
Les données étant le nouvel or du monde des affaires, il est extrêmement problématique pour les entreprises que ces informations précieuses soient enfermées dans des formats de documents non structurés tels que les PDF. En effet, ces formats ne sont pas lisibles par les machines, ce qui implique que pour exploiter les données d’un document PDF, il faut les extraire manuellement et les sauvegarder dans une base de données.
L’extraction manuelle des informations est un processus possible tant que les entreprises ne traitent que quelques documents PDF. Dès qu’une organisation doit traiter des quantités plus importantes, le processus manuel devient trop lent, trop coûteux et trop sujet aux erreurs.
C’est là qu’un parseur de fichiers PDF ( ou aussi nommé analyseur de fichiers PDF) peut remplacer le processus manuel traditionnel d’extraction et de saisie des données. L’analyse de données permet de convertir rapidement des données d’un format à un autre, par exemple un fichier PDF en un fichier JSON lisible par une machine.
Dans ce blog, nous verrons ce qu’est un analyseur de fichiers PDF et comment les données PDF sont analysées. Ensuite, nous expliquerons pourquoi les entreprises devraient utiliser un analyseur syntaxique PDF en général, puis nous terminerons le blog avec une solution d’automatisation de l’analyse syntaxique PDF.
Qu’est-ce qu’un parseur de fichiers PDF ?
Un parseur de documents PDF (également connu sous le nom de PDF scraper) est un logiciel capable d’identifier et d’extraire des données à partir de documents PDF. Cela signifie que le texte du document (c’est-à-dire les données non structurées) est converti en données structurées qui peuvent être lues par des machines. Cela permet de débloquer des informations précieuses qui, autrement, resteraient inaccessibles dans le format non structuré.
En général, un analyseur syntaxique de PDF vous permet de:
- Extraction de texte à partir de PDF
- Extraction d’images à partir de PDF
- Extraction de tableaux et d’autres structures à partir de PDF
- Convertir le fichier PDF en fichiers JSON, XML et HTML
- Utiliser des données structurées pour les processus d’entreprise
Maintenant que nous savons ce qu’est un analyseur de fichiers PDF, voyons comment fonctionne l’analyse pour que vous puissiez également l’utiliser dans votre entreprise.
Comment faire du parsing des données PDF ?
Les parseurs de fichiers PDF utilisent des algorithmes avancés pour identifier les éléments de données d’un document PDF. Si l’analyseur syntaxique PDF est bien formé, il sera en mesure d’identifier tous les types d’éléments de base du document.
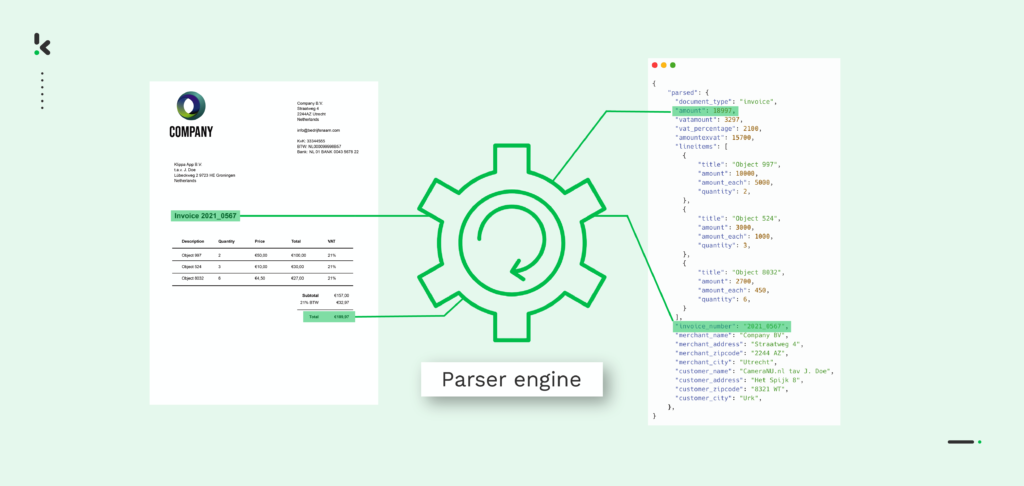
Ce processus fait appel à la reconnaissance optique de caractères (OCR) et à d’autres technologies d’intelligence artificielle telles que le traitement du langage naturel (NLP) et le machine learning (ML). Ce n’est qu’avec l’aide de ces technologies qu’un analyseur de fichiers PDF est capable de scanner un fichier PDF et d’en analyser les données.
