Over the years, you may have collected tens of thousands, or even as much as a hundred million documents in your archive. You might not be aware of what is actually in there, so it’s important to find a way of discovering and navigating exactly what files you have in your archive.
What’s more, you might actually have archived privacy-sensitive data that you’re not allowed to store according to the most recent GDPR guidelines. So you might actually be breaking the rules without knowing it, but is there a good way of finding out if you are?
Although your archive probably isn’t the most interesting part of your business, it is important to make sure you are aware of what you have in there. Fortunately, we live in the times of intelligent archiving, which can help you navigate your archive efficiently by labeling and classifying your archive, and become more compliant with privacy-related regulations.
In this blog, we’ll explore how you can quickly and effectively organize your archive through labeling and making it GDPR compliant through anonymizing.
Three use cases for intelligent archiving
A well-organised archive can be a vast source of knowledge for your business, so it is important to know what is in your archive and how to find it once you need it. If you are reading this blog, you’ve probably discovered that you’re not entirely aware of what is in your archive, you’re looking to find a way of efficiently organizing your archive or you need a solution for compliancy issues. Questions arise:
- “Do we have information about this subject in our archive?”
- “I need a document containing this information, but how do I find it?”
- “Am I even allowed to have these documents in my archive?”
So you may have an enormous backlog of unorganized information at your fingertips, but aren’t able to use any of it. It is possible that you have a corporate archive or a personal archive, and that you have it filed in a DMS, a cloud service, or a paper archive. There are three major ways to solve this problem. Let’s have a look at what you can do to solve these issues with the help of intelligent archiving.

1. How to make your archive searchable
If you don’t have exact knowledge on what files you have in your archive, the first step to intelligent archiving is quickly and effectively identifying every single stored document. You can think about document types such as PDFs, Word documents, Excel sheets, emails, images, scans or any other type.
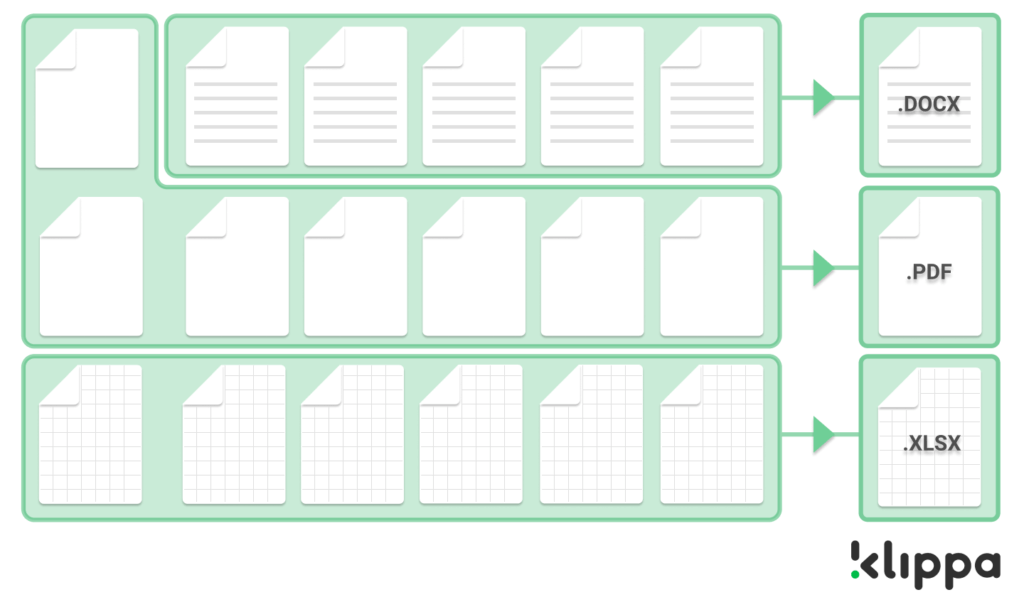
Extracting text from non-text files
Files containing digital text already possess the qualities of being searchable. So if you only have text-based PDFs, Word documents, Excel sheets or TXT-files, you might already be able to navigate the files with a search bar. This is useful if you quickly need to find all the files containing a particular search term or topic.
