such as insertion, deletion, transposition, etc, counts as a distance of “1”. However, with the Levenshtein Distance, you would need to perform three edit corrections, which would equal the distance of 3.
Clearly, all of the above-mentioned Fuzzy Matching algorithms differ from each other in the way the edit distance is calculated. This is the reason why there is no size-fits-all FM algorithm. However, the Levenshtein Distance is the most commonly used FM algorithm in data management and data science, among the three that were presented.
Fuzzy Matching Use Cases
There are multiple ways FM can be used in real-world applications, with some of them appearing in your everyday life. Let’s take a look at a few examples below (the list is not exhaustive):
- Document Data Extraction
- Auto Suggestion with Spell-Checking
- Deduplication
- Genome Sequencing
Document Data Extraction
Although OCR, also known as image-to-text extraction technology, is more advanced than 10 or even 20 years ago, it can still produce inaccurate data extraction results. As many businesses deal with a wide range of documents in high volumes, inaccurate data extraction results can cause them to lose significant amounts of money.
To complement OCR software and help solve this problem, Fuzzy Word Matching can be applied. In cases where OCR fails to find an “exact match” when extracting certain data fields and data from documents, Fuzzy Matching can help find the closest match with approximate string matching using the Levenshtein Distance.
This way businesses are still able to extract data from documents instead of the OCR software not producing any results at all when no exact match can be found.
Auto Suggestion with Spell-Checking
As mentioned earlier, you’ve probably encountered or used various search engines in your lifetime. While doing so, you’ve also noticed how sometimes search engines provide us with the content that we are looking for despite the misspelled words or sentences.
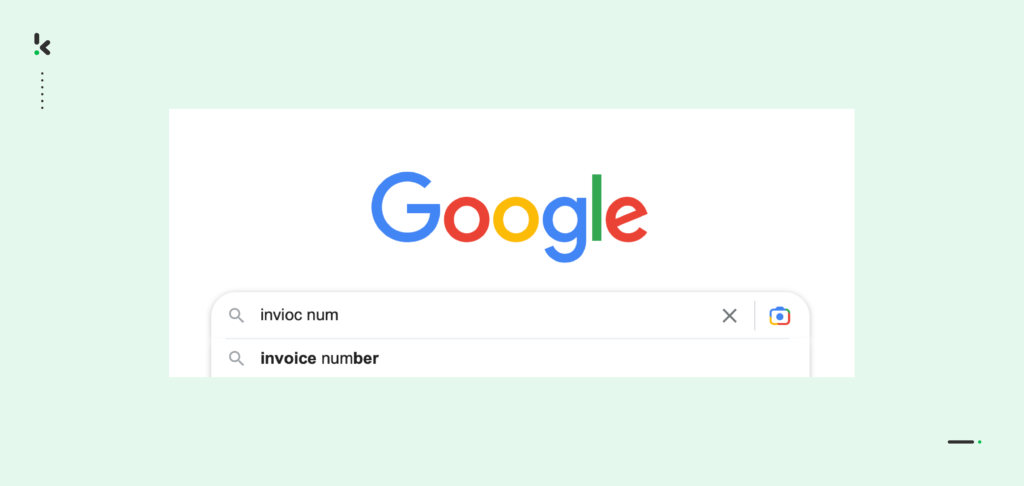
That’s only happening because search engines such as Google use Fuzzy Matching algorithms. Google understands what you meant to type as the main query and provides you with an option for the search word as you are typing on the search bar using Fuzzy logic.
Together with AI or ML, Fuzzy Matching has helped improve search engines such as Google and YouTube to make the search experience better.
