
L’utilisation d’une solution d’OCR est déjà largement répandue. En fait, en 2021, la taille du marché mondial de l’OCR était évaluée à 8,93 milliards de dollars.
La plupart des entreprises connaissent donc déjà l’importance de l’OCR dans l’automatisation du traitement des documents. Mais pourquoi en est-il ainsi ? La réponse est simple. Les solutions d’OCR offrent un moyen plus facile, plus rapide et plus efficace de traiter les documents, sans intervention humaine ou presque. C’est l’étape que les entreprises doivent franchir pour rester compétitives.
Beaucoup de ces entreprises utilisent l’OCR basée sur des modèles, ce qui fonctionne bien si vous devez traiter un seul type de document dans une seule langue. En fait, cette méthode fonctionne mieux avec une structure spécifique, sans variation de la mise en page.
Cependant, vous pouvez être obligé de traiter plusieurs types de documents, tels que des factures, des reçus et des passeports, dans différentes langues. L’OCR basée sur des modèles ne peut pas traiter efficacement ces documents car ils ne sont pas structurés et ne suivent pas toujours la même mise en page.
Dans un tel cas, vous avez besoin d’une alternative à l’OCR basée sur des modèles. Une alternative qui peut vous aider à traiter des données non structurées provenant d’une grande variété de documents: L’OCR par Machine Learning.
Cet article vous en apprendra plus au sujet de l’OCR par Machine Learning et comment cette technologie peut vous aider à progresser. Mais d’abord, expliquons plus en détail pourquoi l’OCR basée sur des modèles n’est que la première étape de l’automatisation du traitement de vos documents.
L’OCR des modèles, première étape de l’automatisation du traitement des documents
L’OCR basée sur des modèles est souvent appelée OCR traditionnelle. Comme tout autre logiciel d’OCR, celui-ci lit, extrait et fournit des données de sortie pour un traitement ultérieur. La principale particularité de l’OCR basée sur des modèles est qu’elle est formée pour travailler sur des types de documents, des formats et des langues spécifiques.
En outre, elle ne peut travailler qu’avec des données structurées, telles que des noms, des dates, des adresses ou des informations sur les stocks dans des formats standardisés. Dans le cas de l’OCR basée sur des modèles, les caractères doivent également se trouver exactement à l’endroit où le logiciel a été formé pour les rechercher.
Si vous utilisez l’OCR basée sur des modèles, nous ne vous avons probablement rien dit de nouveau jusqu’à présent. Vous savez comment il peut être utilisé et ce qu’il fait.
Dans ce cas, il est probable que vous soyez également conscient des difficultés liées à l’utilisation de l’OCR basée sur des modèles, notamment en ce qui concerne l’évolutivité. Pour chaque nouveau document que vous souhaitez traiter, vous devez créer de nouveaux modèles. Ces modèles définissent essentiellement les règles du logiciel et indiquent où chercher telle ou telle information.
Et si nous vous disions qu’il existe une alternative plus avancée ? Une alternative qui n’est pas limitée par des modèles et des mises en page spécifiques : L’OCR par Machine Learning. Dans la section suivante, vous en apprendrez davantage sur Machine Learning et sur la façon dont il peut vous faciliter la vie.
Qu’est-ce que Machine Learning ?
Le Machine Learning est une branche de l’IA qui utilise des modèles mathématiques de données pour guider les ordinateurs à apprendre sans instructions humaines. Pour faire simple, le Machine Learning permet à une machine de reproduire un comportement humain intelligent.
En outre, le Machine Learning apprend en permanence, améliorant progressivement sa précision, et fait des prédictions en utilisant des données passées et présentes.
Mais quel est le rapport entre tout cela et l’OCR ? C’est ce que nous allons découvrir !
Machine Learning OCR
Le Machine Learning permet au logiciel d’OCR de comprendre et de reconnaître le contexte général d’un document. Grâce à la capacité de le Machine Learning à faire des prédictions, le logiciel d’OCR ne se débat pas avec la variété des documents qu’il reçoit. Avec suffisamment de données, il peut prédire où apparaissent certains champs de données et extraire les données des documents en conséquence.
Bien sûr, il faut beaucoup de données pour que les modèles de prédiction soient précis. Cependant, il n’est pas nécessaire de créer de nouveaux modèles avec des règles strictes chaque fois que vous traitez avec un nouveau fournisseur ou un nouveau type de document.
En outre, certaines solutions d’OCR basées sur le Machine Learning sont capables de détecter des anomalies dans le texte ou la structure des documents, ce qui explique pourquoi elles sont utilisées pour détecter la fraude documentaire.
Maintenant que les deux technologies ont été expliquées, il est temps de voir pourquoi l’OCR par Machine Learning est la meilleure alternative à l’OCR basée sur des modèles.
