
La numérisation a le vent en poupe, car de nombreuses entreprises cherchent de meilleurs moyens de traiter et de stocker les documents. Les archives traditionnelles sont transférées dans le cloud et davantage de documents sont traités dans des flux de travail numériques.
Si la numérisation présente des avantages fabuleux, il y a quelques défis à prendre en compte. Le plus important est de se conformer au strict Règlement Général sur la Protection des Données (RGPD) imposé en mai 2018.
Bien que ces règlements améliorent la protection des données et clarifient les responsabilités des organisations, ils n’empêchent pas totalement les violations de données.
En fait, les coûts résultant des violations de données sont passés de 3,86 millions de dollars US à 4,24 millions de dollars US, soit le coût total moyen le plus élevé enregistré depuis 17 ans.
Les techniques des cybercriminels étant de plus en plus sophistiquées, les entreprises doivent trouver des solutions pour mieux protéger les données stockées. Une excellente solution pour minimiser les risques de violation des données et assurer la conformité à la RGPD est le masquage des données.
Ce blog couvrira ce qu’est le masquage des données, comment il fonctionne, et comment Klippa peut automatiser le masquage des données pour vous.
Qu’est-ce que le masquage de données ?
Le masquage des données, également connu sous le nom d’anonymisation des données, de rédaction des données ou d’obscurcissement des données, est une technique de sécurité permettant de masquer les données sensibles. Ces données sont par exemple des numéros de Sécurité Sociale ou des numéros de carte de paiement.
Le masquage des données est appliqué pour éviter de compromettre les informations sensibles et réduire les risques de sécurité tout en se conformant aux réglementations sur la confidentialité des données.
Par exemple, de nombreuses organisations doivent effectuer des contrôles de connaissance du client (KYC) dans le cadre des processus d’accueil des clients. En effectuant ces contrôles pour valider l’identité des clients, les entités doivent traiter les documents d’identité.
Cependant, certaines informations telles que les numéros de sécurité sociale ne peuvent pas être conservées en vertu de la RGPD. Bien qu’il existe des exceptions, la majorité des organisations doivent anonymiser ou obscurcir les données pour assurer la conformité.
Actuellement, le masquage des données gagne en popularité, et on estime que l’industrie passera de 483,90 millions de dollars américains en 2020 à 1044,93 millions de dollars américains d’ici 2026.
Types de données sensibles
Le masquage des données peut être utilisé pour protéger de nombreux types de données. Les types les plus courants comprennent :
- Les informations d’identification personnelle (PII)
- Informations de santé protégées (PHI)
- Informations sur les cartes de paiement (PCI-DSS)
- Propriété intellectuelle (ITAR)
- Loi sur la portabilité et la responsabilité de l’assurance maladie (HIPAA)
Il est essentiel de savoir comment fonctionne le masquage des données et d’identifier les types et techniques qui conviennent à vos objectifs commerciaux. Ce n’est qu’alors qu’il sera plus facile d’utiliser le masquage des données pour protéger les données sensibles.
Voyons comment fonctionne le masquage des données.
Comment fonctionne le masquage des données ?
Le point de départ consiste à identifier toutes les données sensibles que votre organisation détient ou traite. Il est essentiel de garder à l’esprit que les données peuvent se présenter sous de nombreuses formes : courriels, télécopies, feuilles Excel, informations de base de données et documents scannés tels que les passeports, pour n’en citer que quelques-unes.
Une fois l’identification des données terminée, il convient d’appliquer des algorithmes et des techniques de masquage des données. Les organisations peuvent supprimer, noircir, remplacer ou chiffrer les données sensibles en fonction du cas d’utilisation et des exigences légales.
Prenons l’exemple d’une feuille Excel contenant des données clients, y compris des informations sensibles comme des numéros de compte bancaire. Lors du stockage de ce type d’informations, le masquage des données peut contribuer à renforcer la sécurité de vos données.
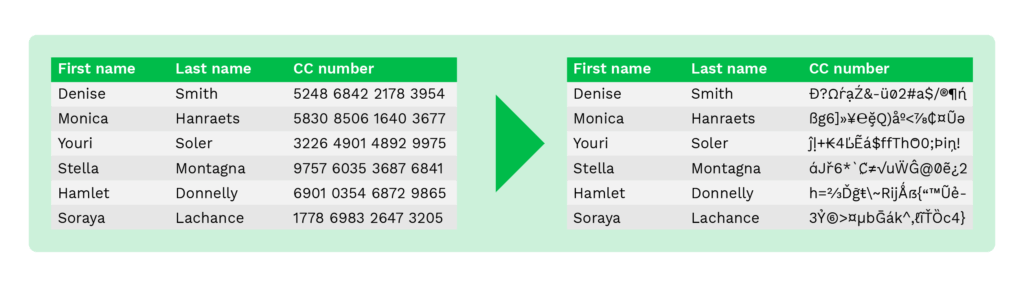
Par exemple, au lieu de révéler des données sensibles, les numéros de compte bancaire peuvent être remplacés par un « x », et seuls les quatre derniers chiffres sont affichés.
