The rapid growth of technology has taken its toll on businesses, as we see more and more organizations facilitating daily tasks using automation. The shift from pen and paper usage at the workplace, towards the integration of OCR technology, has significantly shortened document processing times for a large number of companies.
However, OCR technology has also benefited from upgrades in the last few years. This means that some OCR software might be performing better than others in terms of text detection. What differentiates them is the integration and use of machine learning and AI in traditional OCR solutions. To find out if the technology used in your business is up-to-date or if it needs improvement, keep reading.
In this blog, you will get acquainted with Machine Learning OCR, look at a comparison between traditional and the new-age OCR, and show you how you can build your own Machine Learning OCR model. Let’s start!
Challenges of Traditional OCR
Traditional OCR, which is essentially template-based, simply reads, extracts and provides data output from specific documents, aimed for further processing. Simultaneously, zonal OCR works on the same premises, except it does not extract all of the data from the document, but rather a specific part of it, for instance a single line item, date or name.
The singularity of template-based OCR is that it is trained to work on a particular document type, format and even language. Additionally, it only processes data if the document in question contains structured information, such as names, dates, addresses or any information assembled in a standardized format. There are, however, several downsides of this particular OCR technology, applicable to zonal OCR as well:
- It is incapable of extracting data from complex sources
- It struggles with capturing sequential data fields
- It depends heavily on the quality of the input
- It solely relies on predetermined templates
In case your documents are diversified, or you work with a large amount of unstructured information, a template-based OCR will not meet your needs. It requires training on specific templates, which already suggests that it can be a time-consuming and costly process. Ideally, you’d opt for an OCR software that can process any document type, be it in a structured or unstructured format, without prior adjustments.
To be able to capture data from various documents accurately, a business might want to choose an AI-powered OCR solution. Often, this means that it leverages machine learning technology, which results in machine learning OCR, or simply ML OCR.
What is Machine Learning OCR?
OCR Machine Learning is an optical character recognition software embedded with machine learning technologies. Deploying machine learning allows the software to easily understand and recognize the general context of a document, through a set of rules.
In comparison with traditional optical character recognition, machine learning OCR:
- Processes both structured and unstructured data
- Is based on a continuous learning cycle
- Achieves more than 95% accuracy in information extraction
It is good to keep in mind that the capabilities of OCR with machine learning stretch much further than any of the template-based ones. With enough data and proper training methods applied, ML OCR increases its accuracy and prediction rates, being able to recognize and determine the location of data fields with high precision. Based on this, the software extracts information accordingly, regardless of the complexity of the document.
While machine learning enhances OCR as a whole, different subdivisions of machine learning and OCR algorithms can be used for data extraction processes. For example, some models focus on natural language processing, or NLP, to capture information from live chats, handwriting or emails. Other models deploy, for instance, deep learning.
What is Deep Learning OCR?
OCR with deep learning can be beneficial when dealing with imperfectly scanned paper documents. Flawed scanned images may contain noise, unflattering lighting or need deskewing, which makes data extraction slightly more difficult for an OCR model deprived of AI technologies.
Employing deep learning and OCR entails the following three steps:
- Image pre-processing: AI image processing helps enhance the quality of the image, meaning the noise is removed and lighting adjusted and deskewed. This first step is essential to create the best environment for the data to be extracted.
- Text detection: To locate the text within a document, several models can be used. They create bounding boxes over each text identified in the image or document. It is a preparatory step for data extraction.
- Text recognition: After the text is located in the file, each bounding box is sent to the text recognition model. The final output of these models is the extracted text from the documents.
As we mentioned before, there are multiple subtypes of machine learning algorithms that can be used to amplify the quality and accuracy of data extraction. In the next section, we will take a closer look at what OCR algorithms are.
Understanding OCR Algorithms
An OCR algorithm can be divided into two distinctive categories: template-based algorithm and cognitive algorithm:
- Template-based algorithm: The algorithm reads and extracts solely the information it was trained on. As the name suggests, the training is done on predefined templates, making this algorithm the foundation of traditional OCR.
- Cognitive algorithm: With cognitive training, OCR algorithms are designed to identify each character simultaneously. It involves the system scanning the overall document and building a spatial “map” of the location of important data.
To give you a clearer image of how cognitive algorithm works, let’s take a closer look at the process behind it:
- First, the OCR system scans the area of the document or image, to identify what it assumes to be a cluster of characters.
- The system then assigns a value of either “0” or “1” to every pixel in the close proximity of the characters based on whether or not the color is either black or white.
- All of the values labeled with “1” are black and indicate the shape of each character. The OCR model then compares the initial spatial “map” it created during the pre-training phase, and accurately identifies which characters make up the data.
- Apart from the characters themselves, the most effective OCR algorithm relies on contextual cues and the spatial arrangement of data. Extensive testing consistently demonstrates that this model type outperforms conventional OCR models in terms of both efficiency and accuracy.

Now that we’ve covered some of the topics that make the foundation for machine learning OCR, it is time to discuss how you can actually implement it within your organization. For starters, an option you can take into consideration is building the model from scratch.
How to Build a Machine Learning OCR Model?
In order to build a machine learning based OCR, you need to implement a model for text detection and one for text recognition. To make the process easier, an option worthy of taking into account is using an open-source OCR engine, such as Tesseract, used for text recognition.
Tesseract OCR uses methods based on deep learning, which are more suitable for recognizing and extracting unstructured data. To be able to use it accordingly, you need to pair it with Python libraries or wrappers, such as PYOCR, OpenCV or Pillow for example.
