
For a long time now, Optical Character Recognition (OCR) has been the standard method for extracting text from scanned documents. However, with the growing popularity of Large Language Models (LLMs) like Chat-GPT and DeepSeek, companies now face more options for data processing.
LLMs can be easier, cheaper, and commitment-free. But are they the safest, most reliable, and most accurate option for your business and more importantly, the data you process?
Our blog dives into the differences between LLMs, Traditional OCR, and OCR powered by AI, discusses when each should be used, and explains why businesses that process large volumes of documents still depend on dedicated OCR software.
Key Takeaways
OCR Software vs LLMs: Key Differences Table
What is OCR Software, and How Does it Work?
Optical Character Recognition software are out-of-the-box solutions designed to extract text from images, scanned documents, and PDFs, converting them into machine-readable data. It plays a crucial role in document automation, enabling businesses to process invoices, contracts, receipts, and other text-heavy documents without manual data entry.
Not all OCR solutions work the same way. There are two main approaches:
1. Template-Based OCR (Rule-Based OCR)
Template-based OCR uses templates or rules to extract text from specific locations in a document.
- Works best for structured documents that follow a consistent format, like standardized invoices or forms
- Uses predefined templates and field mapping to extract specific data (e.g., invoice numbers, dates, totals)
- Limitations: Struggles with layout variations, new document formats, or handwritten text
2. AI-Powered OCR (Intelligent Document Processing – IDP)
AI-powered OCR (e.g., Tesseract OCR or Klippa OCR) uses machine learning and natural language processing (NLP) to extract data from semi-structured and unstructured documents
- Can adapt to different layouts, languages, and handwriting without predefined templates
- Often includes Human-in-the-Loop (HITL) for verification to ensure accuracy
- Limitations: Typically requires higher processing power and more setup than simple OCR tools
Businesses rely on OCR because it is faster, more scalable, and provides structured outputs with higher accuracy. However, some businesses found that it’s also possible to use LLMs for certain extraction tasks.
What Are LLMs and How Are They Used for OCR?
Large Language Models are AI models trained on extensive amounts of text data. They excel at analyzing and generating text, making them useful for various NLP tasks. While they were not specifically designed for OCR, they do have “OCR-like” capabilities.
Generally, 2 types of LLMs can be used for document data extraction:
1. Text-only LLMs
- Capable of dealing with text-based documents such as Word documents, emails, and PDFs that contain selectable text
- Limitations: Cannot directly process images, scanned or handwritten documents, and documents with complex layouts
2. Multimodal LLMs
- Can extract data from images and scanned documents but are in the early stages of their development and are somewhat uncommon
- Limitations: Few models that support OCR-like vision, may still struggle with accuracy, layout recognition, and structured data extraction
Companies that use LLMs for OCR choose this method because the process feels easier, cheaper upfront, and more flexible. Many businesses already use ChatGPT or similar LLMs for other tasks, so it feels natural to extend its use to document extraction.
How to Extract Data Using an LLM
Depending on the model you use (e.g., text-based or multimodal), once you have your scanned or text-based document, you can use an LLM to extract key information from your file. The process of extracting data from documents using LLMs will generally follow these steps:
1. Formulate a Clear Prompt
LLMs respond to natural language prompts, so writing a well-structured instruction is key. Clarify what data needs to be extracted. Are you pulling invoice details, contract terms, or structured metadata? The more specific you are, the better the results.
It is common for an LLM to struggle to return consistent outputs. Expect that you might have to continuously tweak the prompt or specify expected output formats.
2. Process the Document
You can use an LLM API (such as OpenAI’s GPT API) or a chatbot interface to process the prompt.
For API usage:
- Send a request to the LLM API with your structured prompt
- The LLM analyzes the text and returns extracted data
- The result is usually returned as a structured response
For chatbot interaction:
- Copy and paste the text into the chatbot interface
- Manually copy the results or refine the response if needed
3. Validate and Refine the Output
LLMs may introduce errors or even “hallucinate” incorrect data. Hallucinations refer to instances where the model generates incorrect or completely fabricated information that was not present in the input data. You have to always review and validate extracted information before using it in critical workflows.
4. Export or Integrate Data into a System
Once validated, the extracted data needs to be stored or sent to another system. You can manually copy the LLM output and paste it into a spreadsheet or send data to a database, CRM, or accounting system using an API integration.
