
Même si la Reconnaissance Optique de Caractères (OCR) a beaucoup progressé au cours des quelques dernières années, elle n’est pas encore et ne sera jamais parfaite. En particulier, le taux de précision de la plupart des solutions OCR n’atteint pas 100%.
Pour que la solution d’OCR produise des résultats précis, la qualité de l’image source est l’une des variables les plus importantes. Le problème est que la qualité de l’image d’entrée envoyée au moteur d’OCR n’est souvent pas au niveau optimal pour que la précision de l’OCR soit élevée. Cela peut être causé par de mauvaises pratiques ou conditions de prise de photos, comme un appareil photo qui tremble ou un mauvais éclairage.
Avec ce blog, nous voulons vous aider à éviter les erreurs courantes de capture de données. Tout d’abord, nous récapitulons rapidement le fonctionnement de l’OCR, expliquons comment est définie la précision de l’OCR et montrons des exemples de capture d’image incorrecte. Puis nous expliquons comment améliorer le taux de précision de l’OCR.
Commençons directement.
Récapitulatif rapide: Comment fonctionne l’OCR?
Au cours de ces quelques dernières années, un plus grand nombre d’entreprises ont utilisé des logiciels d’OCR pour automatiser les flux de travail et les processus. L’OCR ayant la capacité de reconnaître le texte, d’extraire les informations et de les convertir en données lisibles par machine, l’extraction et la saisie manuelles des données ne sont plus nécessaires.
Mais comment cela fonctionne-t-il? L’OCR est capable de convertir une image en texte en examinant chaque forme individuelle d’un caractère et en la convertissant en la lettre la plus proche. L’étape suivante consiste à extraire les informations et à les stocker dans la base de données d’une entreprise. Les données sont alors prêtes à être utilisées pour les processus commerciaux suivants.
En général, la conversion d’images en texte permet aux entreprises d’accéder aux informations et de les trouver plus rapidement, car elles peuvent être recherchées.
Malheureusement, l’un des plus grands défis pour un moteur OCR est de lire les informations et d’extraire les données avec précision. Pour que le moteur OCR nous fournisse des données précises, nous pouvons l’aider un peu.
Mais que signifient des données exactes? Pour que nous soyons tous sur la même longueur d’onde, nous allons définir rapidement la précision de l’OCR ci-dessous.
Définir la précision de l’OCR
Il y a deux façons de définir ce qu’est un OCR fiable:
- Précision au niveau des caractères
- Précision au niveau des mots
Précision au niveau des caractères
La plupart du temps, la précision d’un moteur d’OCR est définie par le niveau des caractères. La précision d’un OCR est mesurée en fonction de la fréquence à laquelle un caractère est reconnu correctement et de la fréquence à laquelle un caractère est reconnu incorrectement.
En théorie, il est assez facile de mesurer la précision de l’OCR. Il suffit de comparer le résultat de l’OCR avec le texte original. Vous pouvez alors compter le nombre de caractères que l’OCR a correctement reconnus (précision au niveau des caractères) ou le nombre de mots que l’OCR a correctement détectés (précision au niveau des mots). C’est logique, non?
Précision au niveau des mots
Pour améliorer la précision au niveau des mots, les moteurs d’OCR utilisent des connaissances supplémentaires comme un dictionnaire ou une bibliothèque de mots. Ainsi, un mot incertain peut être « corrigé » par un mot présentant la plus grande similarité. Cela ne signifie pas pour l’instant que l’OCR a trouvé le bon mot.
C’est pourquoi il est si important de fournir au moteur d’OCR la meilleure qualité d’image possible. Vous vous demandez si la qualité de votre image est suffisante? Voyons quelques exemples qui illustrent différentes conditions de prise de vue.
Exemples de faible précision de l’OCR
Comme promis, nous voulons vous aider à éviter les erreurs courantes de saisie de données. C’est pourquoi nous avons ajouté les exemples suivants ci-dessous:
Exemple 1
Dans un environnement où tout va vite, il peut être tentant de prendre la photo de l’étiquette aussi vite que possible (par exemple, en montant les escaliers). Malheureusement, cela peut rapidement conduire à des images de mauvaise qualité, qui rendent difficile l’extraction précise des données par l’OCR.
Il est préférable de placer l’emballage sur une surface plane pour prendre une photo de qualité, ce qui favorise les performances du moteur OCR.


Exemple 2
Nous le savons tous, une fois jeté dans un sac ou une poche, un reçu est plié en des formes étranges. Si vous voulez ensuite le prendre en photo, il est très probable que l’OCR ne soit pas en mesure de lire les informations avec précision.
Il est plutôt conseillé de redresser le reçu aussi bien que possible, de le placer sur une table, puis de capturer l’image. Le résultat de l’OCR sera beaucoup plus précis.


En gardant ces exemples à l’esprit, nous souhaitons aborder quatre manières différentes d’améliorer la précision de l’OCR.
Les moyens d’améliorer la précision de l’OCR
Prenons l’exemple d’une entreprise de logistique. Souvent, le personnel est confronté à un environnement très rapide dans lequel prendre des images de haute qualité est un défi. Les employés ne sont pas en mesure de se concentrer sur la qualité de l’image car ils doivent prendre une photo rapidement et sur le pouce.