OCR par Machine Learning vs OCR par modèle
Pour prouver que l’OCR par Machine Learning est la meilleure alternative à l’OCR basé sur des modèles, nous allons comparer les deux approches sur les points suivants :
- Capacité à traiter des données structurées et non structurées
- Capacités d’apprentissage
- Participation des employés
- Précision
- Économies de temps et d’argent
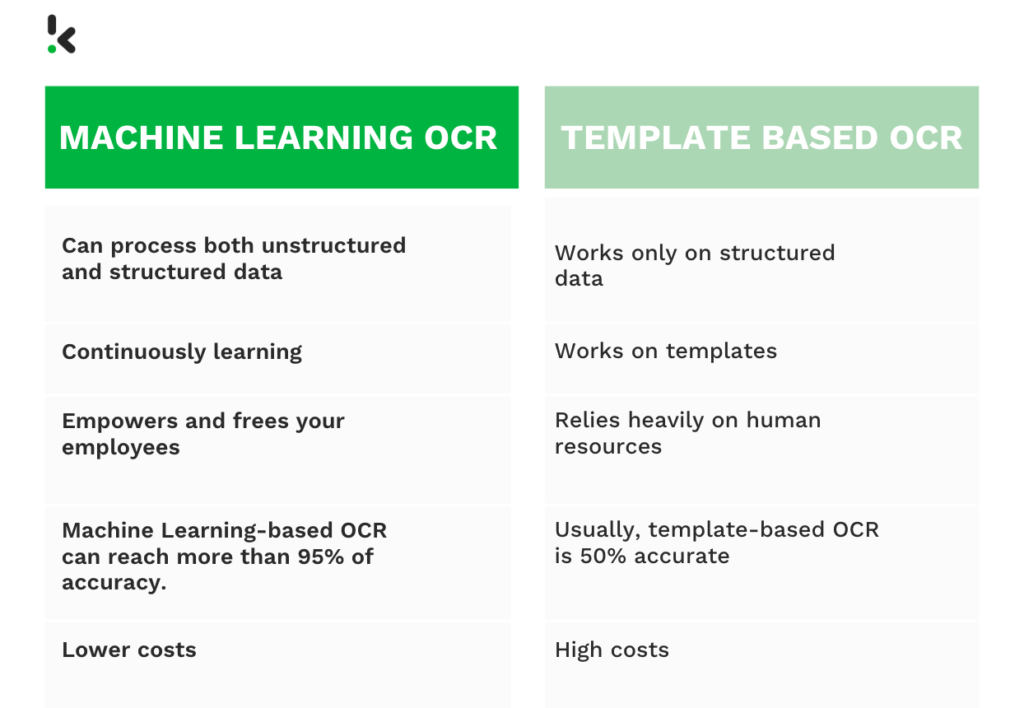
Prenons chacun de ces points et voyons pourquoi l’OCR par Machine Learning est la meilleure solution pour le traitement des documents.
Capacité à traiter des données non structurées et structurées
L’OCR par Machine Learning peut traiter les données structurées et non structurées d’un document. Prenons l’exemple d’une facture. S’il est correctement formé, le Machine Learning de l’OCR comprendra quelles données sont des montants, des détails sur le commerçant, des postes, etc. Pas sur un modèle de facture spécifique, mais sur chaque facture que vous recevez.
Comme l’OCR par Machine Learning fonctionne avec des prédictions et imite l’intelligence humaine, elle peut classer les documents en fonction de leur contenu et de leur structure. Tous les documents peuvent être traités avec précision, à condition que le moteur ait été informé de suffisamment de données.
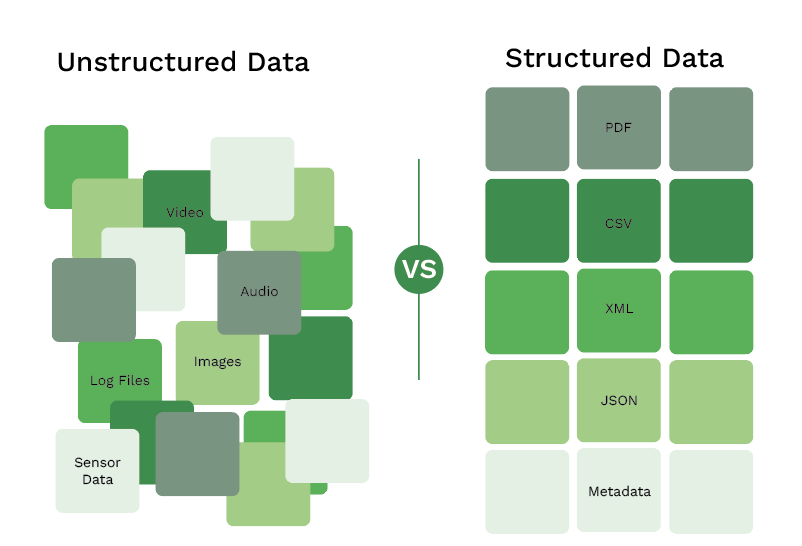
Grâce à le Machine Learning, vous êtes en mesure de traiter tous les types de documents, qu’ils contiennent des données structurées ou non. L’OCR basée sur des modèles, en comparaison, ne fonctionne que sur des données structurées. C’est un inconvénient important, car il limite l’évolutivité de votre organisation en matière de traitement des documents.
