Depuis 2018, la législation européenne GDPR a amené les entreprises à être plus conscientes que jamais de leurs responsabilités en matière de stockage et de gestion des informations personnelles. Les entreprises doivent obtenir le consentement clair de leurs clients avant de pouvoir stocker des données personnelles sensibles à la vie privée. Cette législation a posé des défis aux entreprises jusqu’à aujourd’hui. Dans ce blog, nous expliquerons comment l’anonymisation automatique des documents peut aider votre entreprise à se conformer au GDPR.
Les défis de la conformité au GDPR
Pour de nombreuses entreprises, la législation GDPR a entraîné de nouveaux défis juridiques. Que faire des informations personnelles précédemment stockées dans votre base de données? Ces informations sont souvent stockées dans des archives physiques ou numériques, dans toutes sortes de bases de données et de types de documents. Le consentement du client pour la plupart de ces données fait défaut. Dans la plupart des cas, les entreprises ont trois possibilités:
- Supprimer tous les documents contenant des informations personnelles de la base de données.
- Essayez d’obtenir le consentement rétroactif des clients pour conserver les informations stockées.
- Anonymisez tous les documents contenant des informations personnelles dans votre base de données.
La première option est généralement difficile à déterminer. D’autres informations contenues dans vos documents stockés peuvent encore être pertinentes, ou même vitales, par exemple à des fins comptables ou juridiques. La deuxième option est loin d’être réalisable, car comment contacter une personne pour obtenir son consentement? C’est particulièrement difficile lorsque votre base de données est très importante. Et que se passe-t-il si vous n’obtenez pas de réponse ou de consentement? Les chances d’atteindre tout le monde et d’obtenir le consentement de chacun sont minimes.
Il nous reste donc la troisième option: l’anonymisation de tous les documents ou la pseudonymisation de tous les documents. Cette opération peut être effectuée sur des fichiers tels que les contrats, les passeports, les cartes d’identité, les factures et d’autres types de documents. Le problème est que cette opération manuelle peut représenter un travail énorme. Cela prendrait beaucoup de temps et vous auriez besoin d’une sorte d’interface logicielle pour le faire. Le risque d’erreur est également très élevé. Et si l’anonymisation des documents pouvait être réalisée automatiquement à l’aide d’un logiciel d’anonymisation précis? C’est là que Klippa vient à la rescousse!
Qu’est-ce que Klippa?
Klippa est un spécialiste de l’extraction de données pour les contrats, les factures, les reçus, les passeports, les pièces d’identité et autres documents. Notre logiciel intelligent est utilisé pour extraire des informations telles que des noms, des dates et des montants à partir de documents. Les exemples d’utilisation sont le traitement des factures, la gestion des dépenses et l’automatisation des processus KYC.
L’extraction correcte des données commence par un logiciel de reconnaissance de texte et la localisation des informations dans les documents. Cette technologie étant déjà au cœur de notre logiciel, Klippa a décidé d’étendre ses services aux logiciels d’anonymisation et de pseudonymisation des documents (également connus sous le nom de masquage des données).
Comment fonctionne-t-il?
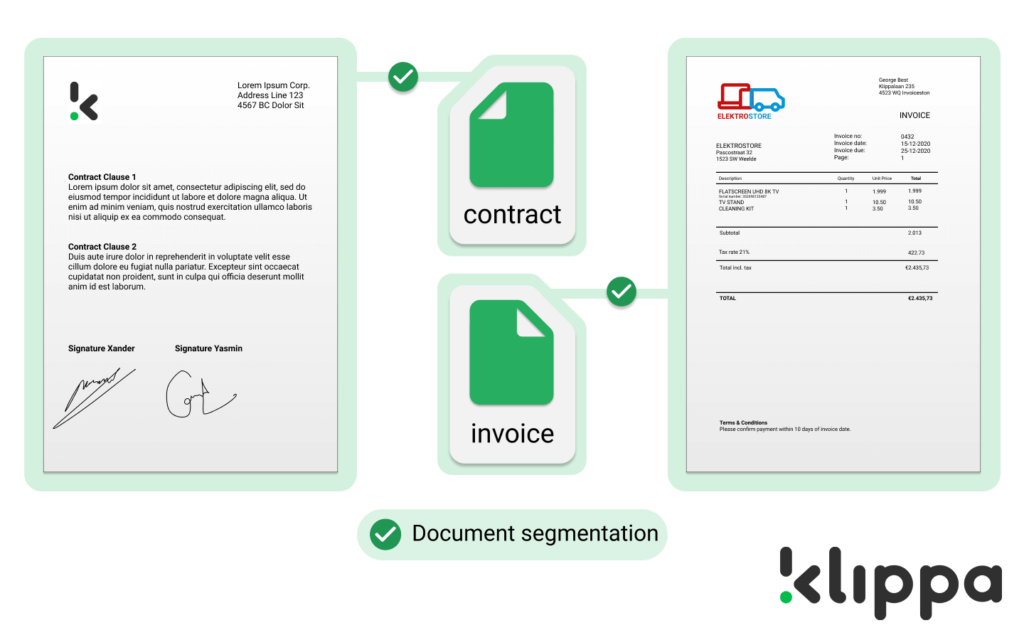
Klippa met en place un serveur sécurisé dans le pays de votre choix. Vous pouvez envoyer vos documents à ce serveur par courrier électronique, par API ou par téléchargement manuel. Dès que les documents sont reçus, le logiciel Klippa entre en action. La première étape du processus s’appelle la segmentation des documents. Dans cette étape, le logiciel Klippa utilise un modèle d’apprentissage automatique pour déterminer le type de documents envoyés et les répartir dans des boîtes virtuelles. Dans cette étape, Klippa sépare par exemple les contrats des factures.
Lors de l’étape suivante, un ensemble unique de règles est utilisé pour chaque document classifié. Ces règles déterminent les modifications à apporter à chaque type de document et garantissent que toutes les données que vous souhaitez rendre anonymes le sont. Les autres informations ne sont pas modifiées. Toutes les données pertinentes sont sauvegardées pour que votre entreprise puisse les utiliser à tout moment.

Anonymisation des informations personnelles dans les documents
Maintenant que les types de documents et les informations pertinentes pour des cas d’utilisation spécifiques sont clairement définis, il est temps pour le logiciel de reconnaissance intelligente de faire son travail. Étape par étape, le logiciel Klippa prend un document, le convertit en format lisible et trouve des types d’informations prédéfinis utilisant la reconnaissance des formes. Les modèles identifiés (informations personnelles) sont ensuite extraits du document et remplacés par un identifiant prédéfini.
Il s’agit d’un élément dépourvu de signification, comme un espace vide, une chaîne de “-” ou une variable telle que “NOM” ou “NUMÉRO DE TÉLÉPHONE”. Selon vos préférences, les valeurs d’origine sont supprimées du document et ne peuvent être récupérées par personne. Enfin, tous les documents sont stockés et renvoyés vers la base de données du client. Le résultat? Une base de données entièrement numérique et anonymisée avec des documents conformes au GDPR!

Si nécessaire, une interface de contrôle peut être mise en place avant que les documents ne soient définitivement marqués comme “anonymes”. Dans cette interface, les employés de votre organisation peuvent vérifier tous les documents ou effectuer des contrôles sur la base d’un échantillon pour obtenir le sceau d’approbation final.
Votre organisation est-elle confrontée à des défis dans les domaines de l’extraction de données, de l’OCR ou de l’anonymisation? Contactez Klippa et nous vous aiderons à relever ces défis de manière rentable.