Most Popular LLMs for OCR
While LLMs are not designed as primary OCR tools, some multimodal models can extract text from images or scanned PDFs. Below are the leading providers and models that offer OCR-like capabilities:
1. ChatGPT (GPT-4 Turbo with Vision)
GPT-4 Turbo is OpenAI’s most advanced LLM, available via ChatGPT Plus and API access. The Vision-enabled version allows it to process both text and images, making it one of the few commercially available LLMs that can extract text from scanned documents and PDFs.
Pros:
- The vision-enabled version can process text and images
- Works well for text-based data extraction, summarization, and classification
- Available via OpenAI API and Azure OpenAI Service
Cons:
- Not optimized for structured data extraction (e.g., invoices, receipts)
- Using Vision requires additional costs when accessed via OpenAI’s API
- Prone to hallucinations
2. DeepSeek-Vision
DeepSeek-Vision is a multimodal, open-source LLM developed by DeepSeek AI. It offers basic OCR-like capabilities, allowing users to process text and images. Its open-source nature makes it a flexible option for custom implementations.
Pros:
- Open-source, offering more flexibility for custom deployments
- Can process both text and images, extracting text from documents
- Works well for basic OCR tasks, such as reading simple invoices or forms
Cons:
- Experimental compared to commercial models
- Not as widely adopted as OpenAI or Google models
Security Disclaimer: Despite its popularity, the latest research uncovered strict filtering and content bias of DeepSeek AI, in addition to its cybersecurity risks. Businesses handling confidential or legally sensitive data should carefully evaluate security risks before integrating DeepSeek into their workflows.
3. Claude
Claude is developed by Anthropic, focusing on safe and explainable AI. While it does not support image processing, it is highly regarded for structured text analysis. Businesses in legal, financial, and compliance-heavy industries favor Claude due to its controlled outputs and reduced risk of fabricated data.
Pros:
- Known for more reliable, controlled outputs (fewer hallucinations)
- Ideal for processing text-based documents (contracts, legal documents, reports)
- Works well for content summarization and structured extraction
Cons:
- No image processing support
- Limited adoption in enterprise OCR workflows
As you can see, many LLMs include impressive vision and data extraction capabilities. However, after experimenting with document automation using these models, many businesses still switch to OCR software for reliable high-volume extraction. Let’s explore the reasons why.
Limitations of LLMs in Document Data Extraction
While LLMs can be useful for simple OCR tasks, they have significant limitations when a company begins exploring document automation for precise, structured data extraction from documents:
Inability to Process Images without Multimodal Capabilities
LLMs cannot extract text from scanned PDFs or images without integrated vision capabilities that require additional costs. Even multimodal LLMs face challenges with complex layouts, tables, forms, and handwritten text, making them less reliable for OCR tasks, unlike dedicated OCR engines.
Fabrication of Data with Hallucinations
One of the biggest drawbacks of LLMs is that they do not extract text in a traditional sense, instead, they generate outputs based on probabilities. This can lead to various issues:
- Missing data being “filled in” incorrectly (e.g., guessing a missing invoice number)
- Formatting inconsistencies (e.g., producing a JSON output with non-existent fields)
- Incorrect interpretations (e.g., altering financial figures or legal terms)
Requires Developer Involvement
LLMs need to be prompted, fine-tuned, and integrated into existing workflows, which typically require support from developers. These models also require ongoing maintenance, including managing updates and optimizing initial prompts. In contrast, most OCR software offers out-of-the-box automation with predefined templates for invoices, receipts, and ID cards.
No Standardization in Extraction
Traditional OCR software uses consistent rule-based extraction that ensures accuracy across documents. LLMs, however:
- Require prompt tuning to maintain output consistency
- Can format data differently for the same prompt
- Have no built-in verification to confirm extracted values
Final Verdict: Why AI-Powered OCR Is the Better Option
LLMs are not a direct replacement for OCR since they are better suited for contextual analysis and post-processing. A hybrid approach, where AI-powered OCR (Intelligent Document Processing) software like Klippa DocHorizon extracts structured data, refines or classifies it, ensures high accuracy without hallucinations.
The Best Alternative to LLM OCR – Klippa
Klippa DocHorizon is a powerful IDP platform that easily automates document workflows and can extract data from more than 100 document types and formats. Our IDP platform combines the best of LLMs and Traditional OCR. It uses machine learning and NLP to extract data from both structured and unstructured documents, adapting to different formats, layouts, and languages.