However, many corporate archives contain scans of documents and other image-types. The text in these documents hasn’t been digitized yet. An excellent solution to making such files searchable is by automatically extracting the text in them using Optical Character Recognition (OCR) technology. Klippa’s OCR API is a great solution for this purpose.
With the help of OCR, Klippa’s API is able to automatically detect pixels containing textual characters in image files. It can do this accurately and reliably for a limitless amount of files. That means that no matter how many non-text files you have in your database, the API can extract the text fully automatically and quickly. You can then have, for instance, PDF/a files, which are both searchable and GDPR compliant. So you don’t need a huge back office to run through all the files in your archive. Pretty nifty, right?
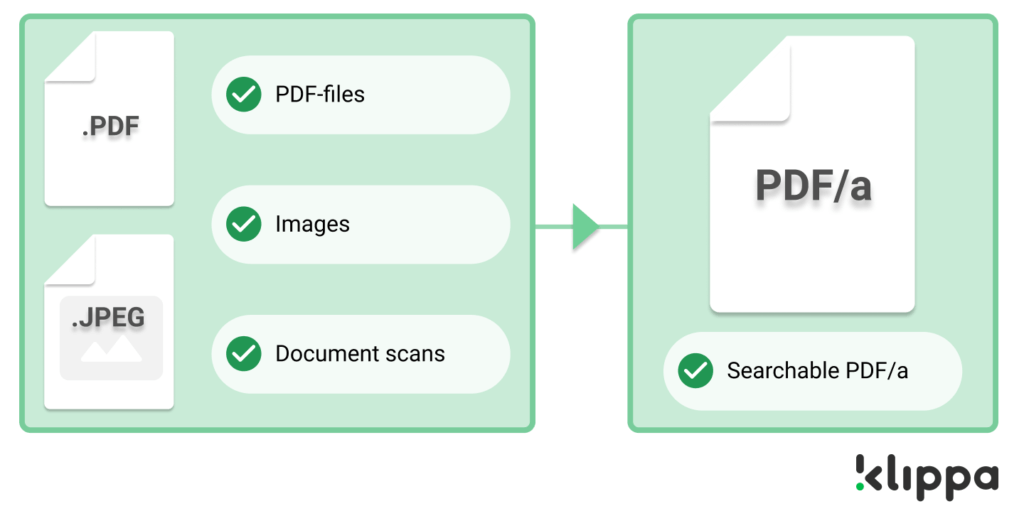
Using your searchable archive
The searchable archive is now at your fingertips. Now you can determine what to do with the documents moving into the future. Do you still need all those files? Can you delete them? What is a smart way of finding documents with specific characteristics? These are all questions related to the follow-up process. It is particularly useful to identify the following purposes:
- Identify which files you don’t need, to clean up your archive or remove privacy-sensitive information.
- Identify which files to keep and labeling them, so that you can easily access the specified and grouped information you need.
- Identify which documents contain useful client or market information, which you can use to set up a business strategy.
- Identify which documents contain sensitive information, so you can make sure you fully comply with privacy regulations by anonymising or removing them.
These are just some examples of what you can do with your archive once you’ve made it searchable.

2. Labeling and classification of your archive
Once your archive is searchable, you may need it to be neatly grouped and classified in order to improve your overview, easily transfer groups of files in your database to someone who needs them, or to make sure certain files are restricted for specific colleagues.
It is important to first define the characteristics with which you would like to group your files. You can think of the following labeling context:
- Document types: .pdf, .docx, .xml, .xlsx
- Document characteristics: identity documents, emails, invoices, receipts, application forms, contact forms, balance sheets, client photos, etc.
- Document groups: financial documents, client documents, HR documents, legal documents, etc.
- Document numbers or codes
- Documents containing specific (GDPR related) information: names and addresses, contact details, client specific information, location details, etc.
Establishing the parameters is an important step before you start with the actual labeling. This way you can keep your labels nice and limited, and don’t start inventing labels on the fly. It will prevent you from losing your overview and logic on the go.
Once you’ve chosen your parameters, you can start labeling and classifying your searchable archive. Of course, you always have the option of labeling manually. But this would quickly become unmanageable and subject to error. Luckily it is also possible to apply OCR and AI algorithms from Klippa to automatically identify and label/ classify documents.