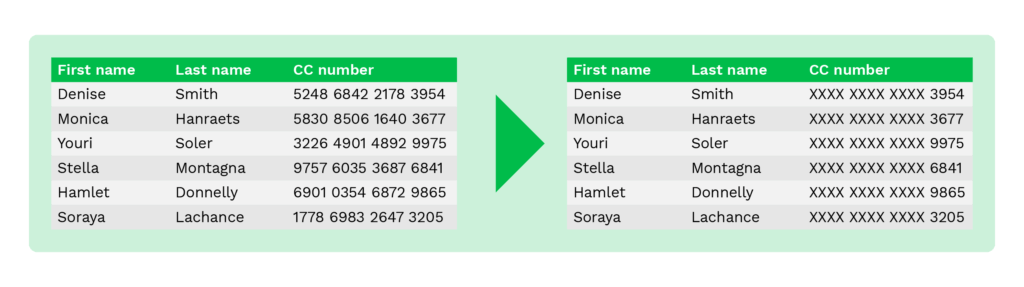
Même si seuls les quatre derniers chiffres sont affichés, votre personnel de back-office est toujours en mesure de vérifier la propriété du compte bancaire. Ainsi, les fraudeurs ne peuvent pas utiliser le numéro de compte bancaire, même s’ils obtiennent les informations.
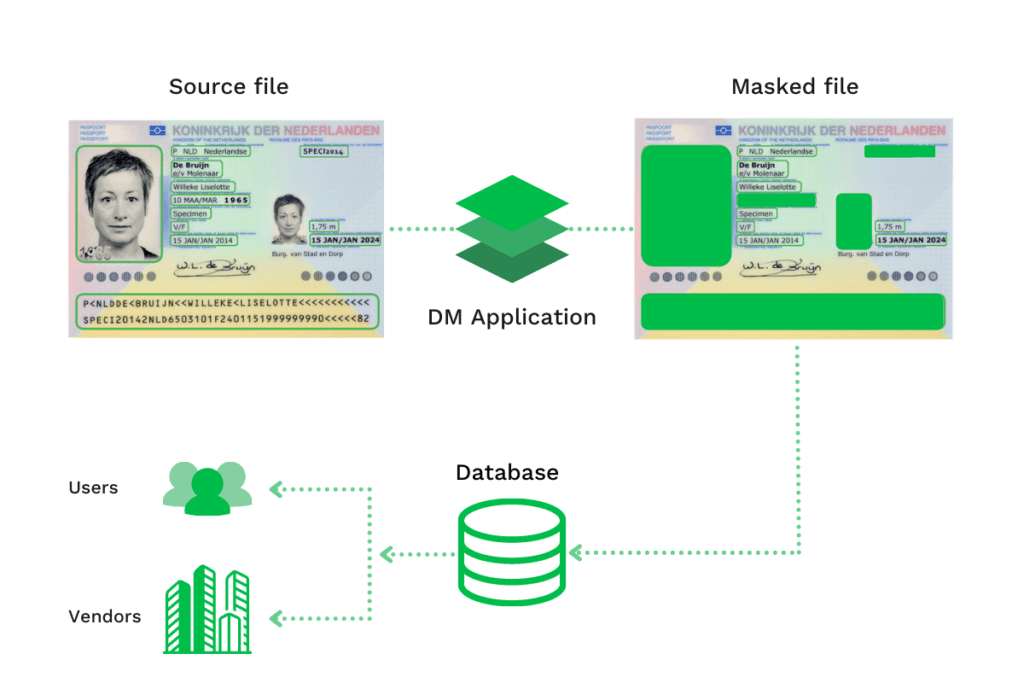
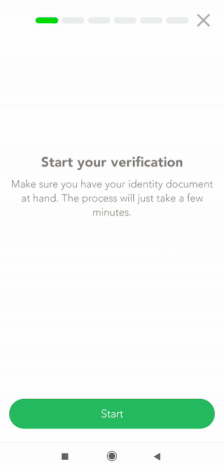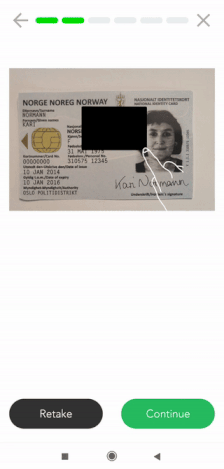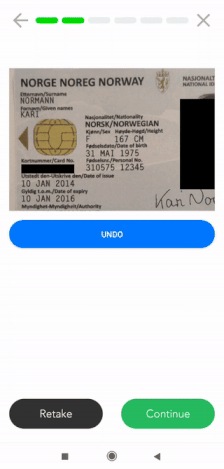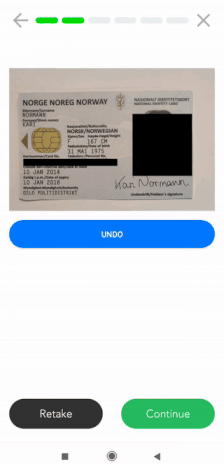
Un autre exemple pourrait être le masquage des informations sur le scan d’un document d’identité lors d’un processus KYC. Ci-dessous, vous pouvez voir un avant et un après d’un passeport masqué pour assurer la conformité au RGPD.

Une approche similaire du masquage des données peut être appliquée aux numéros d’assurance, aux numéros de carte de paiement ou aux numéros de sécurité sociale, pour n’en citer que quelques-uns.
Maintenant que nous avons expliqué comment fonctionne le masquage des données, examinons deux types différents.
