
With data being the new gold for the business world, it is incredibly inconvenient for businesses when valuable information is stuck in unstructured document formats such as a PDF. The reason for this is that unstructured document formats are not machine-readable. This means, in order to work with the data of a PDF document, information has to be manually extracted and saved in your database.
Manually extracting information is an acceptable process as long as businesses only deal with a handful of PDF documents. As soon as an organization needs to process larger amounts, the manual process becomes too slow, expensive and error-prone.
Here is where a PDF parser is able to replace the traditional manual data extraction and entry process. With data parsing it is possible to quickly convert data from one format to another, such as a PDF file into a machine-readable JSON file.
In this blog we will discuss what a PDF parser is and how PDF data is parsed. Next to this, we will explain why companies should use a PDF parser in general, and then finish the blog with a PDF parsing automation solution.
What is a PDF parser?
A PDF parser (also known as PDF scraper) is a software able to identify and extract data from PDF documents. This means the text in the document (i.e. unstructured data) is converted into structured data that can be read by machines. That way, valuable information is unlocked that otherwise would remain inaccessible in the unstructured format.
In general, a PDF parser allows you to:
- Extract text from PDFs
- Extract images from PDFs
- Extract tables and other structures from PDFs
- Convert the PDF file into JSON, XML and HTML files
- Use structured data for business processes
Now that we know what a PDF parser is, let’s have a look at how parsing works so that you are able to use it for your business as well.
How to parse PDF data?
PDF parsers make use of advanced algorithms to identify the data elements in a PDF document. As long as the PDF parser is well-trained, it will be able to identify all basic types of document elements.
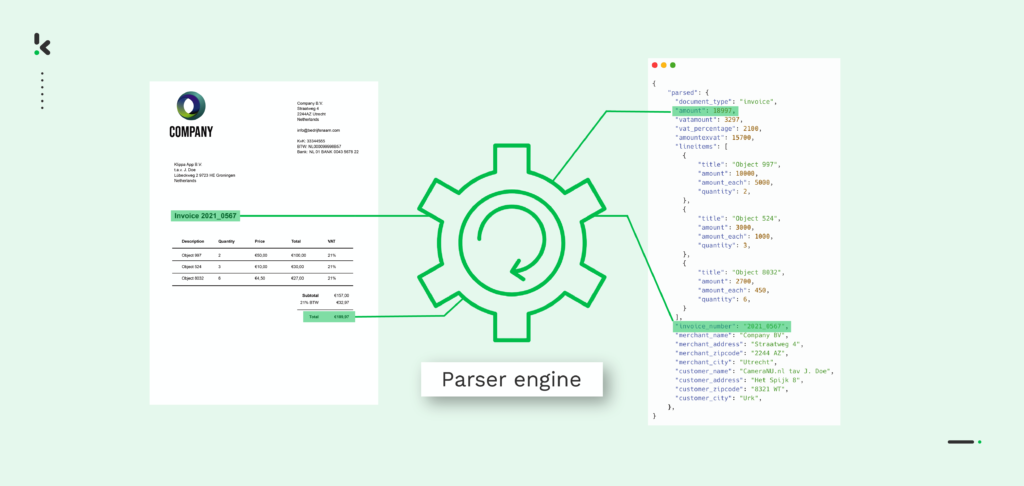
This process involves Optical Character Recognition (OCR) and other AI technologies such as Natural Language Processing (NLP) and Machine Learning (ML). Only with the help of these technologies, a PDF parser is able to scan a PDF file and parse data from it.
The process could look like the following:
- Uploading a PDF file to the parser → The PDF has to be uploaded to an API to start the parsing process. It is important that the PDF contains no noise in the background.
- Pre-processing of the PDF → Brightness of the PDF scan can be optimized or the grayscale improved to increase the recognition accuracy of the data.
- Converting PDF to text → In this step, the PDF document can be converted into a text (TXT) file. Each part of the document is recognized (total amount, address, etc.) and then data extracted.
- Conversion to structured data → In this last step, the text file is converted to a structured machine-readable format such as JSON. Now, it is possible to easily process the data from the PDF in your database.
At this point you might be wondering what kind of data a PDF parser can actually extract to help you decide whether a PDF parser performs according to your needs.
Which data can be parsed from PDFs?
For most organizations PDF files are the go-to option for many different document types. Think of books, presentations, invoices, purchase orders and reports that are often shared among organizations in the form of a PDF file.