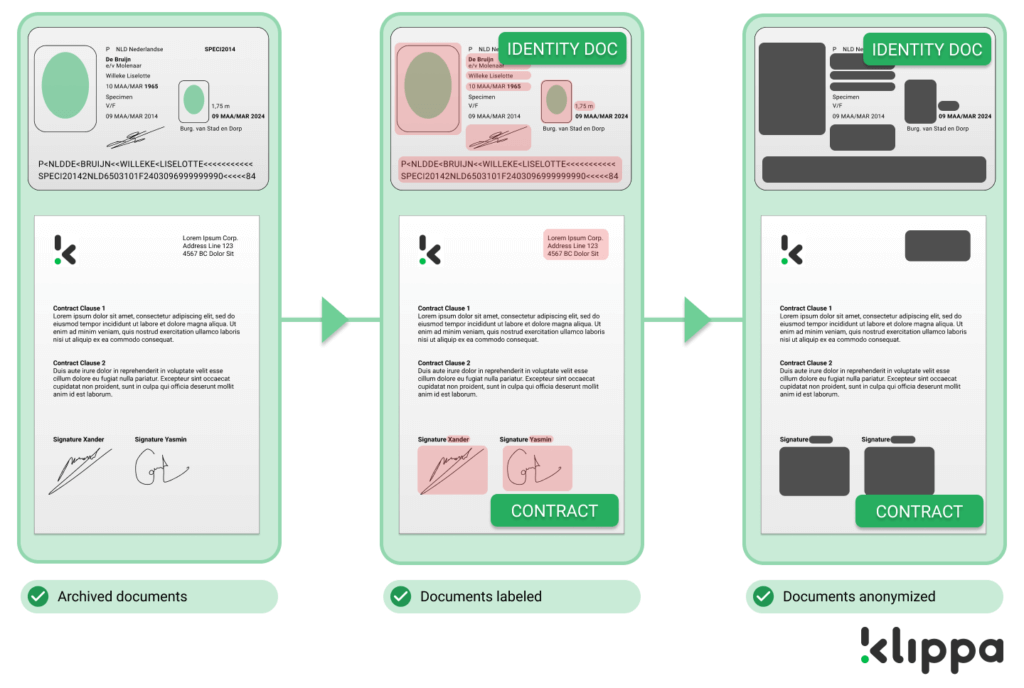
A document containing specified information can be automatically labeled with the parameter of your choice. So for example, any document can be labeled with the corresponding case number, all passports can be labeled as ‘Identity documents’ or could even be anonymized or removed.
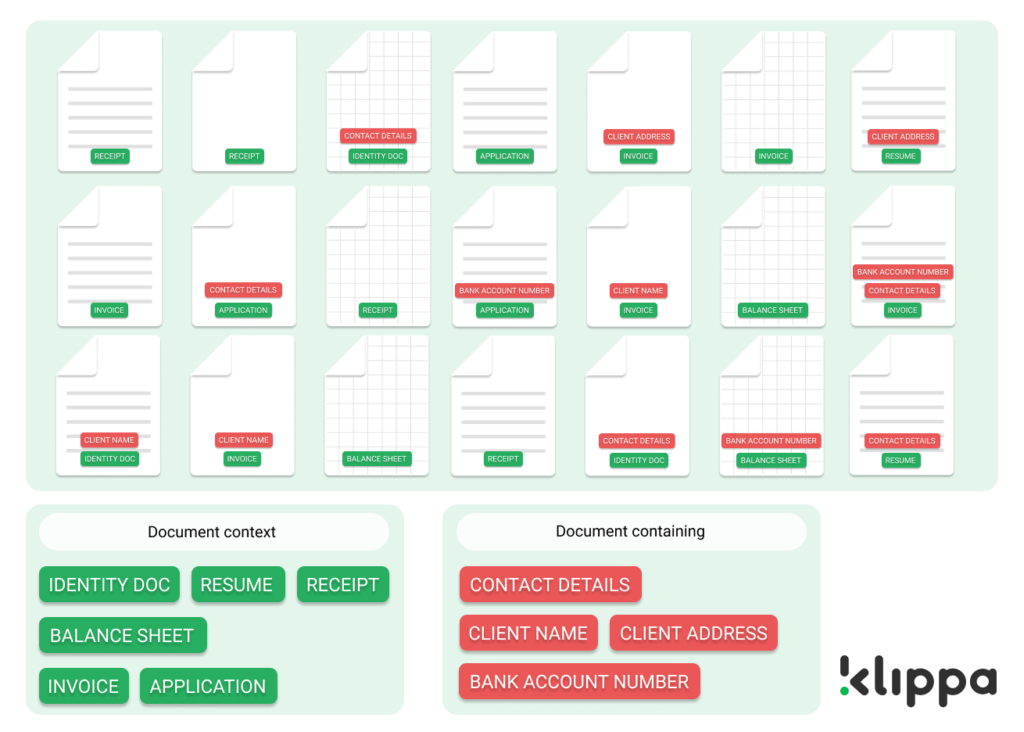
Navigating labeled groups is much less cumbersome than scouring millions of files with merely the search bar. If you have a digital archive that can be accessed by hundreds of employees in your archive, you can make sure to limit access to specific groups of files. What’s more, you immediately gain insight into how many files you possess in a particular group and you can determine what your next course of action for the documents is. So you’ll be able to quickly access and grab a document from the archive and you use it for your particular intents and purposes, for instance in a different system.

3. Identifying and anonymising privacy-sensitive data in your archive
An important purpose of having the documents in your archive identified and labeled is your compliance with GDPR- or other privacy-related regulations. If you are not aware of any private data you have stored in your database, you might face severe consequences once your security is breached. Not only can this allow cybercriminals to distribute information that is not yours to share, it also results in private client data being compromised, potential fines, and eventually bad press for your business.
So the obvious solution is detecting the presence of privacy-sensitive data in your archive and either removing or anonymizing such documents. With the help of Klippa’s OCR API, you can automatically detect specific combinations of names, addresses, bank account numbers, or other private information and have it anonymized by removing those specific lines on a document or deleting the documents entirely.
You have the option of automatically extracting specific lines of information from the documents before you choose to delete them. This makes sure no valuable client information is lost that might be needed for compliance, research or marketing purposes.
An alternative to deleting files is to have them automatically anonymized or pseudonymized. This allows you to keep your files without losing such a significant chunk of your database. This way you have all the data you need as well as comply with the GDPR regulations.
