Swiftly extracting and processing data is a crucial part of daily operations in organizations today. As they grapple with an influx of information in different formats and layouts, including emails, scans, and images, there is a clear need for automation in document processing.
Luckily, there are Intelligent Document Processing (IDP) solutions that combine Optical Character Recognition (OCR) with AI, Machine Learning, Computer Vision, Large Language Models (LLM), and Natural Language Processing (NLP). These have revolutionized the document processes, making workflows faster, smarter, and more efficient.
In this blog, we will dive deeper into one of these technologies, which is also known as LayoutLM, and their practical uses in workflows.
What is LayoutLM?
LayoutLM is a cutting-edge language model developed by Microsoft, able to comprehend document layout and structure. Unlike traditional models, LayoutLM can interpret both text and visual elements of a document such as tables, images, and paragraphs.
As one of the Large Language Models (LLMs), LayoutLM is a sophisticated AI model trained to understand data in a human-like manner. LayoutLM is particularly successful at performing tasks where both the content and the spatial arrangement (positioning) of information, such as document classification, and information extraction. It essentially combines NLP with layout understanding, providing a comprehensive approach to document comprehension and processing.
LayoutLM in Document Processing
LayoutLM is a standout of the document processing technologies. Its integration of language understanding with spatial awareness revolutionizes document-based workflows. Integral to document-centric processes, LayoutLM excels in deciphering documents with unusual layout structures, in turn transforming how we approach document workflows.
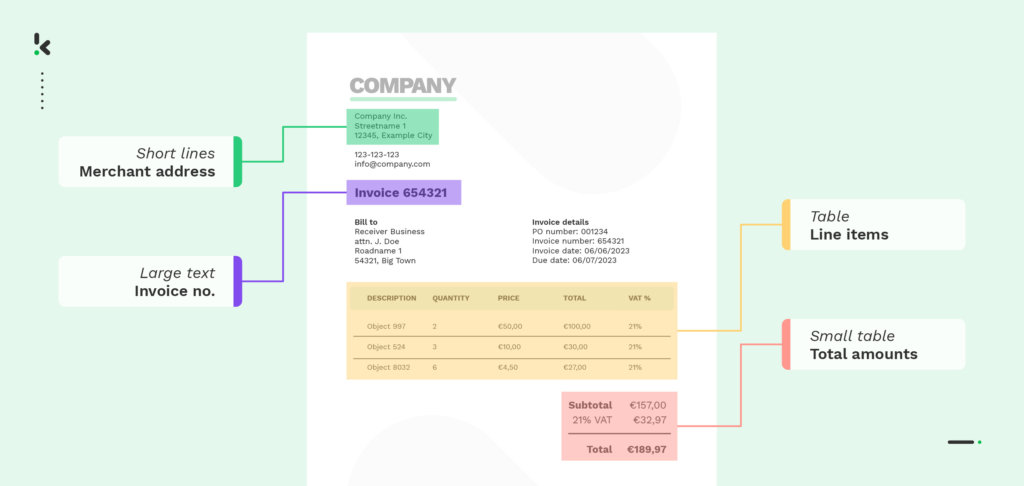
It has the ability to locate and understand where each word sits on a page giving it the ability to find information in documents and images, sort documents into categories, and spot specific details like names or numbers.
Below are some applications of LayoutLM in the document processing game.
Image Understanding
In image understanding, LayoutLM goes beyond the recognition of visual elements and can interpret and comprehend the visual layout of documents and its elements including images, tables, and other graphs. These nuances enhance the model’s overall ability to understand and comprehend a document and its contents providing a more accurate and sophisticated document processing solution.
Document Image Classification
Document Image Classification with LayoutLM involves the automated categorization of entire documents based on their visual and textual content. By combining language understanding and layout recognition, LayoutLM excels in accurately classifying documents into predefined categories. This capability streamlines document organization, retrieval, and management, offering a more prepared solution for industries dealing with diverse document types.
Masked Visual Language Model (MVLM)
MVLM integrates visual information into language models, like LayoutLM, by predicting masked visual tokens alongside masked language tasks during training. This enhances the model’s ability to understand both textual and visual elements in documents, resulting in a more comprehensive approach to document workflows. This innovation significantly enhances the model’s performance in tasks requiring comprehensive document understanding.
Multi-label Document Classification (MDC)
Multi-label Document Classification (MDC) uses LayoutLM document categorization by allowing a document to belong to multiple categories simultaneously. Unlike traditional single-label classification, MDC recognizes the diverse nature of documents, enabling more accurate and flexible classification based on various content aspects.
For instance, a single-label classification in the context of financial documents can be classified documents as “Financial Reports”. A multi-label classification would take the same document, Financial Reports, and include labels like “Income Tax filings,” “Expense Reports,” and “Accounts Payable”.
Text Extraction with OCR
Text Extraction with OCR is one of the fundamental capabilities of LayoutLM. LayoutLM allows accurate text extraction from scanned or image-based documents. It transforms content into machine-readable formats like XML, JSON, or CSV through OCR. This enables businesses and organizations to process and analyze information from a variety of document formats quickly and efficiently.
