Optical Character Recognition (OCR) is a technology that automatically extracts text from documents or scanned images, and then converts it into a structured, machine-readable format. This makes it faster, easier, and cheaper to collect, store, and handle data.
Traditional OCR, however, extracts all data from a document without any differentiation by relevance or importance. In case you only need a specific data field or section of a document, you’ll end up with a lot of irrelevant data. You would need to filter and exclude this data to end up with the data you actually need.
In situations like these, Zonal OCR can help you out. Often considered the second generation of OCR, it allows you to extract only the important and specified data fields from a scanned document.
In this article, we will discuss what Zonal OCR is, its pros and cons, what it is used for, and introduce you to the newest generation of OCR that might suit you even better.
What is Zonal OCR?
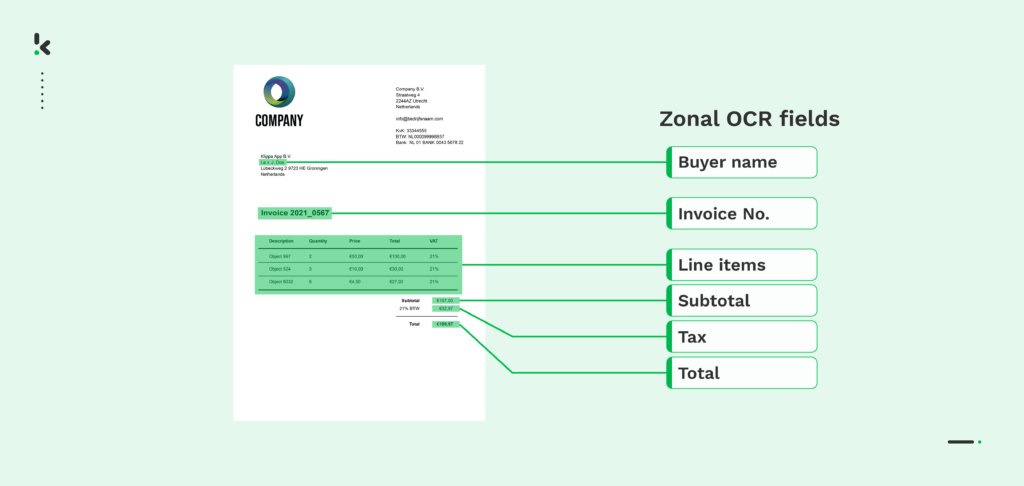
In short, Zonal OCR also known as Zone OCR, is a type of OCR technology that extracts data from a specific part of a given source or document. For example, it could extract only the needed data fields from an invoice, such as the invoice number, total amount, and due date, and ignore the rest of the text.
To do so, it makes use of pre-defined templates for data extraction. These templates allow a machine to be taught to isolate a certain section of text at a certain location. For each data field you want to extract, you will have to create a separate configuration and teach the computer where to find that field on the document.
Although this might sound quite complex, it can be as easy as drawing a rectangle (i.e. bounding box) around data that must be extracted. Then, instead of extracting data from the entire document, the texts in the zones are identified and extracted as specified in the template.
In the example below, you can see a PO number being identified and extracted by Zonal OCR:

Imagine your business receives thousands of purchase orders per week. Thanks to their consistent layout, it’s easy to teach Zonal OCR software where specific data fields can be found. As a result, purchase orders can be processed within a matter of seconds.
Advantages of using Zonal OCR software
- Makes data collection faster, cheaper, easier, and more accurate: Zonal OCR takes only a few seconds to collect data from a document. It would’ve taken much longer for a human, and the repetitive process of analyzing similar data can easily bore a person and lead to errors. It’s also cheaper to work with Zonal OCR software than to hire multiple employees to do things manually.

- Avoids redundant data: A business doesn’t always desire to gather all the data from a particular document. Using OCR templates, it’s easy to cut down the fuss and only focus on what’s needed.
- Helps businesses go paperless: With Zonal OCR software, your organization can go paperless and have data stored in a digitized format. This makes information accessible to everyone, irrespective of location and time. This accessibility enhances productivity and reduces repetitive and wasteful efforts.
- Can structure extracted data in a tailored layout: Zonal OCR can collect specific information and format it in a specific way at the same time. This helps to track and analyze data for trends and issues.
Disadvantages of using Zonal OCR software
- Incapable of extracting data from complex sources: It gets hard for Zonal OCR to extract data when sources differ from each other. When it comes to complex structures, where the data source and placement can vary, it becomes problematic to extract data by OCR zone.
- Struggles to extract sequential data fields: When there is sequential data (e.g. continuing product numbers in the same invoice), even though the format is the same, it becomes problematic for Zonal OCR to produce accurate results.
- Depends on input quality: Text recognition and extraction quality depend on the source quality. A certain standard, in terms of quality, has to be maintained to get optimal results.
- Reliant on templates: A successful scaling of a Zonal OCR application can be extremely resource-intensive as you would need to create a separate template for every document variation you receive.
Take supplier invoices as an example. Even small businesses have to deal with dozens of different suppliers, whereby each supplier usually structures their invoices slightly differently. This means that a separate template has to be created for each of these suppliers.