The benefits of the intelligent archive
There are a lot of benefits to be distinguished from the intelligent archive, especially when you decide to have your archive automatically labeled and anonymized by Klippa. We have named most of them above, but for all intents and purposes we’ll shortly list them below.
- Awareness of your archive
First and foremost, you’re aware of what is actually in your archive. This may give you a huge advantage, as you may discover valuable information you didn’t know you had in the first place.
- Searchable archive at your disposal
You can quickly find the files you need or simply discover whether you have any files with a certain topic or with a specific context. You can think of search terms for the text in documents, or finding documents with specific codes or labels.
- GDPR-compliant
Compliance with the regulations in your geographical area or globally is an important aim for all businesses. With intelligent archiving and data anonymization, you’ll be guaranteed to play according to the rules.
- Keep valuable data stored
By anonymizing the privacy-sensitive data in your archive, you’ll be sure to keep the valuable data surrounding that information safely stored for future reference.
- No back office required
You don’t need a huge group of employees to scour your archive and find out what is in there. The necessity for a large back office or back office outsourcing is usually there for many companies when confronted with such a large-scale task. But with automation, you can have all of this performed by an AI.
- Cost and time saving process
Not having to apply a back office and valuable time in identifying and anonymising thousands of files in your archive will result in saving costs. Applying an AI, that can work around the clock, is near 100% accurate and works incredibly quickly will eventually outweigh the costs spent on back office employees.
So now you’ve seen what you can gain from a smart and compliant archive, perhaps you might be interested to learn how Klippa can help you achieve it.
Archiving with Klippa
Do you have an archive that is in thorough need of organizing? You have no clue what’s in it? Is your archive GDPR compliant? Well, it may be high time to contact Klippa to see how we can solve your archiving challenges. Contact Klippa via [email protected] or schedule a demo with one of our experts below.