Whether you opt for an open-source OCR engine or not, there are some matters you need to keep in mind if you want to build your own machine learning OCR model:
- Data Collection
- Data Annotation
- Model Training
- Testing
- Implementation & Monitoring
Data Collection
The first step is to gather as much data as possible, such as documents, templates or any other type of file you’d like to process in the future. There are a couple of methods to obtain this data:
- You can ask your clients or customers for empty templates of documents and fill them with random data. For GDPR compliance, it is good practice to avoid using personal or sensitive information in the training process.
- You can purchase synthetic data or outsource it from a third party.
Data Annotation
Data annotation, or data labeling, involves creating bounding boxes over the area containing the text you intend your model to recognize. This step is very important, as it helps determine the output of the extraction process. Based on the precision used for drawing the bounding boxes, extracted data is also more accurate, giving you the desired data output. Additionally:
- Data annotation can be done in-house, by your organization’s team of specialists.
- You can also outsource data annotation, either from the software provider or an additional third party.
Model Training
After gathering and labeling the data, it is time you train the model. Much like the previous step, training is also a crucial part of building a machine learning OCR model. It is important to focus on one template at a time, so the model does not get confused at a sequence of different documents. It is better to train it on one specific file type until it is confident enough to move on to different ones. The training can be done via:
- Supervised learning – Supervised learning is solely reliant on labeled data for training. In this case, the model learns the relationship between labeled input and data output and is able to accurately predict the outcome of raw, unseen data.
- Unsupervised learning – On the contrary, unsupervised learning learns from unlabeled training data. The model is then capable of learning occurring patterns and discover existing correlations within the given data set.
- Both supervised and unsupervised learning – In this context, the model is trained on both labeled and raw data, to further enhance its prediction capabilities. The model therefore uses a small amount of labeled data and lots of raw data, cutting down the training time.
Testing
To check the performance of the data extraction process, it is necessary to test the model. To do so, you can compare the extracted data with the ground truth, meaning the information in the document template. Another option is to simply observe the results portrayed in the bounding boxes and make a judgment based on that specific output.
To achieve the best results in training and testing the model, it is important that three different data sets are used: one for the training, one for validation and lastly, one for checking the performance of the model.
Implementation and Monitoring
Lastly, after the model is trained and performs at your desired level, it is ready to be launched and deployed in your organization. To keep track of its performance, it is important that the model is continuously monitored. This helps easily detect if there is any room for improvement and whether it still performs at expected levels.
While building an ML OCR model from scratch is definitely an option, it may not always be viable. This process as a whole can be quite the challenge. How so? Let’s look at some of the downsides of this procedure:
- It requires a large amount of financial and human resources for building, training and implementing the model.
- It is dependent on the expertise of specialized personnel, as its performance is solely based on extensive documentation.
- Its creation and implementation are time consuming, making it harder to use it right when the need arises.
If your organization does not hold these resources or is not willing to embark on this demanding and hefty journey, you may want to try a different approach. An ideal alternative is choosing an out-of-the-box solution, such as Doxis AI.dp.
Intelligent Text Recognition with Doxis
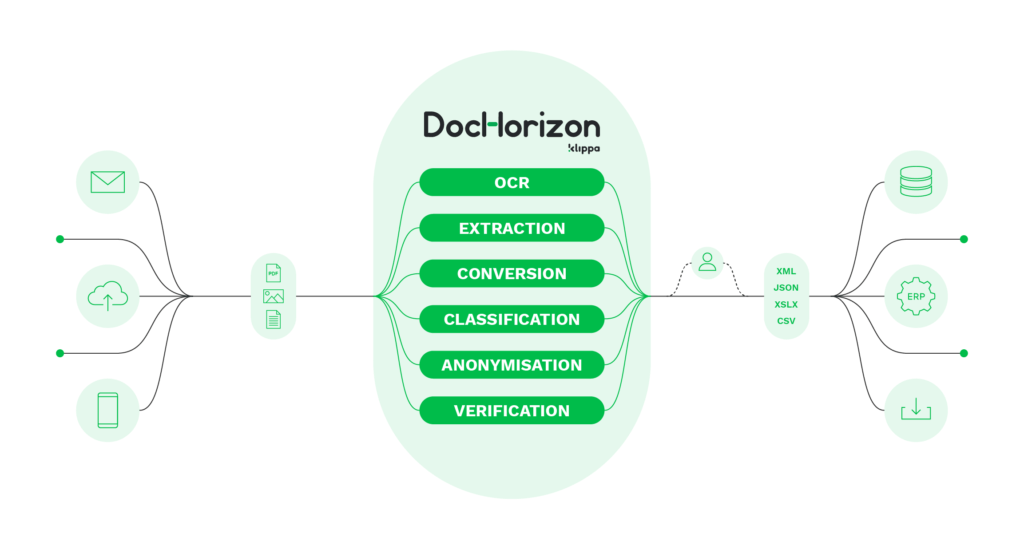
Doxis AI.dp is an intelligent document processing solution that reaches up to 99% accuracy in data recognition and extraction processes. It leverages OCR and AI technologies to swiftly recognize text from both structured and unstructured documents, but also:
- Automatically converts documents to and from various formats – You can automate data entry and get business-ready data in seconds
- Automatically verifies the authenticity of documents – helps you detect invoice fraud or identity theft
- Classifies documents based on their content – You can sort documents automatically with no human intervention needed.
- Instantly parses documents – It allows you to unlock useful data
- Cross check documents and data points
- Anonymizes and masks sensitive data, letting your organization enhance GDPR compliance
- Seamlessly integrate it via API or SDK
- Be customized to fit your organization’s needs, for instance, with custom data field extraction
If you still want to give building your own text recognition model a chance, keep in mind that soon, you will be able to do so using Doxis AI.dp’s platform. Until then, feel free to contact our experts for any additional information or book a free demo down below and employ intelligent text recognition promptly.