Il en résulte des difficultés pour l’OCR à reconnaître le texte et à lire les informations nécessaires. Il en résulte une sortie de données inexactes, ce qui rend extrêmement difficile l’utilisation de ces informations dans d’autres processus commerciaux. Dans le pire des cas, les entreprises peuvent perdre beaucoup d’argent à cause de données inexactes.
Mais il existe différentes façons d’améliorer la précision de l’OCR sans que les employés aient à fournir beaucoup d’efforts supplémentaires. Ces moyens sont les suivants:
- Amélioration de la qualité de l’image source
- Images prises dans un environnement « contrôlé »
- Commentaires de l’utilisateur en temps réel
- Solution d’OCR qui dessine des « boîtes de contour » pour indiquer la zone de capture des données
Examinons chaque point individuellement.
1. Amélioration de la qualité de l’image source
Celle-ci est assez évidente. Si la qualité de l’image source originale est améliorée, le taux de précision de l’OCR augmentera de manière significative. Vous vous demandez peut-être comment savoir si la qualité de l’image est suffisante.
C’est assez facile à tester. Si un œil humain est capable de voir clairement l’image source, il est possible d’obtenir de bons résultats d’OCR. La hauteur des caractères est un bon indicateur. Il est conseillé de ne pas laisser la hauteur des caractères descendre en dessous de 20 pixels, sinon il devient difficile de reconnaître les mots et les caractères.
Gardez à l’esprit que plus la qualité de l’image originale est élevée, plus il est facile de distinguer les caractères de l’arrière-plan, et donc plus la précision est élevée.
2. Des photos prises dans un environnement « contrôlé »
Un autre moyen d’améliorer la précision de l’OCR consiste à prendre la photo dans un environnement « contrôlé ». Cela signifie qu’il est important, par exemple, d’éviter les conditions trop sombres (comme une photo prise dans une pièce sombre ou à l’extérieur la nuit) et les surfaces inégales. De même, un environnement très encombré et une couleur similaire de l’arrière-plan et de l’image peuvent entraîner des difficultés et un faible taux de précision.
Il est préférable de prendre la photo d’un document sur une surface plane, comme un bon de livraison sur le sol d’un entrepôt.


3. Commentaire en temps réel des utilisateurs
Pour s’assurer que les employés peuvent prendre des photos de haute qualité et obtenir ainsi une précision élevée de l’OCR, il est conseillé d’utiliser une solution axée sur l’OCR qui exploite le retour d’information en temps réel de l’utilisateur.
Grâce au retour d’information en temps réel, les utilisateurs sont immédiatement avertis lorsque les conditions de prise de vue ne sont pas suffisantes et ont la possibilité de reprendre la photo. En outre, le retour d’information en temps réel guide l’utilisateur tout au long du processus de prise de vue, en veillant à limiter au maximum les erreurs.
Ce commentaire de l’utilisateur peut ressembler à: « Rapprochez-vous du document » « Trop de mouvements » ou « Conditions trop sombres ».
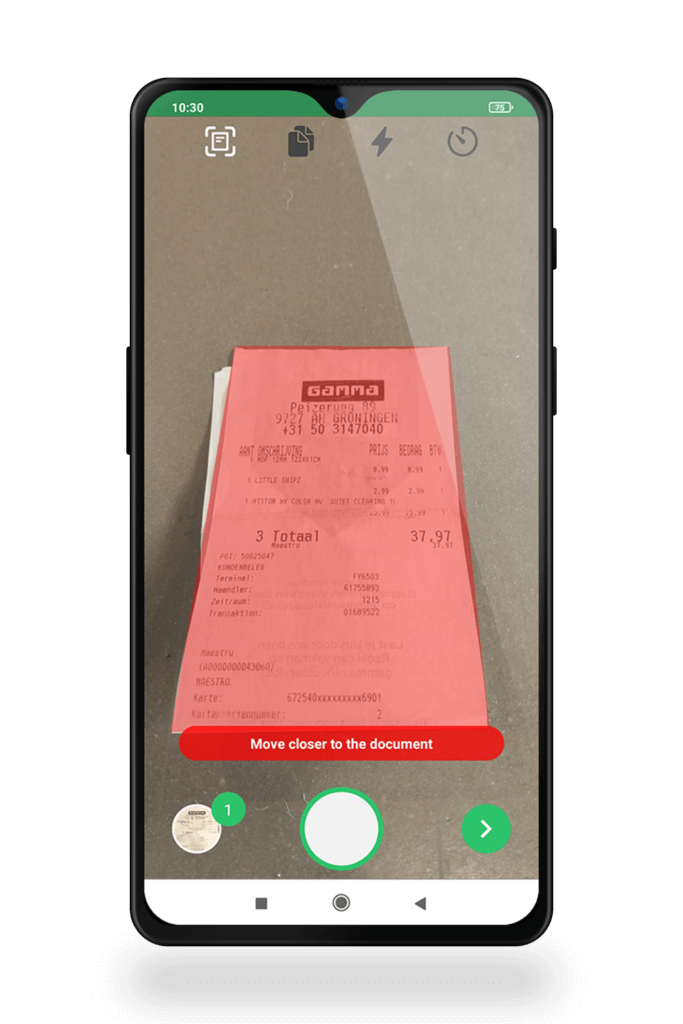
4. Solution d’OCR qui dessine des « boîtes de contour » pour indiquer la zone de capture des données
Certaines solutions d’OCR, comme le Doxis Document Scanning SDK, dessinent des « boîtes de contour » auxquelles le document doit être ajusté. Cela permet de garantir le bon angle de prise de vue et la bonne distance.
