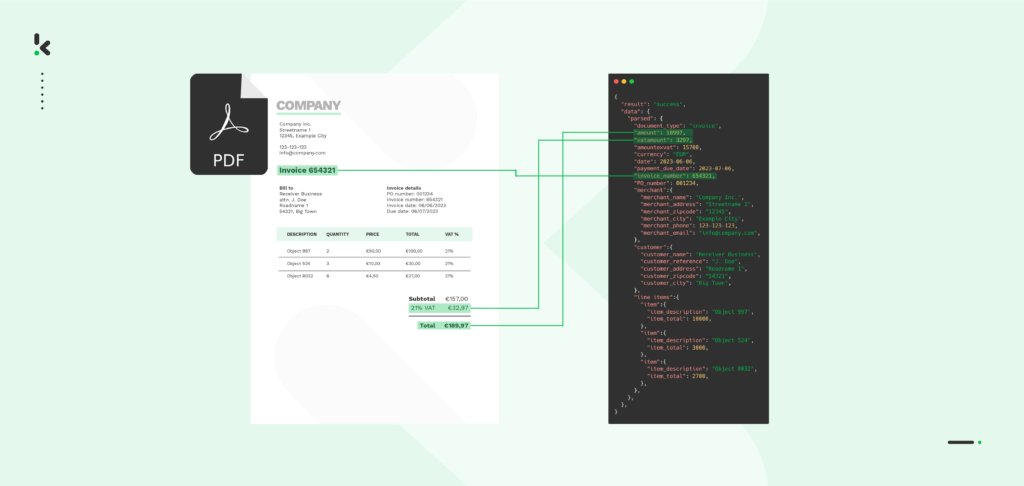
Whether your business is in the financial or retail industry or any public sector institution, you’ve probably realized that PDFs hold the most important information. However, they are designed to be human-readable, making their unstructured nature a big challenge when it comes to processing these documents with software applications.
One way to swiftly retrieve all relevant information from your PDFs is with PDF scraping. To do so, your business can opt for AI-powered platforms capable of automating PDF scraping workflows. In this blog, you will get to know the ins and outs of PDF scraping and learn how to make scraping data from PDFs part of your business processes. Let’s start!
What is PDF Scraping?
PDF scraping is the process of extracting data from unstructured documents in a PDF format and transforming it into a structured one such as Excel, JSON, or XML. This technique is used to capture only selected information or data fields from a PDF.
That makes PDF scraping essential for businesses that want to make data-driven decisions. The extracted PDF data can easily be read and utilized by business software such as ERPs, CRMs, and accounting software, or major databases.
Challenges of PDF Scraping
As we just mentioned, scraping data from PDFs isn’t without its hurdles. The main challenge comes from the format’s versatility—or lack of it. PDFs contain text, images, and tables, which makes uniform data scraping a quite complex process.
Additionally, the difference in the quality of PDFs, especially when it comes to scanned documents, adds another layer of difficulty to PDF data scraping efforts. If the quality is lacking, the exported information might present errors, mistakes, or missing information.
Due to the many variations in structure, PDF scraping is most commonly done in two main ways: the good old copy-and-paste method and manual data entry. Both of these methods interfere with the document’s layout and formatting, messing up most of the information. Not to mention, it takes a large amount of time to search the document, type the information of your interest, and go on, pages on end.
Thankfully, technology has a solution for it once again. Instead of wasting time, energy, and resources on scraping PDF data manually, your business can benefit from an automated solution. Let’s get more detailed on how to scrape data from a PDF with an Intelligent Document Processing platform, such as Klippa DocHorizon.
How Automated PDF Scraping Works with Klippa
Klippa DocHorizon is an intelligent document processing platform that helps your business streamline document-related workflows, such as PDF scraping. In just 6 very easy steps, you can set up a very unique flow, completely customized to your business’s needs and use case.
Step 1: Sign Up
First things first, sign up on the platform. Just provide your details and create an account. Our user-friendly interface makes it easy to interact with the platform, so you don’t have to worry about any obstacles.
