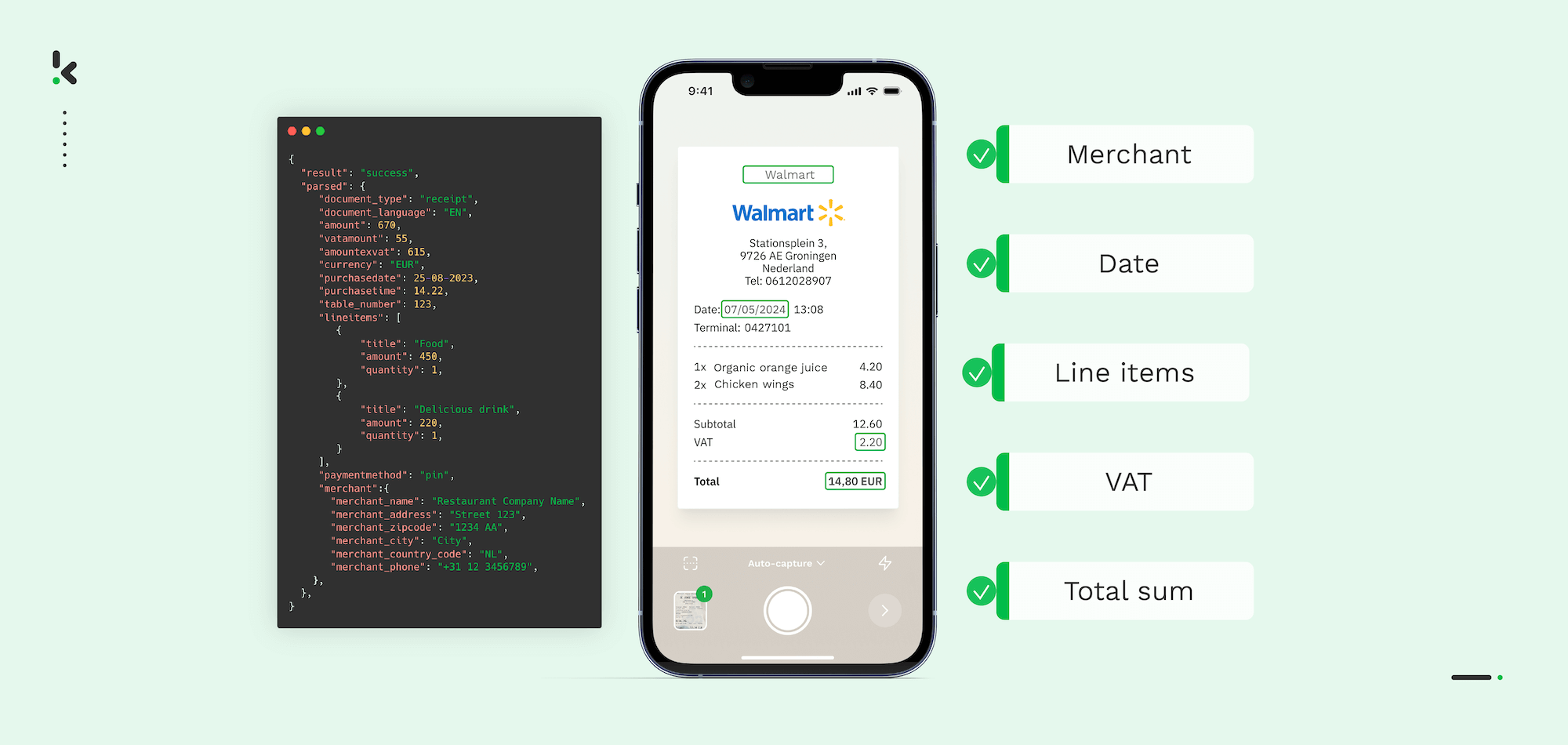
Even though Optical Character Recognition (OCR) has been advancing greatly over the last couple of years, it is still not and will never be perfect. In particular, the accuracy rate of most OCR solutions is not able to reach 100%.