Let’s walk you through a step-by-step process of extracting data from a document using Klippa DocHorizon. In this process, we will use a PDF invoice as our example document, with Google Drive as our input source and JSON as our output format.
The best part? You can try it yourself for free!
Step 1: Sign up on the platform
The first thing you have to do is to sign up for free on the DocHorizon Platform. Enter your email address and password, then provide details such as your full name, company name, use case, and document volume. Once you’ve done that, you’ll receive a free credit of €25 to explore all the platform’s features and capabilities.
After logging in, create an organization and set up a project to access our services. For our goal – extracting data from invoices – simply enable the Financial Model and Flow Builder to get started. This setup ensures you have everything you need right from the start!
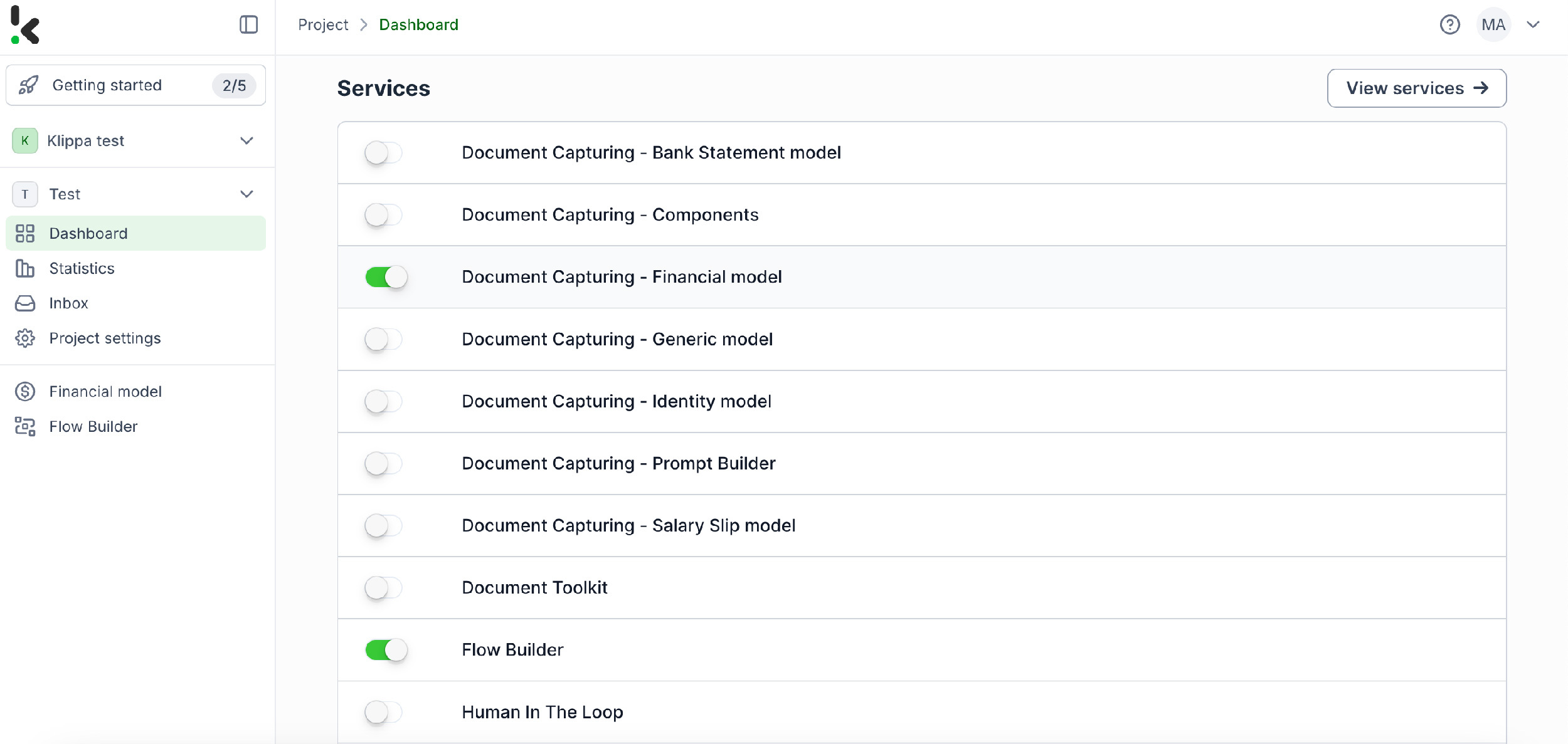
Step 2: Create a preset
You might wonder why we’ve chosen to enable the Financial Model over other options. The Financial Model is designed to streamline your financial workflows by automating the extraction, analysis, validation, and classification of data. It efficiently processes a wide range of financial documents, including receipts, purchase orders, bank statements, and more.