Types de masquage des données
Il existe plusieurs types de masquage des données, dont l’utilisation dépend principalement des ressources, des cas d’utilisation et des fournisseurs. Les deux types courants de masquage des données sont le masquage statique et le masquage dynamique des données.
Nous allons développer la différence dans les paragraphes suivants.
Masquage statique des données
Le masquage statique des données (MDS) est souvent nécessaire pour les tests logiciels afin de remplacer les données sensibles en modifiant les données stockées sur un ordinateur portable, un disque dur ou dans une base de données. Grâce au masquage statique des données, les entreprises peuvent se conformer aux réglementations relatives aux données et à la confidentialité telles que la RGPD, PCI, PHI, PII, ITAR et HIPAA.
Cette architecture de masquage des données commence par la copie originale, à partir de laquelle les données sensibles sont masquées avant de les envoyer plus loin pour être traitées (dans une base de données, un logiciel, etc.).
Grâce à cette approche, les informations sensibles sont remplacées de façon permanente afin de garantir la conformité aux réglementations sur la confidentialité des données et la protection contre les violations de données.
Masquage dynamique des données
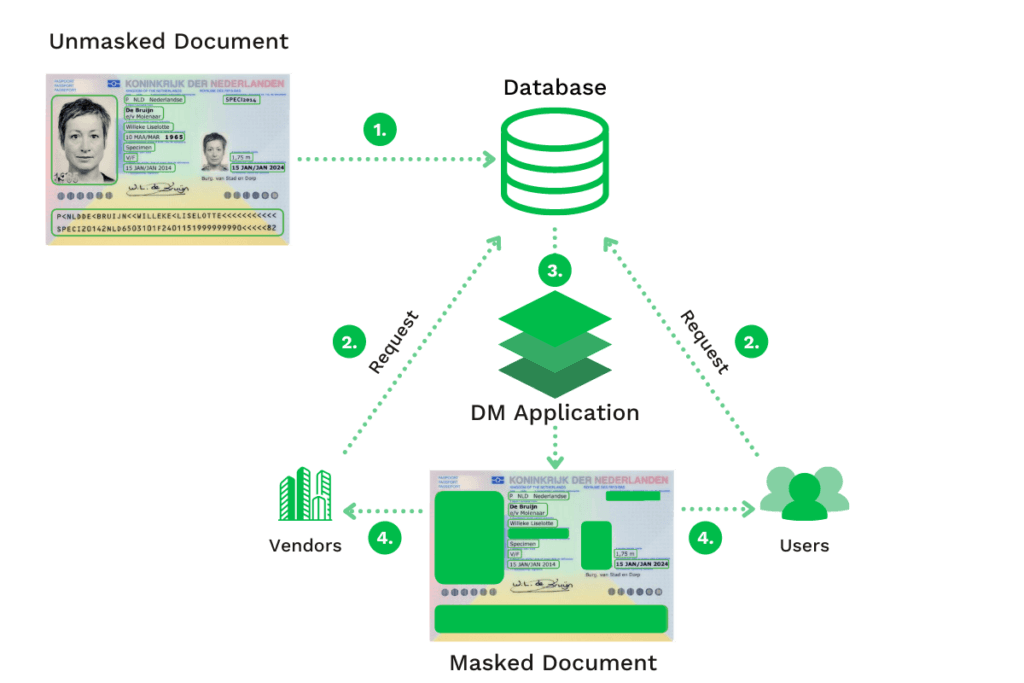
L’architecture de masquage dynamique des données (DDM) diffère de l’architecture statique. Elle est utilisée pour masquer les données sensibles en transit (c’est-à-dire utilisées activement), en laissant la copie originale inchangée. Avec cette approche, les données non masquées sont visibles dans la base de données actuelle.
Le DDM est principalement utilisé pour traiter les demandes de renseignements des clients et les dossiers médicaux dans le cadre d’applications de sécurité basées sur les rôles. Dans certains secteurs, il est nécessaire de cacher des données sensibles à des utilisateurs spécifiques.
Avec le DDM, les organisations peuvent utiliser les requêtes modifiées (c’est-à-dire les demandes de données) qui arrivent dans la base de données d’origine pour masquer dynamiquement les données et les transmettre à la partie qui les demande.
Ce type de masquage des données est souvent utilisé lorsque les organisations envoient des données à un fournisseur tiers ou à des parties prenantes internes, non-autorisées à voir des données sensibles. Ces données peuvent être des numéros de sécurité sociale (SSN) ou des numéros de cartes de paiement.
Maintenant que les types les plus courants de masquage des données sont couverts, examinons les techniques de masquage des données.
Techniques de masquage des données
Le masquage des données s’accompagne de diverses techniques, qui sont expliquées ci-dessous.