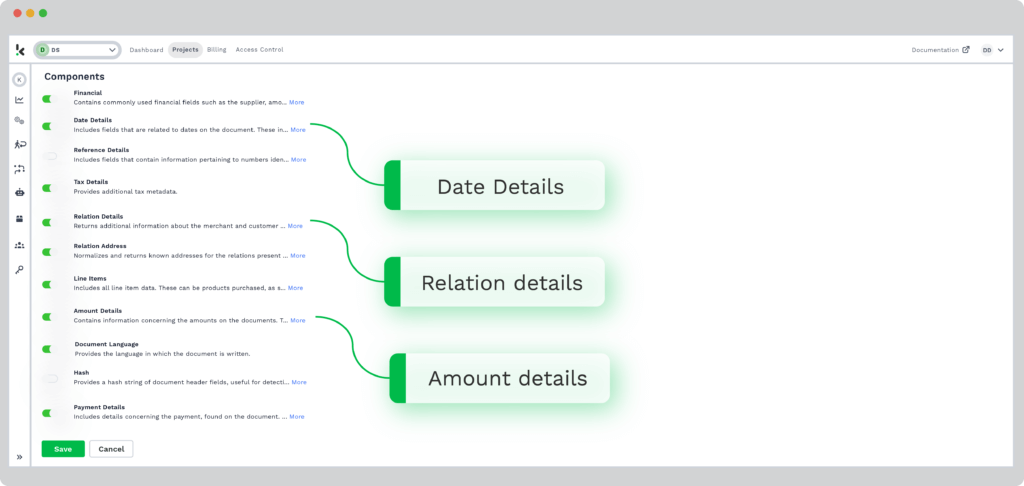
Step 2: Select Components
Once you’re in the flow builder, go to the services option and select which data fields you want to scrap from the PDF. Choose from multiple data fields that you want to scrape and simply select them to the preset.
Step 3: Retrieve PDF
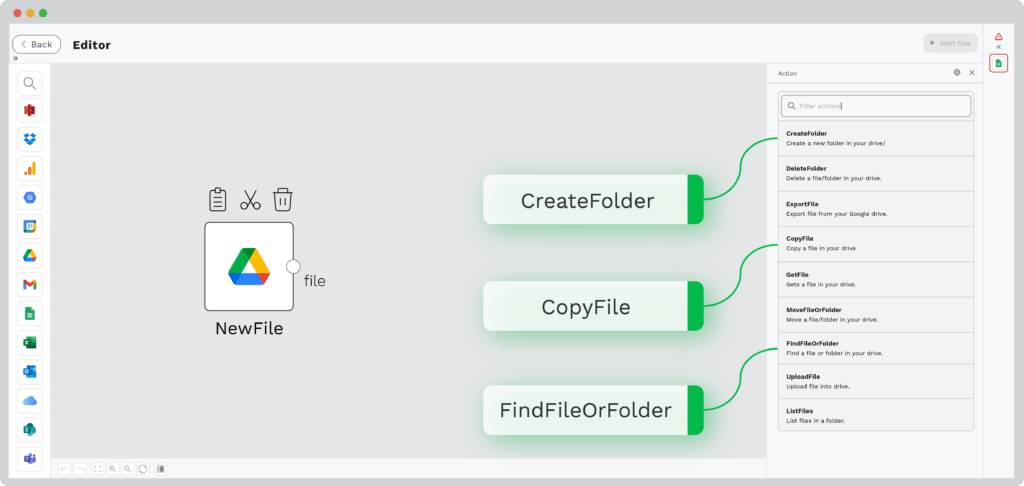
To get the flow started, you need to select the input source. With Klippa DocHorizon, you can choose from retrieving a document from your Drive, parsing it from an email attachment, or an existing application used in your business.
For the sake of this example, we will use a PDF retrieved from Drive as the input source.