Le processus peut se dérouler comme suivant:
- Téléchargement d’un fichier PDF vers le parseur → Le PDF doit être téléchargé vers une API pour lancer le processus d’analyse. Il est important que le PDF ne contienne pas de bruit de fond.
- Prétraitement du PDF → La luminosité de la numérisation du PDF peut être optimisée ou les niveaux de gris améliorés afin d’accroître la précision de reconnaissance des données.
- Conversion du PDF en texte → Cette étape permet de convertir le document PDF en fichier texte (TXT). Chaque partie du document est reconnue (montant total, adresse, etc.), puis les données sont extraites.
- Conversion en données structurées → Dans cette dernière étape, le fichier texte est converti en un format structuré lisible par une machine, tel que JSON. Il est désormais possible de traiter facilement les données du PDF dans votre base de données.
À ce stade, vous vous demandez peut-être quel type de données qu’un parseur de fichiers PDF peut réellement extraire pour vous aider à décider s’il répond à vos besoins.
Quelles sont les données qui peuvent être analyser à partir des PDF?
Pour la plupart des organisations, les fichiers PDF sont l’option de choix pour de nombreux types de documents. Pensez aux livres, aux présentations, aux factures, aux bons de commande et aux rapports qui sont souvent partagés entre les organisations sous la forme d’un fichier PDF.
Si les PDF sont un format de fichier idéal pour intégrer des contenus multimédias, les analyseurs de PDF vous permettent d’en extraire les informations suivantes:
- Paragraphes de texte → Même s’il s’agit de la forme de données la plus élémentaire, le fait de copier et coller manuellement le texte entraînerait des problèmes de formatage. Un analyseur syntaxique de PDF est capable d’extraire le texte avec le bon formatage afin que vous puissiez facilement l’utiliser pour d’autres processus.
- Tableaux et listes → Ici, il vaut la peine de faire des recherches supplémentaires car seuls les analyseurs de PDF les plus modernes peuvent identifier la présence de tableaux. La plupart des anciens analyseurs de PDF considèrent les tableaux comme des paragraphes et les détruisent, ce qui nécessite une extraction manuelle des données.
- Images → Un analyseur syntaxique de PDF est capable d’extraire les images présentes dans le document PDF. C’est particulièrement utile lorsque vous souhaitez réutiliser des images du document ailleurs et cela vous évite de faire des captures d’écran de mauvaise qualité.
- Champs de données uniques (numéros de localisation, codes QR, codes à barres, etc.) → Si un PDF contient des champs avec des données uniques, un analyseur de PDF peut les extraire avec précision et organiser proprement les données dans un champ particulier.
Dans cette optique, nous allons maintenant examiner les raisons pour lesquelles un analyseur de fichiers PDF est utile aux entreprises.
Pourquoi les entreprises devraient-elles utiliser l’analyse syntaxique des PDF?
Les différentes mises en page et structures des fichiers PDF les rendent complexes et difficiles à extraire. C’est pourquoi l’extraction manuelle des données prend du temps et peut donc coûter beaucoup d’argent. Elle est également source de nombreuses erreurs et d’une extraction de données imprécise.