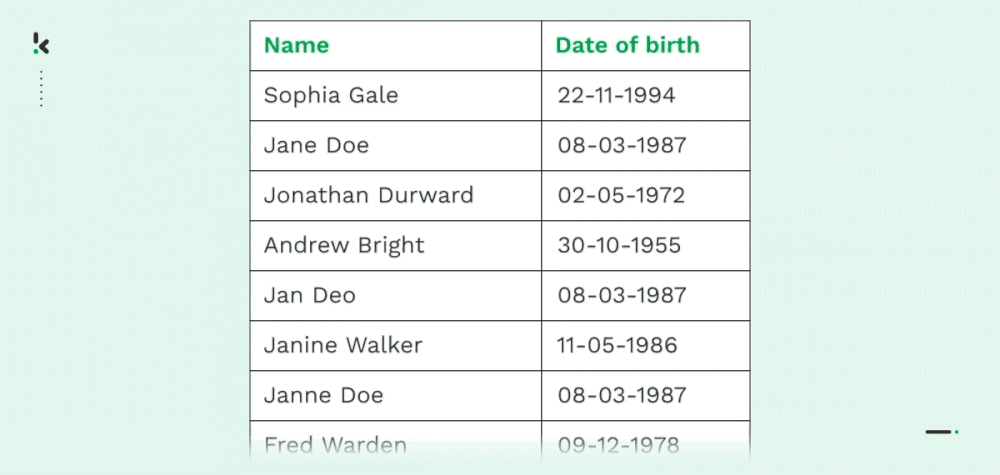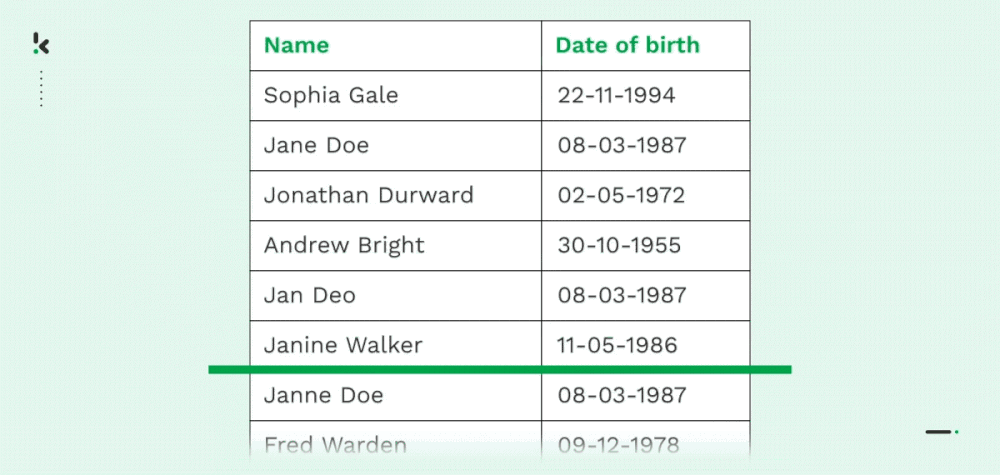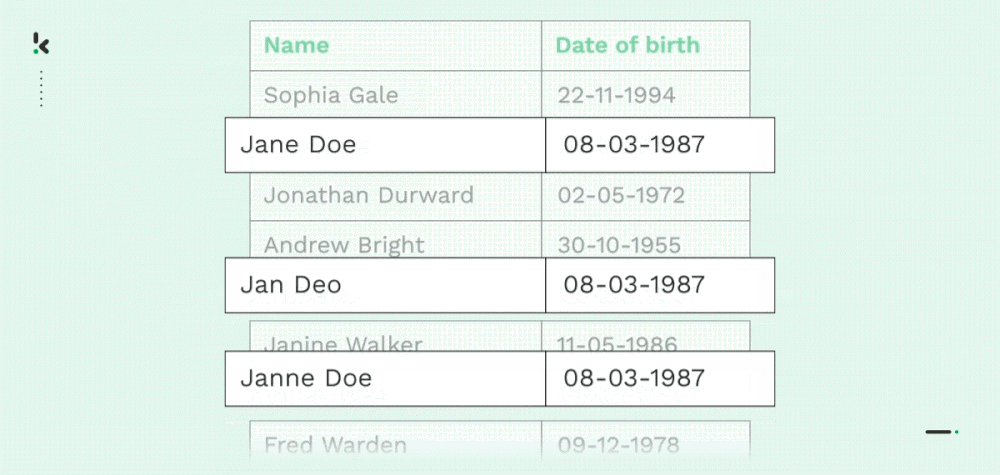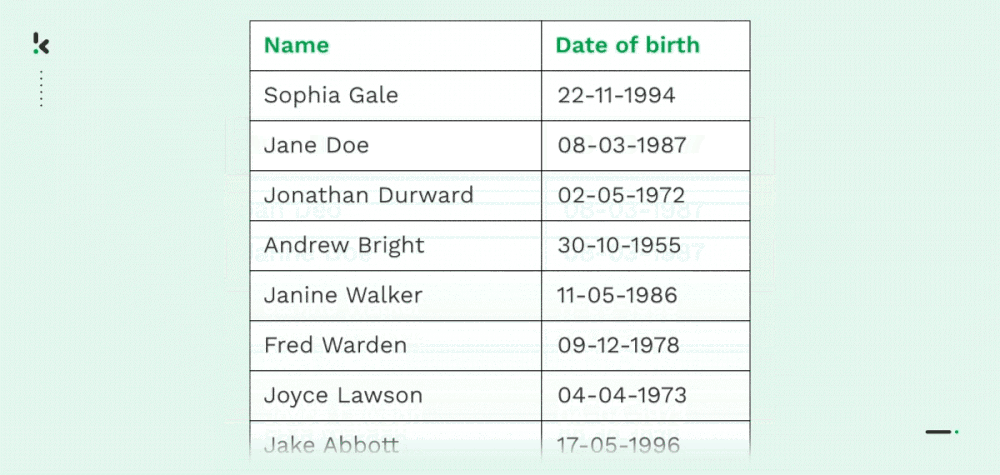
Deduplication
As mentioned before, numerous businesses suffer from duplicate data, mainly due to data transfers, lack of control, or data entry mistakes. Both carbon copies of a record (name, address, email, phone number, etc.) or partial duplicates are common for organizations.
