Organizing information is a key task for companies aiming to improve their data management. To do so, they focus on extracting key-value pairs from various types of documents, depending on their industry. The key-value pairing synthesizes the most important information from documents, allowing businesses to efficiently store and retrieve it.
A solution that appeals more and more to businesses when it comes to facilitating data processing is the use of OCR technology. Automating data extraction gives businesses the ability to swiftly gain access to key-value pairs, therefore streamlining the information extraction process.
In case you have not yet heard of key-value pair extraction or you’d like to know more about it, keep reading. In this blog, you will get familiar with the term key-value pair and will get the chance to see how automating this process can bring your business great benefits. Let’s start!
What is a Key-Value Pair?
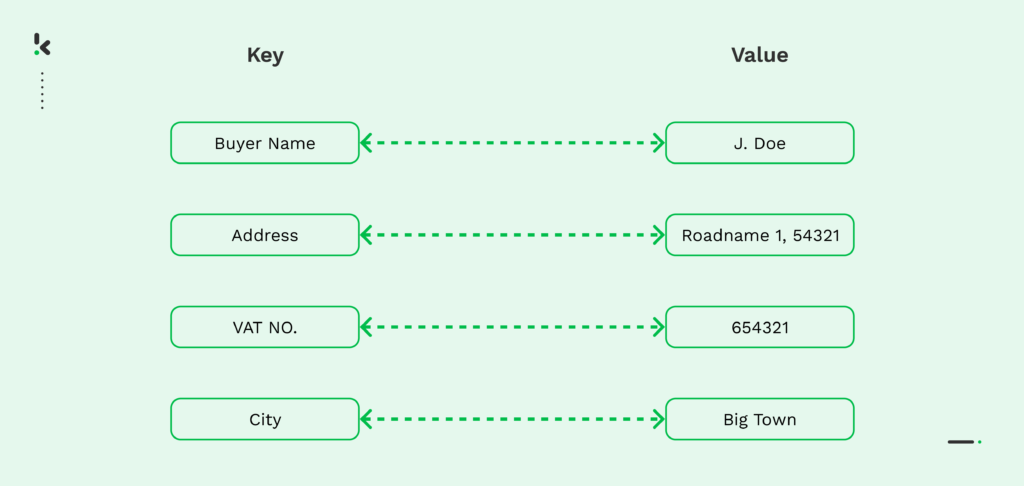
A key-value pair is a central data representation, consisting of two data items, a key and a value. The key is a unique identifier, for instance a predefined field, while the value is always unique, corresponding to the key at all times.
An accurate example can be found in the example below. In this case, the key is “Name” and the value is “Doe Jane”.

Key-value pairs are present in a multitude of documents, from identity documents to invoices and even bank statements. Let’s delve deeper into the topic and see how key-value pair extraction is used for various document types, using smart document processing software, such as OCR.
Key-Value Pair Extraction In Various Document Types
Depending on your industry, your business may use certain documents more frequently than others. Regardless, the key-value pairs are still the most important data fields extracted and used in daily business transactions.
Invoices
Collecting data from invoices and manually entering it into spreadsheets can be challenging and error-prone. The automated key-value pair extraction directly captures information from scanned images or documents, therefore reducing processing times. Some of the most processed keys in invoices are:
- Invoice number
- Invoicing Date
- Vendor name
- Total amounts
- Tax and VAT
Receipts
Receipts are some of the most widespread documents. Whether they are used for loyalty programs and cashback campaigns or business expense reimbursements, businesses process large amounts of receipts daily. Receipts hold important key-value pairs, mostly used to check the authenticity of the document:
- Retailer name
- Purchase date
- Total amount
- Separate line items
- Taxes and VAT
Identity Documents
Identity documents contain the most key-value pairs, and rank high in importance for both individuals and organizations. For example, companies need to extract and process essential key-value pairs for KYC checks or identity proofing, processes which are at the backbone of every business. The key-value pairs often encountered in identity documents are:
- Name and surname
- Date of birth
- Issuing authority
- Country of issue
- Social security number
- Document number
Bank Statements
Companies, as well as public institutions, process bank statements regularly. Some of the instances where organizations need to extract and process key-value pairs from bank statements are employee onboarding, automating accounts payable, as well as performing a credit card risk assessment.