Substitution
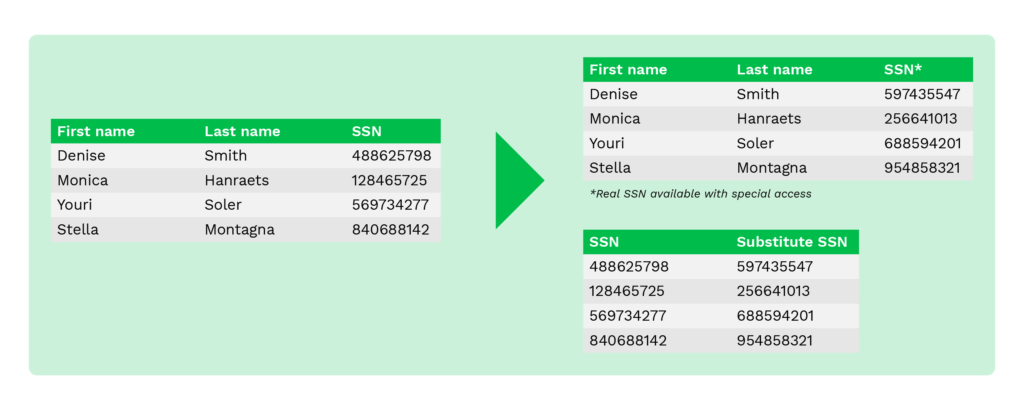
La substitution, également appelée pseudonymisation, est une technique utilisée pour remplacer les données originales par des données aléatoires provenant de fichiers de consultation fournis ou personnalisés. Elle est utile lorsque les organisations doivent préserver l’aspect authentique des données tout en masquant les données sensibles.
Cette technique peut protéger efficacement les données contre les violations et aider à contrôler l’accès interne.
Mélange de données
Le mélange est une technique similaire à la substitution. Elle est également utilisée pour remplacer des données originales par d’autres données qui semblent authentiques. La différence est que les entités d’une même colonne sont mélangées de manière aléatoire.
Par exemple, les organisations peuvent utiliser cette technique pour mélanger de manière aléatoire les colonnes de noms d’employés de plusieurs enregistrements d’employés. Cette technique peut faire l’objet d’une ingénierie inverse si quelqu’un met la main sur l’algorithme de brassage.
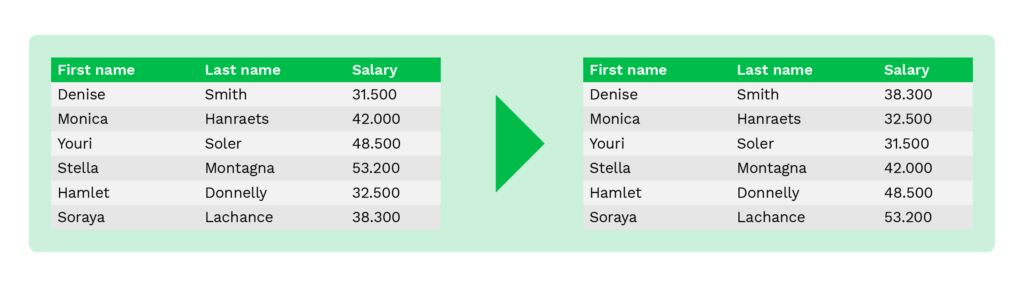
Calcul de la moyenne
Le calcul de la moyenne est une méthode permettant de remplacer les valeurs originales par une valeur moyenne des colonnes du tableau. Par exemple, au lieu de montrer les salaires ou les soldes de comptes des individus, l’initiateur montre seulement la valeur moyenne données inscrites.
Cette méthode permet de conserver la valeur agrégée et est couramment utilisée à des fins d’analyse statistique ou de collecte de données par les institutions financières.
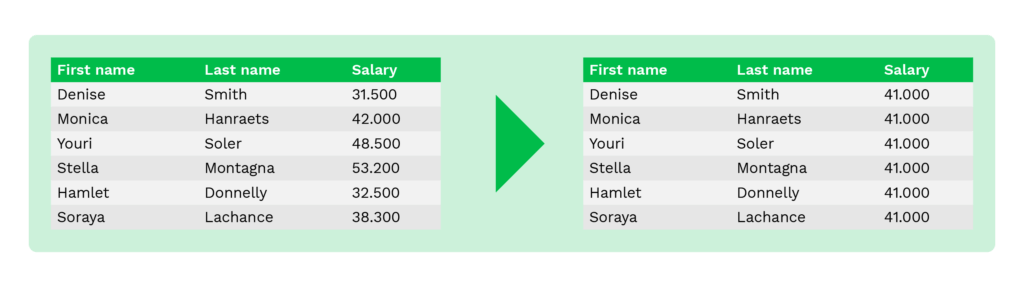
Suppression
La suppression est une technique qui consiste à remplacer des données sensibles par une valeur nulle afin d’empêcher les utilisateurs non autorisés de voir les données d’origine. Elle consiste simplement à supprimer l’information ou à la remplacer par une valeur vide sur les documents.

Dans certains cas d’utilisation, les informations figurant sur certains documents sont entièrement supprimées, comme la date de naissance sur les CV. Souvent, cela est fait pour éliminer les risques de pratiques d’embauche non éthiques.

Rédaction de données (occultation)
La rédaction de données, également connue sous le nom de blacklining, est une méthode similaire à l’annulation, car seule une partie des données originales est masquée.
Par exemple, seuls les quatre derniers chiffres du numéro de la carte de paiement sont montrés aux clients dans l’environnement d’achat en ligne afin de prévenir la fraude.