Avec un analyseur syntaxique de PDF, les erreurs et les extractions imprécises peuvent être évitées. Comme nous l’avons vu plus haut, grâce aux technologies modernes, un analyseur syntaxique de PDF est capable d’identifier et d’extraire des informations sur des PDF avec précision et sans problèmes de formatage.

Comme vous pouvez l’imaginer, cela entraîne une réduction significative du temps consacré au traitement des PDF, ce qui réduit les coûts et l’utilisation d’autres ressources qui peuvent alors être consacrées à des tâches à plus forte valeur ajoutée. La réduction de la durée de traitement des documents se traduit par une optimisation des flux de travail, ce qui facilitera le fonctionnement de votre entreprise.
Comme vous pouvez le constater, un logiciel d’analyseur de documents PDF présente de nombreux avantages. C’est pourquoi plusieurs éditeurs de logiciels ont mis au point une solution dont vous pouvez profiter. L’une de ces solutions logicielles est Klippa DocHorizon.
Automatisation du parsing des fichiers PDF avec Klippa DocHorizon
Klippa DocHorizon est notre logiciel d’OCR basé sur l’IA qui peut être utilisé pour analyser les informations contenues dans les PDF et autres documents avec lesquels votre entreprise est susceptible de travailler. Grâce à notre technologie d’OCR, vous pouvez extraire avec précision des données pertinentes à partir de formats de données non structurés (tels que les PDF) et les convertir dans le format souhaité.
En outre, DocHorizon peut classer les types de documents, vérifier et anonymiser les données, tout en éliminant la saisie manuelle des données. DocHorizon reconnaît d’emblée un large éventail de documents dans plus de 100 langues.
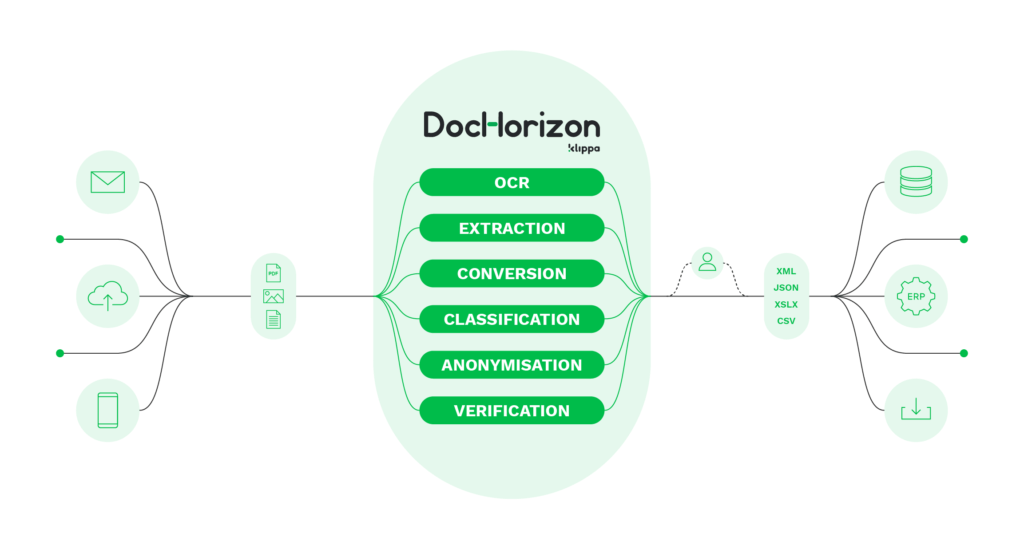
Notre solution est disponible via API et SDK, ce qui permet à vos employés d’extraire et de sauvegarder rapidement toutes les informations pertinentes dans la base de données de votre organisation.
Souhaitez-vous également transformer vos données qui sont bloquées dans des formats inutilisables en données prêtes à l’emploi? Nous nous ferons un plaisir de vous montrer comment y parvenir grâce à notre solution. Réservez une démonstration gratuite ci-dessous ou contactez l’un de nos experts.