Use Cases of Zonal OCR
Zonal OCR can be used in many sectors to speed up and automate various data processing and collection processes. As long as there’s data to be extracted from a readable document, Zonal OCR will work.
Some processes that can benefit from using Zonal OCR are given below:
Identity document processing
ID cards, passports and driving licenses are used in many sectors to verify people’s identities. Manually verifying the data and putting it into a computer is time-consuming and leaves room for errors. Zonal OCR can easily collect data from identity documents and store the data in a structured database, for further automation or processing.
Invoice processing
All businesses have to deal with invoice processing. That’s no problem by itself, but if you deal with thousands of invoices every day, it will get hard to keep track of them and collect data in a structured manner. Zonal OCR can easily identify merchant names, addresses, dates, total amounts, product names, and other information from the invoice and store it accordingly.
Purchase order processing
Similarly to invoices, Zonal OCR makes it easier to take certain data from a purchase order and store it in a way that allows for better data visualization and tracking.
Bank statement processing
Organizations often have a huge number of bank statements to further process and make a certain report or analysis. Zonal OCR makes it easier to read and collect specific information from bank statements, such as balances, total amounts, and transaction lines.
Form processing
All sorts of businesses and service providers use registration forms. Most of the time, data from registration forms are manually put in a certain order to keep track. This is extremely time-consuming and boring to do. A Zonal OCR solution can automate form processing and do this very efficiently and effectively, especially when it concerns some standardized forms.
Some other real-life use cases include text detection from objects and images, utility bill processing, receipt processing for warranty procedures, bill of lading processing, and many more.
Why do we use AI-powered OCR
After having discussed the pros and cons of Zonal OCR, we can conclude that Zonal OCR is a great technology but that it comes with a few important shortcomings.
Zonal OCR works well if the text layout within the document matches the layout coded in the template. However, it starts to fail for systems that deal with a large number of document variations or frequently encounter new document types.
For every new document type, layout or language, you would have to create new templates for Zonal OCR to work. Just imagine what this means if you work with many different suppliers or do business in multiple countries…
One way to address the problems mentioned above is by using an AI-based OCR solution. Such a solution is also known as Intelligent Document Processing (IDP) software, which can optimize your processes step by step, with fully automated workflows and a streamlined organization.
But why is this approach considered to be superior to Zonal OCR? This is mainly due to the fundamentally different design of such solutions. Instead of the OCR software having to be dictated by a number of document templates for each company, different system components can be trained on text blocks of all sorts of different document layouts. The result is a flexible solution that can process a large variety of documents and is not limited by templates.
IDP solutions like Klippa DocHorizon, therefore, take things to the next level and eliminate much of the work involved in setting up and optimizing the software. This alone results in significant cost reductions.
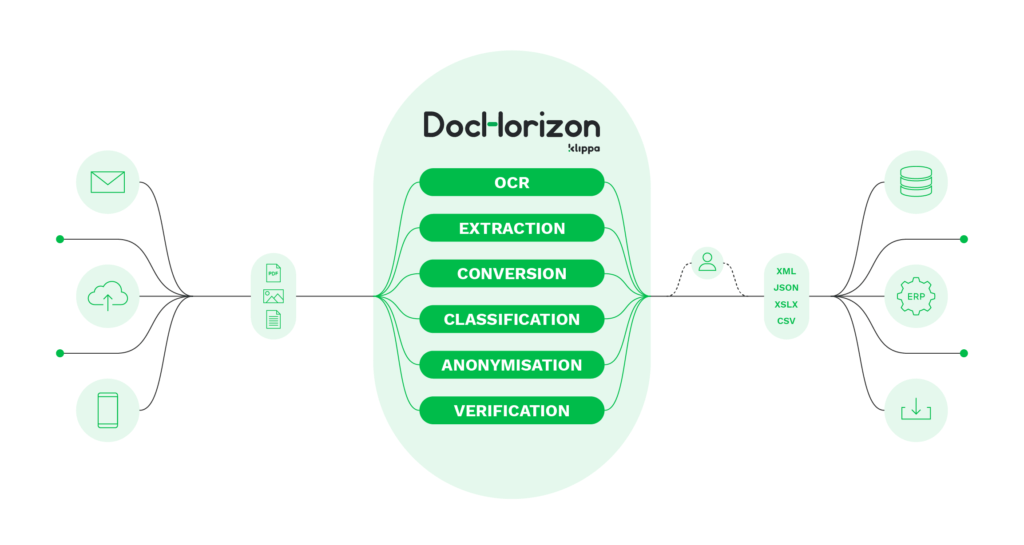
In addition, DocHorizon’s advanced AI technology cannot only automate your data extraction, classification, and verification processes, but it can also mask sensitive data and detect document fraud. As such, it offers the solution for all your document automation needs.
Did we spark your interest in OCR and Intelligent Document Processing? If so, feel free to reach out to us. Our product experts are more than happy to advise you on the best way to implement OCR in your business.
Simply plan a free demo via the form below to get started!