Once activated, you can create a new preset. Let’s name it “Extract Data from Invoices”. This preset lets you activate the components you need for your specific use case. For this case, you’ll enable the financial and line items components to process specific fields in your invoices such as supplier, amount, VAT information, date, currency, and invoice number.
Here’s a tip: You have the choice to customize the preset further depending on your use case by enabling more components such as Date Details, Reference Details, Amount Details, Document Language, Payment Details, etc.
You’re almost done! Click “Save” to finalize your settings and you’ll be ready for the next step in the Flow Builder.
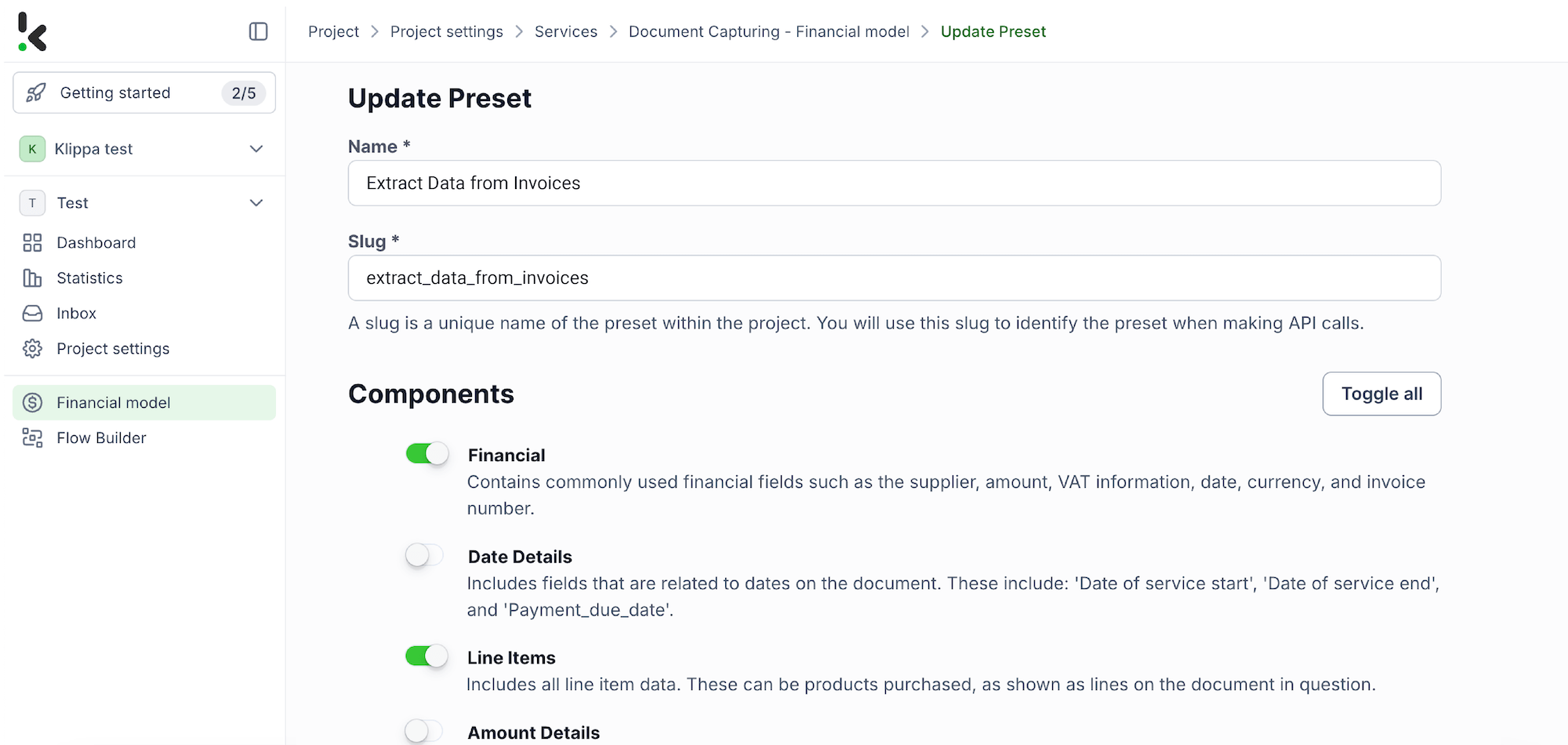
Step 3: Select your input source
After creating your preset and enabling the Flow Builder, it’s time to build your flow. A flow is essentially a sequence of steps that define how your invoices are processed and transferred to your output destination. For this example, we will choose Google Drive as our input source.