Retrieving sensitive data from these documents manually is not only a repetitive and redundant task, but also error-prone. Automated key-value pair extraction ensures the captured information is correct, reducing the chance of mistakes in business operations to occur. The most important key-value pairs from bank statements are:
- Bank name
- Total amounts
- Date of transactions
- Transaction overview
- Document number
Challenges of Manual Key-Value Pair Extraction
As mentioned before, most documents come in unstructured formats. This makes data extraction set to be more difficult than planned, especially if it’s done manually. While manual key-value pair extraction does the job, it comes with certain limitations:
- Inability to process high volumes of documents: Reading and extracting key-value pairs from a large amount of documents in one sitting can be rather overwhelming. Processing only one document at a time affects the efficiency of a business, doing more damage than good in the long run.
- Lack of accuracy: Manual extraction of key-value pairs, which oftentimes consists of sensitive data, can lead to errors in data processing. A single mistake can occur and the accuracy of the extracted information is compromised.
- Slow processing times: Going through multiple documents at once, identifying the key-value pairs and extracting them, all while making sure the data is correct, can take up a large amount of time. This inefficiency can lead to longer processing times, which slows down daily tasks for all businesses.
- Lack of formatting: When dealing with unstructured documents, which is the case with most businesses, the formatting of a document poses a big problem. Since keys and values do not have the same structure, they cannot be used for further data analysis.
To avoid slow processing times and having to double check the extracted key-value pairs for errors, companies choose to automate this process. There are multiple technologies available to automate key-value pair extraction, so every organization has the freedom to choose the most suitable option for their business.
Technologies for Key-Value Pair Extraction
Thanks to the development of intelligent document processing solutions, businesses are offered a great variety of options they can use to automate data extraction. In this section, you will get acquainted with some of the most frequented technologies, such as Optical Character Recognition, Object Detection and Named Entity Recognition.
OCR

Optical character recognition, also known as OCR, is an IDP solution that swiftly extracts key-value pairs from both structured and unstructured documents. It reads the document, extracts the data and converts it into machine readable format, preparing it for further processing, depending on your use case.
However, most OCR solutions are unable to read and extract handwriting from documents. For instance, if the key is represented by a bounding box within a digital document, and the value is an individual’s personal information in handwritten format, the average OCR cannot accurately extract the key-value pair. This is where ICR comes into play.
Intelligent character recognition, or simply ICR, is an improved version of the standard OCR technology. Its ability to accurately identify and extract handwritten text and characters, using AI and ML technologies, makes key-value pair extraction possible for a variety of documents.
Object Detection
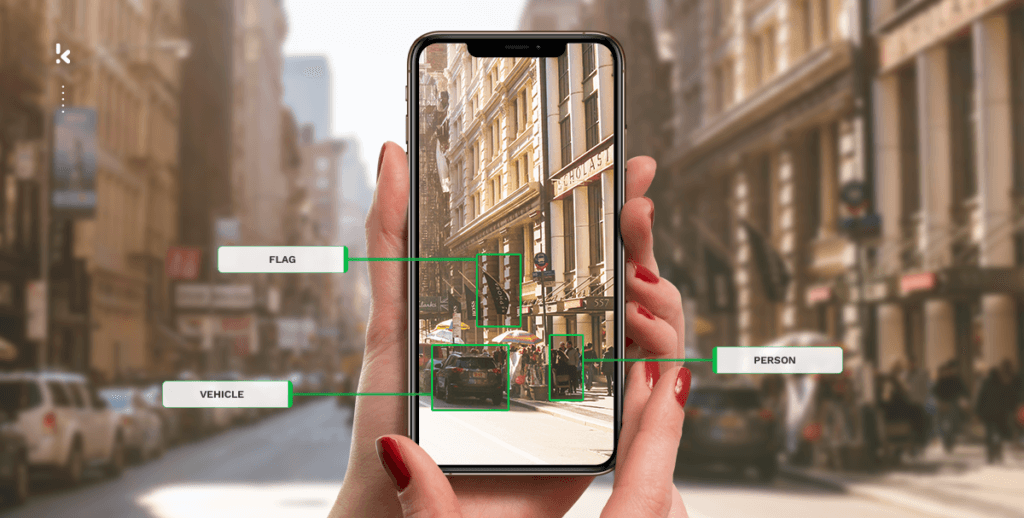
Object detection is a neural network, used in detecting objects and text from images and scanned documents. It uses computer vision technologies to locate objects and text, drawing bounding boxes around the entities of interest. The neural networks automatically interpret the document layout and location of the targeted entities.
While object detection is very good at detecting addresses, company names, locations and other text entities within visual depictions, its precision rate is only at 65%.