With Fuzzy Matching, organizations can merge, delete, or reorganize data by finding approximate matches. It allows organizations to streamline their records and data management, which comes with various benefits discussed later in this blog.
Deduplication is also very useful when you are training OCR models to extract information from documents. By removing duplicate data samples from the training data sets, training becomes more efficient and the prediction accuracy of OCR models improves significantly.
Genome Sequencing
In healthcare and science, Fuzzy Matching can be very helpful, especially in genome sequencing. It enables researchers to find an approximate match to a particular genome sequence by running an algorithm on the sequence.
With the Fuzzy Matching Algorithm, they can find the nearest matching sequence or set of sequences to determine to which organism the sequence belongs based on the result. An example would be finding the closest match to a certain bacteria or virus to find the right cure.
In other words, Fuzzy Matching can help researchers find a cure for certain diseases. Interesting right?
By now, it should be clear that the use of FM is flexible and can be applied in various use cases. Whatever your use case may be, there are various benefits that Fuzzy Matching comes with.
Benefits of Fuzzy String Matching Algorithms
The most common benefits for organizations using Fuzzy Matching as their approach to identifying matches include:
- Data Accuracy – Organizations can achieve a high data matching accuracy as FM has the capability to search for approximate matches by analyzing the strings and calculating the “edit” distance score using algorithms.
- Searchable Data – Fuzzy Matching enables users to find matches despite the variations due to errors such as misspelling, miss capitalization, or miss formatting of words or strings.
- Flexibility – There are many ways where Fuzzy logic algorithms can help solve even the most complex problems.
- Cleaner Database – Fuzzy Matching algorithms can help organizations find duplicate data records for a healthier, cleaner, and more accurate database.
Downsides of Fuzzy Matching
Not everything about fuzzy string matching is perfect. On the contrary, FM comes with various limitations including:
- Incorrect Linking – Despite Fuzzy Matching being excellent in finding approximate matches, it sometimes results in a high amount of false positives leading to incorrect linkages, especially with larger databases.
- Requires Maintenance – The algorithms must be constantly tested and the rules in them updated in order to do string matching accurately.
Although there are drawbacks, utilizing Fuzzy Matching benefits companies more rather than creating challenges. So how can you implement it into your solutions? Let’s take a look at that next!
Implementing Fuzzy Matching
You can implement Fuzzy Matching algorithms using various programming languages including:
- Python – Fuzzywuzzy Python library applies the Levenshtein Distance approach to perform approximate string matching.
- Java – It’s very difficult to implement FM in Java, however, it is done through a GitHub repository to implement the Fuzzywuzzy library in Java.
- Excel – Easy implementation of FM via add-ons such as Exis Echo, Fuzzy Lookup and even using the native VLOOKUP function.
Of course, building your own solutions to find approximate string matches is possible, but it takes time and requires resources. Often it is better to acquire a solution that uses Fuzzy Matching algorithms to support your business case.
If you are curious about how we at Klippa use Fuzzy Matching in our solutions, then keep on reading!
How does Klippa use Fuzzy Matching?
Many OCR software like Klippa DocHorizon primarily focuses on finding an exact match in data fields for data extraction. However, not every OCR software can always find exact matches when extracting data due to various reasons such as the use of abbreviations, shortened words, etc. This is why it is important to use Fuzzy Matching to make sure that relevant data can be extracted from documents.
In this regard, Klippa uses the Levenshtein Distance to find approximate matches and ensure that all relevant data is extracted. Once the data extraction is completed, the data output is provided in JSON format with a match score. With the match score, Klippa’s clients can determine if they need to have a person verify the results to avoid getting inaccurate results.
In addition to data extraction, Klippa uses Fuzzy Matching to eliminate duplicate data from data sets to train OCR models. This way, the training process is more efficient and brings better improvement results as no time is wasted and chances for false positives (in data extraction & recognition results) are reduced.
Are you interested in finding Fuzzy Matches to improve your organization’s data extraction or data management? Feel free to schedule a demo via the form below to see how our solution works with Fuzzy Matching. In case you want to have a consultation or want to get more information, contact one of our experts.