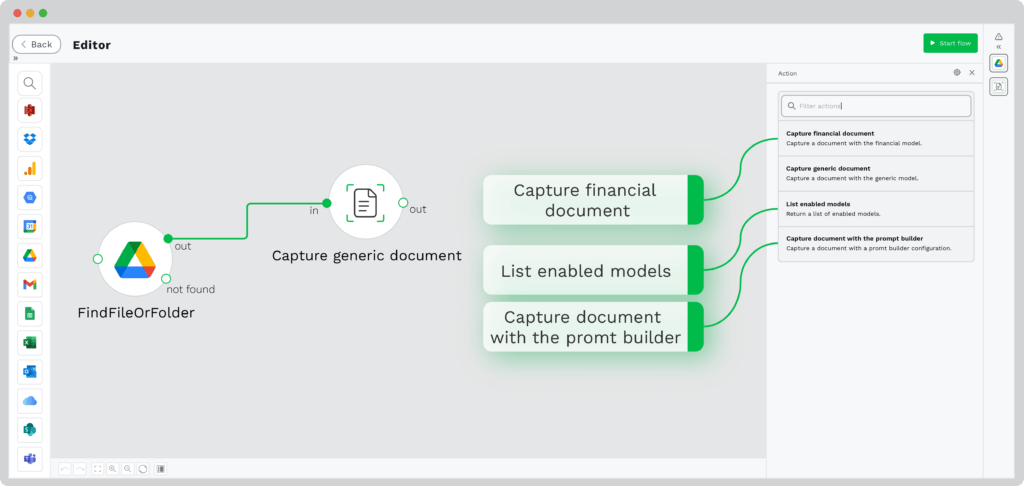
Step 4: Select Document Capture Mode
To be able to capture information from the PDF and eventually scrape it, you need to select a document capture mode. After having selected the components, this mode will now capture the exact information you need.
Select a suitable document capture mode and the platform will do the rest for you. For this example, we will use the generic document capture mode.
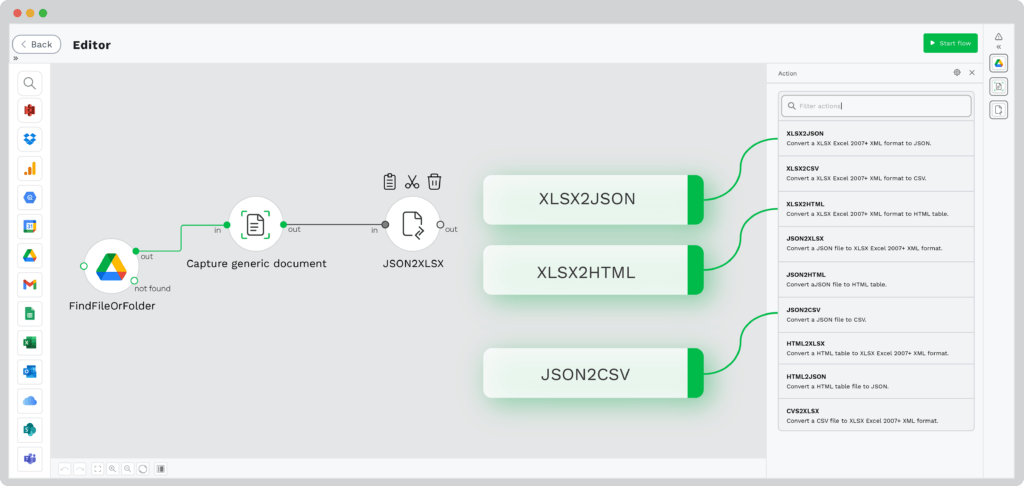
Step 5: Convert Data to Format of Your Choice
By default, all of the scraped data from this PDF, or any other document, is converted to JSON. However, you can select which format you want to export your data to.
Choose from keeping the JSON format, XLSX, CSV, and more. For this example, we will convert the data to XLSX format.
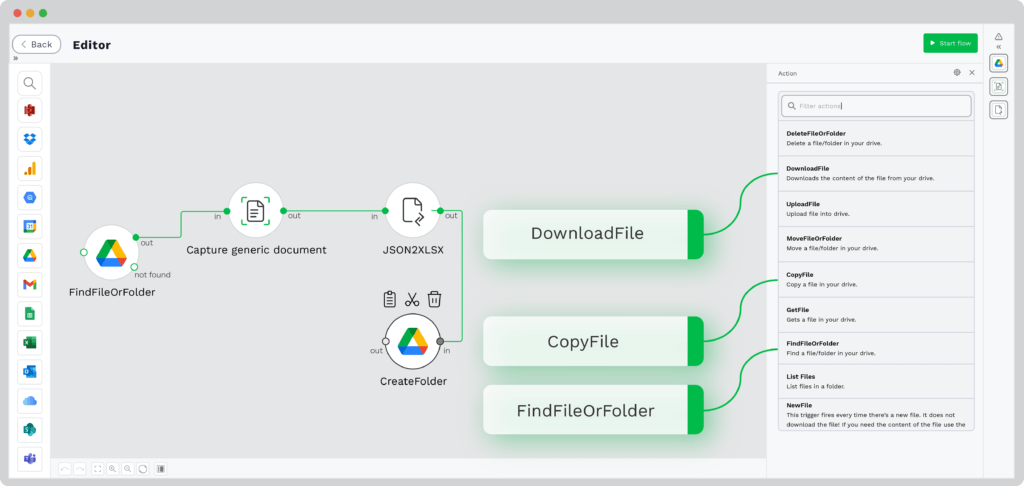
Step 6: Choose Output Destination
Based on your use case, the output destination can differ at all times. Be it Drive, email, or a CRM application, simply select your desired destination for the newly scraped PDF data.