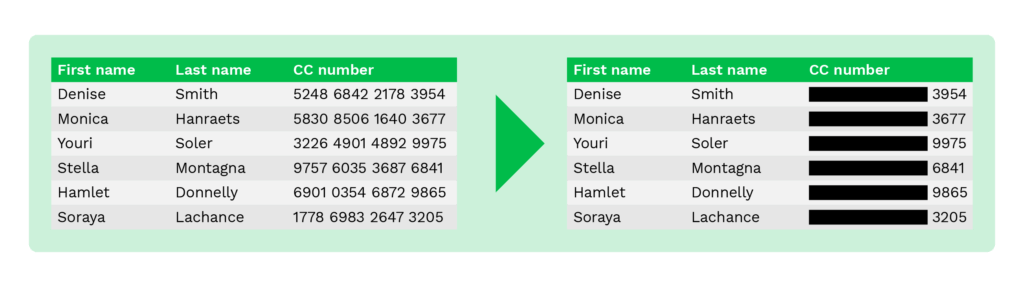

La même méthode peut être appliquée à tout document contenant des informations sensibles sur le plan de la vie privée. Vous pouvez voir ci-dessous l’exemple d’un passeport, où plusieurs champs sont occultés.
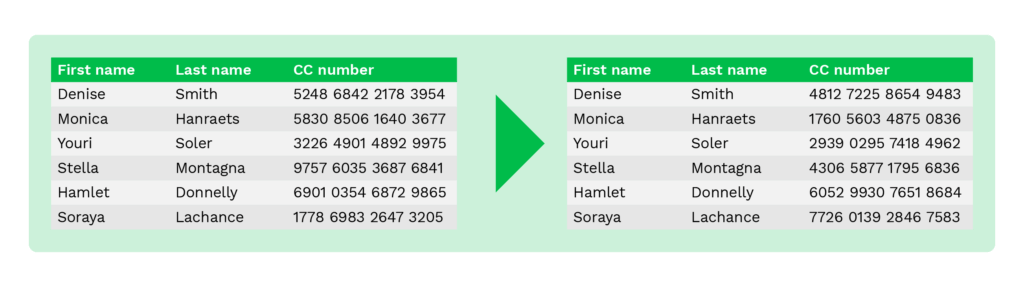
Brouillage de données
La technique de brouillage des données est utilisée pour modifier des données en réorganisant de manière aléatoire l’ordre des caractères ou des chiffres à l’aide d’un algorithme spécifique.
Les données originales ne peuvent plus être obtenues à l’issue du processus, car elles sont brouillées.

Le cryptage des données
Le cryptage des données est une technique qui ne permet d’accéder aux données qu’avec la clé de décryptage.
Il s’agit de l’algorithme de masquage des données le plus complexe et le plus sûr. En plus de sa complexité, il nécessite une gestion appropriée des clés de cryptage pour garantir la sécurité.

Pourquoi le masquage des données est-il important ?
Depuis l’imposition de la RGPD, la protection des données est devenue la priorité absolue pour de nombreuses entreprises. Par conséquent, les organisations ont trouvé essentiel de mettre en œuvre le masquage des données comme l’un des outils pour protéger leurs données sensibles.
Alors pourquoi le masquage des données est-il nécessaire ? En principe, le masquage des données offre aux organisations un moyen sûr de créer des versions alternatives de données utilisables et bien sécurisées.
Grâce au masquage des données, les organisations peuvent bénéficier des avantages suivants.
Conformité aux lois sur la confidentialité des données
Le masquage des données aide les entreprises à se conformer aux lois et réglementations sur la confidentialité des données. Grâce aux différentes techniques de masquage des données disponibles, de nombreuses organisations peuvent éliminer l’exposition des données sensibles.
Pourtant, toutes les organisations n’utilisent pas le masquage des données pour se conformer à la RGPD.
Par exemple, en 2020, le grand détaillant de vêtements de mode H&M a été condamné à une amende de 35 millions d’euros en raison de violations du RGPD. L’incident impliquait que la direction accède à des données sensibles telles que les croyances religieuses et les questions familiales par le biais d’enregistrements de réunions. Ces enregistrements étaient utilisés comme base pour évaluer les performances des employés.
Cet incident aurait pu être évité en expurgeant toutes les données sensibles des enregistrements documentés de ces réunions.
Protection contre la violation des données
One of the main benefits of data masking is to make data useless for cyber attackers while preserving its usability for the organization. Even if the data is breached due to cyber attacks, many data masking techniques can prevent intruders from gaining sensitive information.
En 2018, Panera Bread aurait fait fuir au moins 37 millions de dossiers de clients en raison d’un manque de contrôle d’accès et de mesures de sécurité. Des données telles que des emails personnels, des adresses et des informations sur les cartes de crédit étaient accessibles par crawling.
Pourtant, là encore, ce scénario aurait pu être évité grâce à diverses techniques de masquage des données.
Réduction des risques liés à la sécurité des données
De nombreuses entreprises collaborent avec des tiers et des fournisseurs dans leur périmètre, à qui certaines données sont transmises. En outre, les employés et autres parties prenantes internes peuvent également avoir accès aux données.
En d’autres termes, il existe toujours un risque de perte de données. Le masquage des données peut fournir les moyens de protéger les données contre les personnes ou les parties qui ne sont pas autorisées à les voir.
Seules les fausses données peuvent être vues, à moins que l’autorisation de démasquer les données ait été accordée. Ainsi, l’anonymisation des données peut réduire les risques internes de sécurité des données et les fuites de données.
Dans l’ensemble, le masquage des données offre des avantages impressionnants, qui peuvent aider les entreprises à obtenir un avantage concurrentiel. Mais quels sont les cas d’utilisation courants ? Jetons un coup d’œil à certains d’entre eux.