Why use LayoutLM?
LayoutLM is beneficial to document processing because it seamlessly blends layout and language understanding. Its ability to identify, understand, and distinguish different document structures is crucial to the processing of documents with intricate layouts.
Why is this beneficial? Well, when it comes to extracting and processing data from documents like invoices, contracts, and receipts, the layout of a document and the subtleties of the language can play a crucial role in the models’ ability to understand the document. That being said, it is not limited to any specific structure or layout like some traditional solutions.
LayoutLM examples
LayoutLM for Document Classification (LINK)
LayoutLM can be used to classify documents into predefined categories based on both textual content and document structure. So, suppose you have a collection of legal documents with varying structures. LayoutLM can be used to categorize these documents automatically into relevant classes, such as contracts, agreements, or legal briefs. Overall, this can help you as a business efficiently organize and manage diverse document types.
Here is an example code snippet of LayoutLM.
from transformers import LayoutLMTokenizer, LayoutLMForSequenceClassification
import torch
tokenizer = LayoutLMTokenizer.from_pretrained("microsoft/layoutlm-base-uncased")
model = LayoutLMForSequenceClassification.from_pretrained("microsoft/layoutlm-base-uncased")
words = ["Hello", "world"]
normalized_word_boxes = [637, 773, 693, 782], [698, 773, 733, 782]
token_boxes = []
for word, box in zip(words, normalized_word_boxes):
word_tokens = tokenizer.tokenize(word)
token_boxes.extend([box] * len(word_tokens))
# add bounding boxes of cls + sep tokens
token_boxes = + token_boxes +
encoding = tokenizer(" ".join(words), return_tensors="pt")
input_ids = encoding["input_ids"]
attention_mask = encoding["attention_mask"]
token_type_ids = encoding["token_type_ids"]
bbox = torch.tensor([token_boxes])
sequence_label = torch.tensor([1])
outputs = model(
input_ids=input_ids,
bbox=bbox,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
labels=sequence_label,
)
loss = outputs.loss
logits = outputs.logits
LayoutLM for Text Labeling (LINK)
LayoutLM can be used to label or annotate specific text within documents. The model automatically annotates or labels specific portions of text within a document. Suppose you want to label specific clauses in a legal document. LayoutLM can be applied to automatically identify and label these clauses, taking into account both the content and the visual layout of the text.
Similarly, the LayoutLM can be used by HR professionals to automatically recognize and categorize sections in a resume taking into consideration, the document layout and content.
Here is an example code snippet of LayoutLM.
from transformers import LayoutLMTokenizer, LayoutLMForTokenClassification
import torch
tokenizer = LayoutLMTokenizer.from_pretrained("microsoft/layoutlm-base-uncased")
model = LayoutLMForTokenClassification.from_pretrained("microsoft/layoutlm-base-uncased")
words = ["Hello", "world"]
normalized_word_boxes = [637, 773, 693, 782], [698, 773, 733, 782]
token_boxes = []
for word, box in zip(words, normalized_word_boxes):
word_tokens = tokenizer.tokenize(word)
token_boxes.extend([box] * len(word_tokens))
# add bounding boxes of cls + sep tokens
token_boxes = + token_boxes +
encoding = tokenizer(" ".join(words), return_tensors="pt")
input_ids = encoding["input_ids"]
attention_mask = encoding["attention_mask"]
token_type_ids = encoding["token_type_ids"]
bbox = torch.tensor([token_boxes])
sequence_label = torch.tensor([1, 1, 0, 0]).unsqueeze(0) #batch size of 1
outputs = model(
input_ids=input_ids,
bbox=bbox,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
labels=sequence_label,
)
loss = outputs.loss
logits = outputs.logits
How can businesses apply LayoutLM?
For businesses of all sizes, LayoutLM can bring benefits to different levels of document processing. Here are some of the use cases of LayoutLM that many businesses will likely be confronted with.
- Invoice processing: Easily automate the extraction of important data from invoices, including line items, merchant details, dates, and amounts, to improve the accuracy and efficiency of accounts payable workflows.
- Receipt processing: Streamline the processing and line item extraction from receipts to streamline expense tracking, financial record-keeping, and receipt clearing with reduced manual input.
- Forms processing: Automate the extraction of data from various forms, including surveys or application forms, enhancing workflow efficiency and reducing manual data entry.
- Resume parsing: Improves the recruitment process by automatically extracting and categorizing information from resumes, enabling faster candidate evaluation.
- Contract processing: Easily streamline the examination, review, and categorization of legal documents like contracts. This not only enhances productivity but also ensures accuracy and consistency in legal document processing but also reduces errors and maintains organization throughout.
These are just a few examples of how LayoutLM can be applied in a business. However, there are many more use cases in which LayoutLM can be beneficial for document processing solutions.
Conclusion
Implementing LayoutLM into document-centric workflows can be a powerful way to level up the way you approach processing documents. While some may have the skills, knowledge, time, and resources to build and train their models themselves, not all businesses have the same luxury.