In order for the OCR solution to produce accurate results, the quality of the source image is one of the most important variables. The problem is that the input image quality sent to the OCR engine is often not at the optimal level for the OCR accuracy to be high. This could be due to poor picture-taking practices or conditions, such as a shaky camera or poor lighting.
With this blog, we want to help you avoid common data capture mistakes. First, we provide a quick recap about how OCR works, explain how OCR accuracy is defined, and show examples of incorrect image capture. Then, we clarify how the accuracy rate of OCR can be improved.
Let’s jump right in.
Key Takeaways
- OCR technology is highly advanced, but it’s still imperfect and cannot guarantee 100% accuracy, especially when the quality of the input image is poor.
- There are several effective ways to improve OCR accuracy. It’s important to capture images in controlled environments, to implement real-time user feedback, and to use visual aids like bounding boxes.
- Klippa’s Document Scanning SDK ensures high OCR performance, including real-time guidance, automatic image capturing, smart cropping, lighting adjustments, and support for multiple documents.
- Thanks to machine learning and AI, Klippa’s OCR solution is continuously improved and doesn’t rely on fixed templates, allowing it to adapt to different document types and customer-specific needs with high precision
Quick Recap: How Does OCR Work?
Over the last couple of years, an increasing number of companies have been making use of OCR-powered software to automate workflows and processes. Since OCR can recognize text, extract the information, and convert it into machine-readable data, manual data extraction and entry is not necessary anymore.
But how does this work? OCR is able to convert an image into text by looking at each individual shape of a character and converting it into the closest matching letter. As a next step, information is extracted and stored in a company’s database. Then, the data is ready to be used for following business processes.
In general, image-to-text conversion enables businesses to access and find information quicker as it is made searchable.
Unfortunately, one of the greatest challenges for an OCR engine is to read out information and extract data accurately. In order for the OCR engine to give us accurate data, we can help it a little.
But what do we mean by accurate data? To have us all on the same page, we will quickly define OCR accuracy below.
Defining OCR Accuracy
There are two ways to define reliable OCR:
- Accuracy on a character level
- Accuracy on a word level
Accuracy on a character level
Most of the time, the accuracy of an OCR engine is defined by the character level. How accurate an OCR is measured based on how often a character is recognized correctly and how often a character is recognized incorrectly.
Theoretically, measuring OCR accuracy is quite easy. You simply compare the output of the OCR run with the original text. Then, you can either count how many characters the OCR got right (character-level accuracy) or how many words the OCR detected correctly (word-level accuracy). That makes sense, right?
Accuracy on a word level
To improve word-level accuracy, OCR engines make use of additional knowledge like a dictionary or a library of words. That way, an uncertain word can be “fixed” to a word with the highest similarity. Now, that doesn’t mean that the OCR got the word right.
That’s why it is so important to provide the OCR engine with the highest image quality possible. Are you wondering if your image quality is high enough? Let’s have a look at some examples that illustrate different picture-taking conditions.
Examples of Low OCR Accuracy
As promised, we want to help you avoid common data capture mistakes. That’s why we added the following examples below:
Example 1
In a fast-paced environment, it can be tempting to take a picture of the label as quickly as possible (e.g., while walking up the stairs). Unfortunately, this can quickly lead to poor-quality images, which makes it difficult for OCR to extract data accurately.
Alternatively, the package should be placed on a flat surface to take a qualitative picture, which helps the OCR engine to perform well.


Example 2
We all know it: once thrown into a bag or pocket, a receipt is folded in weird shapes and forms. If you then want to take a picture of it, it is very likely that OCR is not able to read out information accurately.
Instead, it is advisable to straighten the receipt as much as possible, place it on a table, and then capture the image. The OCR output will be much more accurate.


With these examples in the back of our minds, we want to discuss four different ways in which OCR accuracy can be improved.
Ways to Improve OCR Accuracy
Let’s take a logistics company as an example. Often, the staff experiences a very fast-paced environment in which taking high-quality images is a challenge. Employees aren’t able to focus on the quality of the image as they need to take a picture quickly and on the go.