Cas d’utilisation du masquage des données
Il existe de nombreux cas d’utilisation du masquage des données, notamment les suivants :
- Le masquage des numéros de cartes de paiement
- Anonymisation des numéros de sécurité sociale
- Rédaction de curriculum vitae
- Masquage des données pour l’archivage numérique
- Rédaction ou cryptage d’informations de santé personnelles
- Rédaction ou cryptage de documents gouvernementaux
- Rédaction de documents juridiques et d’affaires judiciaires publiques
- Anonymisation d’enregistrements de réunions
- Contrôle d’accès interne
- Cryptage de documents relatifs à la propriété intellectuelle
- Partage de données avec des fournisseurs tiers
Nous examinons ci-dessous les quatre premiers points plus en détail.
Mise à l’index des numéros de cartes de paiement
Dans certaines circonstances, un membre de votre organisation peut avoir besoin d’accéder aux informations relatives à une carte de crédit ou de paiement. Par conséquent, l’utilisation du masquage des données pour masquer les quatre derniers chiffres du numéro de carte peut empêcher l’exposition à des éléments sensibles tels que les numéros de carte de paiement.
Il s’agit d’une méthode très répandue dans les banques et autres institutions financières pour traiter les informations de paiement de leurs clients. En noircissant le numéro de carte de paiement, les organisations peuvent garantir la conformité avec la norme PCI-DSS.

Anonymisation des numéros de sécurité sociale
Les informations telles que le SSN figurant sur les documents d’identité tels que les passeports et les cartes d’identité sont très sensibles. Souvent, les organisations autres que les institutions gouvernementales ne sont pas autorisées à stocker le SSN dans leur base de données.
Aux Pays-Bas, le burgerservicenummer (BSN) est l’équivalent du SSN. Le BSN est un numéro de service personnel unique utilisé pour identifier chaque citoyen enregistré. Par exemple, le BSN est utilisé par les institutions gouvernementales pour trouver les données de chaque citoyen, souvent à des fins fiscales.
Les SSN et BSN sont strictement encadrés par la RGPD car ils appartiennent à des « catégories particulières de données à caractère personnel. » Bien sûr, il existe des cas où le stockage de ces données est autorisé. Mais seulement avec une exception légale spéciale ou le consentement de la personne.
Par conséquent, il est courant d’anonymiser les numéros SSN ou BSN à l’aide de diverses techniques de masquage des données.

Rédaction de curriculum vitae
Malgré toutes les formations visant à réduire les préjugés dans le processus d’embauche, un grand nombre de recruteurs sont coupables de fonder leurs décisions sur différents préjugés. Malheureusement, il est encore courant de penser que si deux candidats ont des compétences et une expérience similaires, c’est le plus attrayant qui sera engagé.
Bien qu’il soit illégal de pratiquer une quelconque discrimination dans le processus de recrutement, de nombreuses entreprises le font encore. En fait, 20 % des entreprises américaines sont à l’origine de la moitié des cas de discrimination.
Les organisations ont commencé à rédiger des CV afin d’éliminer les préjugés et la discrimination au début du processus de recrutement. Selon le rapport de HRO Today, les champs les plus courants qui sont expurgés des CV sont les suivants :
- L’adresse du domicile
- Nom
- Photo (attractivité, sexe)
Grâce au masquage des données, les recruteurs sont mieux armés pour évaluer les candidats uniquement sur la base de leurs compétences et de leur expérience. Il est important de noter que les recruteurs ne sont qu’humains, après tout.

Masquage des données pour l’archivage numérique
Le stockage de données sur papier n’est plus une option pour de nombreuses organisations. Les raisons qui poussent les organisations à s’orienter vers la numérisation avec l’avancée de la technologie sont les suivantes :
- Un énorme arriéré de données non organisées.
- Contrôle d’accès interne
- Des économies de temps et d’argent
- Respect de l’environnement
- Conformité à la RGPD
- Accès facile aux données
Si l’archivage des données peut être très bénéfique, son défi consiste à respecter les obligations légales concernant les lois sur la confidentialité des données. À cet égard, le masquage des données est une solution sûre et solide pour assurer le respect de la RGPD.
Avant l’archivage, les entreprises peuvent simplement utiliser le masquage des données pour expurger toutes les parties sensibles telles que les noms, les numéros de patients et les numéros de sécurité sociale des documents ou les remplacer par des données structurellement identiques (même quantité de chiffres ou de caractères).
Les organisations ont adopté cette méthode dans des secteurs tels que le droit et la santé, pour n’en citer que quelques-uns.
Maintenant que nous avons abordé quelques-uns des cas d’utilisation, examinons la transformation de la rédaction de documents.
Transformation de la rédaction de documents
D’aussi loin que l’on se souvienne, la rédaction manuelle de documents a été utilisée dans divers secteurs. Il s’agit d’une tâche fastidieuse qui présente de nombreux problèmes sous-jacents. L’un des principaux problèmes est l’évolutivité.
Le personnel humain a du mal à maintenir la précision, l’efficacité et la cohérence dans le temps. Il en résulte des délais d’exécution lents, des clients insatisfaits et des coûts élevés.
Prenons l’exemple du secteur juridique. Un flux de travail typique implique des équipes d’avocats et de parajuristes qui passent des centaines d’heures à examiner une grande pile de documents.