Benefits of Scraping Data from PDF
Scraping PDF data, especially if it’s done automatically, brings a lot of benefits to your business:
- Improved Efficiency and Time Savings: Automating PDF scraping significantly reduces manual labor and processing time. Get accurate results in an instant and forget about the tedious process of manual data entry.
- Enhanced Accuracy and Consistency: Minimize human error and ensure data uniformity across documents. Your employees don’t need to deal with inconsistencies in reporting data or processing documents.
- Scalability and Standardization: Easily process large volumes of PDFs while maintaining data consistency. Moreover, you can process bulk PDFs, so you can ensure that all of the information corresponds to each PDF.
- Integration into Existing Systems: Export scraped data to various formats for easy integration into your current systems.
Knowing how to scrape data from PDFs can bring lots of advantages for your business, no matter the industry. Curious to learn about some real-life applications of PDF scraping? Keep reading!
Real-Life Applications of PDF Scraping
Streamlining Document Workflows in Financial Industries
Financial professionals deal with the daunting task of managing an extensive amount of documents, including bank and credit card statements, mortgage applications, and compliance paperwork.
With Klippa’s automated solution for scraping PDF files, financial institutions significantly enhance their document processing capabilities. This solution helps increase accuracy, reduce processing times, and ensure compliance with regulatory standards.
Optimizing Patient Records and Insurance Form Processing
Healthcare providers often face challenges in managing medical prescriptions and insurance forms, resulting in delays in patient care and complications in billing processes.
Klippa’s solution transforms healthcare document management by automating PDF scraping of patient records and insurance forms. This enables faster and more accurate processing of patient data, leading to better healthcare document processing and streamlined billing operations.
Enhancing Inventory and Supplier Invoice Management
Retail businesses frequently deal with complex shipping labels and supplier invoices. Not to mention, since the majority of invoices and delivery confirmations come in a digital format, it can become very easy to lose track of all incoming documents.
By implementing Klippa’s IDP platform for scraping PDF files, retailers can achieve greater accuracy and efficiency. This solution ensures that inventory levels are accurately updated, and supplier invoices are processed promptly, as well as making sure there is no sign of invoice or vendor fraud.
Streamlining Supply Chain Document Processing
In the manufacturing sector, managing supply chain documents, including purchase orders and shipping labels, can be overwhelming and eventually lead to operational delays or disruptions.
Klippa’s automated document workflow helps you streamline supply chain document management by streamlining PDF data scraping. This enables your manufacturing team to maintain smooth operational workflows, ensuring timely production and delivery.
To be able to see powerful results in your document management, it’s better to go above and beyond and automate the full PDF scraping flow, not just a part of it.
Fully Automate PDF Scraping
Klippa’s solution seamlessly streamlines the PDF scraping process, soon making it a standard practice for any of your business workflows. Regardless of your industry or use case, automating the process of scraping data from PDF with Klippa DocHorizon enhances operational efficiency and empowers you to focus on core activities.
By employing our platform, you benefit from:
- Global document coverage, including documents in all Latin-alphabet languages
- Time-saving practices with our bulk-processing option
- Unlimited document support with our prompt builder
- Ensured data privacy and security, by means of our ISO and GDPR compliance
- Ensured onboarding and maintenance support
- Automated document classification
- Up to 100% accuracy in the workflow thanks to our HITL feature
- Clear documentation and instructions
Dealing with PDF documents manually is history’s tale. Join our DocHorizon platform and fully automate your PDF scraping flow. Contact our experts for more information or book a free demo down below!