This results in challenges for OCR to recognize the text and read out the necessary information. Inaccurate data output is the consequence, making it extremely difficult to use the information in further business processes. In the worst-case scenario, businesses can lose a lot of money as a result of inaccurate data.
However, there are different ways to improve OCR accuracy without much additional effort for employees. These ways are:
- Improved quality of source image
- Pictures taken in a “controlled” environment
- Real-time user feedback
- OCR solution that draws ‘bounding boxes” to indicate data capture area
Let’s have a look at every point individually.
1. Improved quality of source image
This one is quite obvious. If the quality of the original source image is improved, then the accuracy rate of OCR will significantly increase. You might ask yourself how you know if the image quality is high enough.
This is quite easy to test. If the human eye is able to see the source image clearly, then it is possible to achieve good OCR results. A good indicator would be the character’s height. It is advisable to not let the character height drop below 20 pixels, as otherwise, it becomes difficult to recognize words and characters.
Just keep in mind that the higher the quality of the original image, the easier it is to distinguish characters from the background, and therefore, the higher the accuracy becomes.
2. Pictures taken in a “controlled” environment
Another way to improve OCR accuracy is to take the picture in a “controlled” environment. This means it is important to, e.g., avoid too dark conditions (like a picture taken in a dark room or outside at night) and uneven surfaces. Also, a very cluttered environment and a similar color to the background and image can lead to challenges and a low accuracy rate.
Instead, it makes sense to take a picture of a document on an even surface, like a delivery note on the ground of a warehouse.


3. Real-time user feedback
To ensure employees can take a high-quality picture and thus achieve high OCR accuracy, it is advisable to make use of an OCR-driven solution that makes use of real-time user feedback.
With real-time user feedback, users get notified right away when the picture-taking conditions are not good enough and have the chance to retake the picture. On top of that, the real-time feedback guides the user through the picture-taking process, making sure to keep errors to a minimum.
This user feedback may look like this: “Move closer to the document”, “Too much movement,” or “Conditions too dark”.
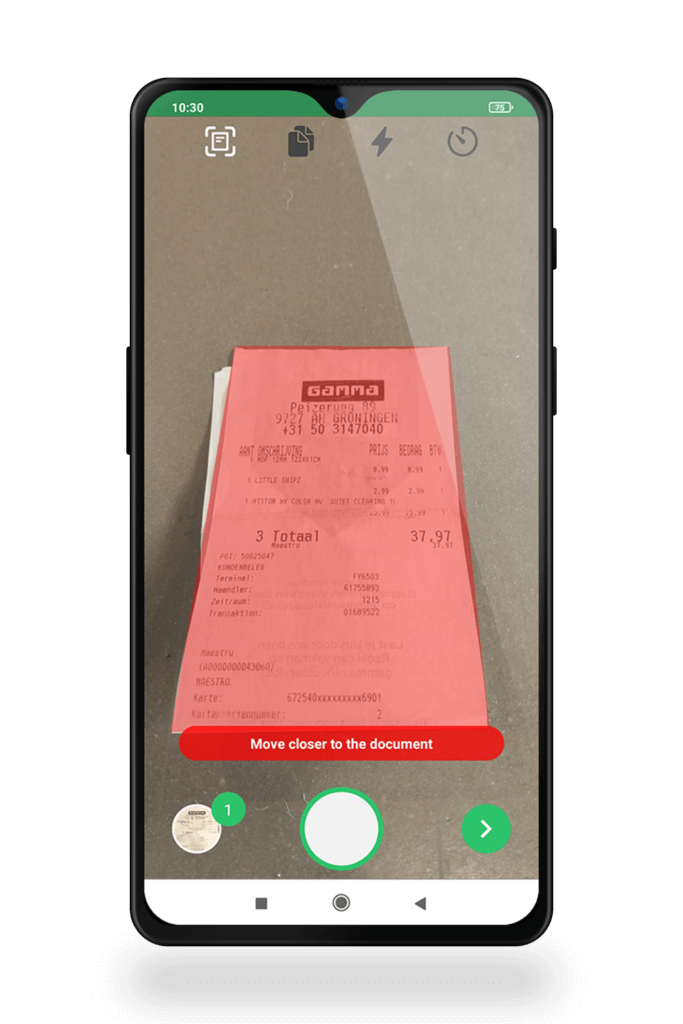
4. OCR solution that draws “bounding boxes” to indicate data capture area
Some OCR software, like the Klippa Document Scanning SDK, draw “bounding boxes” to which the document should be adjusted. This ensures the right image-taking angle and distance.