Au lieu d’utiliser leurs connaissances et leur expérience pour effectuer des tâches utiles, ils sont chargés d’ajouter, de modifier et de supprimer les parties occultées dans les documents. Sans parler des coûts d’embauche de ce personnel.
L’ajout de personnel supplémentaire à mesure que le volume de documents augmente fait grimper les coûts en flèche. Il faut donc se rendre à l’évidence. L’expurgation manuelle des documents n’est pas une option évolutive (du moins pas si vous voulez être rentable).
Heureusement, il est possible d’automatiser la rédaction de documents grâce à la technologie actuelle. Les organisations peuvent tirer parti de deux méthodes : le masquage des données entièrement automatisé et le masquage des données assisté par l’homme.
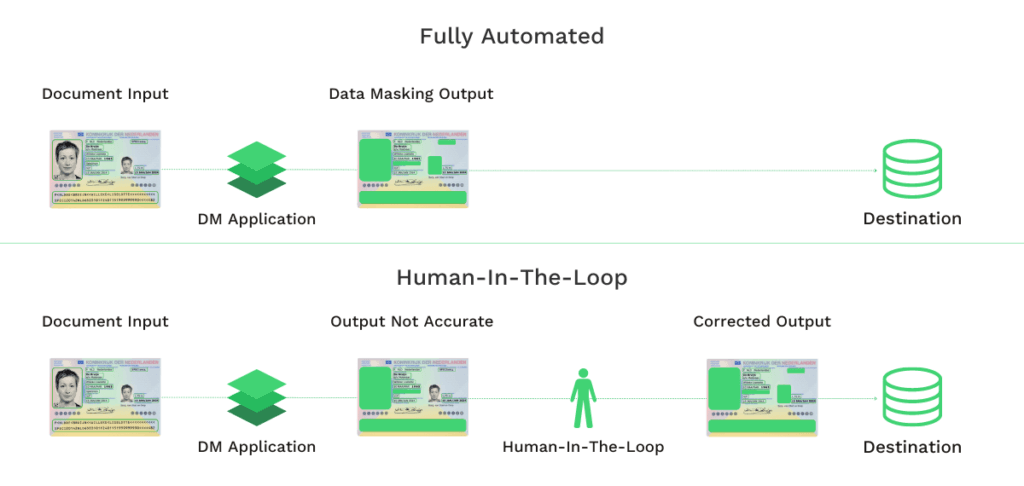
Masquage des données entièrement automatisé
Dans une solution de masquage des données entièrement automatisée, l’intervention humaine n’est pas nécessaire. Grâce à des technologies telles que la reconnaissance optique de caractères (OCR) alimentée par l’IA, il est possible de reconnaître, de localiser et de supprimer automatiquement le champ d’information des documents requis.
Il vous suffit d’alimenter le moteur OCR avec les documents à masquer, et il fait le reste. Cette option libère vos ressources humaines, que vous pouvez affecter à des tâches plus complexes. De cette façon, vous pouvez maximiser l’efficacité de votre organisation.
Masquage des données assisté par l’homme
L’autre solution consiste à utiliser l’automatisation assistée par l’homme, autrement dit, l’automatisation par l’homme dans la boucle (HITL). Cette solution utilise l’IA pour l’automatisation et permet au personnel humain d’effectuer les contrôles finaux pour vérifier l’achèvement du masquage des données.
L’avantage de l’automatisation par l’homme dans la boucle est qu’elle permet une plus grande précision dans la rédaction des documents. Ce n’est pas une surprise puisque la solution HITL combine le meilleur de l’intelligence artificielle avec le meilleur de l’intelligence humaine.
Parfois, il peut y avoir des problèmes avec la technologie (qualité de l’image, qualité du document, etc.), ce qui l’empêche d’effectuer les tâches de masquage des données. Par conséquent, l’examen des données en entrée ou en sortie peut contribuer à réduire les erreurs.
Créer l’une ou l’autre de ces solutions à partir de zéro est difficile, coûteux et prend du temps. C’est pourquoi, chez Klippa, nous avons décidé de combiner notre technologie OCR avec des fonctionnalités de masquage de données pour aider diverses organisations. Nous pouvons aider nos clients à automatiser le masquage des documents à grande échelle.
Pourquoi votre entreprise devrait-elle automatiser le masquage des données ? Plongeons dans les avantages qui en découlent.
Avantages du masquage automatique des données
Si les organisations peuvent protéger les données contre les fuites et assurer la conformité RGPD avec le masquage des données, cela ajoute de nombreux autres avantages. Ces avantages sont notamment :
- Des délais d’exécution plus rapides – L’automatisation de la rédaction de documents ou de données permet à votre personnel de se concentrer sur des tâches plus importantes. Il faudrait moins de personnes pour effectuer ces tâches fastidieuses et accélérer les délais d’exécution.
- Précision – Avec une solution automatisée de masquage des données qui utilise l’IA, les entreprises peuvent obtenir une plus grande précision, tout simplement parce que les machines et les ordinateurs ne se fatiguent pas.
- Rapidité – Avec une solution automatisée, le processus de rédaction des données peut aller jusqu’à 90 fois plus vite. Vous pouvez voir un calcul simplifié dans la section suivante.
- Réduction des coûts – Grâce à l’efficacité et à la précision accrues obtenues avec l’IA, les organisations peuvent réaliser des économies considérables (heures de travail, réduction des erreurs, etc.).