Click New Flow → + From scratch and assign your flow a name. We’ll name the flow “Invoice Data Extraction”.
Here’s a tip: The first step in building your flow is selecting your input source. You have several options: you can upload files directly from your device or connect to over 100 external sources, including Dropbox, Outlook, Salesforce, Zapier, OneDrive, your company’s database, or cloud storage solutions like Amazon S3 and iCloud. Make sure to place all invoices in the same folder so they can be processed in bulk if needed.
For this example, we’ll work with PDF invoices. We’ll create a folder named “Input” in Google Drive and upload your invoice there.
Next, choose your input source by selecting “Google Drive” and then “New File” as your trigger. This is going to start your flow. On the right side, fill out the following sections:
- Connection: You can assign any name to your connection. For instance, we’ve named ours “google-drive”. Once named, the system will prompt you to authenticate with Google.
- Parent Folder: Input
- Include File Content: Check this box to ensure file content is processed.
Test this step by clicking on Load Sample Data: remember to have at least one sample invoice in your input folder while setting up your flow.
Here’s a tip: Since the platform supports a wide range of document types to meet all business needs, you can check our comprehensive documentation to learn more.
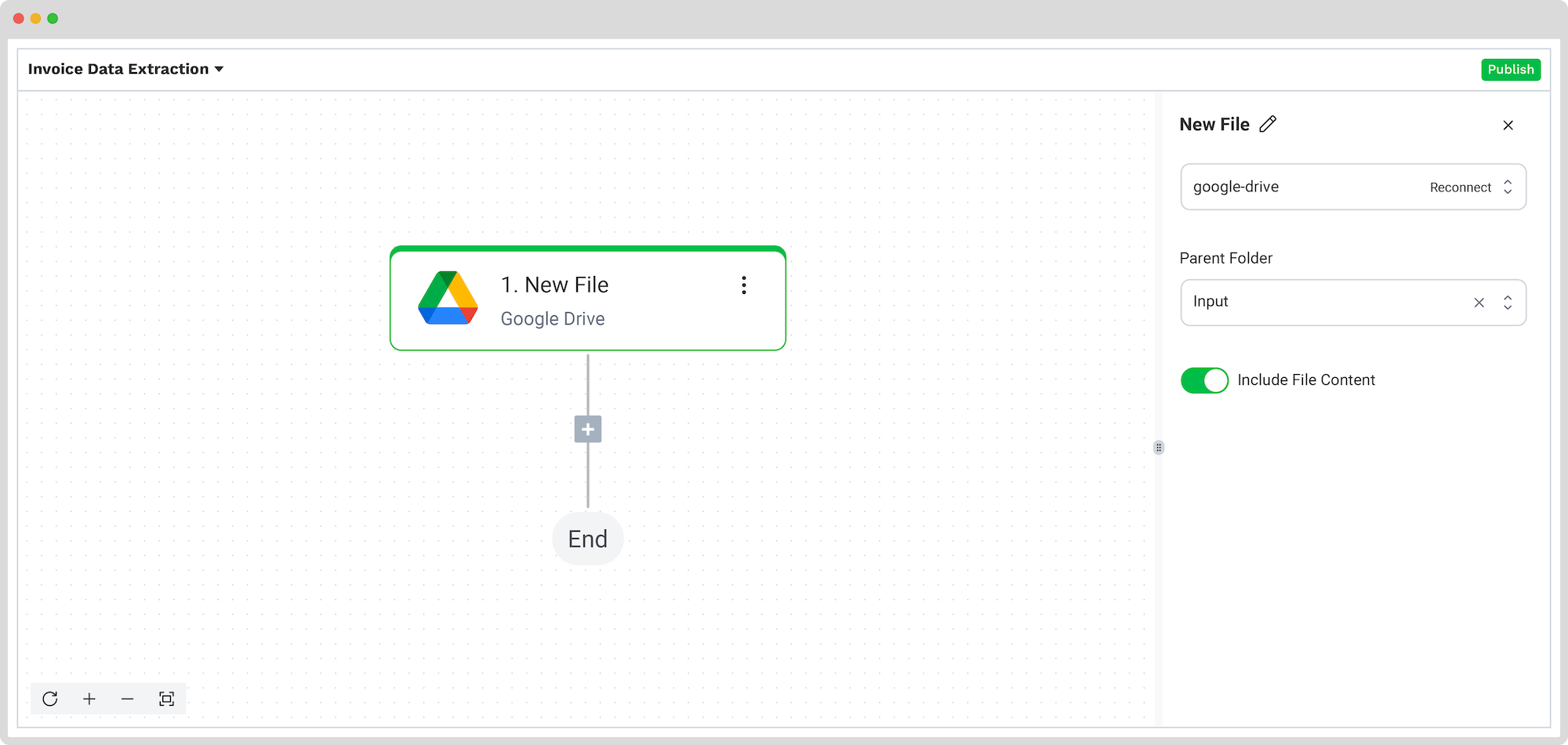
Step 4: Capture and extract data
Now, it’s time to extract the necessary data by using the previously created preset to process all the selected data fields from the invoices in the input folder.
In the Flow Builder, press the + button and choose Document Capture: Financial Document.
To proceed, configure the following:
- Connection: Default DocHorizon Platform
- Preset: The name of your preset (in our case “extract_data_from_invoices”)
- File or URL: New file → Content