Named Entity Recognition
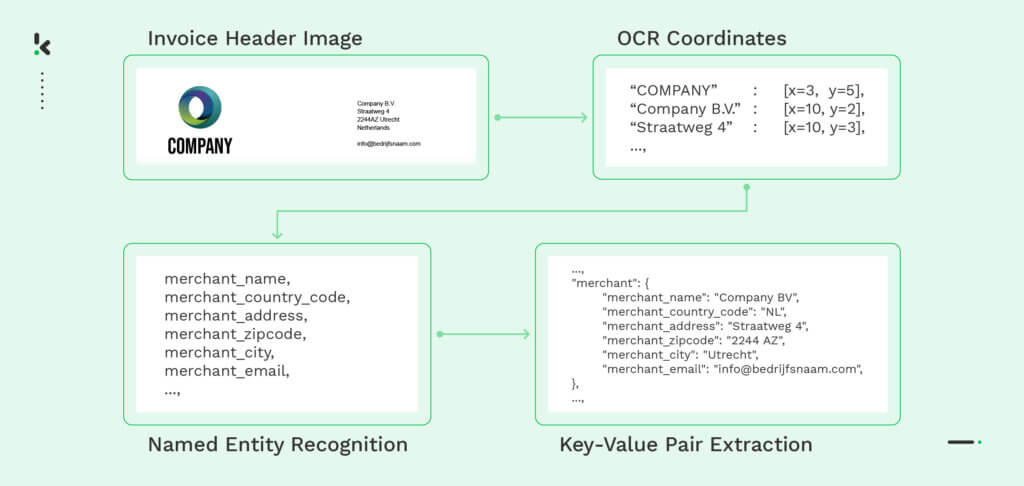
Named entity recognition is a natural language processing technique, used to locate and extract entities, (i.e. parts of speech), in text-based documents. NER categorizes the extracted entities into predefined categories, such as “name”, “number”, “address” and so on. This comes in handy in key-value pair extraction, as it is able to process both structured and unstructured documents.
There are several approaches to using the named entity recognition technology:
- Classical approach (rule-based): In this method, a predetermined set of rules is used for information extraction. These rules can be pattern-based, using the morphological pattern of the words, or context-based, using the context of the given word in the document.
- Machine learning approach: This approach is statistical-based, and involves two main steps. The first step is to gather the files used for training the model and annotating the data from them. Only then, the NER model can start training. The second step lets the trained model annotate raw documents on its own. Machine learning approach uses multi-class classification or conditional random field (CRF).
- Deep learning approach: The DL approach is the most accurate one. It is capable of understanding semantic and syntactic relationships between words in a given text, but also of analyzing topic-specific words. This method can make use of either bidirectional LSTM-CRF, bidirectional LSTM-CNNs, bidirectional LSTM-CNN-CRF or pre-trained language models, such as BERT or Elmo.
- Hybrid approach: The hybrid approach combines both machine learning and deep learning approaches, in order to enhance the quality of the key-value pair extraction output.
The variety of available technologies for automating key-value pair extraction can quickly become overwhelming for companies. While all the options mentioned above are great for extracting a key-value pair, they may lack certain features that could make the extraction process truly efficient and accurate. Klippa DocHorizon however, doesn’t compromise when it comes to the quality of your data extraction processes.
How to Extract Key-Value Pairs with Klippa
Klippa DocHorizon is an intelligent document processing platform, making data extraction a smooth and efficient process. In just four easy steps, your organization is able to automate key-value pair extraction:
- Select the source of input data: Upload your documents in batches via web, email, mobile app, API, FTP or third-party integration. Klippa is also able to be integrated with G-Suite, such as Google Drive.
- Choose which documents you want to process: Depending on the industry of your business, you can choose to process invoices, receipts, bank statements, identity documents and many more. In addition, you can also use our platform to train particular models, in order to process a specific document type, tailored to your needs.
- Define key-value pair fields: Select the data fields you wish to extract. Klippa is able to help you capture and process a variety of key-value pairs, such as names, addresses, total amounts and many more.
- Select output format and location: After key-value pairs are extracted, you can choose the format in which you want to have the data, for instance JSON, XML, CSV, XLSX, UBL, PDF, TXT. Also, you are in total control of the destination of the extracted data. This can be either your database, an ERP system, accounting software, or any other platform depending on your workflow.
Besides helping you streamline data extraction smoothly and efficiently, Klippa can help your business:
- Capture data with an accuracy of up to 99%
- Facilitate document conversion to multiple formats, be it JSON, XML or CSV
- Anonymize documents, ensuring data privacy regulations such as GDPR are met
- Further classify and categorize documents to enhance the efficiency of the key-value pair extraction
- Automate document verification with every processing task to prevent document fraud
- Seamlessly integrate our solution within existing software via API and SDK
- Process documents in 100+ languages, thanks to our global coverage
There is no need to still handle information extraction processes manually. Contact our experts or book a demo down below if you want to benefit from time and cost saving solutions!