- Évolutivité – Il y a une limite au nombre de documents qu’un employé moyen peut occulter. L’automatisation du masquage des données offre aux entreprises un moyen de rédiger des documents à l’échelle sans augmenter les coûts opérationnels.
Il semble qu’une solution de masquage des données automatisée offre de nombreux avantages aux entreprises. Mais qu’est-ce que cela signifie pour vous en termes d’activité ?
Pour vous rendre la chose tangible, nous avons fourni un exemple de calcul d’un retour sur investissement (ROI) potentiel dans la section suivante.
Le retour sur investissement d’une solution de masquage automatique des données
Supposons que vous disposiez de 100 000 documents d’identité dont vous devez supprimer les numéros de sécurité sociale. Supposons également qu’en moyenne, un employé de bureau expérimenté peut masquer manuellement deux documents d’identité par minute. Cela fait 120 documents d’identité en une heure. Estimons le coût de l’embauche d’un employé expérimenté (y compris l’assurance, le salaire horaire et les autres coûts) à 25,00 € par heure.
Pour vous assurer que la rédaction est effectuée correctement, vous devrez engager un autre employé de bureau pour vérifier les documents rédigés. Supposons qu’un employé identique puisse revérifier l’exactitude de chaque rédaction au rythme de 360 documents d’identité par heure.
Le coût total de la rédaction manuelle de 100 000 documents d’identité s’élèverait à plus de 27 700 euros. Les heures de travail des employés nécessaires pour mener à bien ce projet s’élèvent à plus de 1 110.
Si l’on compare ce chiffre à celui de la solution Klippa, qui permet de traiter 10 000 documents par heure, le projet peut être réalisé en 10 heures. Cela représente une économie d’environ 1 100 heures de travail.
À titre d’estimation, il en coûterait à votre organisation 4 000 € pour réaliser ce projet avec notre solution (en fonction du volume et du type de document). Vous pourriez réaliser ce projet plus de 90 fois plus vite et avec un retour sur investissement de 6,9.

Essayez vous-même notre calculateur du retour sur investissement du masquage des données !
Masquage des données avec Klippa
Klippa a été fondée en 2015 dans le but d’aider les entreprises à numériser et à automatiser le traitement des documents à l’échelle en utilisant des technologies de pointe. Grâce à des technologies telles que le machine learning, l’IA et l’OCR, nous sommes en mesure d’aider nos clients de diverses industries à travers le monde.
Notre solution de traitement intelligent des documents (IDP), Klippa DocHorizon, est conçue pour aider les organisations à automatiser intelligemment le traitement des documents ; numériser, extraire, classer, vérifier et anonymiser les données de divers documents.
Avec Klippa DocHorizon, votre organisation réduit ses délais d’exécution, ses coûts et les erreurs humaines tout en protégeant les données sensibles.
Bien que notre logiciel OCR basé sur l’IA comprenne des fonctions de masquage des données, nous avons développé une API de masquage des données pour permettre des intégrations avec les systèmes existants de gestion des documents, de planification des ressources de l’entreprise (ERP) ou de dossiers médicaux électroniques (EHR) de nos clients.
En plus de l’API, nous avons développé un SDK de masquage des données pour permettre aux entreprises de tirer parti de notre technologie dans leur système.
API de masquage des données
Pour aider nos clients à se débarrasser du travail répétitif dans les processus administratifs, nous avons développé une API OCR de masquage des données. Elle permet à nos clients de masquer certains champs et images dans les documents.
Notre moteur d’analyse syntaxique peut être entraîné à reconnaître les champs spécifiques qui doivent être masqués. Nous traitons de nombreux champs prêts à l’emploi, mais des champs personnalisés peuvent être ajoutés ou supprimés sur demande.
Plusieurs entrées peuvent être fournies au moteur d’analyse syntaxique, telles que JPG, PNG et PDF. La sortie par défaut que nos clients reçoivent est un fichier JSON, qui peut être transmis aux destinations souhaitées, comme les systèmes de planification des ressources de l’entreprise (ERP). Toutefois, les sorties peuvent être personnalisées, par exemple en CSV, XLSX ou XML, si nécessaire. Outre le JSON structuré, il est également possible d’obtenir les documents masqués au format JPG, PDF ou autres types de fichiers similaires.
Notre API OCR de masquage de données est actuellement disponible via une API RESTful, ce qui permet à nos clients de l’intégrer dans des applications Web. Pour aider nos clients, nous fournissons une documentation claire.
Masquage de données sur mobile
Si vous avez besoin d’une solution de masquage des données sur mobile, Klippa peut également vous aider. Nous proposons un scanner SDK pour mobile qui inclut des fonctionnalités de masquage de données. Les clients utilisent ce scanner SDK pour masquer certaines informations dans les documents d’identité, les reçus, les factures et de nombreux autres types de documents.
Actuellement, notre SDK est disponible pour Android et IOS. En outre, nous proposons des wrappers pour des langages multiplateformes tels que ReactNative, Flutter, Cordova et Nativescript. D’une manière générale, il peut être intégré à n’importe quelle solution mobile.
Que vous recherchiez une solution de bout en bout ou une intégration API / SDK pour automatiser le traitement de vos documents, Klippa est là pour vous aider. Remplissez le formulaire ci-dessous pour une démo gratuite, ou contactez nos experts pour voir comment Klippa peut vous aider.