Then, test the step to ensure everything is working correctly. Once the test is successful, you’re ready to move on to the next step: saving your results!
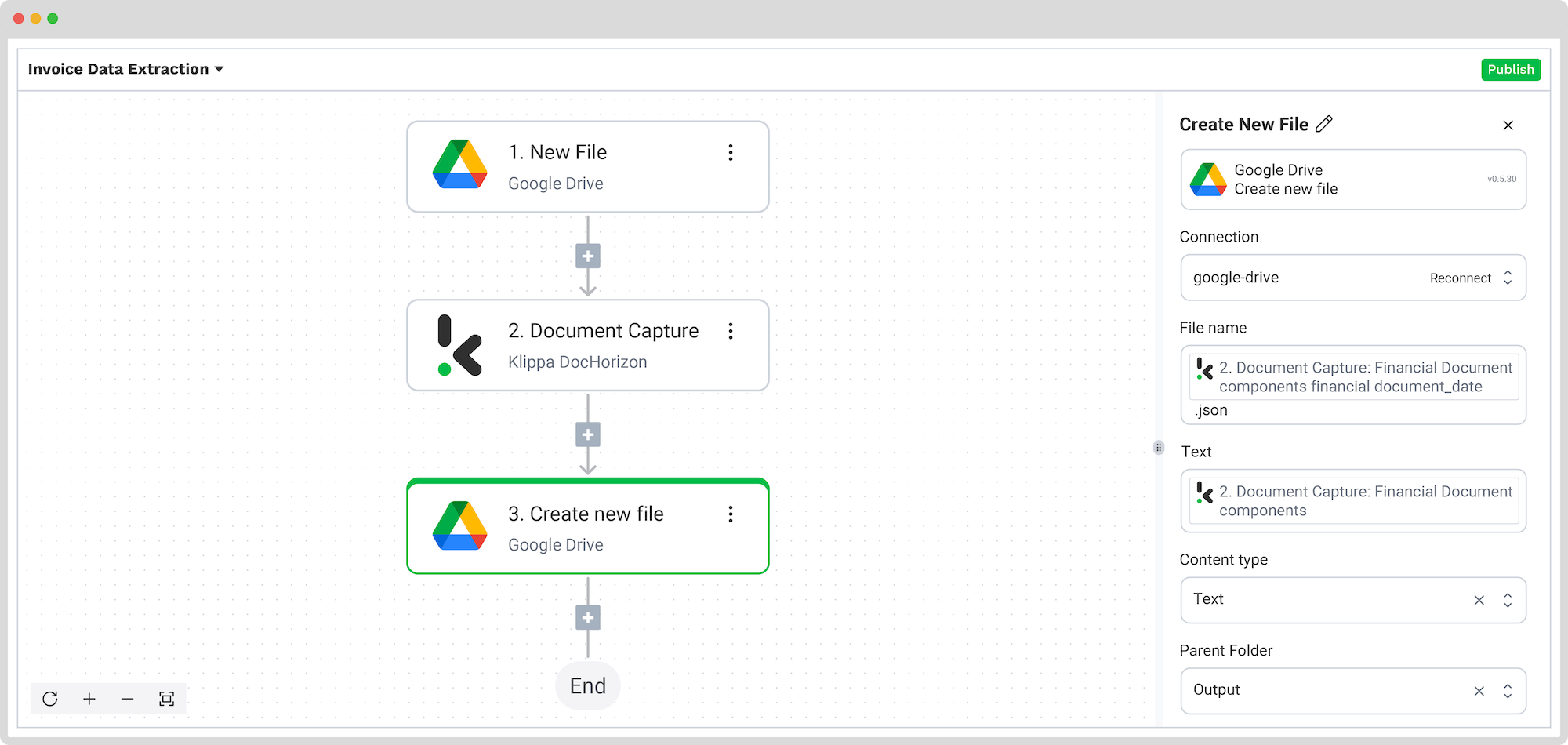
Step 5: Save the file
Once the invoice is processed, the final step is to choose the destination and the data format for the final output. The destination can be your database, ERP system, accounting software, or any other platform depending on your workflow. The data output format can be chosen from JSON, XML, CSV, XLSX, UBL, PDF, or TXT.
For this example, we will set the invoice number as a file name with the extracted data and save it in JSON format. We will create a new folder in Google Drive, name the output folder “Output”, and set it as a final destination for our file with the extracted data.
Press the + button and select Create new file → Google Drive
To proceed, configure the following:
- Connection: google-drive
- File Name: Document Capture: Financial Document → components → financial → invoice_number. Next to it, type .json
- Text: Document Capture: Financial Document → components
- Here’s a tip: Select the text you want to include in the new document. By selecting “components” you choose all the extracted elements.
- Content Type: Text
- Parent Folder: Output (the name of your output file)
Test this step by clicking the button at the right bottom, and you’re all set!
Congratulations! All the invoice data is now available in your Google Drive folder. With this setup in place, you can publish the flow, and any new invoices added to the folder will be processed automatically. That’s how you can save time while ensuring accuracy in your workflows.
Automate Your Data Extraction with Klippa
Looking to extract data from any type of document in Google Sheets, Excel, JSON, and more? We’ve got you covered! With Klippa DocHorizon, you can easily automate all your workflows:
- Data extraction OCR: Automatically extract data from any document.