Une fois l’image est prise, le moteur d’OCR recherche automatiquement les erreurs et corrige les problèmes. Il peut s’agir, par exemple, de redresser une image (l’image est redressée et les angles corrigés) ou de réduire le bruit d’une image en ajustant la valeur d’intensité des pixels aux valeurs moyennes des pixels environnants pour améliorer la qualité de l’image.
En général, lorsque le texte de l’image est extrait, avec l’aide du traitement du langage naturel (NLP), la précision de l’extraction des données peut être encore améliorée. C’est ce qu’on appelle le ‘post-traitement’ de la sortie, dans lequel les données extraites sont comparées à une bibliothèque de caractères. Des contrôles grammaticaux sont effectués et des considérations contextuelles sont complétées pour obtenir le résultat le plus optimal.
Vous aimeriez travailler avec une solution d’OCR qui vous offre tout cela? Eh bien, avec Doxis, c’est possible. Laissez-nous vous convaincre de notre solution en vous montrant ce que nous offrons.
Doxis comme solution d’OCR fiable et précise
La solution de Doxis n’offre pas seulement un retour d’information en temps réel à l’utilisateur et des « boîtes de contour » utiles qui indiquent la taille de l’image. Avec notre SDK pour appareil photo, les employés peuvent scanner des images et prendre des photos en déplacement. En général, l’utilisation d’un SDK présente un grand avantage dans ce cas, car il peut être facilement intégré à votre propre application.
Notre SDK de numérisation de documents offre sept fonctionnalités qui facilitent grandement l’obtention d’une précision élevée de l’OCR. Ces fonctionnalités sont les suivantes:
- Retour d’information en temps réel pour les utilisateurs → Notre SDK donne un retour d’information en temps réel pour guider les utilisateurs lorsqu’ils prennent une photo, par exemple: « Rapprochez-vous du document », « Tenez l’appareil photo immobile » et « Conditions trop sombres ».
- Capture automatique → La capture automatique facilite grandement la numérisation des documents. Les utilisateurs n’ont pas besoin d’appuyer sur le bouton pour capturer une image. Ils peuvent simplement placer le document devant l’appareil photo et le SDK Doxis reconnaîtra automatiquement le document et prendra la photo pour vous.
- Recadrage → Notre SDK de numérisation reconnaîtra les bords du document et le recadrera automatiquement. Grâce à cette fonctionnalité, le processus d’obtention d’une image propre et de haute qualité devient beaucoup plus pratique. En plus de cela, le recadrage manuel est également possible pour recadrer l’image selon vos préférences.
- Réglage d’éclairage → Si un utilisateur se trouve dans un environnement plus sombre et n’a pas de source de lumière appropriée à proximité, il peut activer le flash via le contrôle du flash. Cela vous permettra d’obtenir l’image la plus claire possible.
- Amélioration de l’image → La qualité du document est améliorée par les fonctions de traitement d’image de notre caméra SDK afin de garantir la meilleure qualité d’image possible.
- Numérisation de documents uniques et multiples → Il est possible de numériser rapidement plusieurs documents et de les regrouper pour garantir un processus rapide et efficace.
- Anonymisation → Afin de se conformer au GDPR, il est interdit de stocker certaines informations dans les bases de données. Par conséquent, nous offrons la possibilité de masquer les données automatiquement.
Dans la vidéo, vous pouvez voir comment ces sept fonctionnalités se présentent en action.
En plus de cela, pour maximiser le succès de votre entreprise, nous sommes en mesure de développer des solutions personnalisées. Parce que nous faisons appel à l’apprentissage automatique et à l’IA, nous ne sommes pas dépendants des modèles. Cela permet à l’OCR de produire un résultat avec une plus grande précision. Cela signifie également que nous pouvons former notre OCR pour lire n’importe quel document dont vous avez besoin.
En outre, grâce à l’utilisation de l’apprentissage automatique et de l’intelligence artificielle (IA), nous pouvons constamment former notre solution, de sorte que nous pouvons répondre à vos besoins dès le départ.
Comme vous pouvez le constater, grâce aux fonctions d’amélioration d’image de Doxis, il est facile d’obtenir des résultats d’OCR fiables et précis. Voulez-vous également vous assurer que vos employés peuvent travailler avec une solution OCR fiable et précise?
Laissez-nous vous montrer ce que nous pouvons faire pour vous. Réservez simplement une démonstration gratuite ci-dessous ou contactez l’un de nos experts.