Capacités d’apprentissage
Le principal objectif de le Machine Learning est de permettre aux ordinateurs d’apprendre de manière autonome sans intervention humaine. Expliquons plus en détail ce processus d’apprentissage.
L’OCR par Machine Learning repose sur des modèles de prédiction, construits à partir d’algorithmes et de données d’entraînement. Tout d’abord, les modèles sont créés en fonction de tous les documents et ensembles de données qu’il a traités. Au lieu de chercher une position spécifique sur un document, les algorithmes prédisent où les données devraient se trouver en fonction de tous les exemples qu’il a déjà lus et traités.
Grâce à l’expérience acquise par le moteur à partir d’autres documents, l’OCR par Machine Learning continue d’apprendre. C’est pourquoi vous avez besoin de moins de ressources pour l’améliorer.
Avec moins de ressources nécessaires pour améliorer la solution d’OCR, vos employés peuvent se consacrer à des tâches à plus haute valeur ajoutée. Nous allons maintenant nous concentrer sur ce sujet.
Participation des employés
L’OCR par Machine Learning peut changer la donne pour votre entreprise. En automatisant plus de processus, vos employés sont libérés des tâches ennuyeuses de saisie de données et ils doivent moins s’occuper de la création de modèles pour le logiciel d’OCR. Votre équipe peut désormais se concentrer sur des tâches plus importantes qui contribuent à la croissance de votre entreprise.
Jusqu’ici tout va bien, mais que dire à propos de la précision des deux approches ? Voyons s’il y a une différence entre les deux.
Précision
La précision est l’une des principales raisons pour lesquelles les entreprises se tournent vers l’automatisation lorsqu’il s’agit d’extraction de données.
Le Machine Learning combiné à la technologie OCR présente un taux de précision de plus de 95 %. Pour atteindre ce taux de précision, le modèle de Machine Learning analyse et interprète les données brutes. Cette étape permet aux solutions OCR de Machine Learning de reconnaître des modèles, puis de détecter et d’extraire des données avec une grande précision.
Toutes ces informations et cette expérience de la compréhension du document sont ensuite utilisées pour prédire d’autres similitudes dans le document suivant.
Alors que l’OCR classique, comme l’OCR basée sur des modèles, a une précision d’extraction des données de 60 % à 85 %, de nombreuses solutions plus avancées intégrant l’IA et le Machine Learning peuvent atteindre 99 %.

Grâce à le Machine Learning, les logiciels d’OCR sont presque entièrement autonomes. Il extrait les données avec un taux de précision élevé. Cela vous permet de faire gagner du temps à votre équipe et de réduire les coûts opérationnels. Nous y reviendrons plus tard.
Économies de coûts et de temps
En général, l’OCR par Machine Learning est moins coûteuse que l’OCR par modèle. Pour prouver notre point de vue, examinons les facteurs suivants :
- Moins de ressources humaines nécessaires – Une plus grande efficacité entraîne une réduction des coûts opérationnels
- Une plus grande précision – Moins d’erreurs de saisie de données vous fait économiser beaucoup d’argent à long terme
- Aucune création de modèle coûteuse n’est nécessaire – Votre organisation gagne du temps et de l’argent
Vous savez maintenant que l’OCR traditionnelle n’est pas le logiciel le plus efficace pour l’extraction de données. En utilisant l’OCR par Machine Learning, vous pouvez traiter tous vos documents plus rapidement, avec une plus grande précision et à moindre coût.
Si vous souhaitez savoir comment l’OCR par Machine Learning de Klippa peut vous aider à atteindre cet objectif, vous trouverez plus d’informations ci-dessous.
Présentation de Klippa DocHorizon
À ce moment, vous avez lu le blog et appris les différences entre l’OCR basé sur des modèles et l’OCR par Machine Learning. Avons-nous éveillé votre intérêt pour une solution d’OCR à Machine Learning précise et efficace ? Alors continuez à lire, cela devient encore plus intéressant.
Klippa est un expert en traitement automatisé de documents. Notre société fournit des logiciels d’OCR intelligents, tels que Klippa DocHorizon, qui automatisent l’extraction, la classification, la vérification et l’anonymisation des données. Tous nos logiciels sont basés sur le Machine Learning et l’intelligence artificielle (IA).
Klippa DocHorizon est capable de traiter tous types de documents: documents financiers, documents d’identité, documents logistiques, etc. Essayez-le avec nos exemples ci-dessous ou soumettez vous-même un document, et voyez comment notre solution d’OCR par Machine Learning se comporte.
Try it out yourself
En quelques secondes, généralement entre 1 et 5 secondes, le document est traité. Votre document est numérisé, et toutes les données sont livrées dans le format de sortie structuré de votre choix.
Êtes-vous prêt à automatiser le traitement de vos documents ? Réservez une démonstration avec l’un de nos spécialistes ci-dessous, ils se feront un plaisir de vous montrer les possibilités.