- Human-in-the-loop: Ensure almost 100% accuracy with our human-in-the-loop feature, allowing internal verification or support from Klippa’s data annotation team.
- Document conversion: Convert documents in any format – PDF, scanned images, or Word documents – into various business-ready data formats, including JSON, XLSX, CSV, TXT, XML, and more.
- Data anonymization: Protect sensitive information and ensure regulatory compliance by anonymizing privacy-sensitive data, such as personal information or contact details.
- Document verification: Authenticate documents automatically and identify fraudulent activity to reduce the risk of fraud.
At Klippa, we value privacy, that’s why all of our document workflows are compliant with the HIPAA, GDPR, and ISO standards, ensuring secure data processing. With peace of mind about data safety, take the next step and streamline your data extraction workflows.
If you’re interested in automating your workflow with Klippa’s intelligent document processing solution, don’t hesitate to contact our experts for additional information or book a free demo!
FAQ
No, LLMs are not a direct replacement for OCR. While they can process text from PDFs and structured text files, they struggle with scanned images, handwritten text, and complex layouts. AI-powered OCR remains the more accurate and scalable option for document automation.
Businesses should opt for AI-powered OCR when dealing with high-volume document processing, structured data extraction (e.g., invoices, receipts, ID cards), and compliance-sensitive workflows. AI-powered OCR ensures accuracy, scalability, and security, unlike LLMs, which are better suited for contextual analysis and summarization.
Yes. Klippa offers a free trial with €25 in credits, allowing you to explore the platform’s features and capabilities before deciding.
Absolutely. Klippa complies with global data privacy standards, including GDPR. Your data is encrypted, securely processed, and never shared with third parties without your consent