While PDFs are a great file format to embed rich media, PDF parsers are allowing you to extract the following information of it:
- Text paragraphs → Even though this is the most basic form of data, manually copying and pasting it would result in formatting issues. A PDF parser is able to extract text with the right formatting so that you can easily use it for further processes.
- Tables and lists → Here, it is worth doing extra research as only the most modern PDF parsers can identify the presence of tables. Most old PDF parsers consider tables as a paragraph and make a mess of them, which means manual extraction of data is needed.
- Images → A PDF parser is able to extract images present in the PDF document. This is especially useful when you want to reuse images from the document elsewhere and saves you the burden of taking low-quality screenshots.
- Single data fields (tracking numbers, QR codes, Bar codes, etc.) → If a PDF contains fields with single pieces of data, a PDF parser can accurately extract them and neatly arrange the data in a particular field.
With this in mind, we should now have a look at why a PDF parser is valuable for companies.
Why should companies use PDF parsing?
Different layouts and structures of PDF files make them complex and difficult to extract data from. This is why manual data extraction is time-consuming and therefore can cost a lot of money. It also leads to a variety of errors and inaccurate data extraction.
With a PDF parser errors and inaccurate extraction can be avoided. As we learned above, with the help of modern technologies, a PDF parser is able to identify and extract information on PDFs accurately and without formatting issues.

As you can imagine, this leads to a significant reduction in time spent on the processing of PDFs which ultimately reduces costs and the use of other resources that can then be spent on more value bringing tasks. A reduced document processing duration results in optimized workflows, which will ease the operations of your business.
As you can read, a PDF parser software brings several benefits. This is why there are various software companies that developed a solution you can profit from. One of these software solutions is Klippa DocHorizon.
PDF parsing automation with Klippa DocHorizon
Klippa DocHorizon is our AI-based OCR software that can be used to parse information from PDFs and other documents that your company may work with. With our OCR technology, you can accurately extract relevant data from unstructured data formats (such as PDFs) and convert those into your desired format.
Next to that, DocHorizon can classify document types, verify and anonymize data, all the while eliminating manual data entry. Out of the box, DocHorizon recognizes a wide range of documents in more than 100 languages.
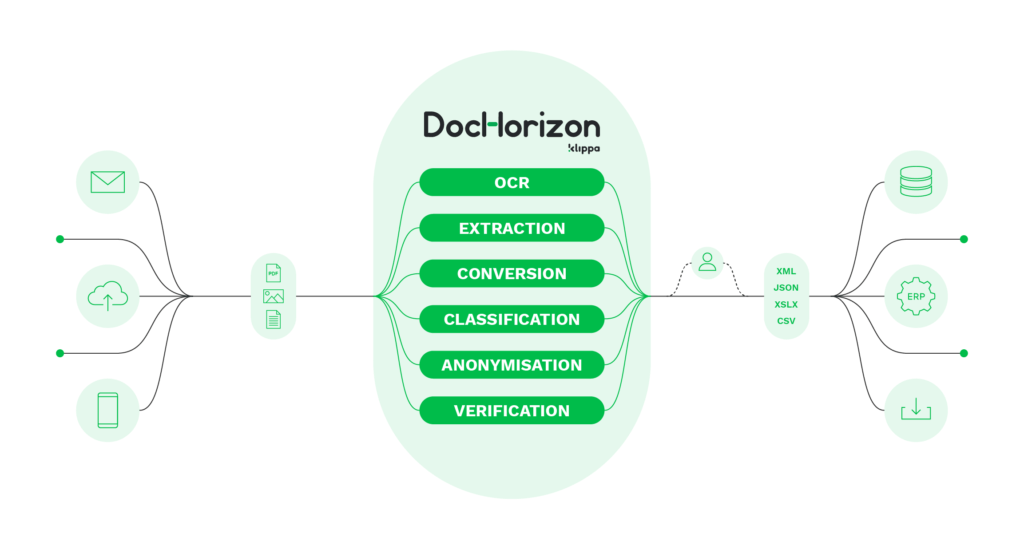
Our solution is available via API and SDK, allowing your employees to quickly extract and save all relevant information in your organization’s database.
Do you also want to transform your data that is stuck in unusable formats to business-ready data? We would gladly show you how to do that with our solution. Just book a free demo down below or contact one of our experts.