Once the picture is taken, the OCR engine automatically looks for errors and corrects problems. This could, for example, mean de-skewing a picture (the picture is straightened and angles corrected) or reducing the noise of an image by adjusting the pixels’ intensity value to the surrounding pixels’ average values to enhance the image quality.
Generally speaking, when the text of the image is extracted with the help of Natural Language Processing (NLP), the data extraction accuracy can be improved even further. This is called post-processing of the output, in which the extracted data is compared against a library of characters. Grammar checks are conducted, and contextual considerations are completed to achieve the most optimal result.
Would you like to work with an OCR solution that can offer you all of the above? Well, with Klippa, that’s possible. Let us convince you of our solution by showing you what we offer.
Klippa as a Reliable and Accurate OCR Solution
Klippa’s solution doesn’t only offer real-time user feedback and helpful “bounding boxes” that indicate the image size. With our camera SDK, employees can scan images and take pictures on the go. In general, using an SDK has a great advantage in this case, as it can be easily integrated into your own application.
Our Document Scanning SDK offers seven functionalities that make achieving high OCR accuracy a lot easier. These functionalities are:
- Real-time user feedback → Our SDK gives real-time feedback to guide users when taking a picture, e.g., “Move closer to the document”, “Hold the camera still,” and “Conditions too dark”.
- Auto capturing → Auto capturing makes scanning documents a lot easier. Users don’t have to press the button to capture an image. They can simply place the document in front of the camera, and the Klippa SDK will automatically recognize the document and take the picture for you.
- Cropping → Our scanning SDK will recognize the borders of the document and crop it automatically. Thanks to that feature, the process of getting a clean and high-quality image becomes much more convenient. On top of that, manual cropping is also possible to crop the image to your preference.
- Lighting adjustment → If a user is in a dark environment and has no proper light source nearby, users can turn on the flash via flash control. This will help you get the clearest image possible.
- Image enhancement → The quality of the document is enhanced by our camera SDK’s image processing features to ensure the best picture quality possible.
- Single and multiple document scanning → It is possible to quickly scan multiple documents and group them together to ensure a quick and efficient process.
- Anonymization → In order to comply with GDPR, some information is not allowed to be stored in databases. Therefore, we offer the possibility to mask data automatically.
In the video, you can see how these seven functionalities look in action.
On top of that, to maximize your company’s success, we can develop customized solutions. Because we make use of Machine Learning and AI, we are not dependent on templates. That enables OCR to produce an output with higher accuracy. It also means that we can train our OCR to read any document you need.
In addition, because of the use of Machine Learning and Artificial Intelligence (AI), we can constantly train our solution so that we can accommodate your needs from the get-go.
As you can see, with Klippa’s packed image enhancement features, it is easy to receive reliable and accurate OCR output. Do you also want to ensure that your employees can work with a reliable and accurate OCR solution?
Let us show you what we can do for you. Simply book a free demo below or contact one of our experts.
FAQ
OCR accuracy refers to how well the software recognizes and converts text from images into machine-readable data. It’s typically measured by the percentage of correctly identified characters (character-level) or words (word-level).
Low lighting, blurry or skewed images, crumpled or folded documents, and cluttered backgrounds all negatively impact OCR accuracy. Even unusual fonts or handwritten text can make recognition harder.
Klippa offers high OCR accuracy thanks to features like image enhancement, real-time feedback, and post-processing with Natural Language Processing (NLP). Accuracy is further improved through machine learning that adapts to document variations.
Yes. Klippa’s mobile SDK includes real-time guidance, auto-capture, and enhancement features to help users scan documents accurately on the go—ideal for field workers or fast-paced environments.