However, there is a more convenient and easy-to-implement solution. Opting for an out-of-the-box solution means you don’t have to invest the resources into building your own solution, as it can get costly and take a lot of time to train the model to deliver good enough results. That is where Doxis AI.dp comes in.
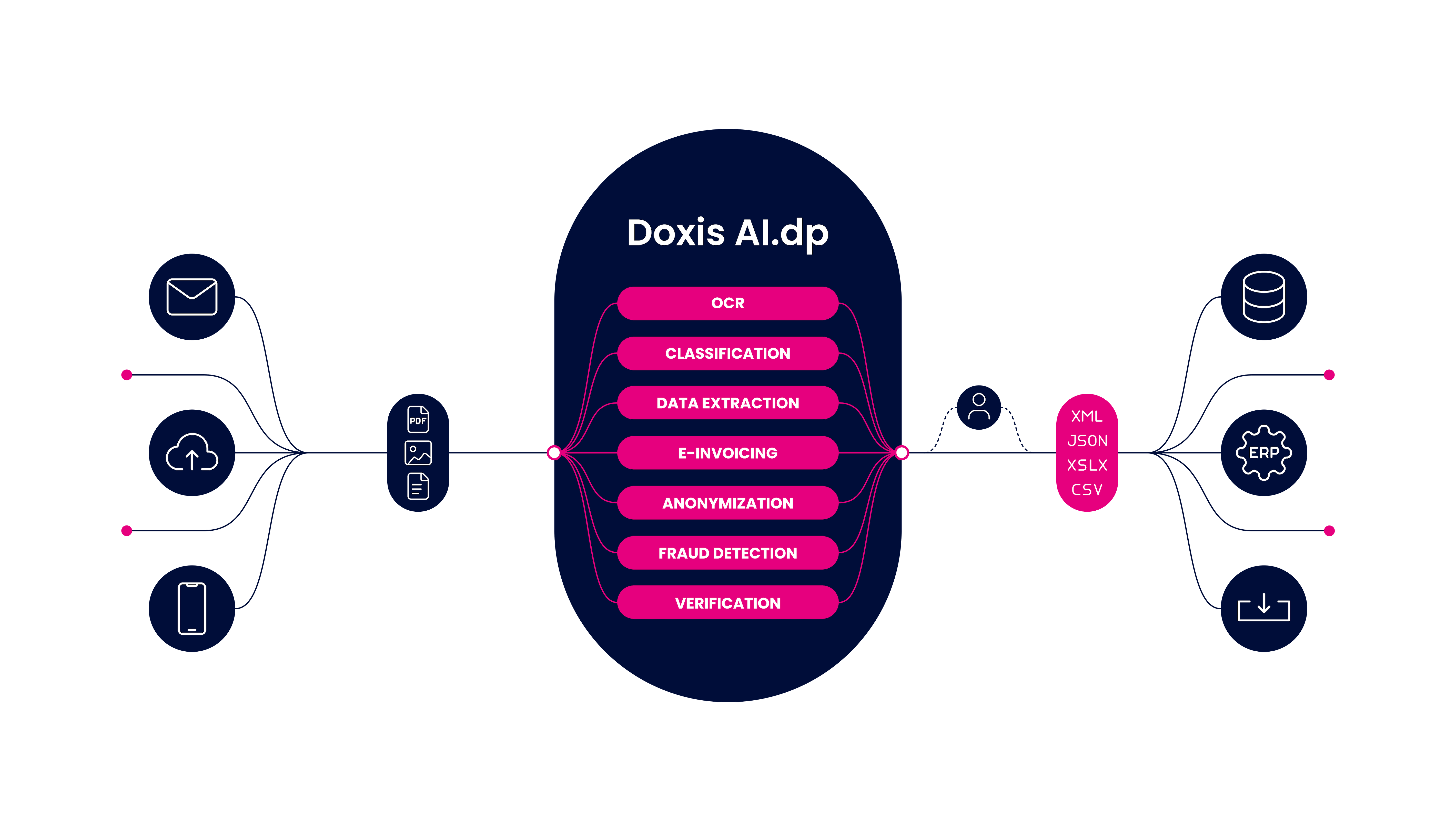
Doxis’ intelligent document processing solution, AI.dp, offers you an AI-powered, out-of-the-box solution that uses large language models similar to LayoutLM and other technologies, including OCR and NLP, to automate any document processing workflows quickly and efficiently. With Doxis AI.dp, you can elevate your business by:
- Automatically Categorize Documents: Organize documents easily and streamline organizational processes to save time and ensure efficient document management.
- Automate Document Management Workflows: With the AI.dp platform, easily set up workflows and automate document-related business processes.
- Precise Content-Location: Speed up document examination with automated location and extraction of features including signatures, logos, and images.
- Document Conversion: Convert documents into several business-ready data formats, such as JSON, TXT, CSV, XML, and many more to suit your needs.
- Customized Processing Modes: Design document workflows with our prompt builder tailored to your needs and specific requirements.
Curious about how Doxis AI.dp can help revolutionize your approach to document processing? Book a demo with us today!